DALL-E 系列:AI绘图原理,根据用户给出的描述,生成与描述相匹配的图像
DALL-E 的提出是为了解决图像生成的问题,即通过文字描述生成对应的图像。
DALL-E 文生图官网:https://labs.openai.com/
DALL-E 1
DALL-E算法分为三个阶段,分别训练 DVAE、DALL-E 和 CLIP 模型。
- DVAE 用于图像特征编码和解码( 下图 Stage One 的 dVAE )
- DALL-E 结合图像和文本特征生成图像(下图的 Stage Two)
- CLIP用于图像排序和匹配( 下图 Sample Ganeration、Rerank using CLIP )
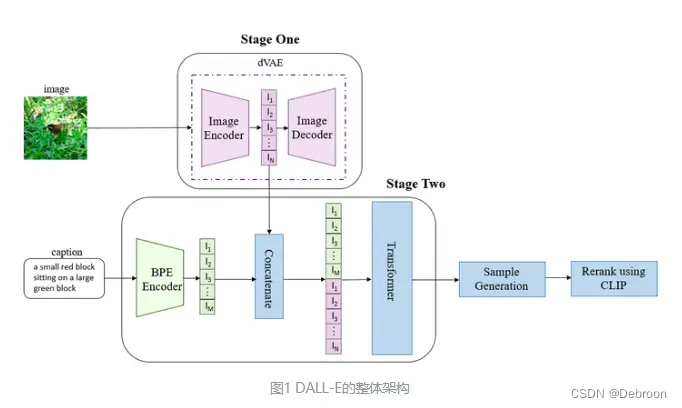
DALL-E的推理主要分为三个阶段,其中前两个阶段对应上图中的Stage One和Stage Two。
在第一阶段,DALL-E 将一张256×256的图片分成32×32个小块。
每个小块都经过训练好的离散VAE模型的编码器进行处理。
编码器将每个小块映射到一个大小为8192的词表中,这个词表可以看作是一个包含很多不同特征的列表。
这样,每个小块都被表示为一个唯一的token,而不是原始的像素值。
最终,整张图片被表示为1024个(上图红色 )这样的token,其中每个token代表着图片的一个小块。
- 1024 是把,输入图的 256×256 压缩成 32×32(1024)
- 每个位置有 8192 种可能的值
- 也就是说 dVAE 的 encoder 输出是维度为 32x32x8192 的 logits(每个类别的得分或概率)
这种表示方式可以帮助 DALL-E 更好地理解图片的结构和特征,从而在后续的生成过程中更好地控制和生成与给定图片相关的内容。
在第二阶段,DALL-E使用 BPE 编码器对文本进行编码。
BPE是一种常用的文本编码技术,将文本分割成更小的单元,通过组合这些单元来表示更复杂的文本结构。
通过 BPE-encoder 对文本进行编码,最多可以得到256个token(上图绿色 )。
如果文本不足256个token,就会进行填充,以达到256个token的长度。这样,每个token代表文本的一个部分或特征。
然后,将这256个文本token与之前得到的1024个图像token进行拼接。
得到一个长度为1280的数据(上图绿色+红色块)。
这个拼接的数据包含了文本和图像的信息。
最后,这个拼接的数据被输入到训练好的Transformer模型中。
在第三阶段,DALL-E使用已经训练好的模型生成图像。
- Sample Generation(上图)
- Rerank using CLIP(上图)
首先,模型通过对输入的1280个token进行处理和解码,生成一张图像。
这个生成的图像可能与给定的文本相关,但也可能不太符合预期。
为了评估生成的图像与给定文本的匹配程度,DALL-E使用 CLIP 模型。
- 前置知识:CLIP 模型
CLIP 模型是一个能够理解和衡量图像与文本之间关系的模型。通过将生成的图像和给定的文本输入到CLIP模型中,可以计算出它们之间的相似度或匹配程度。
