
2020年,OpenAI提出了在增加模型尺寸与提高模型性能之间的扩展定律,指出人们应该将大部分预算用于扩大模型规模。这篇论文直接推动了增大模型规模的浪潮。然而,在预算和内存有限的情况下,盲目扩大模型规模并不是提升模型性能的最佳选择。
2022年,DeepMind团队发表了一篇论文(https://arxiv.org/pdf/2203.15556.pdf),文中对比了模型大小和训练数据,最终结论是:多数语言模型明显训练不足。也就是说,在不增加模型大小的情况下,在更大的数据集上训练模型将受益匪浅。文中,DeepMind团队训练了一个相对较小的LLM,名为Chinchilla,这个模型只有700亿个参数,但却有1.4万亿个训练token。经过训练,Chinchilla模型的性能超越了诸如GPT-3、Gopher、Jurassic-1和MT-NLG等更大的语言模型,这些语言模型的参数都在1750亿-5300亿之间,但训练token却在2700亿-3000亿之间。
更小的模型参数意味着更低的推理成本和更小的内存占用,实际上,对于大部分用例来说,小型语言模型的性价比更高。本文就从数学角度推算了为何在更多token上训练更小的LLM是更优选择。(以下内容在遵循CC BY-NC-SA 4.0协议的基础上由OneFlow编译发布,译文转载请联系OneFlow获得授权。原文:https://www.harmdevries.com/post/model-size-vs-compute-overhead/)
作者|Harm de Vries
OneFlow编译
翻译|杨婷、徐佳渝
当我们使用大型计算集群来训练大型语言模型(LLM),通常需要考虑计算(资源)预算的分配问题。具体来说,就是考虑如何确定模型参数的数量N及训练token数量D。
我们可以利用扩展定律(scaling laws)来获得相关指导,既可以在给定的计算(资源)预算C的条件下,如何把C分配给参数数量![]() 和训练token数量
和训练token数量![]() 从而使模型达到最佳性能;也可以在给定模型性能的条件下,平衡参数数据量N和训练token数量D,从而使得计算预算C最小,我们可以把计算预算C最小的LLM称为计算量最优的LMM。
从而使模型达到最佳性能;也可以在给定模型性能的条件下,平衡参数数据量N和训练token数量D,从而使得计算预算C最小,我们可以把计算预算C最小的LLM称为计算量最优的LMM。
然而,对大多数用例而言,我们不一定要去训练计算量最优的LLM,而应投入一定的额外计算(资源)来训练一个同等性能但更小的模型。小型模型的推理速度更快同时推理价格也更低,对GPU资源有限的开发人员和研究人员来说运行也更容易。
尽管许多LLM从业者训练模型的token数量比Chinchilla扩展定律(译者注:Hoffmann等人(2022)重新审视了Kaplan等人的扩展定律。表明用较小的模型对更多数据进行训练可能更有效,从而产生了参数效率提高的70B参数模型Chinchilla)建议的token数量多得多,但不是所有人员都清楚扩展定律为何对模型训练有帮助,它能让我们确定可以训练出多小的模型以及需要多少额外的计算(资源)。
