
你每天都在做很多看起来毫无意义的决定,但某天你的某个决定就能改变你的一生。——《西雅图不眠夜》
目录
什么是C语言数组?
1、一维数组的创建与初始化
1.1数组的创建格式
1.2数组的初始化
1.3一维数组的使用
1.4一维数组在内存中的存储
2、二维数组的创建与初始化
2.1二维数组的创建格式
2.2二维数组初始化
2.3二维数组的使用
2.4二维数组在内存中的存储
3、越界数组
4、为什么数组下标是从0开始的?
5、数组作为函数参数
5.1冒泡排序函数的错误设计
5.2数组名到底是什么?
5.3冒泡排序函数的正确设计
什么是C语言数组?
- 首先,从字面了解数组是一堆数字组成的集合。C语言中数组是一组固定大小且相同类型元素的集合。数组分为一维数组和二维数组。
- 数组类型的声明并不是对一个元素进行声明而是对整个数组里面的元素类型都进行声明。
- 所有的数组元素都是在一块连续的地址上的存储的,第一个元素占最低的地址,最后一个元素占最高的地址。
- 数组的下标从0开始到元素的个数减1结束。
1、一维数组的创建与初始化
1.1数组的创建格式
数组是由数组类型+数组名+数组大小组成的,其中最重要的是数组大小是一个常量表达式。结合下图理解:

🤼数组的创建格式有四种情况,如下所示:
情况1,定义一个数组并给定数组大小
int arry1[10];//未初始化的名为arry1的整形数组大小是10
情况2,定义一个常量并给定数组大小为这个常量