然后,DALL-E对生成的图像进行采样,即生成多个不同版本的图像。
这些采样结果与给定文本一起,作为输入送入CLIP模型。
CLIP模型会对每个采样结果和给定文本进行评分,排序出最与给定文本匹配的生成图像。
- 产生的结果再用 clip 选择一个最合适的进行输出。
这样,通过对模型生成的图像进行采样,并使用CLIP模型对采样结果进行排序,DALL-E能够找到与给定文本最匹配的生成图像。
这个过程可以提高生成图像的质量和与文本的关联性。
&nsbp;
dVAE
dVAE 是 VQVAE。
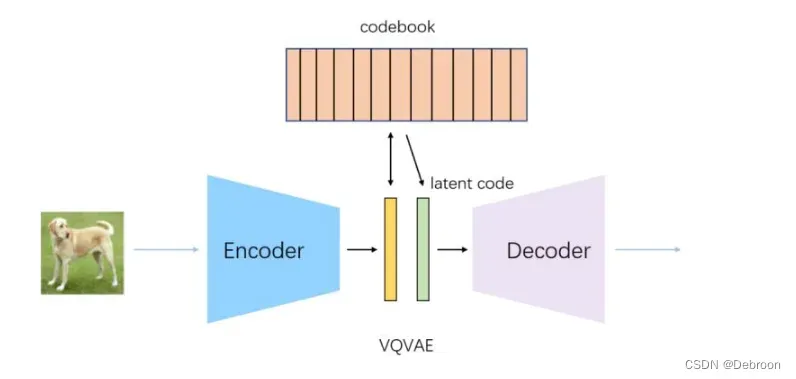
假设我们有一张猫的图像,它有大眼睛和尖耳朵。
对于VAE,会学习到这个猫图像的均值和方差,比如大眼睛的均值和方差、尖耳朵的均值和方差。然后,从这些高斯分布中采样,生成新的猫图像,可能会有稍微不同的大眼睛和尖耳朵。
对于VQVAE,会将这张猫的图像转换成一些离散的编码。比如选择一个表示大眼睛的编码和一个表示尖耳朵的编码。然后,通过解码器,可以使用这些编码来生成新的猫图像,可能会有稍微不同的大眼睛和尖耳朵的组合。
俩者区别:
VAE生成的样本可能会有一些模糊和平滑的效果,而VQVAE生成的样本则更加清晰和锐利。
- VAE 只能在高斯分布的范围内生成样本,生成的图像或数据会比较平滑和连续,会有一些模糊和模糊的效果。
- VQVAE通过直接匹配代码簿中的向量来生成,生成的样本会更加清晰和锐利,因为代码簿特定编码经过训练优化,能够更好地捕捉数据的重要特征、提供抽象表示能力,并生成清晰、锐利的样本。
因为这个词表是离散的,不可导。
dVAE 引入 Gumbel-Softmax-trick 解决不可导,就是通过引入随机性来近似最大值的选择,变得可导。
- 使用一个特殊的 Gumbel 分布来加入随机噪声。
- 使用softmax函数来对这些带有噪声的值进行归一化,以得到一个概率分布。
- 最终,可以通过对这个概率分布进行采样,来选择最接近的编码。
在重建图像的过程中,通常使用一个分布来建模图像的像素值。传统的方法通常使用高斯分布来建模图像像素的概率分布。
提出了 logit-Laplace 分布(拉普拉斯变体)代替真实图像与高斯图像不匹配。
logit-Laplace分布是一种以 logit 函数为参数的 Laplace 分布。
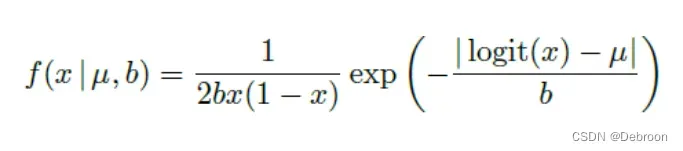
与高斯分布相比,logit-Laplace分布能够更好地捕捉到图像中的边缘和细节,因为它的尾部分布更加重。
dVAE 就是在 VAE 只能高斯分布生成图像基础上,变成,特定编码表生成 + 引入随机性来近似最大值的选择 + 拉普拉斯变体。
如果对 dVAE 模块感兴趣,请猛击:《漫谈VAE和VQVAE,从连续分布到离散分布》
Transformer
Transformer 模块有:64层注意力,每层注意力62个头,每个头64注意力维度。
有 64 层注意力
- 注意力层是神经网络模型中的一种组件,用于将模型的注意力集中在输入数据的不同部分上。
