一、协同过滤算法的基本原理
协同过滤算法(Collaborative Filtering) 是比较经典常用的推荐算法,它是一种完全依赖用户和物品之间行为关系的推荐算法。我们从它的名字“协同过滤”中,也可以窥探到它背后的原理,就是 “协同大家的反馈、评价和意见,一起对海量的信息进行过滤,从中筛选出用户可能感兴趣的信息”。协同过滤算法主要分为两类:
- 基于物品的协同过滤算法:给用户推荐与他之前喜欢的物品相似的物品。
- 基于用户的协同过滤算法:给用户推荐与他兴趣相似的用户喜欢的物品。
接下来,我们就通过电商场景下的例子,来了解一下基于用户的协同过滤算法。通过分析这个例子,你就能搞清楚协同过滤算法的大致推荐过程了。这个电商推荐系统从得到原始数据到生成最终推荐分数,全过程一共可以总结为 6 个步骤,如下所示。
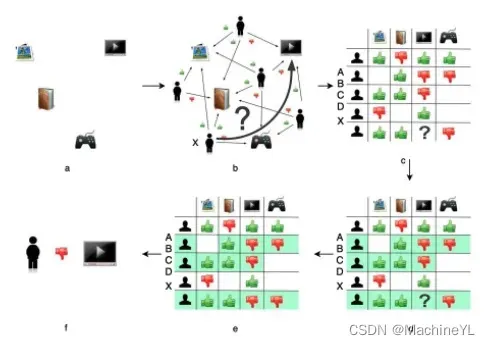
电商网站的商品库里一共有 4 件商品:游戏机、小说、杂志,以及电视机。现假设,有一名用户 X 访问了这个电商网站,推荐系统需要决定是否推荐电视机给用户 X。
为了进行这项预测,推荐系统可以利用的数据有用户 X 对其他商品的历史评价数据,以及其他用户对这些商品的历史评价数据。我在图 1(b) 中用绿色“点赞”的标志表示好评,用红色“踩”的标志表示了差评。这样一来,用户、商品和评价记录就构成了带有标识的有向图。
接下来,为了方便计算,我们将有向图转换成矩阵的形式。这个矩阵表示了物品共同出现的情况,因此被称为“共现矩阵”。其中,用户作为矩阵行坐标,物品作为列坐标,我们再把“点赞”和“踩”的用户行为数据转换为矩阵中相应的元素值。这里,我们将“点赞”的值设为 1,将“踩”的值设为 -1,“没有数据”置为 0。
生成共现矩阵之后,推荐问题就转换成了预测矩阵中问号元素(图 1(d) 所示)的值的问题。由于在“协同”过滤算法中,推荐的原理是让用户考虑与自己兴趣相似用户的意见。因此,我们预测的第一步就是找到与用户 X 兴趣最相似的 n 个用户,然后综合相似用户对“电视机”的评价,得出用户 X 对“电视机”评价的预测。
从共现矩阵中我们可以知道,用户 B 和用户 C 由于跟用户 X 的行向量近似,被选为 Top n(这里假设 n 取 2)相似用户,接着在图 1(e) 中我们可以看到,用户 B 和用户 C 对“电视机”的评价均是负面的。因为相似用户对“电视机”的评价是负面的,所以我们可以预测出用户 X 对“电视机”的评价也是负面的。推荐系统就不会向用户 X 推荐“电视机”这一物品。
到这里,协同过滤的算法流程就说完了。这个过程中有两个需要进一步思考的地方:
- 一是用户相似度到底该怎么定义?
- 二是我们预测用户 X 对“电视机”的评价也是负面的,这个负面应该有一个分数来衡量,应该怎么计算呢?
