Dilated Neighborhood Attention Transformer
Abstract
Transformers 迅速成为跨模态、领域和任务中应用最广泛的深度学习架构之一。在视觉领域,除了对普通Transformer的持续努力外,分层Transformer也因其性能和易于集成到现有框架中而受到重视。这些模型通常采用局部注意力机制,例如滑动窗口Neighborhood Attention(NA)或Swin Transformer的Shifted Window Self Attention。尽管在降低自注意力二次复杂性方面表现出色,但是局部注意力削弱了自注意力的两个最理想的属性:长程相互依赖建模和全局感受野。在本文中,我们引入了Dilated Neighborhood Attention(DiNA),这是对NA的一种自然、灵活且高效的扩展,可以在不增加额外成本的情况下捕获更多的全局上下文并指数级地扩展感受野。NA的局部注意力和DiNA的稀疏全局注意力相互补充,因此我们引入了Dilated Neighborhood Attention Transformer(DiNAT),这是一种结合了两者新的hierarchical vision transformer。DiNAT的变体在性能上显著优于NAT、Swin和ConvNeXt等strong baseline。我们的大型模型在COCO目标检测中比其Swin对应模型更快,box AP提高了1.6%,在COCO实例分割中,mask AP提高了1.4%,在ADE20K语义分割中,mIoU提高了1.4%。配合新框架,我们的大型变体成为了COCO(58.5 PQ)和ADE20K(49.4 PQ)上的最新技术水平的全景分割模型,以及Cityscapes(45.1 AP)和ADE20K(35.4 AP)上的实例分割模型(无额外数据)。它还与ADE20K上最先进的专业语义分割模型相匹配(58.1 mIoU),在Cityscapes上排名第二(84.5 mIoU)(无额外数据)。
//
“长程相互依赖建模” 指的是模型捕捉序列或空间排列中相距较远的元素之间关系或依赖的能力。在神经网络的背景下,实现长程相互依赖建模通常涉及允许信息在远距离元素之间交换的机制,使得模型能够考虑全局上下文和依赖关系。
“全局感受野” 涉及影响神经网络层中特定单元的输入数据的空间范围。较大的全局感受野意味着层中的每个单元都会考虑来自更广泛区域的信息。这对于捕捉远距离元素之间的关系并理解输入数据的整体结构至关重要。
总的来说,长程相互依赖建模和较大的全局感受野都是神经网络中期望具备的特性。这些特性使得模型能够有效捕捉长距离的依赖关系并考虑广泛的上下文,对于涉及理解整个输入数据的关系和结构的任务尤为重要。
1. Introduction
Transformers [42]在AI研究中取得了显著的贡献,首先在自然语言理解[12,34]方面取得成功,然后应用到其他模态,如语音[14]和视觉[13, 32],这要归功于它们建立在自注意力基础上的通用架构。这一成功激发了对基于注意力模型在视觉领域的研究,包括骨干网络[35, 41],以及更具体的应用,如图像生成和密度建模[6, 32]、目标检测[3]、图像分割[20, 43]等。
Vision Transformer(ViT)[13]是将transformers直接作为卷积神经网络(CNNs)[19, 22, 23]的替代品的首次重要演示之一,CNNs是视觉领域的事实标准。ViT将图像视为patch的序列,并使用普通的transformer编码器对图像进行编码和分类。它在大规模图像分类上表现出与CNNs竞争的性能,引发了对transformer架构作为CNNs竞争对手的视觉研究的激增[38, 39]。38:Deit 39:deep transformer
ViT(Vision Transformers)和卷积神经网络(CNNs)在架构和构建块方面不同,同时它们对待数据的方式也有所不同。卷积神经网络通常在通过模型时逐渐对输入进行降采样,并构建分层特征图。这种分层设计对于视觉任务至关重要,因为对象在尺度上有所变化,然而高分辨率的特征图对于密集任务(如分割)非常重要。另一方面,transformer以其整个模型保持固定的维度而闻名,因此,为了缓解自注意力的二次成本,标准的ViT从一开始就对输入进行强烈的降采样,这种保持固定维度的大幅度的降采样反过来阻碍了将标准的ViT应用为密集视觉任务的主干。
尽管关于将标准的ViTs应用于密集视觉任务的研究仍在继续进行 [17:MAE, 24],但关于hierarchical vision transformers的研究迅速占据主导地位 [29:swin transformer, 44] 并且持续增长 [15, 28]。(分层的vision transformer可以与分层的视觉框架进行轻松的集成。)这些分层transformer模型的一个关键优势是它们与现有的分层视觉框架轻松集成。受现有卷积神经网络的启发,hierarchical vision transformers由多个(通常为4个)级别的变换器编码器组成(例如:swin transformer),在其间有降采样模块,且初始降采样较少侵入性(即1/4而不是1/16)。如果在hierarchical vision transformers的较早层中使用无限制(全局的)的自注意力,则与输入分辨率相关,其复杂性和内存使用也会呈二次增长,使其在处理更高分辨率图像时变得难以处理。因此,hierarchical vision transformers通常采用特定的局部注意力机制。
hierarchical vision transformers
Swin Transformer [29],作为最早的hierarchical vision transformers之一,利用了窗口自注意力(WSA)模块,接着是像素平移的窗口自注意力(SWSA),这两者都将自注意力局限在不重叠的子窗口上。这降低了自注意力的成本,使得其时间和空间复杂性相对于分辨率呈线性关系。SWSA与WSA相同,SWSA会进行一个特征图像素的平移,之后是一个相反的平移。这对其性能至关重要,因为它允许窗口外的交互,从而扩大了其感受野。Swin的一个主要优势是效率,因为像素平移和窗口划分是相对廉价且易于并行化的操作。此外,它几乎不需要对自注意力模块进行任何更改,使得实现更容易。Swin已经成为多个视觉任务中的最新技术水平,并且后续推出了Swin-V2 [28] 以适应大规模的预训练。
