1、Transformer为何使用多头注意力机制?(为什么不使用一个头)
使用多头有助于捕获更丰富的特征信息,多头是通过降维获得多个子空间,可以更加综合利用各方面的信息,且计算成本与单个head相差不多。这也与CNN的通道有点类似。
2、Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
请求和键值初始为不同的权重是为了解决可能输入句长与输出句长不一致的问题。并且假如QK维度一致,如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。
Q和K相乘是为了得到一个attention score矩阵,然后用来对V进行提纯。Q和K使用不同的权重W_q和W_k进行相乘,可以理解为在不同空间上的投影,在不同空间上的投影不相同,增加了表达能力,获得不同的attenton score矩阵,这样得到的attention_score矩阵泛化能力更高,提高了泛化能力。
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
为了计算的更快,而且空间效率更高。矩阵加法的加法计算相对简单,但是作为transformer的隐层,整体的计算量和点乘差不多,即两者的计算复杂度相差不多。
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解。
转载介绍
为什么比较大的输入会使softmax的梯度变得很小,对于输入向量x,softmax经过映射归一化到一个分布y’,这个过程中softmax用一个自然底数e,将输入之间的差距拉大,然后归一化为一个分布,假设向量X中最大元素的下标是k,如果输入的数量级变大(每个元素都很大)那么yk会非常靠近1。

可以看出数量级对softmax 的影响很大,在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。
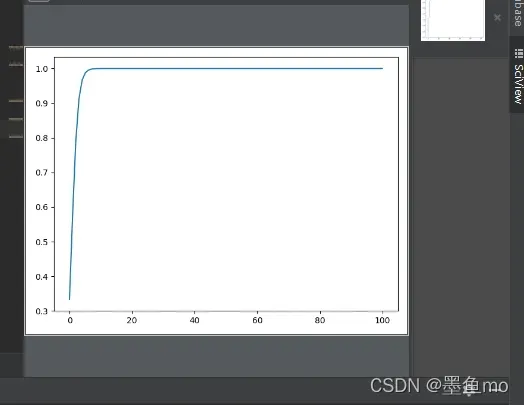

假设向量 q和k 的各个分量是互相独立,均值为0,方差为1,q*k的均值为0,方差为dk。


为使其方差为1.
5.在计算attention score的时候如何对padding做mask操作?
对需要mask的位置设置成很大的负数,然后再算attention score.
6.为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
将原来的高维空间转换成多个低维空间并拼接起来,不仅可以丰富特征信息,还可以减少计算量。
7.大概讲一下Transformer的Encoder模块?
输入时加入词嵌入并加上位置编码信息,再多个编码模块(每个有一个multi-head-attention 和FFN每个子层有残差连接并使用层归一化)
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
这个也是为了使方差为1。为了更好的初始化
9.简单介绍一下Transformer的位置编码?有什么意义和优缺点?
attention是与位置无关的,无论句子怎么样,通过attention计算都是一样,这不符合我们的要求,所以要想办法表达每个token的位置信息,所以transformer来通过位置编码来表示token在句子中的信息。
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
相对位置编码(RPE)1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
11.简单讲一下Transformer中的残差结构以及意义。
因为本身训练的参数就是比较少,可以将模型做的比较深,encoder和decoder的self-attention层和ffn层都有残差连接。反向传播的时候不会造成梯度消失。
12.为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
layernorm更适合句子不一样长的NLP序列,对每个样本进行归一化,这样更好,在多头注意力层和激活函数层。
13.简答讲一下BatchNorm技术,以及它的优缺点。
批归一化是在进入激活函数之前对每批的数据进行归一化处理,可以提高收敛速度,防止过拟合,防止梯度消失,增加网络对数据的敏感性。
14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
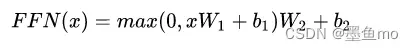
使用ReLU激活函数,
优点:收敛速度比 sigmoid 和 tanh 快;(梯度不会饱和,解决了梯度消失问题)计算复杂度低,不需要进行指数运算;适合用于反向传播。
缺点:ReLU的输出不是zero-centered;
ReLU在训练的时候很”脆弱”,一不小心有可能导致神经元”坏死”。举个例子:由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活。如果这个情况发生了,那么这个神经元之后的梯度就永远是0了,也就是ReLU神经元坏死了,不再对任何数据有所响应。实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都坏死了。 当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。,Dead ReLU Problem(神经元坏死现象):某些神经元可能永远不会被激活,导致相应参数永远不会被更新(在负数部分,梯度为0)。产生这种现象的两个原因:参数初始化问题;learning rate太高导致在训练过程中参数更新太大。 解决方法:采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
ReLU不会对数据做幅度压缩,所以数据的幅度会随着模型层数的增加不断扩张。
15.Encoder端和Decoder端是如何进行交互的?
通过转置encoder_ouput的seq_len维与depth维,进行矩阵两次乘法,即q*kT*v输出即可得到target_len维度的输出
16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?
Decoder有两层多头,encoder有一层多头,Decoder的第二层mha是为了转化输入与输出句长,Decoder的请求q与键k和数值v的倒数第二个维度可以不一样,但是encoder的qkv维度一样。
17.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
Transformer的并行化主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,但是rnn只能从前到后的执行。
18.Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
LN是为了解决梯度消失的问题,dropout是为了解决过拟合的问题。在embedding后面加LN有利于embedding matrix的收敛。
版权声明:本文为博主墨鱼mo原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_45553275/article/details/123218466