本篇博客将概述如何推导模型大小与计算(资源)额外开销之间的权衡(trade-off)关系,同时揭示了有办法在最小化额外开销的条件下可以大大缩减计算量最优模型的大小。然而,如果模型大小的缩减超出一定阈值,即使增加计算资源,也无法维持特定的模型性能,我们可以把这个模型的阈值称之为临界模型大小(critical model size)。
我的分析表明,临界模型大小大约降低到计算量最优模型大小的30%,而只增加了100%的额外计算开销。值得注意的是,近来的模型尚未达到这一点,例如训练了1T个token的LLaMa-7B模型,这表明训练“更小”的LLM仍有充足的空间,但需要延长训练时间。
1
回顾Chinchilla扩展定律
根据Chinchilla评估扩展定律的第三种方法,作者认为损失可以建模为参数数量和训练所用token数量的函数:
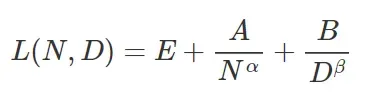
实验中,作者通过一系列不同的模型大小、训练token拟合了参数,并得出以下参数估值:
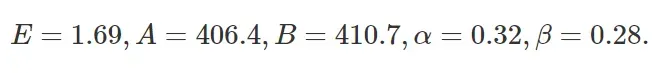
在计算(资源)预算的限制C=6ND下优化损失函数L,可以证明计算最优参数数量![]() 及计算最优token数量
及计算最优token数量![]()
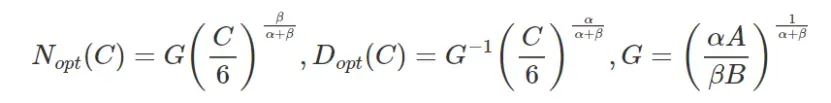
2
模型大小与计算(资源)额外开销
假设将最优模型大小缩小一半![]() ,需要增加多少训练token才能获得相同的性能?如果目标是保持相同的计算(资源)预算,显然必须增加一倍的训练token数量
,需要增加多少训练token才能获得相同的性能?如果目标是保持相同的计算(资源)预算,显然必须增加一倍的训练token数量![]() 才行,不过为了保持相同的模型性能,我们可以预期会增加一定的计算(资源)额外开销,也就是需要延长训练时间。
才行,不过为了保持相同的模型性能,我们可以预期会增加一定的计算(资源)额外开销,也就是需要延长训练时间。
现在,让我们回到Chinchilla的参数损失函数,再来回答这个问题。我们希望寻求一种方法,将参数按![]() 扩展,训练token按
扩展,训练token按![]() 扩展,同时使损失达到
扩展,同时使损失达到![]() 不变。准确来说,我们希望满足以下方程式:
不变。准确来说,我们希望满足以下方程式:
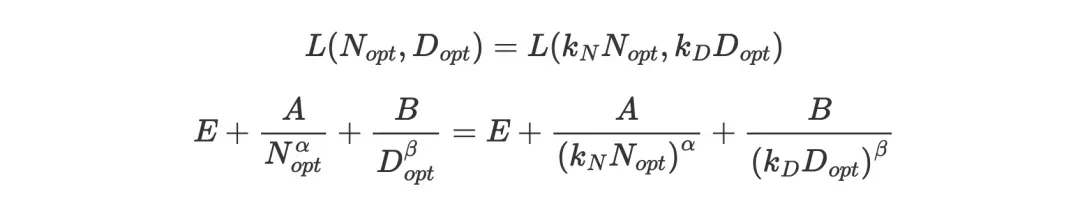
通过几个数学步骤,你会发现:
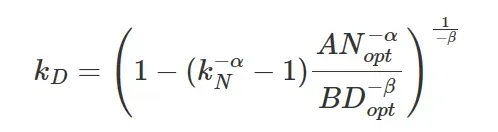
一旦确定了数据扩展因子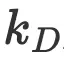 ,我们就能确定新的计算(资源)预算
,我们就能确定新的计算(资源)预算
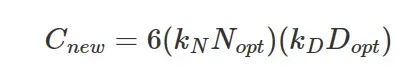
以及计算(资源)额外开销
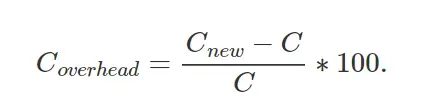
有意思的是,如图所示,数据扩展因子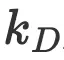 与计算预算C并无关联。因此,可以得出这一结论:模型大小与计算额外开销之间的权衡规律在所有计算预算下都一样。
与计算预算C并无关联。因此,可以得出这一结论:模型大小与计算额外开销之间的权衡规律在所有计算预算下都一样。
