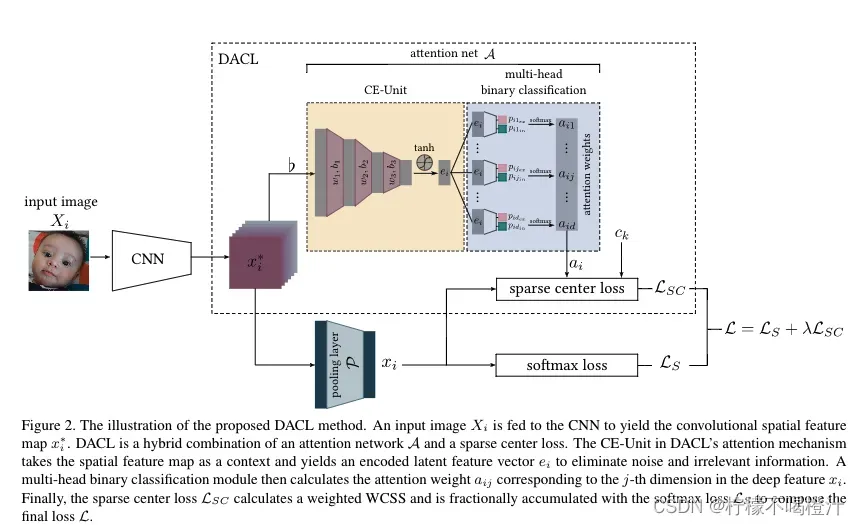
这篇文章的重点是“深度注意力中心损失”。
下面简要描述一下网络中下面分支的pipeline:
为输入的图像,经过CNN处理后,得到特征图
。下面的分支进行如下处理:pooling layer处理
后得到
,
是一个一维的特征向量,再将
经过一个全连接层计算后得到表情的概率分布,最后计算分类softmax loss,也就是
。
难点在于上面分支的理解,也就是sparse center loss如何计算。在介绍上面分支的pipeline之前,需要介绍一下什么叫中心损失。
中心损失的目标是:最小化 “ 深层特征 ” 与其 “ 对应的类中心” 之间的距离。举个例子,有一批batch size为m的样本,其中
为某个样本
的一维特征向量,
,d代表一维特征向量
的长度。
代表各个样本的类别,
,比如说有8种表情,那么K就为8。
代表各个类别的中心特征向量,
,d代表一维特征向量
的长度。那么中心损失的定义如下式,其实就是“ 深层特征
” 与其 “ 对应的类中心
” 之间的距离。
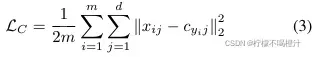
我们认为,并非特征向量中的所有元素都与区分表情有关。我们的目标是在深层特征向量中只选择一个子集的元素来进行表情区分。因此,为了在判别过程中滤除不相关的特征,我们在上述公式中的维度d上对计算出的欧式距离进行加权。也就是下式:

好了,补充完中心损失的知识点,下面来说上面分支的pipeline。
上面分支存在的目的是:为了计算Eq.4(也就是上式)中的。通过堆叠三个全连接的线性层来构建一个密集的 CE-Unit 以提取特征图
中相关的信息,也就是下式,其中
是一个一维的特征向量,且其长度
远小于d。

那么怎么用计算得到
呢?答案就是利用多头二分类网络。也就是说将得到的
利用d次,做d次全连接操作,每次全连接操作完成后都会得到一个长度为2的一维特征向量,这个特征向量里第一个元素
代表inclusion的分数,另一个元素
代表exclusion的分数。

最后通过下式计算(也就是对每个头的
和
做softmax)而得:
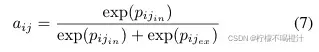
有了后,就可以对普通的中心损失加权了,也就是Eq.4中所表达的稀疏中心损失,也就是网络总结构图中所画的sparse center loss,即图中的
。
通篇读下来,其实这篇文章的创新点主要在于 sparse center loss的生成,我刚开始读的时候一直不明白到底代表什么,后来想想,
所描述的是一维特征向量中各个元素的重要性,而不是各个一维特征向量之间的重要性。打个比方,比如 “一张开心表情图片” 的特征向量是
,“开心表情” 的中心特征向量是
,我们要计算二者之间的距离,很容易就会想到计算两个向量之间的欧式距离就行了,也就是上面说的Eq.3,这样就是平等地对待两个向量中的各个元素:
,…,
。本文作者就是要打破这种平等对待,作者认为并不是说特征向量中所有的元素都同样重要,而是说有的元素更重要,有的元素没那么重要,也就是说不平等地对待两个向量中的各个元素:
,…,
。这里的0.15和0.45就是
。
最后的loss如下式:

版权声明:本文为博主柠檬不喝橙汁原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42785704/article/details/123258913