
文章目录
1、LLaMA
🔥 纯基座语言模型
《LLaMA: Open and Efficient Foundation Language Models》:https://arxiv.org/pdf/2302.13971.pdf
- 开源!
- Meta AI 发布,包含 7B、13B、33B 和 65B 四种参数规模的模型。其中llama-13B(gpt-3 1/10大小)在多数benchmarks上超越gpt-3(175B)。
- 训练数据集使用的都是开源的数据集。
1.1、模型结构
transformer decoder结构
llama在transformer decoder结构上做了3大改进:
- 【gpt-3采用的】layer-norm -> RMSNorm (Root Mean square Layer Normalization)。transformer的block里是这样的前向流程multi-head-att -> add&norm -> feed-forward -> add&norm。而llama将norm改成里RMSNorm,并将其移到里input层,而不是output层。
- 【PaLM采用的】采用SwiGLU激活函数
- 【GPTNeo采用的】采用RoPE位置编码,即苏神提出的RoPE,现在基本是大模型必备的位置编码方式。(具体介绍可看我的另一篇博客:Rotary Position Embedding (RoPE, 旋转式位置编码) | 原理讲解+torch代码实现)
1.2、训练方式
- 语言模型预训练
- 优化器:AdamW。
- 使用cosine learning rate schedule,使得最终学习率等于最大学习率的10%,设置0.1的权重衰减和1.0的梯度裁剪。warmup的step为2000,并根据模型的大小改变学习率和批处理大小。嗯大概是模型变大,学习率变小了一丢丢。
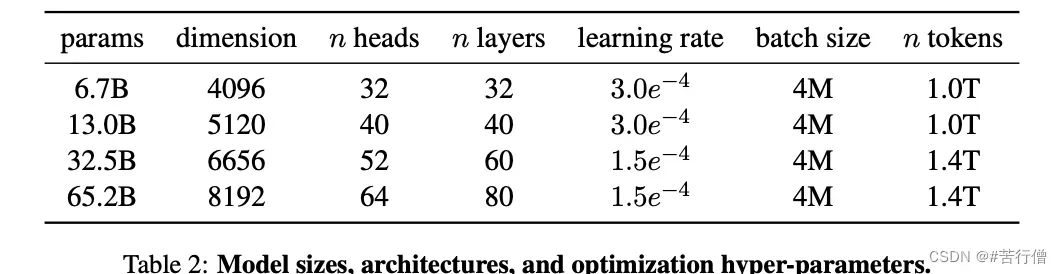
- 另外地,为提高训练效率,还做了些优化操作,如gradient checkpoint等。
1.3、结论
- 从实验来看,模型越大越好,小模型确实达不到大模型大力出奇迹的效果,而模型结构也并没有那么重要(虽然有很多工作是在改进模型结构本身)。结论部分更强调了大模型比大数据更重要,但都重要,因为增大数据或是增大模型,都能看到性能不断提高。
2、LLaMA-2
《Llama 2: Open Foundation and Fine-Tuned Chat Models》:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- 开源!
- 包含3种参数版本:7B、13B 和 34B,70B。
- LLaMA-2-CHAT 与 OpenAI ChatGPT 效果一样好。
2.1、相比LLaMA1的升级
- LLama2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
- 新增预预训练数据,并注重安全&隐私问题。
- 训练出了chat版本:llama-2-chat:SFT, RLHF。
2.3、模型结构
-
模型结构基本和llama一样,transformer decoder结构,RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
-
上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
7B和13B 使用与 LLaMA 相同的架构,34B和70B模型采用分组查询注意力(GQA)。【下面我展开来讲解】 -
For speed up decoding! 自回归解码的标准做法(past key-value 机制)是缓存序列中先前标记的k,v矩阵,从而加快注意力计算速度。但上下文长度、批量大小、模型大小较大时,多头注意力(MHA)中的kv缓存无疑巨大。
-
所以采用分组查询注意力机制(GQA)可以提高大模型的推理可扩展性。它的工作原理是将键和值投影在多个头之间共享,而不会大幅降低性能。可以使用具有单个KV投影的原始多查询格式(MQA)或具有8KV投影的分组查询注意力变体(GQA)。
2.3.1、MHA, MQA, GQA区别与联系
LLama2的注意力机制使用了GQA,那么什么是GQA呢?和标准的MHA有什么区别呢?