每层注意力有 62 个头
- 注意力头是在注意力机制中的并行处理单元,可以同时关注输入数据中的不同位置和特征。
每个头 64 注意力维度
- 每个头可以生成的注意力权重的数量,这些权重用于加权不同位置的输入数据。
attention层使用了行注意力mask、列注意力mask、卷积注意力mask三种稀疏注意力:

Transformer的输入:
-
pad embd 通过学习得到,为每个位置都训练了一个 pad embd,即 256 个pad embd。
-
在对文本 token 进行 pad 时,使用对应位置的 pad embd。
DALL-E 2
论文地址:http://arxiv.org/abs/2204.06125
代码实现:https://github.com/lucidrains/DALLE2-pytorch
DALL-E 2 改进在于,生成高度逼真的图片。
模型分为 3 部分:CLIP(下图虚线之上)、先验Prior、decoder(image)
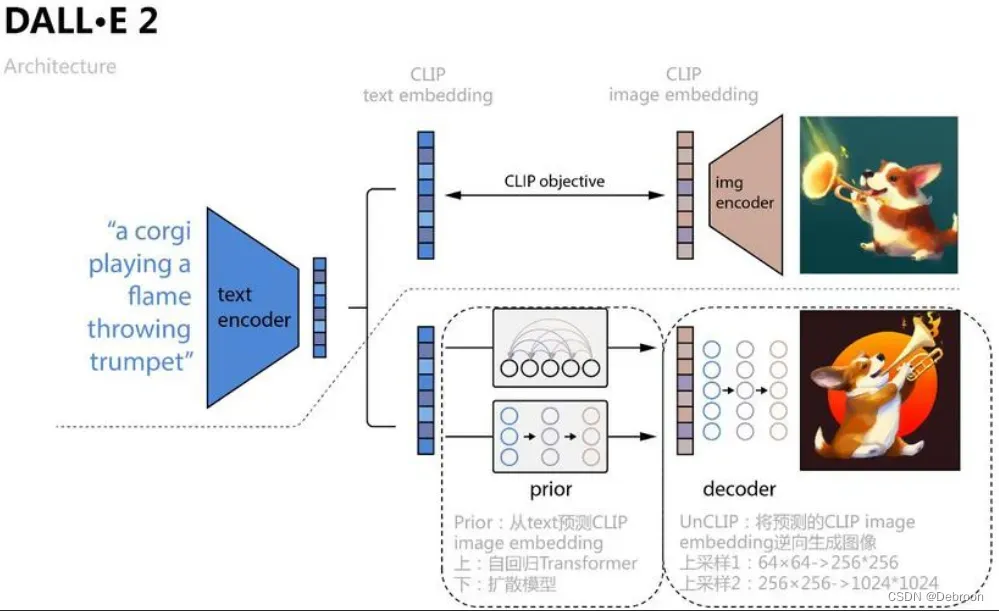
3 个模块各自训练。
CLIP
CLIP 模块目的是文本编码和图像对应。
- 前置知识:CLIP 模型
先验 prior
先验 prior:
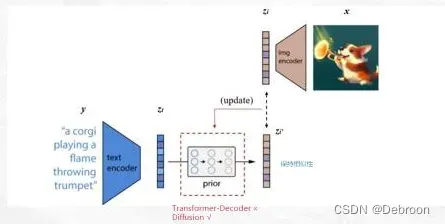
先将文本编码器中的文本拿出,把文本向量,输入。
再从图像编码器中的图像拿出来,把图像向量,输入,输出
。
希望 输入,输出
越接近越好,根据这个来更新 prior(扩散模型实现)。
训练好 prior 后,走一遍流程:文本编码器 -> prior -> ,得到新图像。
decoder(image)
decoder(image):从图像特征还原出真实图像。
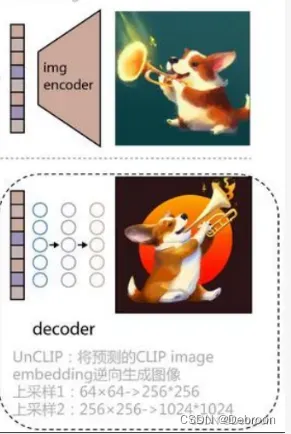
DALL-E 2 不仅能文生图,还可以图像修补、图像风格迁移。
还有一些问题:容易把物体和属性混淆、文本放入图像能力不足、复杂场景细节处理不真实。
DALL-E 3
论文地址:https://cdn.openai.com/papers/dall-e-3.pdf
DALL-E 3 链接:https://openai.com/dall-e-3
DALL-E 3 经过精心设计,对提示词的完美遵循。
无论是整体的环境描写,还是精确到物体数量、着装、颜色这种细节叙述,DALL·E 3都能很好地理解,并生成对应的画作,丝毫不漏重点。
能够将抽象的想法和提示转化为异常准确的图像。
比如能将模糊的形容词,如繁华、讨价还价、脾气暴躁等词汇用绘画的方式演绎得活灵活现。
和 DALLE2 对比,在细节、清晰度、明亮度等方面都能看出两者生成的明显差异。
- DALLE3 能够更有效地细化手部等小细节,更加准确地表示具体特定对象和它们之间关系的场景。
训练了一个“图像字幕器”(image captioner),专门用来给数据集中的图像重新生成文本描述。

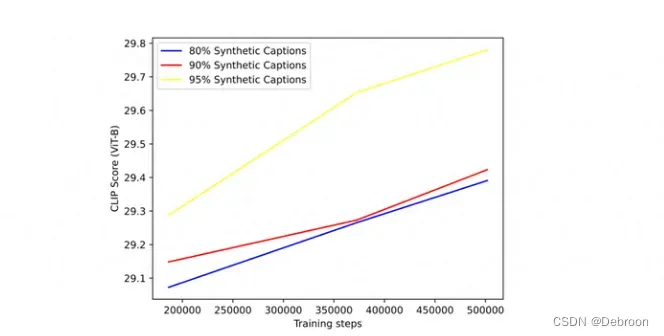
属于大力出奇迹。
文章出处登录后可见!