后来引入了Neighborhood Attention Transformer (NAT) [15],采用了基于滑动窗口的简单注意力机制,即邻域注意力(NA)。与 Stand Alone Self Attention (SASA) [35] 不同,后者以卷积的方式应用注意力,NA将自注意力局限在每个token周围的最近邻域,这使得它在定义上可以接近自注意力并具有固定的注意力范围。像素级别的自注意力操作被认为效率低且难以并行化 [29, 35, 41],直到 Neighborhood Attention Extension [15] 的发布,。通过这个扩展,NA在实践中甚至可以比Swin的SWSA更快运行。NAT在图像分类方面能够显著优于Swin,并在下游任务中取得竞争性能,尽管架构略有不同,但Neighborhood Attention Extension的性能甚至比Swin更快。
//*说明NAT相较于swin transformer 的好处。基于局部自注意的hierarchical vision transformers 进行了不断的改进和发展,但是由于局部自注意破坏了全局感受野和建模长程依赖性的能力,最理想的情况是保持线性复杂性,同时保持自注意力的全局感受野和建模长程相互依赖的能力。在本文中,我们旨在回答这个问题,并通过将一种简单的局部注意力机制Neighborhood Attention,扩展为Dilated Neighborhood Attention(DiNA)来改进hierarchical vision transformers:稀疏全局注意力,将NA中的邻域扩张为更大的稀疏区域:
- 捕捉更多的全局上下文
- 使感受野乘指数级增长
- 不带来额外的计算成本
*//
尽管对于具有局部注意力的hierarchical vision transformers进行了努力,但由于局部自注意力的最重要属性:包括全局感受野和建模长程依赖性的能力会受到削弱。换句话说,最理想的情况是保持线性复杂性,同时保持自注意力的全局感受野和建模长程相互依赖的能力。在本文中,我们旨在回答这个问题,并通过将一种简单的局部注意力机制,Neighborhood Attention,扩展为Dilated Neighborhood Attention(DiNA)来改进hierarchical vision transformers:一种灵活而强大的稀疏全局注意力。将NA中的邻域扩张为更大的稀疏区域具有多重优势:1. 它捕捉更多的全局上下文,2. 感受野呈指数级增长,而不是线性增长[50],3. 不带来额外的计算成本。为了证明DiNA的有效性,我们提出了Dilated Neighborhood Attention Transformer(DiNAT),它不仅在下游性能方面改进了现有的NAT模型,而且在下游任务中以明显的优势超越了强大的现有的CNNbaseline,如ConvNeXt [30]。我们的主要贡献可以总结如下:
• 引入DiNA,一种简单而强大的稀疏全局注意力模式,允许感受野呈指数级增长,捕捉更长程的上下文,而不带来额外的计算负担。DiNA在保持NA引入的邻域对称性的同时实现了这一点。它还可以适应更大的分辨率,而无需扩展到更大的窗口大小。
• 在基于卷积、局部注意力和基于DiNA的模型的理论感受野大小方面进行分析。
• 引入DiNAT,一个由NA的扩张和非扩张变体组成的新的hierarchical vision transformers。DiNAT通过模型进行逐渐扩张变化,这更优化地扩展了感受野,并有助于进行从细到粗的特征学习。
• 对DiNAT进行广泛的图像分类、目标检测和分割实验,发现它在下游任务中相对于基于注意力和卷积的baseline表现出明显的改进。此外,我们研究了各向同性和混合注意力变体,使用ImageNet-22K预训练进行的缩放实验,以及不同扩张因子的影响。我们还在先进的分割框架中取得了最先进的图像分割性能。
• 通过添加对扩张的支持和bfloat16的利用,扩展了NA的PyTorch CUDA扩展NAT-TEN,使得这个方向的研究可以扩展到其他任务和应用中。
虽然使用DiNAT的初步实验已经在下游视觉任务中展示出显著的改进,但其性能和应用并未止步于此。NA的局部注意力和DiNA的稀疏全局注意力相互补充:它们可以保留局部性,建模更长程的相互依赖关系,指数级地扩展感受野,并保持线性复杂性。NA的局部注意力和DiNA的稀疏全局注意力对自注意力的限制可以潜在地避免自注意力可能的冗余交互,比如与重复、背景或分散注意力的token的交互 [26, 36],从而提高收敛性。局部注意力和稀疏全局注意力的组合可以潜在地增强各种视觉任务及其他任务的能力。为了支持在这个方向上的研究,我们开源了整个项目,包括我们修改过的NAT-TEN,相对于naive实现,它可以将运行时减少数个数量级 [15]。
2. Related Work
我们简要回顾一下点积自注意力(DPSA),Transformer [42]和Vision Transformer [13]。然后我们转向局部自注意模块,如Stand Alone Self Attention /SASA [35],Swin Transformer中的SWSA [29],以及Neighborhood Attention Transformer中的NA [15],并讨论它们的局限性,这是我们进行这项工作的动机。最后,我们讨论了在语言处理 [1, 37] 和视觉 [6, 20] 中以前使用的稀疏注意机制。
2.1. Self Attention
Self attention的定义: 将点积注意力定义为查询与一组键-值对之间的操作。查询和键的点积被缩放,并通过softmax激活送入,产生注意力权重。然后,这些注意力权重被应用于值。
Vaswani等人[42]将点积注意力定义为查询与一组键-值对之间的操作。查询和键的点积被缩放,并通过softmax激活送入,产生注意力权重。然后,这些注意力权重被应用于值:
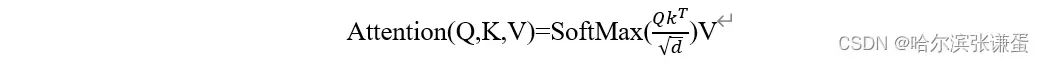