二、计算用户相似度
首先,我们来解决计算用户相似度的问题。计算用户相似度其实并不是什么难事,因为在共现矩阵中,每个用户对应的行向量其实就可以当作一个用户的 Embedding 向量。最常见的方法就是利用余弦相似度,衡量用户向量 i 和用户向量 j 之间的向量夹角大小。夹角越小,余弦相似度越大,两个用户越相似,它的定义如下:
除了最常用的余弦相似度之外,相似度的定义还有皮尔逊相关系数、欧式距离等等。咱们课程主要使用的是余弦相似度,因此你只要掌握它就可以了,其他的定义我这里不再多说了。
三、预测用户对某个商品的评分
再来看看用户对某个商品的评分怎么计算。在获得 Top n 个相似用户之后,利用 Top n 用户生成最终的用户 u 对物品 p 的评分是一个比较直接的过程。这里,我们假设“目标用户与其相似用户的喜好是相似的”,根据这个假设,我们可以利用相似用户的已有评价对目标用户的偏好进行预测。最常用的方式是,利用用户相似度和相似用户评价的加权平均值,来获得目标用户的评价预测,公式如下所示:
其中,权重 是用户 u 和用户 s 的相似度,
是用户 s 对物品 p 的评分。
在获得用户 u 对不同物品的评价预测后,最终的推荐列表根据评价预测得分进行排序即可得到。到这里,我们就完成了协同过滤的全部推荐过程。
四、矩阵分解算法原理
协同过滤虽然可以帮助用户找出合适的推荐列表,在实践中得到广泛的应用,但是也存在着一些问题。那就是共现矩阵往往非常稀疏,在用户历史行为很少的情况下,寻找相似用户的过程并不准确。于是,著名的视频流媒体公司 Netflix 对协同过滤算法进行了改进,提出了矩阵分解算法,加强了模型处理稀疏矩阵的能力。
这里,我们还是用一个直观的例子来理解一下什么叫做矩阵分解。这次从 Netflix 的矩阵分解论文中截取了两张示意图,来比较协同过滤和矩阵分解的原理。
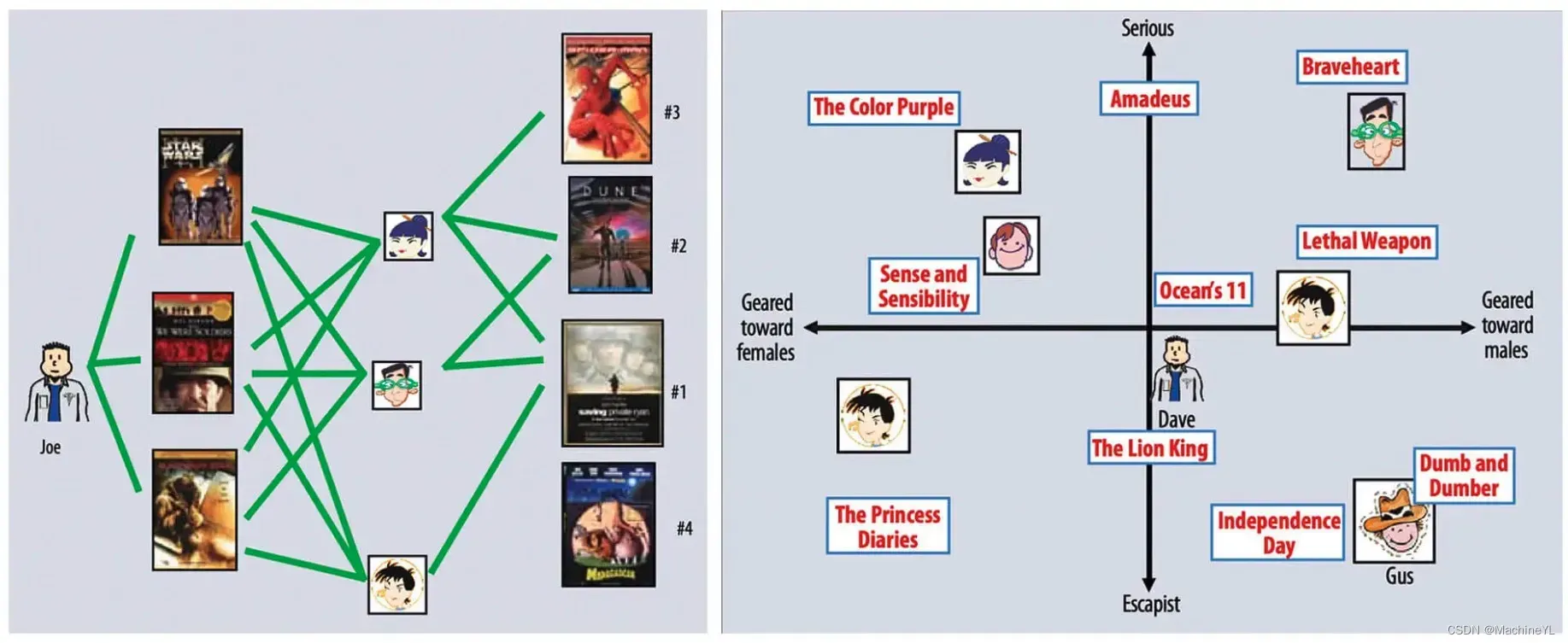
如左图所示,协同过滤算法找到用户可能喜欢的视频的方式很直观,就是利用用户的观看历史,找到跟目标用户 Joe 看过同样视频的相似用户,然后找到这些相似用户喜欢看的其他视频,推荐给目标用户 Joe。
矩阵分解算法则是期望为每一个用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上(如图右所示),距离相近的用户和视频表明兴趣特点接近,在推荐过程中,我们就应该把距离相近的视频推荐给目标用户。例如,如果希望为图右中的用户 Dave 推荐视频,我们可以找到离 Dave 的用户向量最近的两个视频向量,它们分别是《Ocean’s 11》和《The Lion King》,然后我们可以根据向量距离由近到远的顺序生成 Dave 的推荐列表。
这个时候你肯定觉得,矩阵分解不就是相当于一种 Embedding 方法嘛。没错,矩阵分解的主要过程,就是先分解协同过滤生成的共现矩阵,生成用户和物品的隐向量,再通过用户和物品隐向量间的相似性进行推荐。