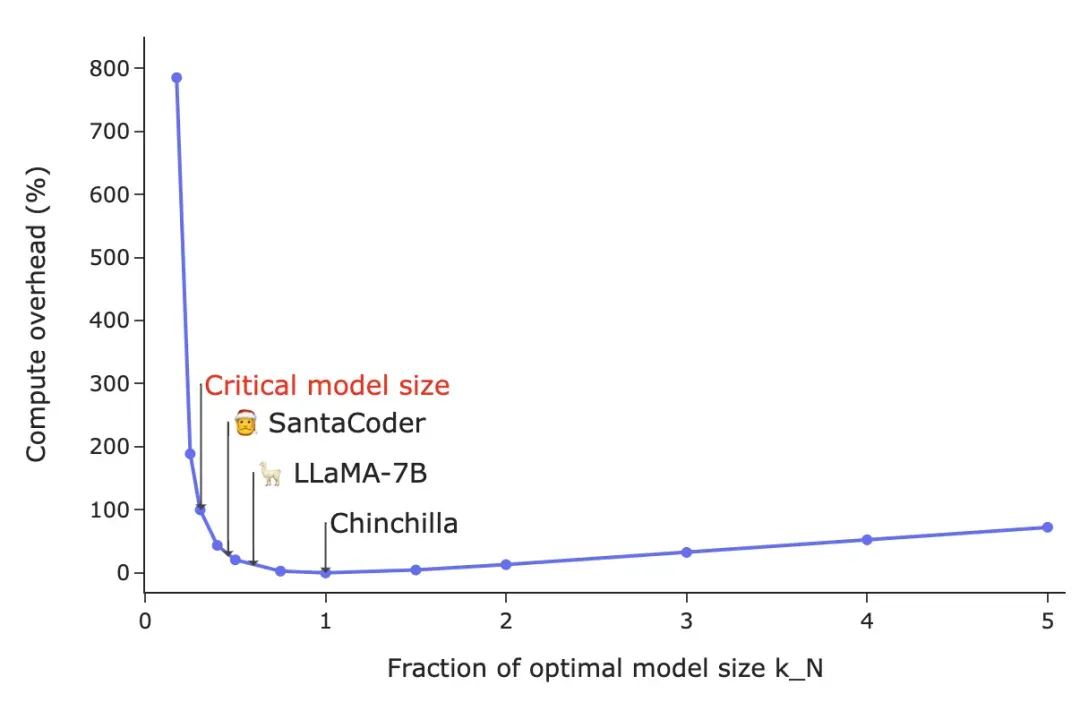
注意:原始扩展定律论文中的图12与该图表类似。
3
临界模型大小
如图所示,存在相当大的区间,在此范围内可以大大缩小最优模型大小,而几乎不怎么增加额外计算(资源)开销。训练一个相当于最优大小75%的模型,需增加的计算额外开销仅为2.8%,而训练最优模型大小一半大小的模型,额外开销则增加至20%。转向更小的模型,我们观察到这样一种渐近趋势:当![]() 时,额外计算开销会迅速增至188%。
时,额外计算开销会迅速增至188%。
如何确定我们在这条曲线上所处的位置取决于运行推理的频次。若从不运行推理,则应选择Chinchilla扩展规律来决定。若偶尔运行推理,则应选择稍小的模型。极限情况下(运行推理无限次),应选择尽可能最小的模型(即不考虑额外增加的计算开销)。
然而,在实践中,缩小模型的大小存在一个极限,该极限被称为临界模型大小(critical model size)。临界模型大小是指达到一定损失程度(loss level)所需的最小模型容量,几乎不可能在此基础上进一步缩小模型了。
据我分析,临界模型大小约为Chinchilla最优模型大小的30%,但这会增加100%的计算额外开销。请注意,临界模型大小并非一个硬性阈值,而应理解成一个收益递减的区域。如果我们不需要最小模型,就可以保守一点,选择占最优计算模型大小40-60%之间的模型,因为这样只会增加10-42%的计算额外开销。
4
LLaMA-7B和SantaCoder
最近有一些新模型(例如LLaMA-7B和SantaCoder),其训练时间比Chinchilla扩展定律建议的时间更长。那么换取更小模型所使用的计算资源是多少呢?
以LLaMA-7B为例:
-
该模型具有6.9B个参数和1000B个训练token,总计算资源预算为4.14e22 FLOP。
-
根据这一计算资源预算,最优计算模型的参数约为12.52B个,并在550B个token上进行训练。
-
我们可以查看哪个扩展因子
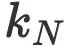 取多大值与LLaMA-7B的参数和训练token数量更为“接近”。我们发现,在
取多大值与LLaMA-7B的参数和训练token数量更为“接近”。我们发现,在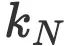 =0.57的情况下,可以得到一个具有7.13B个参数和1088B个训练token的合理配置。
=0.57的情况下,可以得到一个具有7.13B个参数和1088B个训练token的合理配置。 -
额外计算资源开销大约为12%。
再看SantaCoder:
-
该模型具有1.1B个参数和236B个训练token,总计算资源预算为1.56e21 FLOP。
-
根据计算资源预算,最优模型的参数约为2.79B个,并在93B个token上进行训练。
-
对于SantaCoder来说,要找到一个好的配置可能比较困难,但如果K=0.46,我们就可以在258B个token上训练参数为1.29B的模型。
-
额外计算资源开销约为24%。
相比LLaMA-7B,SantaCoder进一步减少了模型大小,根据Chinchilla扩展定律,这些模型可以进一步权衡计算,以获得更小的模型。