在上述公式中,√d 是缩放参数,d 是键的维度。点积自注意力简单地是这个操作的一种情况,其中查询、键和值都是相同输入的线性投影。给定一个输入X ∈ Rn×d,其中n是token的数量,d是嵌入维度,这个操作的复杂度为O(n2d),注意力权重的空间复杂度为O(n2)(空间复杂度取决于实现 [10])。Vision Transformer(ViT)[13]是最早将纯Transformer编码器应用于视觉的研究之一,展示了基于大规模自注意力模型的强大能力。后续研究通过对训练技术的最小更改 [38]、架构变更 [39] 和对小数据情境的应用 [16] 扩展了这项研究。由于其二次时间复杂性,许多研究尝试限制注意力跨度以减少计算量,特别是在扩展到更大输入时,如NLP中的长文档 [1] 和视觉中的大分辨率 [29]。限制自注意力可以通过不同的模式进行,其中一种是局部化。
2.2. Local Attention
Stand-Alone Self Attention (SASA): SASA [35]是最早专门设计用于视觉模型的局部注意机制之一,比ViT [13]早了数年。它将query-key对设置为在特征图上滑动的窗口,因此将每个查询(像素)的注意力局限在以其为中心的窗口中。这样的操作可以很容易地替代现有CNN中的卷积,例如ResNets,理论上甚至可以减少计算复杂性。尽管它显示出了潜在的效果,但由于该模块的低效实现,作者发现生成的模型运行速度较慢。因此,随后的研究转而采用能够更高效运行的替代方法,如HaloNet中的块自注意 [41] 和Swin中的Window Self Attention。
Shifted Window Self Attention (SWSA): 刘等人 [29] 提出了窗口自注意(WSA)及其平移变体SWSA,并在他们的分层视觉模型Swin Transformer中使用它们。他们指出了像SASA这样的滑动窗口方法的低效性是发展窗口自注意的动机之一。平移变体(SWSA)顾名思义,在进行注意力操作之前将像素进行平移,然后在之后进行逆平移,以创建与前一层不同的窗口划分,这允许窗口外的交互对于不断扩大的感受野至关重要(见图3)。Swin最初成为目标检测和语义分割领域的最先进技术。它还启发了其他将其扩展到文中未探讨的不同任务的工作,如生成 [52]、恢复 [25]、遮蔽图像建模 [(SiMMIM)49]、视频动作识别 [31] 等等。此外,后续模型Swin-V2 [28] 成为了最新技术水平,其最大型号取得了这样的性能。值得注意的是,Swin-V2使用了更大的窗口尺寸来实现这样的性能,这反过来增加了时间复杂性和内存使用。
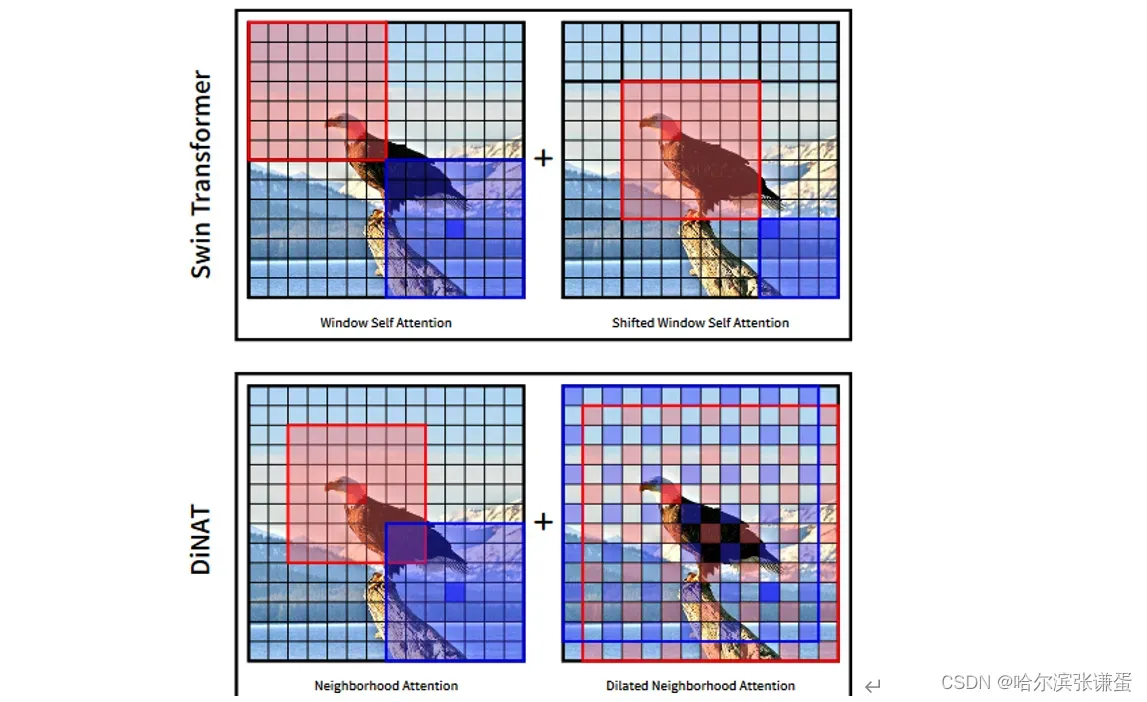
图3。Swin Transformer和DiNAT中的注意力层的示意图。Swin将输入分成非重叠的窗口,并分别对每个窗口应用自注意力,在每个其他层上进行像素移位。像素移位的层掩盖了不按顺序的区域之间的注意力权重,这将自注意力限制在移位的子窗口内。DiNAT应用Neighborhood Attention,一种滑动窗口注意力,并在每个其他层上进行扩张。
Neighborhood Attention (NA): NA [15] 被提出作为一种简单的滑动窗口注意力,将每个像素的自注意力局限在其最近的邻居。NA与Swin的WSA和SWSA相比,具有相同的时间和空间复杂性以及参数数量,但是它在重叠的滑动窗口中操作,因此保留了平移等变性。虽然NA的滑动窗口模式与SASA相似,但其对最近邻的制定使其成为自注意力的直接约束,因此与SASA不同,随着窗口大小的增长,NA逐渐接近自注意力。滑动窗口注意力的一个主要挑战是缺乏高效的实现,因为目前不存在深度学习或CUDA库直接支持这种操作。因此,NA随附了NATEN,这是一个具有高效CPU和GPU内核的扩展,使得NA在速度和内存使用方面都能胜过诸如WSA/SWSA之类的模块。模型Neighborhood Attention Transformer (NAT) 在其分层设计上与Swin Transformer相似。除了注意力模块之外,NAT在下采样层中使用了重叠卷积,而不是Swin中使用的分块卷积。因此,为了保持与Swin变体在参数数量和FLOPs方面的相似性,模型被稍微加深,采用较小的反转瓶颈。NAT在图像分类方面取得了优越的结果,表现在下游任务中也具有竞争力。
尽管基于局部注意力的模型由于其保留局部性和高效性而能够在不同的视觉任务中表现良好,但它们在捕捉像自注意力这样对于视觉至关重要的全局上下文方面表现不足。此外,与自注意力中的全尺寸感受野相比,局部化注意力机制利用更小且增长较慢的感受野,类似于卷积。除了自注意力之外,一些工作还探讨了视觉中的全局感受野,包括但不限于非局部神经网络 [45]。然而,具有无限制全局感受野的操作通常与局部或稀疏感受野相比,计算复杂性较高。
2.3. Sparse Attention
Child等人[6]提出了Sparse Transformers,除了扩展到更深的变体外,还利用了一种稀疏内核的注意力机制。通过这种方式,模型能够更高效地训练更长的数据序列。在稀疏注意力方面还有其他一些研究,例如Longformer [1]、Routing Transformers [37]和CCNet [20],它们都共享一个共同特征:在不可避免地需要处理更长token序列的情况下,减少自注意力的成本,同时仍然需要全局上下文。Longformer [1]专门研究了使用1-D滑动窗口注意力与和不带扩张的组合,以及特定token的全局注意力。这导致了一个能够处理长文档并保持全局上下文的模型。CCNet [20]使用轴向注意力改进语义分割头部,引入全局上下文,避免了不受限制的自注意力的二次成本。最近,MaxViT [40]探索了一种混合模型,它结合了MBConv、Window Attention [29]和稀疏网格注意力,取得了较高的ImageNet准确性。然而,与Swin [29]相比,由此产生的模型具有更高的复杂性和较低的吞吐量。
非局部(全局)和稀疏自注意力的idea表现出了很大的潜力,但在hierarchical vision transformer的范围内,它们尚未得到充分研究。为了扩展局部感受野并将全局上下文重新引入hierarchical vision transformer,我们引入了Dilated Neighborhood Attention(DiNA),这是NA的扩展,通过增加步长跨越更长的范围,同时保持总体注意力跨度。DiNA可以作为一种稀疏和全局的操作,在与NA作为仅局部操作一起使用时效果最佳。我们在图4中提供了感受野的示例,其中我们将全连接层与卷积和扩张卷积进行比较,类似地将自注意力与NA和DiNA进行比较。我们通过我们的hierarchical vision transformer Dilated Neighborhood Attention Transformer(DiNAT)为这一说法提供了实证证据。