-
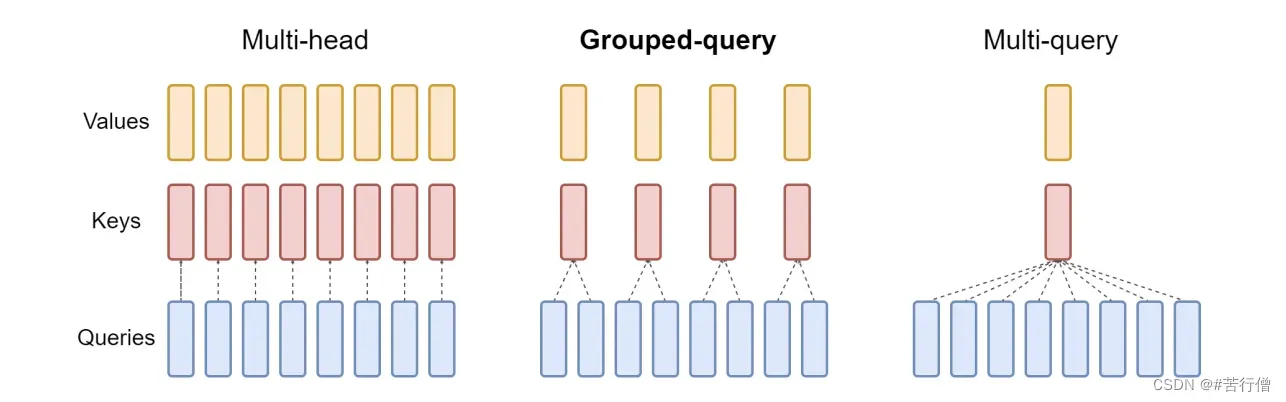
MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。
-
MQA(Multi-Query Attention,Fast Transformer Decoding: One Write-Head is All You Need)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。【论文:https://arxiv.org/pdf/1911.02150.pdf】
-
GQA(Grouped-Query Attention,GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。【论文:https://arxiv.org/pdf/2305.13245v1.pdf】
2.4、训练方式
【优化器:AdamW;学习率计划:cosine learning rate schedule。使用 0.1 的权重衰减和1.0的梯度裁剪。】
- 0、Llama2使用与Llama1相同的分词器;它采用BPE算法,使用 SentencePiece 实现。与Llama 1 一样,将所有数字拆分为单独的数字,并使用字节来分解未知的 UTF-8 字符。词汇量为 32k token
- 1、使用公开的在线数据进行预训练。
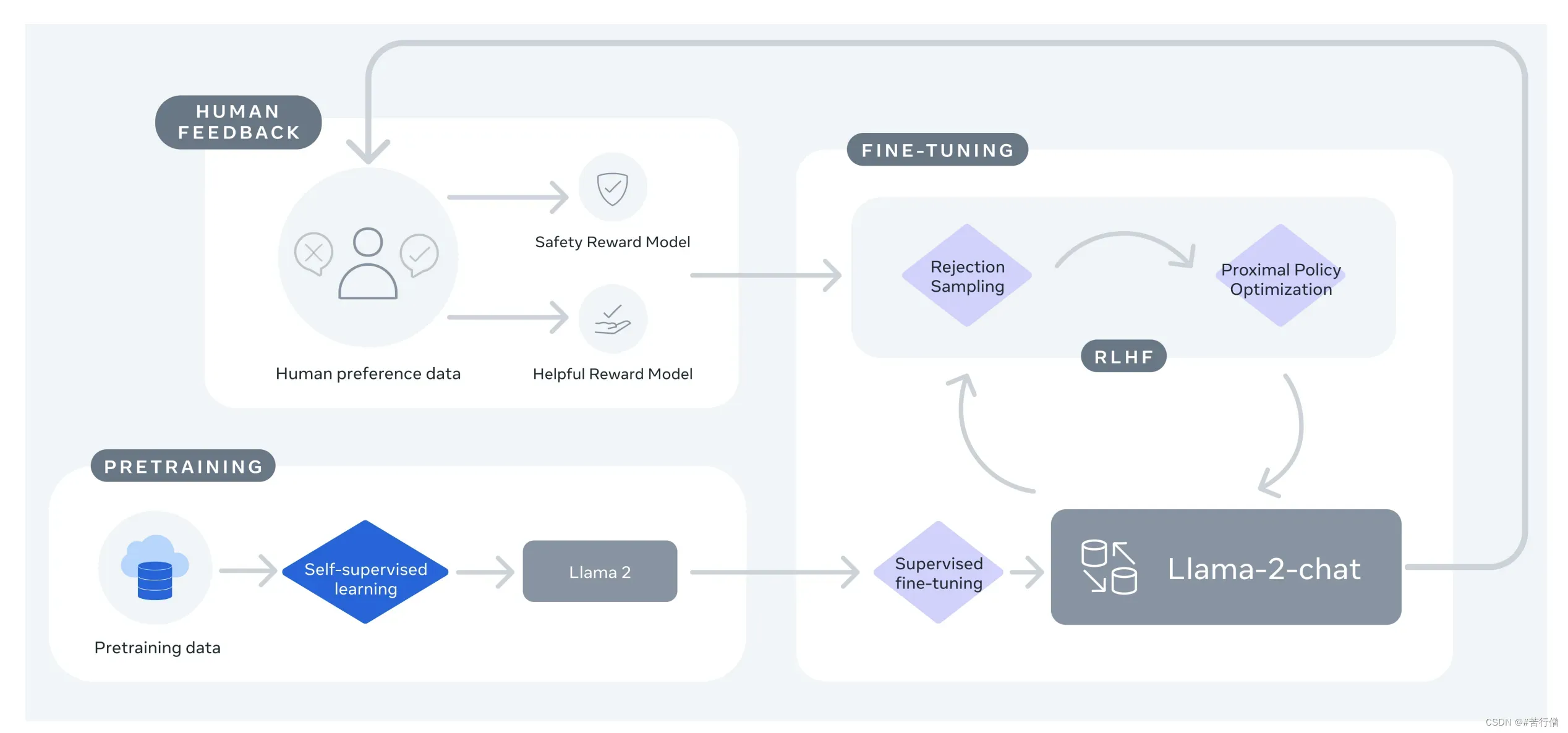
- 2、SFT:然后通过使用有监督微调创建 Llama-2-chat 的初始版本。
- 3、RLHF:接下来,llama-2-chat 使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
文章出处登录后可见!