5
不同![]() 的训练token
的训练token
为了更好地了解哪些模型大小和训练 token 数量处于模型大小与计算权衡的合理范围内,我对Chinchilla论文中的A3表格作了更新,其中预测了![]() =0.5和
=0.5和![]() =0.3的情况。我只报告了第三种估计Chinchilla计算最优模型的方法,这种方法可以预测出最小的模型大小和最大的训练token数量。
=0.3的情况。我只报告了第三种估计Chinchilla计算最优模型的方法,这种方法可以预测出最小的模型大小和最大的训练token数量。
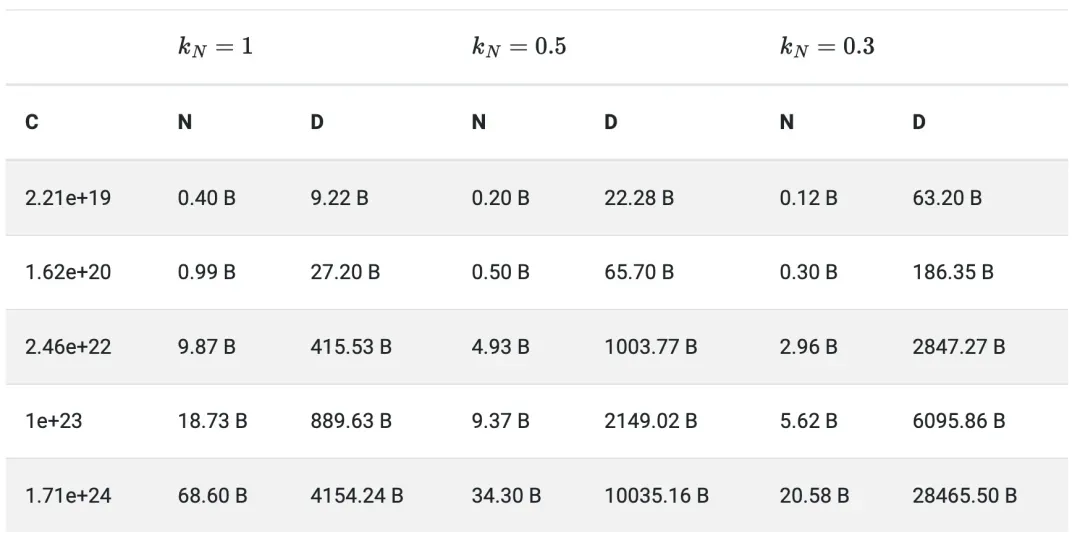
-
当
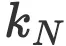 =0.5 时,建议在1万亿个token上训练参数为5B的模型,在10万亿个token上训练参数为34B的模型。
=0.5 时,建议在1万亿个token上训练参数为5B的模型,在10万亿个token上训练参数为34B的模型。 -
当
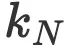 =0.3 时,建议在2.8万亿个token上训练参数为3B的模型,在28.4万亿个token上训练参数为21B的模型。
=0.3 时,建议在2.8万亿个token上训练参数为3B的模型,在28.4万亿个token上训练参数为21B的模型。 -
作者可能已经将论文中的
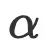 和
和 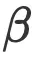 参数做了四舍五入。因此,我对这两个参数的值做了少许修改, 让
参数做了四舍五入。因此,我对这两个参数的值做了少许修改, 让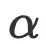 =0.036 、
=0.036 、 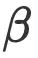 =0.283 ,以更好地适应表A3的扩展定律预测。其余参数保持不变A=406.4,B=410.7,E=1.62。
=0.283 ,以更好地适应表A3的扩展定律预测。其余参数保持不变A=406.4,B=410.7,E=1.62。 -
需要注意的是,Chinchilla系数取决于数据集,而我们不知道该数据集是什么。因此,结果可能会因为使用不同的训练数据而有所变化。
6
不足
1. Chinchilla扩展定律准确吗?它们对参数估计的微小变化(https://twitter.com/suchenzang/status/1616752482226671620)非常敏感,但没有考虑小模型长时间训练的情况。
2. 即使较小的模型达到相同的困惑度(perplexity),也无法确定它们是否具有相同的模型能力(例如Zero-shot prompt性能)。
3. 长时间训练较小的模型可能难以有效利用HPC集群上的有效并行化能力。
7
结论
根据Chinchilla扩展定律,我们还没有达到在更多token上训练更小模型的极限。鉴于开源人工智能社区的惊人创新速度,我预计功能强大的小型语言模型将很快出现!