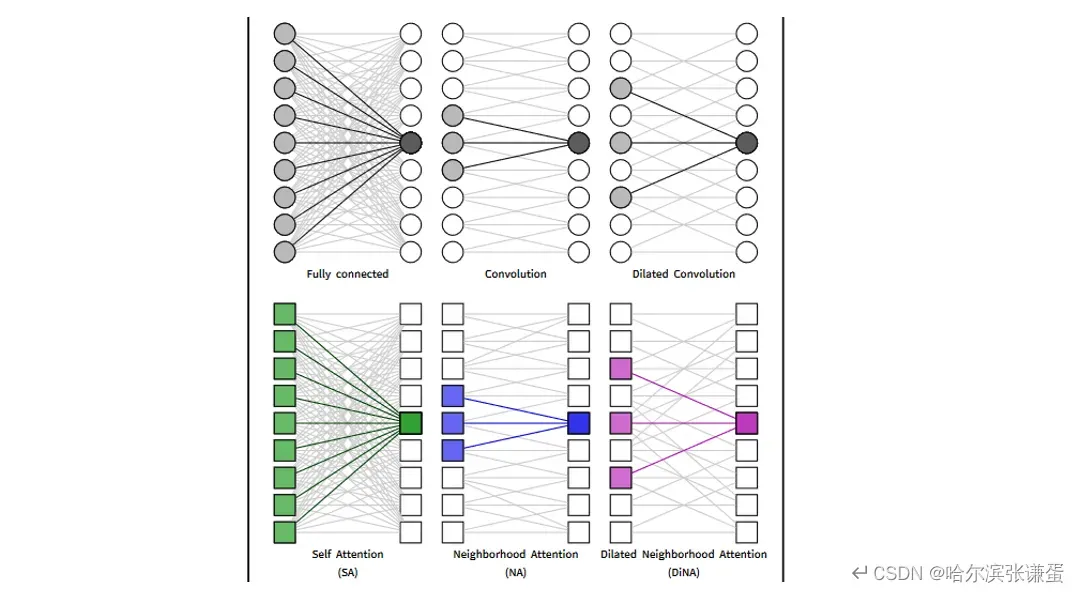
图4。在全连接层、卷积层和不同的注意机制中,对感受野的单维度示意图。NA和DiNA通过滑动窗口限制自注意力,类似于卷积和扩张卷积如何限制全连接层。这些限制减少了计算负担,引入了有用的归纳偏差,并在某些情况下增加了对不同输入尺寸的灵活性。
3. Method
在这一部分,我们将DiNA定义为对NA的扩展,分析它对感受野的影响,然后转向我们的模型DiNAT。我们还简要介绍了实现的细节,并与现有的NAT-TEN包进行了集成。
3.1. Dilated Neighborhood Attention
为简单起见,我们将符号限制在一维NA和DiNA。给定输入X ∈ Rn×d,其行是d维token向量,以及X的query和key线性投影,Q和K,以及任意两个token i和j之间的相对位置偏差B(i, j),我们定义了第i个token的邻域注意力权重,记作Aik,它是第i个token的query投影与其k个最近邻token的k投影的矩阵乘法:
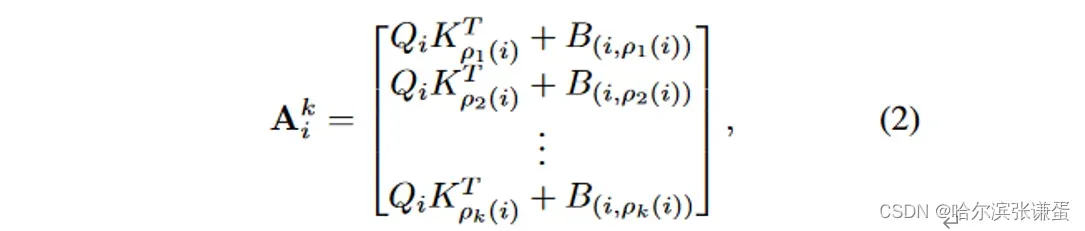
其中,ρj(i)表示i的第j个最近邻。类似地,我们定义邻近value Vki,作为矩阵,其行是第i个token的k个最近邻value投影:
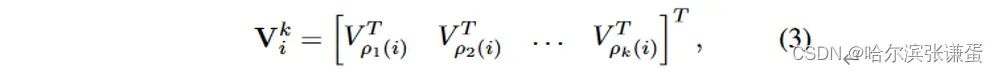
其中,V是X的线性投影。第i个token的邻域注意力输出,具有邻域大小k,然后被定义为:
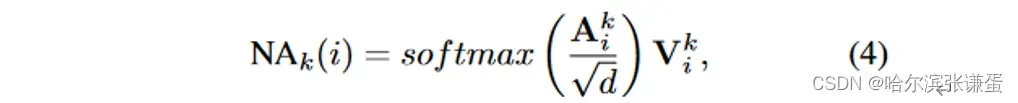
其中,√d是缩放参数,d是嵌入维度。为了将此定义扩展到DiNA,给定一个扩张因子δ,我们简单地将ρjδ(i)定义为token i的第j个最近邻,满足条件:j mod δ = i mod δ。然后,我们可以定义第i个token的具有邻域大小k的δ扩张邻域注意力权重A(k,δ)i,如下所示:
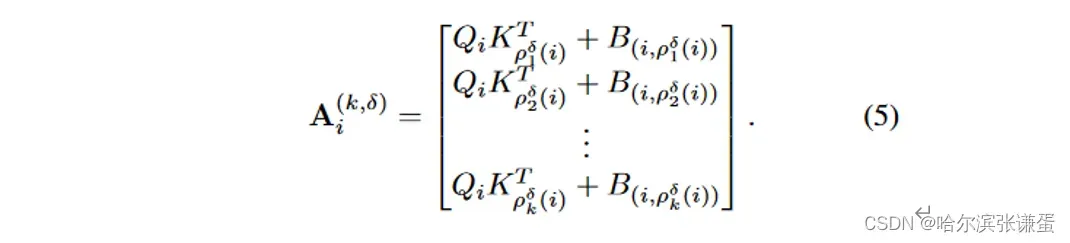
我们类似地定义第i个令牌的具有邻域大小k的δ扩张邻近值,记作V(k,δ)i
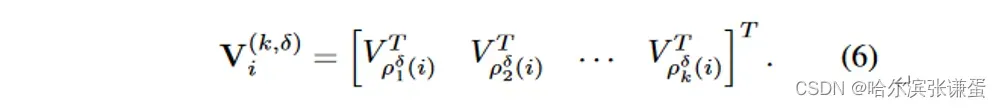
第i个token邻域大小k的DiNA输出定义为:
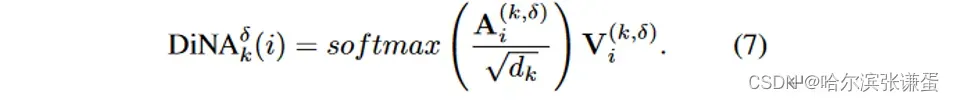
3.2. Choice of Dilation
DiNA引入了一个重要的新的架构超参数:每层扩张因子。我们定义了扩张因子的上限为n/k向下取整,其中n是token的数量,k是内核/邻域大小。这仅仅是为了确保每个token都有恰好k个扩张邻居。下限始终为1,这相当于普通的NA。因此,模型每层的扩张因子将是一个依赖于输入的超参数,可以取任何整数δ ∈ [1, n/k向下取整]。由于扩张因子是可变的,它们提供了一个灵活的感受野(在第3.3节中讨论)。尝试所有可能的组合是不可行的,因此我们探索了有限数量的选择,这些选择在第4.4节中讨论。
3.3. Receptive Fields
我们分析了DiNA的感受野,这对于理解DiNA的能力特别重要,尤其是与其他模型进行比较。我们在表1中对不同注意力模式下的感受野大小进行了比较,同时还包括了FLOPs和内存使用情况。为了完整起见,我们还包括了ConvNeXt [30]中的关键组件深度可分离卷积(DWSConv)。我们根据层数L,内核大小k和token数量n计算感受野的大小。卷积和NA都以大小为k的感受野开始,并且每层扩大k−1(中心像素保持固定)。Swin Transformer的Window Self Attention [29]本身保持恒定的感受野大小,因为窗口分区阻止了窗口间的交互,因此阻止了感受野的扩展。像素偏移的SWSA解决了这个问题,并且每层扩大一个窗口,即每层扩大k。
值得注意的是,尽管Swin的感受野比NAT和ConvNeXt略大,这要归功于其特殊的偏移窗口设计,但它破坏了一个重要的属性:对称性。由于Swin的特征图被分成不重叠的窗口,同一窗口内的像素只与彼此关注,而不考虑它们的位置(无论是在中心还是在角落),导致一些像素看到它们周围的上下文不对称。与NAT、Swin和ConvNeXt中固定的感受野增长不同,DiNA的感受野是灵活的,并且随着扩张而变化。它的范围可以从NAT的原始L(k−1)+1(所有扩张因子均设置为1)到呈指数增长的kL(逐渐增加扩张),这是其强大性的主要原因之一。无论扩张如何,第一层始终产生大小为k的感受野(DiNA)。给定足够大的扩张因子,前面的DiNA层将为DiNA层中的每个k产生一个大小为k的感受野(NA),从而产生大小为k2的感受野。因此,具有最佳扩张因子的DiNA和NA组合有可能将感受野的增长呈指数级提高到kL。这并不令人惊讶,因为已知当使用指数增长的扩张因子时,扩张卷积的感受野大小也会呈指数增长[50]。图5中还展示了增加的感受野大小的示意图。
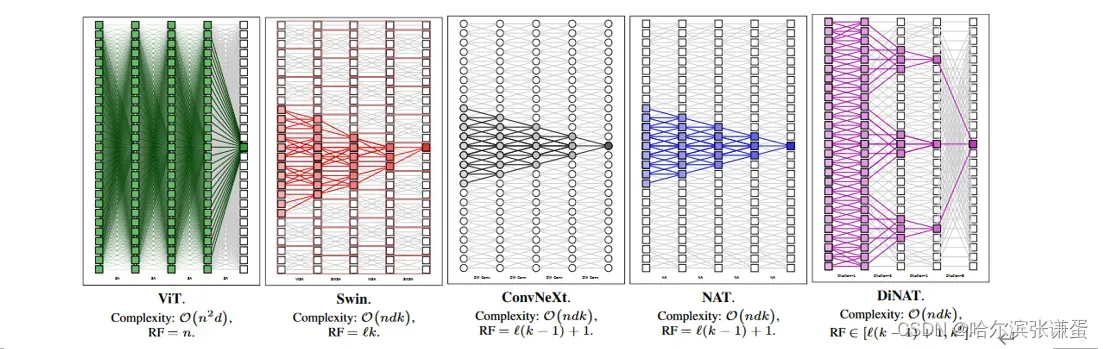
图5. ViT、Swin、ConvNeXt、NAT和我们的DiNAT中的感受野。我们还提供了每种方法主要操作的复杂性。n表示token的数量,d表示嵌入维度,k表示内核/窗口大小。所有感受野都受到输入大小n的限制。DiNAT的感受野是灵活的,范围从线性的L(k−1)+1,到指数增长的Lk。
3.4. DiNAT

为了公平评估DiNA的性能,我们设计DiNAT的体系结构和配置与原始的NAT模型完全相同。它最初使用两个2×2步幅的3×3卷积层,导致特征图的分辨率为输入分辨率的四分之一。它还在级别之间使用一个2×2步幅的单个3×3卷积进行下采样,将空间分辨率减半并将通道加倍。详细信息见表2。DiNAT的关键区别在于每隔一个层次使用DiNA而不是NA。DiNA层的扩张因子根据任务和输入分辨率进行设置。对于2242分辨率的ImageNet-1k,我们分别将扩张因子从stage1到stage4分别设置为8、4、2和1。在下游任务中,由于它们具有更大的分辨率,我们将扩张因子增加到更大的值。所有扩张因子和其他相关的体系结构细节见表II。
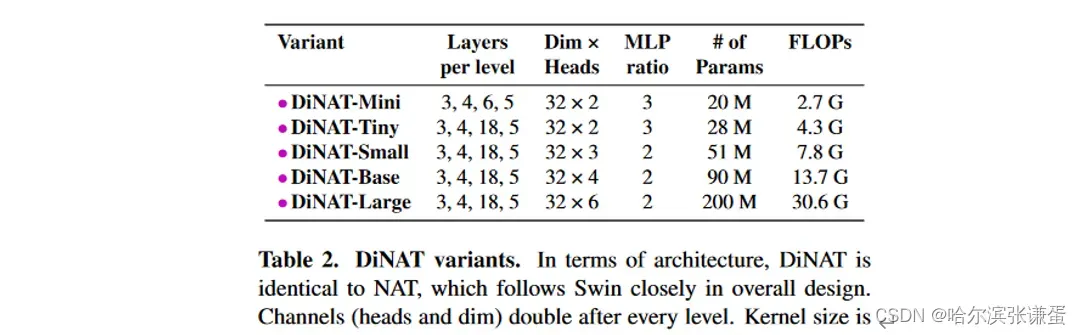