那这个过程的关键就在于如何分解这个共现矩阵了。从形式上看,矩阵分解的过程是直观的,就是把一个 m * n 的共现矩阵,分解成一个 m * k 的用户矩阵和 k * n 的物品矩阵相乘的形式(如下图)。
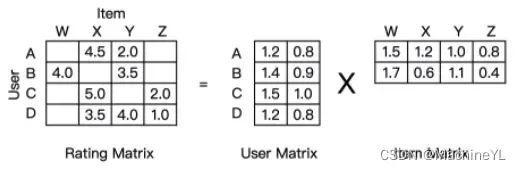
有了用户矩阵和物品矩阵,用户隐向量和物品隐向量就非常好提取了。用户隐向量就是用户矩阵相应的行向量,而物品隐向量就是物品矩阵相应的列向量。
那关键问题就剩下一个,也就是我们该通过什么方法把共现矩阵分解开呢?最常用的方法就是梯度下降。梯度下降的原理,简单来说就是通过求取偏导的形式来更新权重。梯度更新的公式是 (wt+1=wt−α∗∂w/∂L)。为了实现梯度下降,最重要的一步是定义损失函数 L,定义好损失函数我们才能够通过求导的方式找到梯度方向,这里我们就给出矩阵分解损失函数的定义如下。
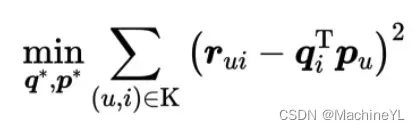
这个目标函数里面, 是共现矩阵里面用户 u 对物品 i 的评分,
是物品向量,
是用户向量,K 是所有用户评分物品的全体集合。通过目标函数的定义我们可以看到,我们要求的物品向量和用户向量,是希望让物品向量和用户向量之积跟原始的评分之差的平方尽量小。简单来说就是,我们希望用户矩阵和物品矩阵的乘积尽量接近原来的共现矩阵。
在通过训练得到用户隐向量和物品隐向量之后,就可以通过前面介绍的部分进行推荐了。
五、协同过滤存的其他问题
- 当系统建立之初,还未收集足够的用户信息,协同过滤算法不能为指定用户找到合适的邻居,从而无法向用户提供推荐预测。
- 对于新注册的用户由于系统里没有他们的历史数据信息,所以协同过滤算法也无法为新用户推荐商品。
- 对于冷门的商品,可能从未被评过分,比如新加进的商品或者是比较小众的商品,它们也是不可能会被推荐给用户的。
为了克服以上的缺点,现今的推荐系统一般会用多种推荐策略进行互补,而不是单单只采用某一种推荐策略。常用的思路有:
- 如果推荐商品种类比较少,可以将多种推荐算法的预测值进行加权,得到最终的预测值进行排序推荐。
- 如果推荐商品种类比较多,可以用协同过滤算法及其他推荐算法来做召回;后面再用更好的模型对召回池中的商品进行精排,进行推荐。
总结
协同过滤是一种协同大家的反馈、评价和意见,对海量的信息进行过滤,从中筛选出用户感兴趣信息的一种推荐算法。它的实现过程主要有三步,先根据用户行为历史创建共现矩阵,然后根据共现矩阵查找相似用户,再根据相似用户喜欢的物品,推荐目标用户喜欢的物品。
但是协同过滤处理稀疏矩阵的能力比较差,因此,矩阵分解算法被提出了,它通过分解共现矩阵,生成用户向量矩阵和物品向量矩阵,进而得到用户隐向量和物品隐向量。你可以完全把最后的结果当作用户 Embedding 和物品 Embedding 来处理。
介绍完了协同过滤算法的原理,想要了解源码的可以访问我的另外一篇文章:
【推荐算法】协同过滤算法代码(pyspark | ALS)_MachineCYL的博客-CSDN博客
参考链接
文章出处登录后可见!