附录
虽然数据扩展因子 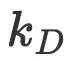 以计算最优参数
以计算最优参数 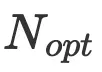 和训练token
和训练token 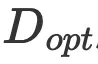 表示,在本部分,我将展示解决方案,该解决方案对计算预算C来说是固定不变的。首先
表示,在本部分,我将展示解决方案,该解决方案对计算预算C来说是固定不变的。首先
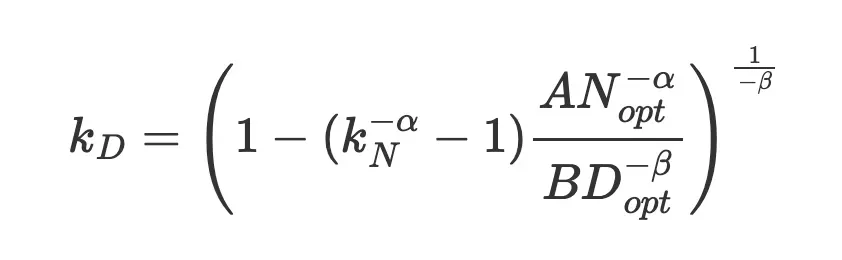
放大取决于计算预算C的部分:
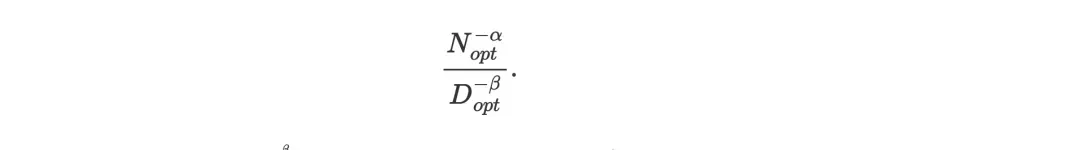
将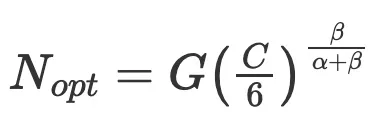 、
、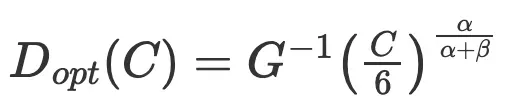 代入公式:
代入公式:
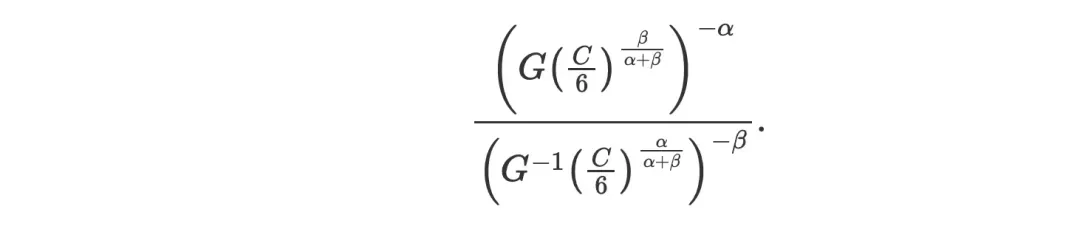
引入外部指数,可以消掉C
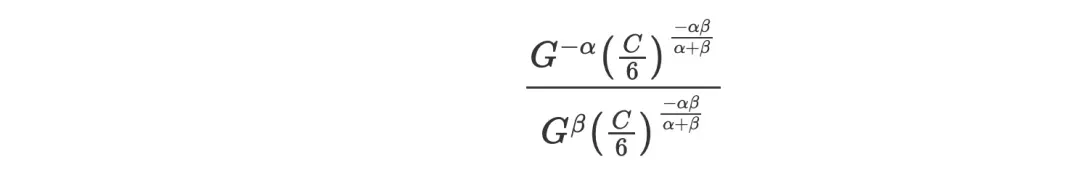
最终简化为: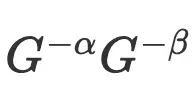 。
。
致谢
本文是BigCode 训练工作组的讨论分析结果。感谢所有参与人员,特别是:Raymond Li,Joel Lamy Poirier,Denis Kocetkov,Leandro von Werra,Loubna Ben Allal,Evgenii Zheltonozhskii,Niklas Muennighoff,Dzmitry Bahdanau和Thomas Wolf。感谢Leandro对文章标题的建议;感谢Niklas授权我们在推理运行频率方面使用他的解释来描述模型大小与计算额外开销曲线。
其他人都在看
欢迎Star、试用OneFlow: github.com/Oneflow-Inc/oneflow/![]() http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/
文章出处登录后可见!