表2. DiNAT变体。在体系结构方面,DiNAT与NAT相同,其整体设计紧随Swin。通道(头部和维度)在每个级别之后加倍。在所有变体中,内核大小为7。
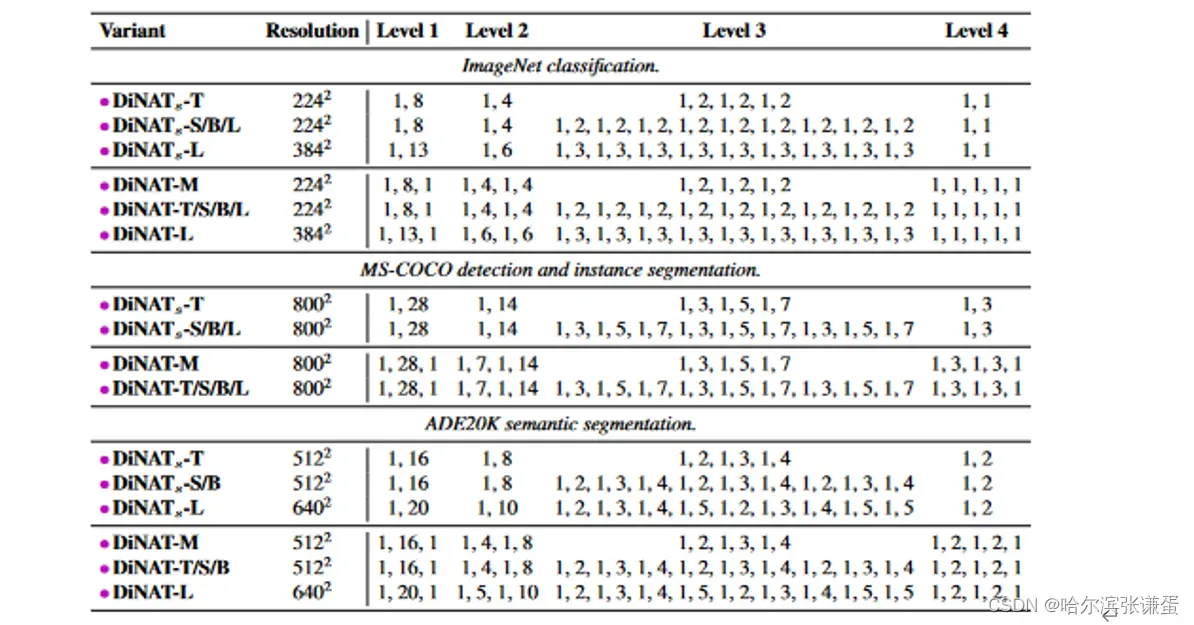
表II. 扩张因子。由于ImageNet的输入分辨率相对较小,stage 4的层不能超过扩张因子1,这相当于NA。还请注意,在224×224分辨率下,stage 4的输入将恰好为7×7,因此NA将等同于自注意力。这在分辨率明显更高的下游任务中并非如此,其中stage 2和stage 3具有逐渐增加的扩张因子,这在更深的模型中重复。这对应于表9中标有“Gradual”的突出显示行。这些配置适用于所有下游实验(不包括第4.4节中的实验)。
3.5. Implementation
我们在现有的Neighborhood Attention Extension (N ATTEN)基础上实现了DiNA,使其易于使用并且在内存使用上与NA相同。扩展的最新公共版本包括更高效的“平铺”实现,这是它在速度上可以与Swin等方法竞争的原因。通过向所有现有的CUDA核添加一个扩张元素,并重新实现“平铺”核以支持扩张内存格式,我们成功地实现了DiNA,而不影响现有NA核的速度。然而,应注意DiNA的吞吐量将取决于扩张因子,并且在实践中预计会略慢于NA。这仅仅是由于内存访问模式的中断,这将总体上影响吞吐量(见图Ia)。我们还注意到,这些实现仍然相当简单 ,并且没有充分利用CUDA中的新架构标准,例如Tensor Cores,因此只能作为概念验证。尽管存在这个限制,使用NA和DiNA的模型在吞吐量水平上可以与主要利用卷积、线性投影和自注意力的其他方法竞争,所有这些方法都通过充分利用前述标准的NVIDIA库运行。有关实现的更多信息,请参见附录A。
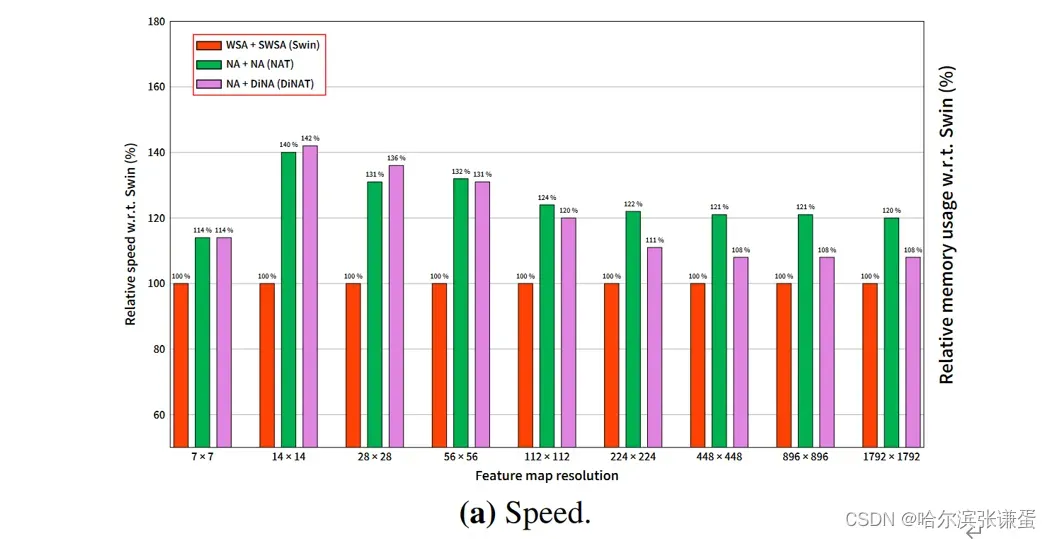
图I. 相对于Swin,基于NAT和DiNAT的层级相对速度和内存比较。具有相同核大小的NAT层,即仅由两个连续的kernel大小为72的NA层组成的层,已经比具有相同kernel大小的Swin层快多达40%。由NA层后跟DiNA层组成的DiNAT层,由于在内存访问模式中的中断,实际上稍慢于NAT层,但仍然比Swin层快。
4. Experiments
我们进行了广泛的实验来研究我们提出的DiNAT模型对现有基线的影响。与现有方法类似,我们在图像分类(ImageNet-1K和ImageNet-22K [11])上对模型进行预训练,然后将学到的权重迁移到下游视觉任务。我们将DiNAT与原始NAT模型[15]、Swin [29]和ConvNeXt [30]进行比较。我们还将我们的模型与Mask2Former [5]搭配,并进行实例、语义和全景分割实验。
4.1. Image Classification
我们使用了 PyTorch 中的 ImageNet 训练的社区标准工具 timm [46](Apache License v2),该工具现在已经成为 PyTorch 中 ImageNet 训练的社区标准 [33],用于在 ImageNet-1k [11] 上训练我们的模型。我们采用了与 NAT [15] 和 Swin [29] 中使用的相同的训练配置、正则化技术和数据增强方法(CutMix [51]、Mixup [53]、RandAugment [9] 和 Random Erasing [54])。直接在 ImageNet-1K 上训练的模型进行了 300 个 epoch 的训练,批量大小为 1024,采用迭代余弦学习率调度和 20 个 epoch 的热身,基础学习率为 1e-3,权重衰减率为 0.05,并在额外的 10 个 epoch 中进行冷却。较大的模型变种在 ImageNet-22K [11] 上进行了 90 个 epoch 的预训练,批量大小为 4096,但采用线性学习率调度和 5 个 epoch 的热身,基础学习率为 1e-3,权重衰减率为 0.01,同样遵循 Swin [29] 的设置。我们对在 ImageNet-22K 上进行预训练的模型进行了 30 个 epoch 的微调,批量大小为 512,采用线性学习率调度,没有热身,基础学习率为 5e-5,权重衰减率为 1e-4。Tabs. 3 和 4 提供了最终的 ImageNet-1K 验证集准确性水平,以及可学习参数数量、FLOPs、吞吐量和内存使用情况。提供 FLOPs 和吞吐量的原因在于指出区分理论计算需求与每种方法的实际效率之间的必要性,每种方法的可用实现都有各自的优劣。这在这种情况下尤为重要,因为 NA 和 DiNA 基于从头实现的算法(N AT T EN),并且不像 ConvNeXt 或 Swin 那样经过优化,后者主要运行在为最佳吞吐量设计的原生 NVIDIA 库上。
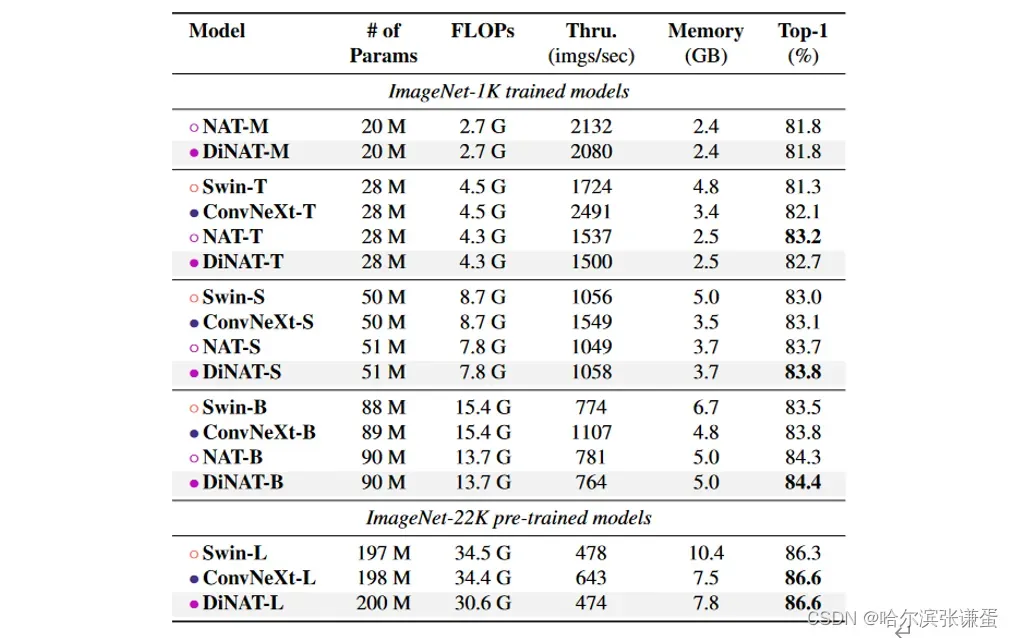
表3。2242分辨率下的ImageNet-1K图像分类性能。吞吐量和峰值内存使用量是从单个NVIDIA A100 GPU上批量大小为256的前向传递中测量的。
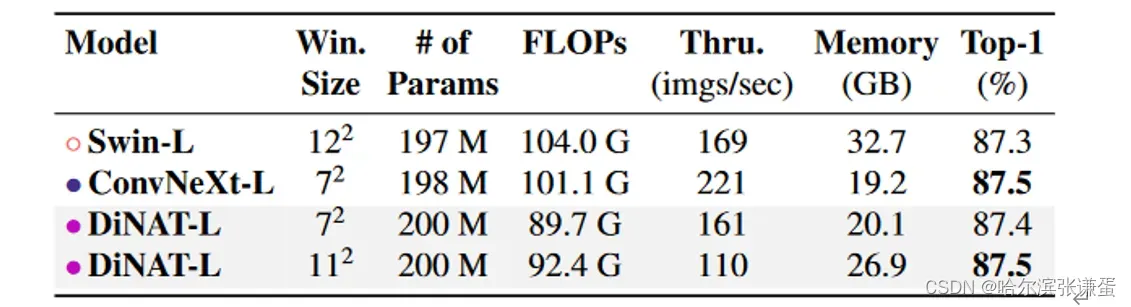
表4。3842分辨率下的ImageNet-1K图像分类性能。吞吐量和峰值内存使用量是从单个NVIDIA A100 GPU上批量大小为256的前向传递中测量的。
ImageNet-1K。在较小的变体上,DiNAT在NAT上没有显示出改进。与NAT-Mini相比,对NAT的改进小于0.1%,而我们发现尽管Tiny变体在开始时收敛速度比NAT-Tiny快,但它的准确性收敛到了82.7%。我们注意到,尽管如此,DiNAT在所有四个变体中在下游任务上始终优于NAT。 DiNAT在Small和Base变体上的改进至少为0.1%。
ImageNet-22K。我们在ImageNet-22K上预训练了我们的Large变体,并将其微调为ImageNet-1K,分别为2242和3842分辨率。我们发现我们的大型变体可以在2242分辨率下成功胜过Swin-Large,并与ConvNeXt-Large的准确性相匹配。在3842上,我们的大变体在不增加其内核大小(从72增加到122)的情况下超过了Swin对应的报告准确性。增加大变体的内核大小到112并插值位置偏差后,我们看到我们的大变体也与ConvNeXt-Large的准确性相匹配。我们注意到NA / DiNA在理论上限于奇数内核大小,这是选择112而不是122的原因。
各向同性变体。为了进一步比较 NA/DiNA 与普通自注意力的差异,我们还探索了 NAT 和 DiNAT 的各向同性变体,类似于各向同性 ConvNeXt [30] 的变体。这些模型设计上简单地遵循 ViT:在具有固定空间尺寸(142)的特征图上运行的单个 Transformer 编码器,前面有一个单独的块和嵌入层;它们不是分层变压器。为了保持与自注意力的公平比较,我们训练了带有相对位置偏差的 ViT 模型(ViT+),以确保模型只在注意力模式上存在差异。请注意,已经在 timm [46] 中探索了带有相对位置偏差的 ViT 变体,但我们进行了自己的运行以确保相似的训练设置。我们在Tab. 5中对这些模型及其在 ImageNet-1k 上的性能进行了比较。我们发现,NAT 和 DiNAT 的各向同性变体在吞吐量上只有轻微的改进,这可以归因于缺乏完全优化的实现。这些变体将 FLOPs 减少到与各向同性 ConvNeXt 变体几乎相同的数量。与 ViT+ 相比,它们还显着减少了内存使用。至于性能,我们观察到各向同性 NAT 变体相对于 ViT+ 会导致性能下降,这是预料之中的,因为NAT的注意力跨度是 ViT+ 的一半。然而,我们发现各向同性 DiNAT 变体显著改进了 NAT 的各向同性变体,而不增加核大小。这进一步支持我们的论点,即将 NA 和 DiNA 结合起来更有效地产生替代自注意力的模型,而不仅仅在整个模型中使用 NA。为了进一步研究不同注意力机制的影响,并探讨一个完全基于自注意力的模型是否总是产生最佳结果,我们尝试使用既包含 NA/DiNA 层又包含自注意力层的混合各向同性模型。我们在 Tab. 6 中展示了这些结果。我们发现,一个小规模(22M 参数)的模型,仅有一半的层执行自注意力,而另一半执行邻域注意力,可以达到与所有 12 层使用自注意力的类似模型相似的准确性。我们还发现,更改不同注意力层的顺序可能导致准确性的约 0.2% 的变化。
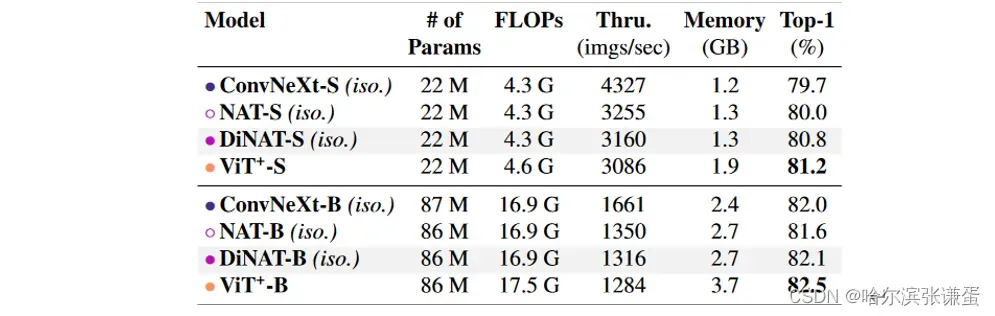
表5. ConvNeXt、NAT 和 DiNAT 同向变体与 ViT 的 ImageNet-1K Top-1 验证准确性比较。为了公平比较自注意力和 NA/DiNA,我们运行了 ViT+,它在注意力层中使用相对位置偏差,而不是原始 ViT 中的一次性绝对位置编码。吞吐量和内存使用峰值是在单个 NVIDIA A100 GPU 上使用批量大小为 256 的前向传递中测量的。
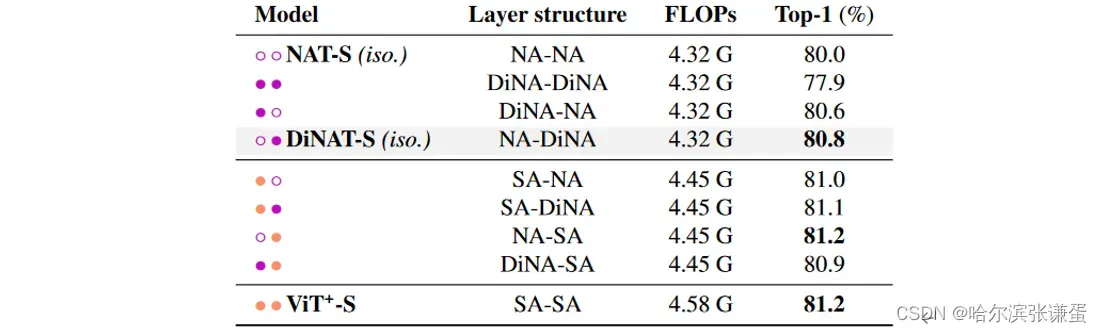
表6. 同向变体中不同层结构的比较。我们通过创建混合模型,同时使用 SA 和 NA/DiNA,详细比较了不同的注意机制。
4.2. Object Detection and Instance Segmentation
为了探讨 DiNAT 在目标检测和实例分割中的有效性,我们使用其预训练权重作为 Mask R-CNN [18] 和 Cascade Mask R-CNN [2] 的骨干,并在 MS-COCO [27] 上训练这些模型。
我们遵循了 NAT [15] 和 Swin [29] 在 mmdetection [4] 中的训练设置(Apache 许可证 v2),并采用了相同的加速 3× 学习率计划。结果显示在表 7 中。我们观察到 DiNAT 在吞吐量上持续显示出明显的改进,几乎没有吞吐量的下降。甚至在某些情况下,DiNAT 甚至超过了 NAT 的吞吐量,但在误差范围内。此外,我们观察到相对于 NAT,这种改进使 DiNAT 在规模上超越了 ConvNeXt [30]。
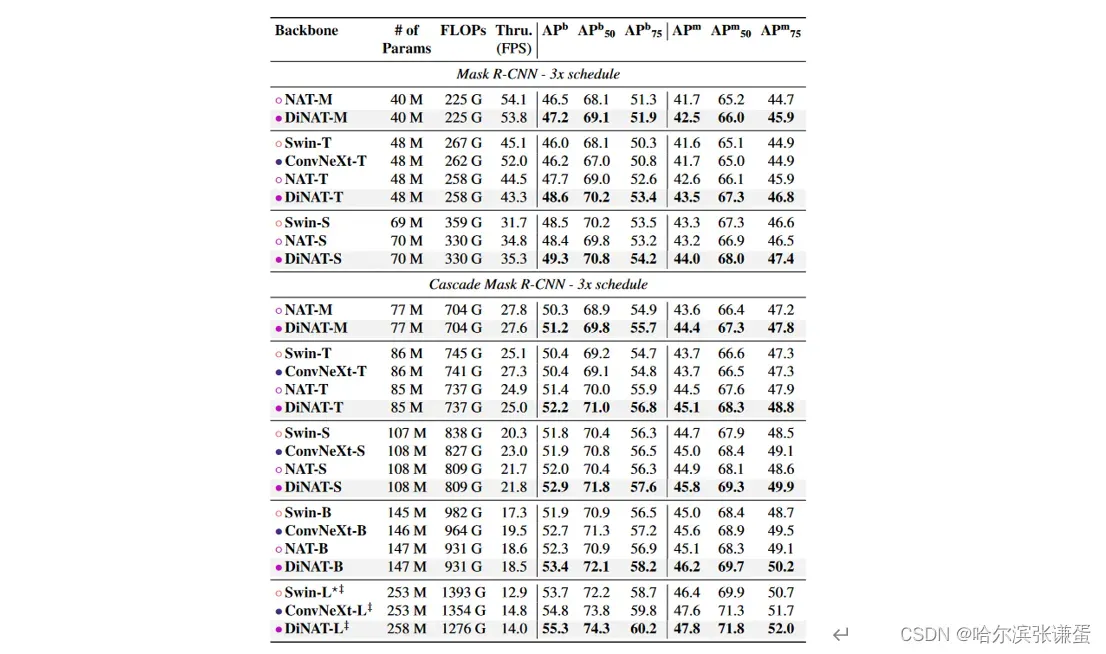
表7. COCO 目标检测和实例分割性能。 ‡ 表示该模型在 ImageNet-22K 上进行了预训练。 ? Swin-L 在级联掩膜 R-CNN 中没有报告,因此我们使用了官方的检查点进行训练。吞吐量是在一块 NVIDIA A100 GPU 上测得的。
4.3. Semantic Segmentation
我们还使用 DiNAT 作为 ADE20K [55] 上 UPerNet [48] 的骨干进行了训练,采用了 ImageNet 预训练的骨干。我们遵循 NAT 的 mmsegmentation [7](Apache 许可证 v2)配置,该配置本身遵循 Swin 在训练 ADE20K 时的配置。结果显示在表 8 中。我们发现 DiNAT 相对于原始 NAT 模型表现出明显的改进。DiNAT 在采用 ImageNet-22K 预训练的规模上仍然保持领先。
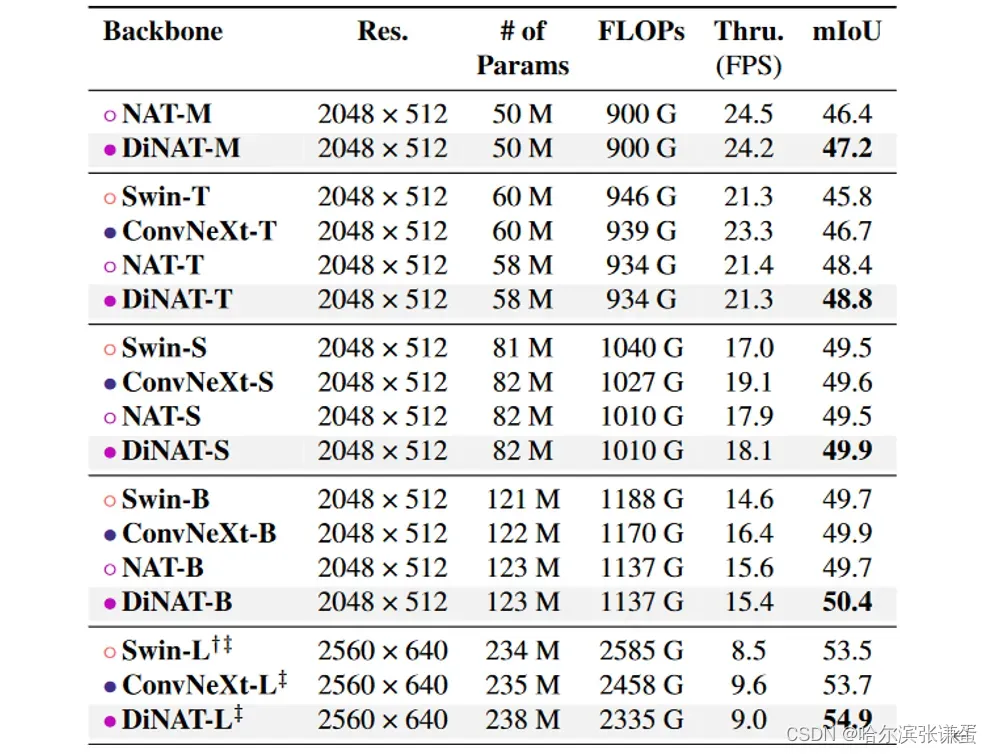
表8. ADE20K 语义分割性能。 ‡ 表示该模型在 ImageNet-22K 上进行了预训练。 † 表示将窗口大小从默认的 72 增加到 122。吞吐量是在一块 NVIDIA A100 GPU 上测得的。
4.4. Ablation study
在这一部分,我们旨在通过分析膨胀值、NA-DiNA顺序、核大小和测试时膨胀变化的影响,更深入地研究DiNAT。
膨胀值。在表9中,我们展示了具有不同膨胀值的模型及其对分类、检测、实例分割和语义分割性能水平的影响。请注意,增加的膨胀值(16、8、4、2)仅适用于下游任务,因为理论上输入特征图应大于或等于核大小和膨胀的乘积(最后一层的特征图为7×7:不适用最大的膨胀率)。因此,“8、4、2、1”是适用于 ImageNet 在 224 × 224 分辨率上的最大膨胀。根据图像分辨率,甚至可能使用更高的膨胀值。我们尝试了“动态”膨胀值,其中 DiNA 层应用最大可能的膨胀,即分辨率除以核大小的 floor(“Maximum”在表9中)。我们最终选择了“渐进”膨胀(参见图4中的示例),在这种情况下,我们逐渐增加膨胀直到定义的最大级别。例如,如果特定级别的最大膨胀为8,其层将具有膨胀值1、2、1、4、1、6、1、8(详细信息请参见附录B)。
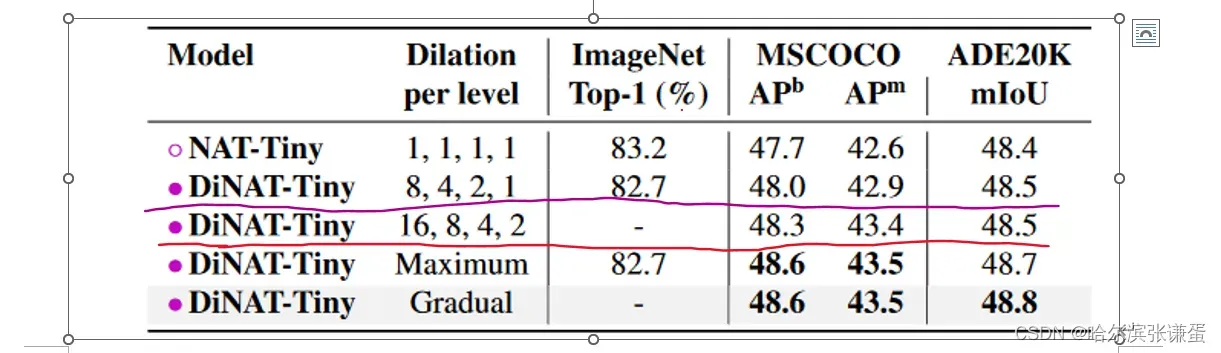
9。膨胀对性能的影响。超出“8, 4, 2, 1”的膨胀值仅适用于下游任务,因为它们具有更大的分辨率。最大膨胀表示根据输入大小设置为可能的最大值。对于ImageNet,它将与“8, 4, 2, 1”相同。渐进膨胀表示DiNA层中的膨胀值逐渐增加。
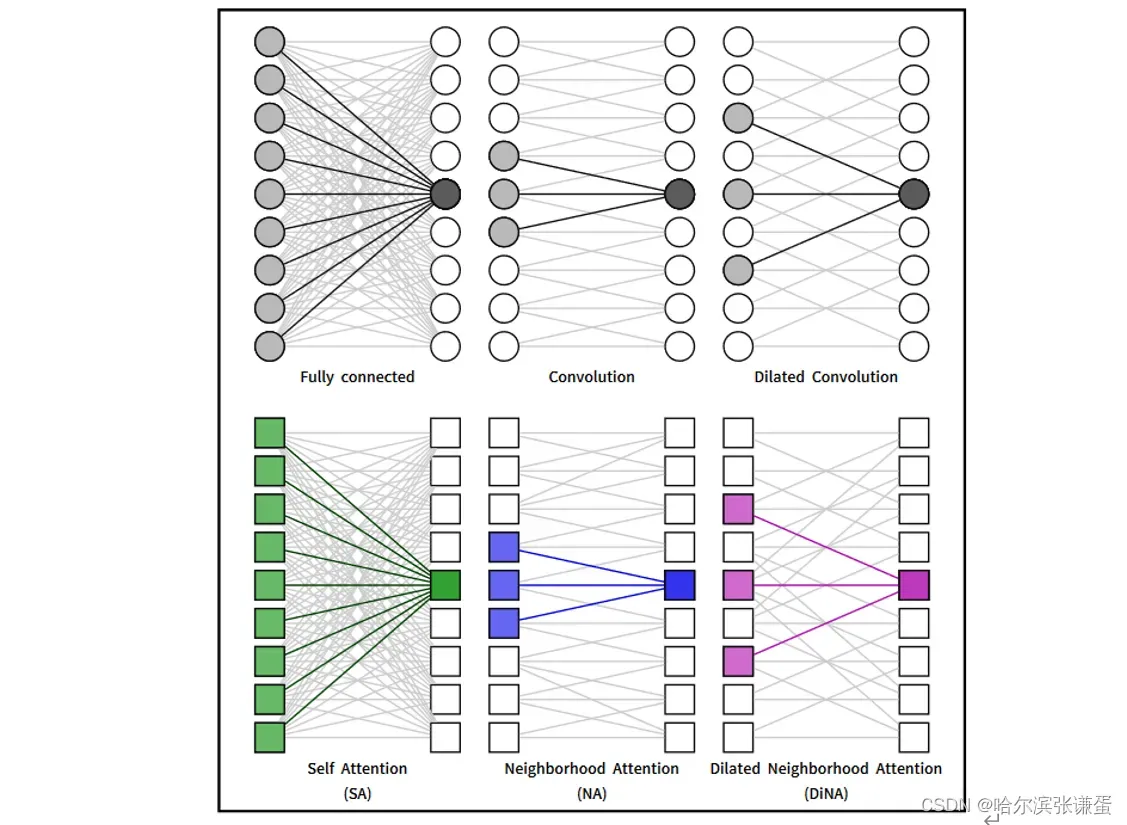
图4。对全连接层、卷积层和不同注意机制的感受野的单维度插图。NA和DiNA通过滑动窗口限制自注意力,类似于卷积和膨胀卷积限制全连接层。这些限制减少了计算负担,引入了有用的归纳偏差,并且在某些情况下增加了对不同输入尺寸的灵活性。
NA-DiNA vs. DiNA-NA。我们还尝试了在NA层之前使用DiNA层的模型,而不是我们最终选择的NA层之前使用DiNA层的顺序。尽管(NA-DiNA)是我们最初的选择,但我们也发现这是更有效的选择。我们还尝试了仅使用DiNA模块的模型,并发现其性能明显较差。这突显了在模型中同时具有本地和稀疏全局注意模式的重要性。结果总结在表10中。
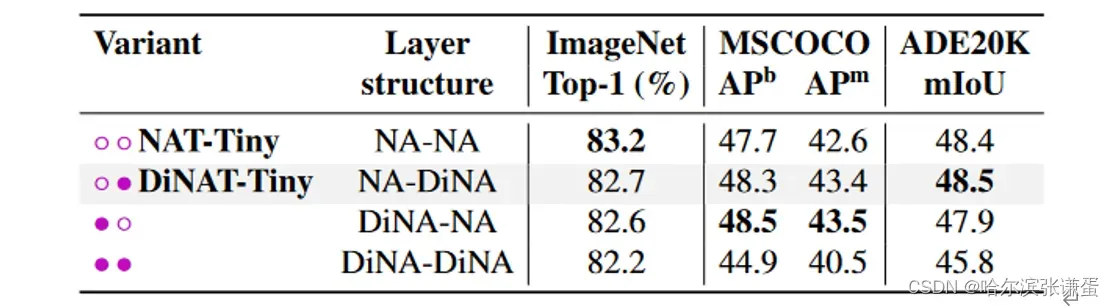
表10。层结构对性能的影响。我们的最终模型具有(NA-DiNA)顺序。
核大小。我们在表11中研究了核大小对模型性能的影响。我们观察到,对于DiNAT-Tiny,在所有三个任务中,较小的核大小会导致性能显著下降。然而,我们发现将核大小增加到默认的7×7以上并不会显著提高性能。
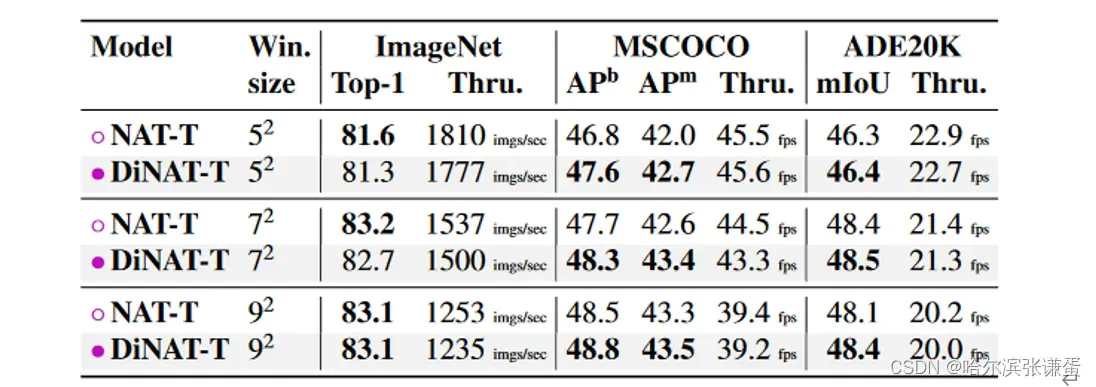
表11。核大小对性能的影响。请注意,我们根据默认分辨率在每个块中将膨胀设置为可能的最大值。因此,核大小为5的变体具有比核大小为7的变体更大的膨胀值。
测试时膨胀变化。我们进行了对膨胀值敏感性的分析,在已经训练好的模型上尝试不同的膨胀值,并评估其性能。这对于分辨率变化的情况,即多尺度测试,可能尤为重要。结果呈现在表12中。
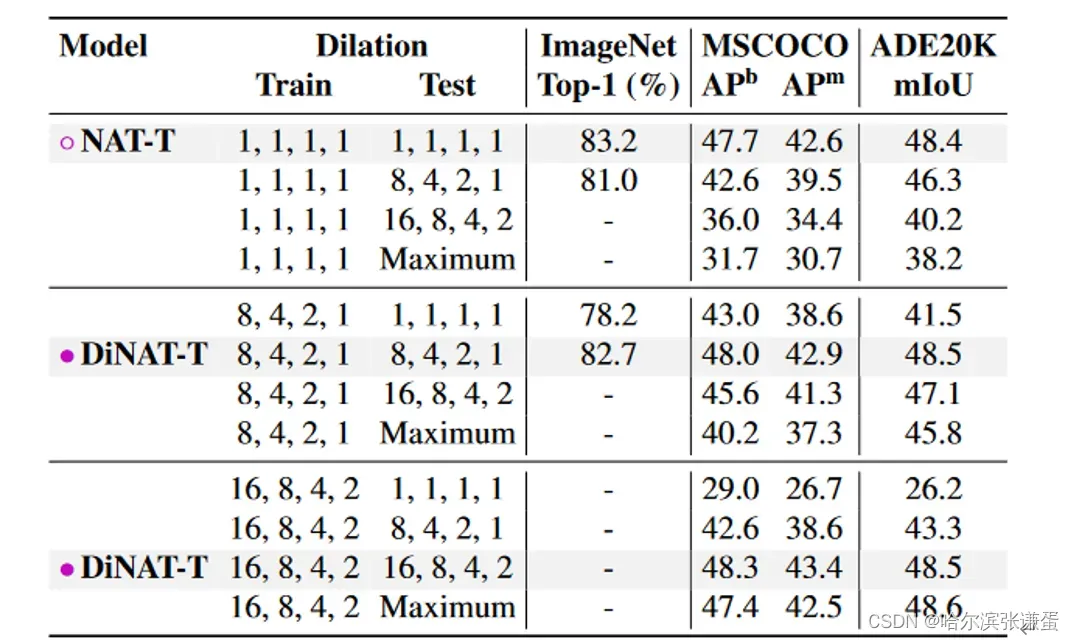
表12。测试时膨胀变化及其对性能的影响。大于8、4、2、1的膨胀值不适用于2242的ImageNet。
4.5. Image segmentation with Mask2Former
为了进一步分析DiNAT在分割任务中的性能,我们进行了使用Mask2Former [5]的实验。Mask2Former是一种基于注意力机制的分割架构,可以用于实例分割、语义分割和全景分割的训练。它在MS-COCO的全景分割和实例分割,以及ADE20K的语义分割方面创造了新的最先进分数。Mask2Former还使用了Swin-Large作为骨干网络,使其成为这个实验的理想候选。我们在MS-COCO [27]、ADE20K [55]和Cityscapes [8]上对Mask2Former进行了训练,完成了所有三个分割任务(实例、语义和全景),只需在其原始存储库的分支中替换Swin-Large的骨干网络。遵循他们报告的环境,我们使用PyTorch 1.9和Detectron2 [47]。我们在表13中展示了实例分割的结果,在表14中展示了语义分割的结果,在表15中展示了全景分割的结果。需要注意的是,DiNAT-L使用了112的核大小,而不是Swin-L的122,因为偶数大小的窗口会破坏NA中的对称性,因此无法定义。
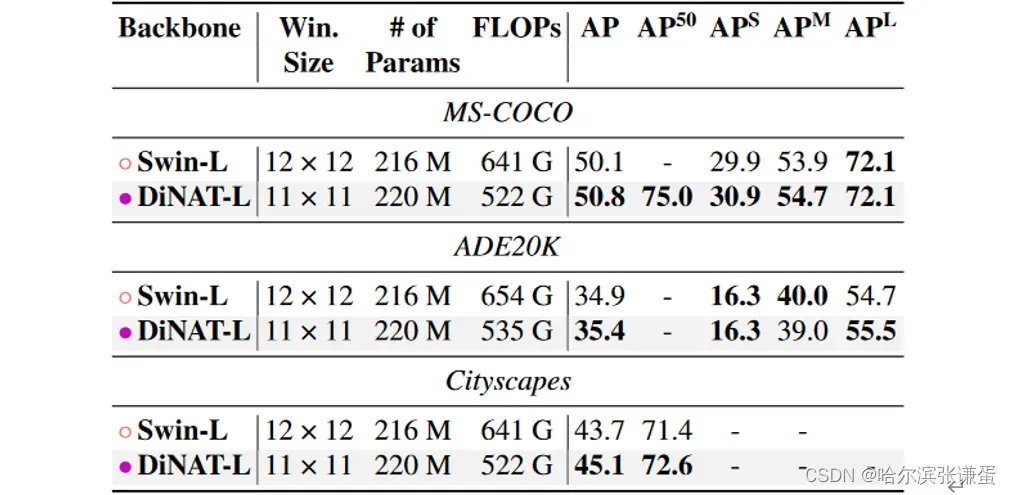
表13. 使用Mask2Former进行实例分割的性能。所有骨干网络都在ImageNet22K上进行了预训练。报告的FLOPs是相对于分辨率800^2的。
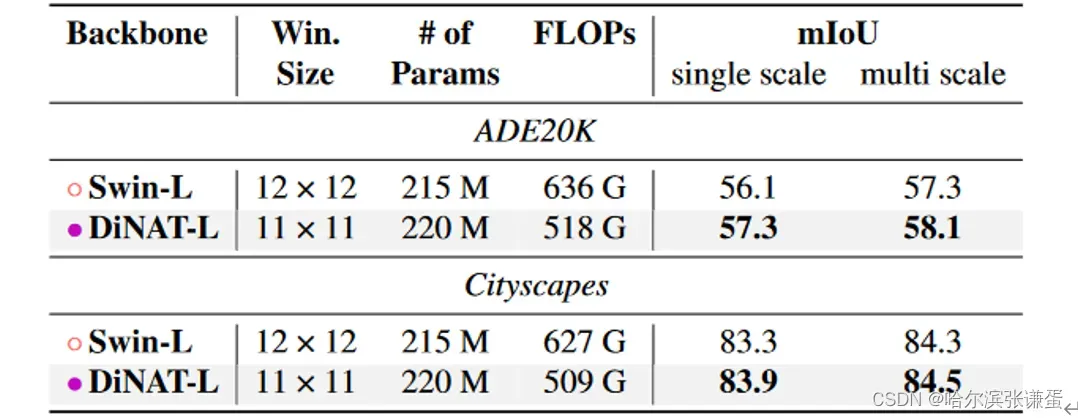
表14. 使用Mask2Former进行语义分割的性能。所有骨干网络都在ImageNet22K上进行了预训练。报告的FLOPs是相对于分辨率800^2的。
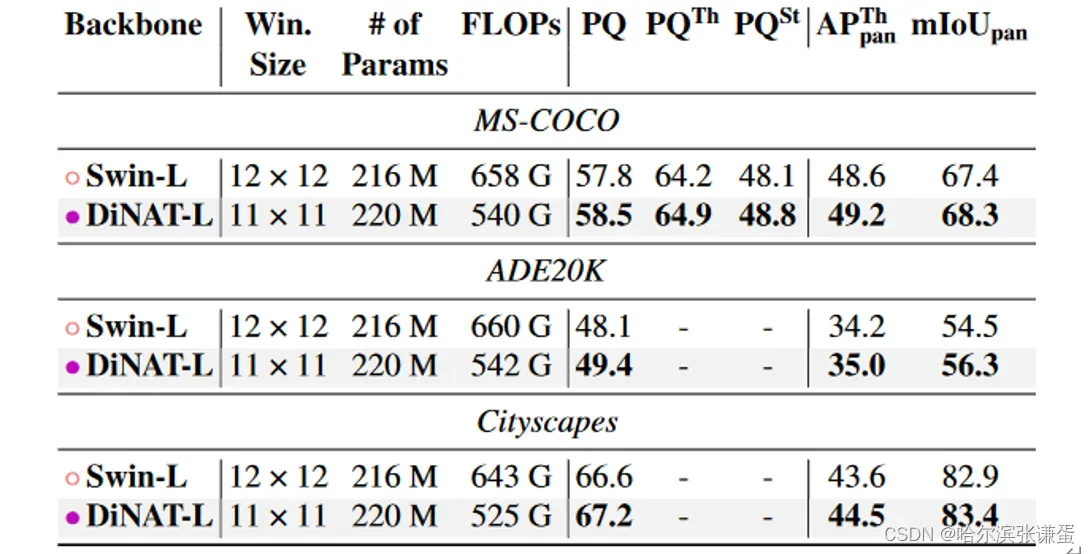
表15. 使用Mask2Former进行全景分割的性能。所有骨干网络都在ImageNet22K上进行了预训练。报告的FLOPs是相对于分辨率800^2的。
DiNAT-L在所有三个任务和数据集上均优于Swin-L,并在不使用额外数据的情况下创造了图像分割的新的最先进记录。根据PapersWithCode排行榜,DiNAT-L与Mask2Former在ADE20K和MS-COCO上是全景分割的SOTA,并且在ADE20K和Cityscapes的实例分割上也是如此。它还与ADE20K上的当前SOTA并列,并在Cityscapes语义分割上排名第二(两者的先前SOTA均为SeMask [21])。
5. Conclusion
本地注意力模块在减少复杂性方面非常有效,尤其在逐渐降低输入分辨率的分层模型中至关重要。然而,除非扩大其感知域大小,否则它们无法像全局自注意力那样捕捉更长范围的相互依赖关系,而这又违背了其最初的高效和可处理性。在本文中,我们提出了DiNA,这是对NA的自然扩展,它以零额外成本将其局部注意力扩展到稀疏的全局注意力。我们使用NA和DiNA的组合构建了DiNAT,并展示了它可以显著提高性能,尤其是在下游任务中,而不引入任何额外的计算负担。配合新的分割框架,我们的模型在图像语义、实例和全景分割性能方面达到了最先进的水平。尽管我们的实验揭示了这种灵活注意力模块背后的潜力,但它们的性能和效率并不止步于此。我们相信NA和DiNA的组合将能够为视觉和其他领域的各种模型提供支持,无论在何处需要局部性和全局上下文。我们开源了整个项目,包括对N ATTEN 的扩展,并将继续支持它作为一个工具包供社区使用,以便轻松进行对稀疏滑动窗口注意力的实验。
致谢。我们感谢Picsart AI Research(PAIR)、Meta/Facebook AI和智能高级研究计划局(IARPA)的慷慨支持,使这项工作成为可能。
Appendix
A. Implementation notes
如第3.5节讨论的那样,我们扩展了现有的N AT T EN包以支持扩张邻域。N AT T EN具有与许多其他实现类似的两阶段注意力计算:QK和AV。前者计算查询和键的点积,并生成注意力权重,后者将注意力权重应用于值。为了防止重新实现,我们没有包括缩放、softmax和dropout。这种两阶段结构相对于手动实现的优势之一是,与卷积的实现一样,滑动窗口直接从源张量中获取,而不是缓存在中间张量中,因此使用的内存明显较少。有关详细信息,请参阅N AT T EN文档和NAT [15]。扩张支持。将扩张添加到N AT T EN的简单内核中通常很简单:我们只需指示内核按变量d逐轴递增邻居,而不是逐轴递增1。然而,NA有一种特殊的处理方式来处理边缘/角像素,这需要额外的更改以支持扩张。向N AT T EN添加扩张的更大挑战是将其添加到利用共享内存的“tiled”内核中。瓦片状NA内核是N AT T EN的一个较新的添加,可以显著提高NA的吞吐量。矩阵乘法和卷积的瓦片实现对于有效并行化这些操作至关重要,同时最小化DRAM访问。正如其名称所示,瓦片实现将操作分成瓦片,并将每个线程块内的输入瓦片缓存到共享内存中。与直接访问全局内存相比,从共享内存中访问值通常要快得多,但也面临着银行冲突等挑战。瓦片实现还假设访问模式没有被破坏。引入扩张因子将破坏这些访问模式,并且需要重新实现以确保扩张邻居而不是本地邻居被缓存。我们在图I中提供了关于NAT和DiNAT相对于Swin的层次相对速度和内存使用的比较。缩放和Brain Float支持。为了训练我们的更大模型并避免在模型的后层中溢出激活值,我们不得不从默认的半精度数据类型float16切换到bfloat16。bfloat16的优势在于它具有8个指数位,而只有7个尾数位。利用bfloat16通常被推荐用于导致大激活的情况,而我们的情况正是如此,因为我们扩展了我们的模型。然而,切换到bfloat16需要重新实现N AT T EN的半精度内核以正确支持和利用bfloat16。
B. Training settings
我们在Tab. I中提供了有关训练DiNAT的额外细节。我们还提供了有关DiNATs的详细信息,它采用了非重叠的块嵌入和下采样,类似于Swin [29]和ConvNeXt [30]。DiNATs作为一种基于DiNA的替代模型,其架构与Swin相同。DiNATs还可以作为一种消融模型,因为它在架构上与Swin相同,只是用NA替换了WSA,用DiNA替换了SWSA。基于DiNA的模型中最重要的与架构相关的超参数之一是膨胀值。DiNAT和DiNATs都使用了NA和DiNA层的组合。我们通常将DiNA层的膨胀值设置为相对于输入分辨率的最大可能值,如果已知的话。例如,ImageNet分类在224×224的分辨率下采样到原始大小的四分之一,因此Level 1层将以56×56的分辨率的特征图作为输入。对于7×7的内核大小,最大可能的膨胀值是b56/7c = 8。Level 2将以28×28的分辨率的特征图作为输入,导致最大可能的膨胀值为4。由于这一点,我们根据任务和分辨率更改膨胀值。我们在分类、检测和分割中使用的最终膨胀值在Tab. II中呈现。请注意,我们仅对DiNA层更改膨胀值,因为我们发现微调NA层以适应DiNA层可能导致初始性能轻微降低(参见第4.4节,Tab. 12)。
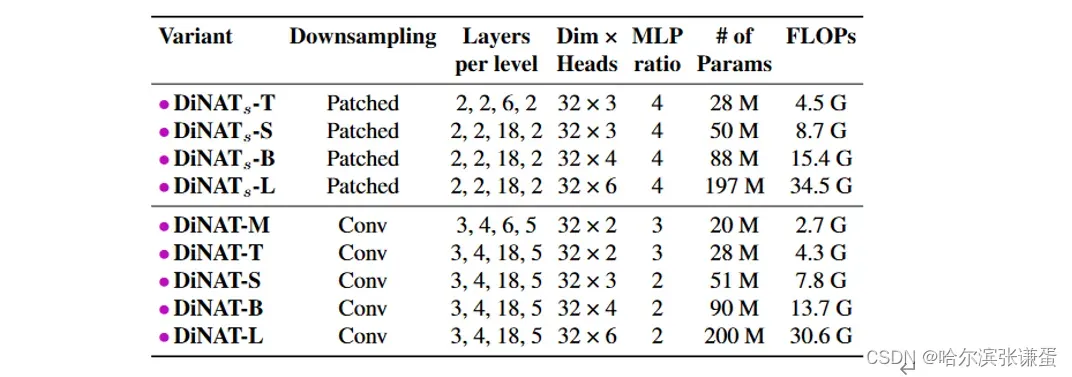
Tab. I. DiNAT和DiNATs配置摘要。通道(头和维度)在每个级别之后翻倍,直到最后一个级别。四个级别的默认膨胀值分别为8、4、2和1。所有变体的内核大小均为7×7。
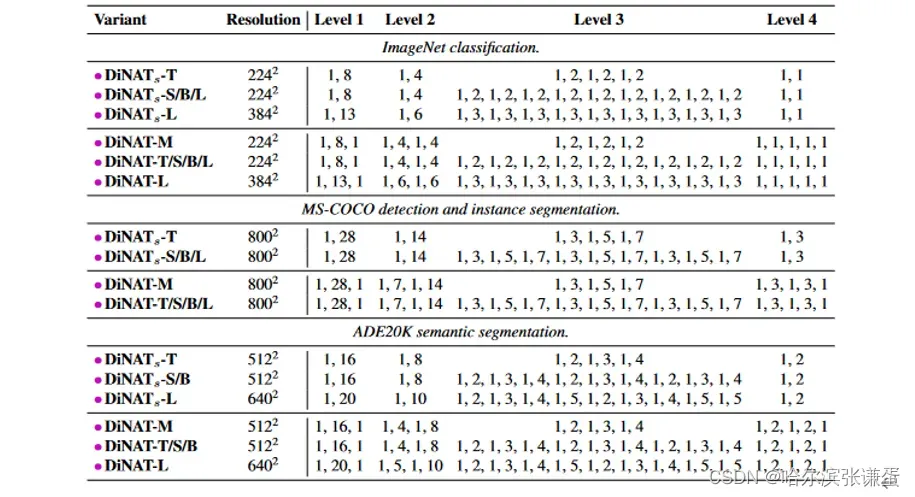
表格 II. 膨胀值。由于ImageNet的相对较小的输入分辨率,第4级的层不能超过膨胀值1,这相当于NA。同时注意,在224×224的分辨率下,第4级的输入将正好是7×7,因此NA将等同于自注意力。在分辨率明显更高的下游任务中,情况并非如此,其中第2级和第3级具有逐渐增加的膨胀值,在更深的模型中重复。这对应于标有“Gradual”的Tab. 9中突出显示的行。这些配置适用于所有下游实验(不包括第4.4节中的实验)。
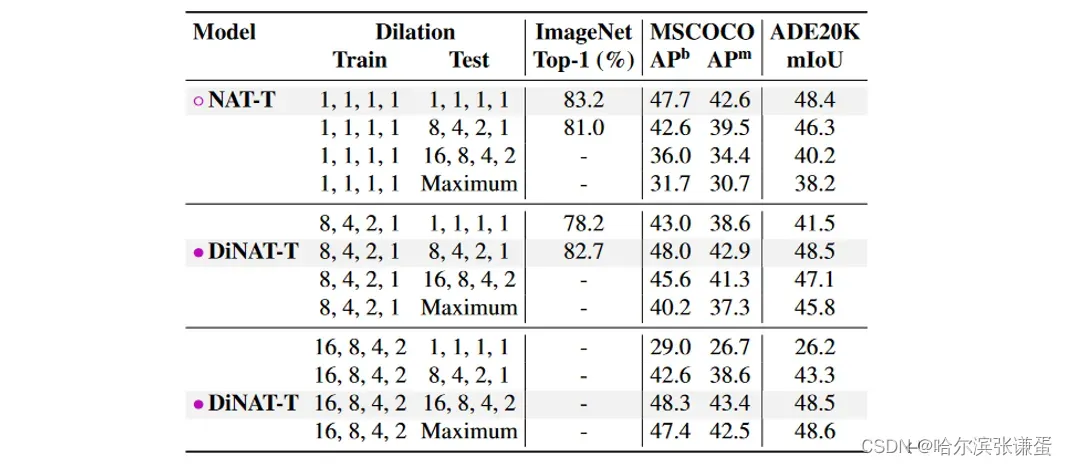
表格 12. 测试时膨胀变化及其对性能的影响。大于8、4、2、1的膨胀值对于2242的ImageNet不适用。
C. Experiments with alternative architecture
我们在所有主要实验中都使用了我们的主要模型 DiNAT,以及 DiNATs。我们发现 DiNATs 在某些情况下可以作为替代品,因为它们在速度、准确性和内存使用方面仍然比 Swin 有明显的改进。分类结果见表格 III,目标检测和实例分割结果见表格 IV,语义分割结果见表格 VI。在第 4.4 节中,我们对由 DiNA 引入的与架构相关的超参数进行了实验:膨胀值和 NA 与 DiNA 层的顺序。我们还通过添加 DiNATs 和 Swin 来完成这些膨胀实验,并在表格 V 和 VII 中呈现了结果。
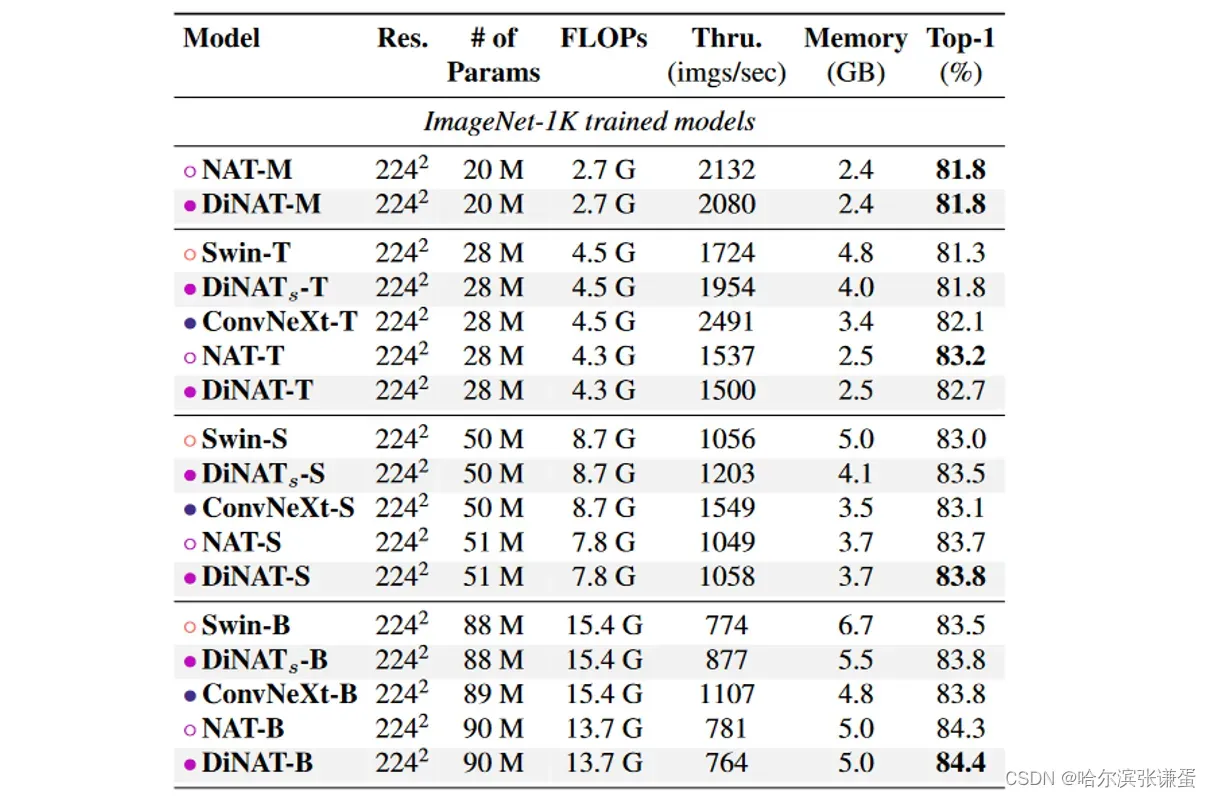
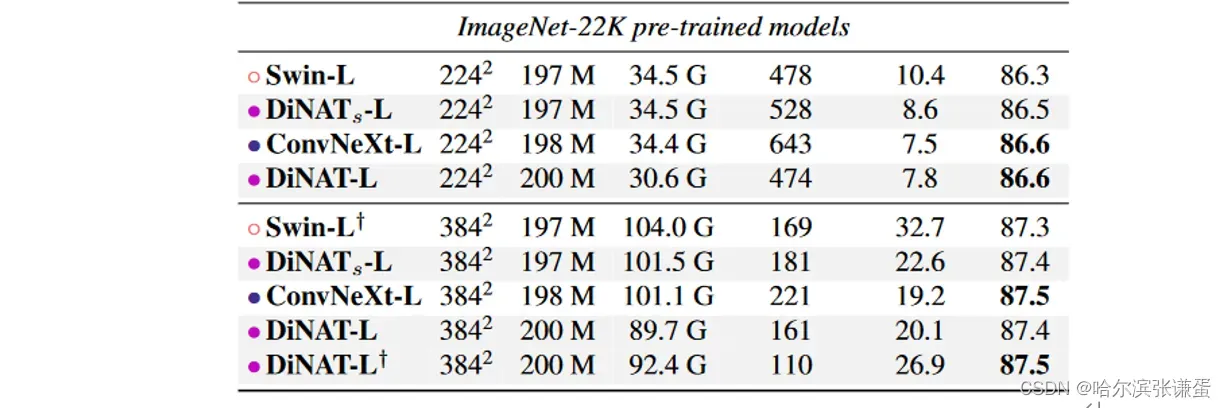
Table III. ImageNet-1K 图像分类性能。†表示将窗口大小从 72 增加到 112(DiNAT)和 122(Swin)。吞吐量和峰值内存使用是在单个 A100 GPU 上进行前向传递时以批量大小为 256 测量的。请注意,DiNATs 在架构上与 Swin 相同,只是在注意模块上有所不同(WSA/SWSA 被替换为 NA/DiNA)。
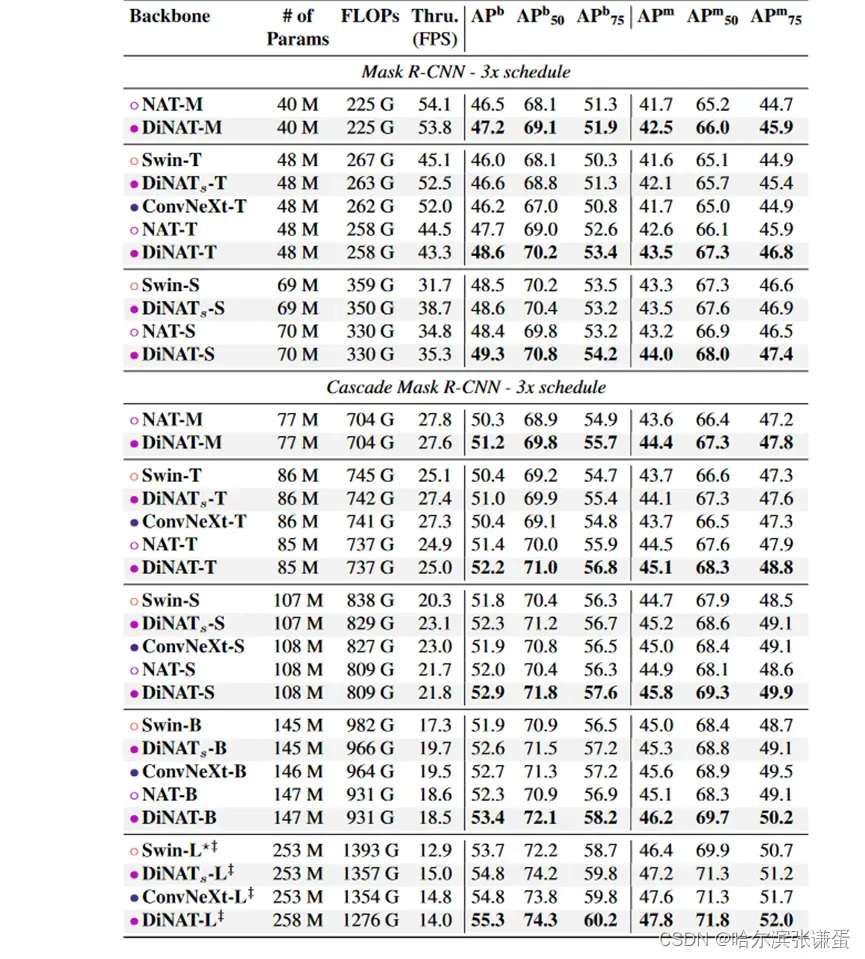
Table IV. COCO 目标检测和实例分割性能。 ‡ 表示该模型是在 ImageNet-22K 上预训练的。? Swin-L 在 Cascade Mask R-CNN 中没有报告,因此我们使用其官方检查点进行了训练。吞吐量是在单个 A100 GPU 上测量的。请注意,DiNATs 在架构上与 Swin 相同,只是在注意模块上有所不同(WSA/SWSA 被替换为 NA/DiNA)。
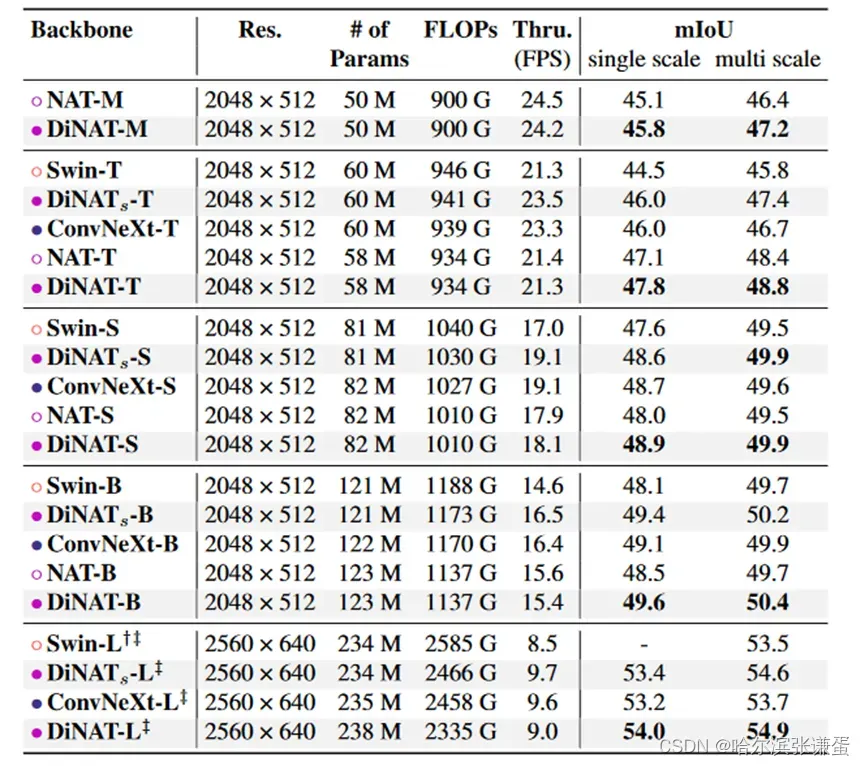
Table VI. ADE20K 语义分割性能。 ‡ 表示该模型是在 ImageNet-22K 上预训练的。†表示将窗口大小从 72 增加到 122。吞吐量是在单个 A100 GPU 上测量的。请注意,DiNATs 在架构上与 Swin 相同,只是在注意模块上有所不同(WSA/SWSA 被替换为 NA/DiNA)。
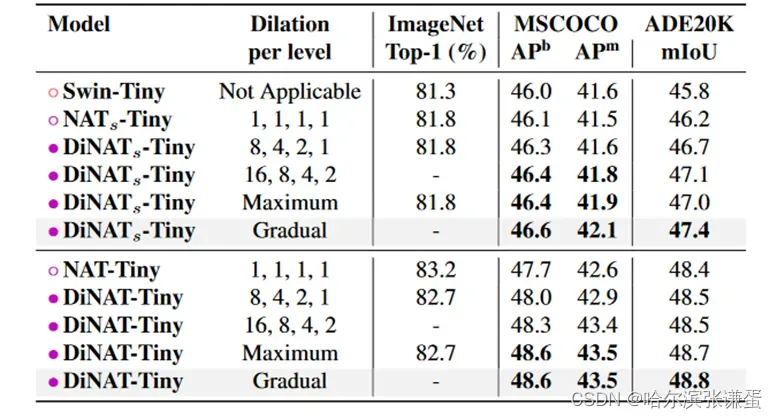
Table V. 膨胀对性能的影响。在同一部分中列出的模型在架构上相同,只在注意模式上有所不同(NATs 在 Swin 的基础上用 NA 替换了 WSA 和 SWSA,DiNATs 用 DiNA 替换了 SWSA)。
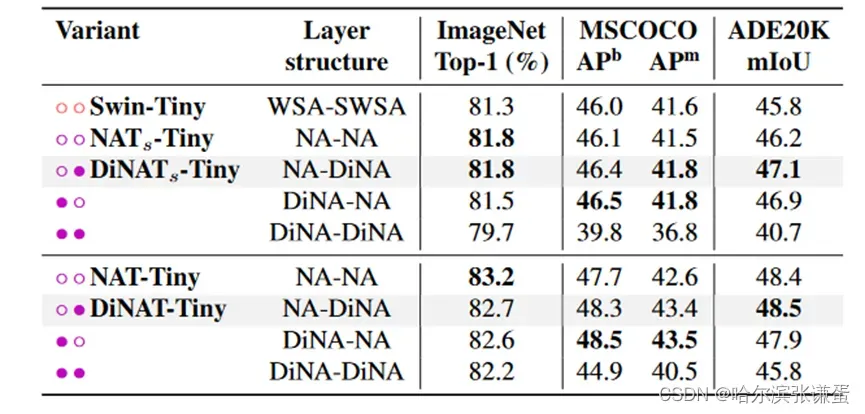
表七。层结构对性能的影响。
文章出处登录后可见!