const int a=5;//定义一个常量a=5
int arry5[a];//未初始化的名为arry5的整形数组大小是5
情况3,数组大小为常量表达式
int arry6[5+6];//未初始化的名为arry6的整形数组大小是11
情况4,空数组
int arry7[];//未初始化的名为arry7的整形数组大小未知
温馨提示:以上均是用整形定义的,您可以定义其他类型。
注意:数组创建,在C99标准之前, [] 中要给一个常量才可以,不能使用变量。在C99标准支持了变长数组的概念,数组的大小可以使用变量指定,但是数组不能初始化。
1.2数组的初始化
在了解数组的创建格式后,我们来看数组的初始化。初始化就是在创建数组后给定数组里面与数组类型相同的元素。初始化又分为完全初始化和不完全初始化,我们来看代码:
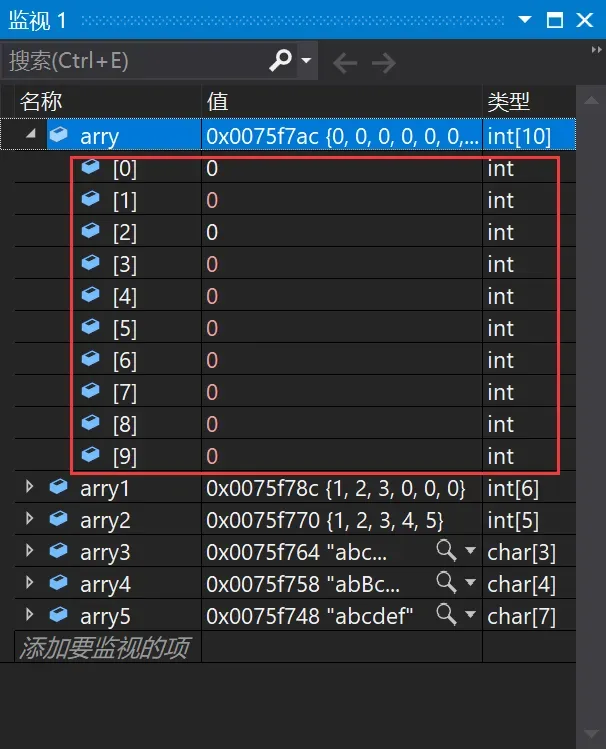
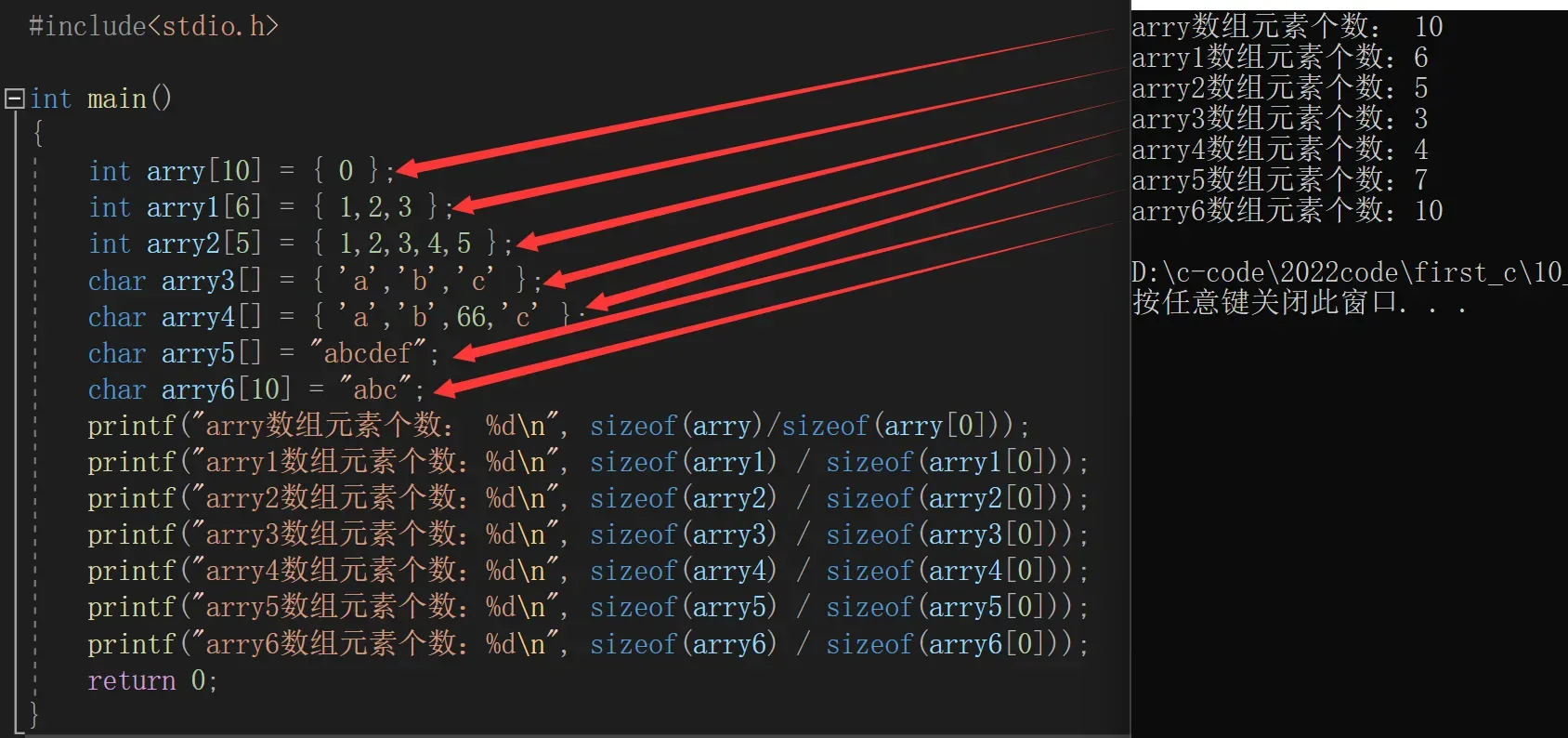
1、int arry[10] = { 0 };//完全初始化
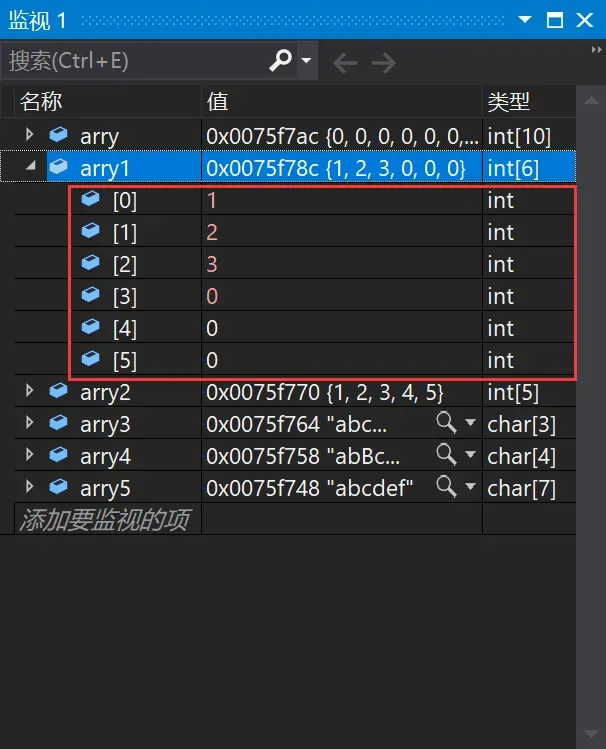
2、int arry1[6] = { 1,2,3 };//不完全初始化
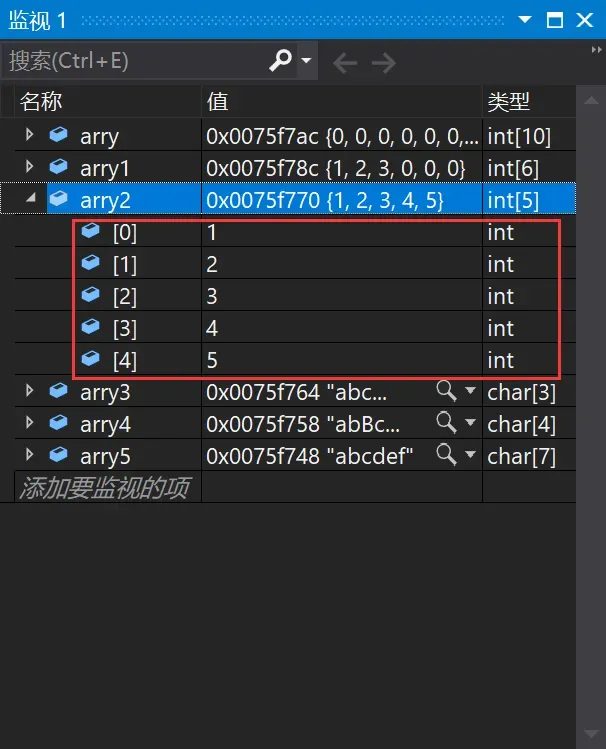
3、int arry2[5] = { 1,2,3,4,5 };//完全初始化
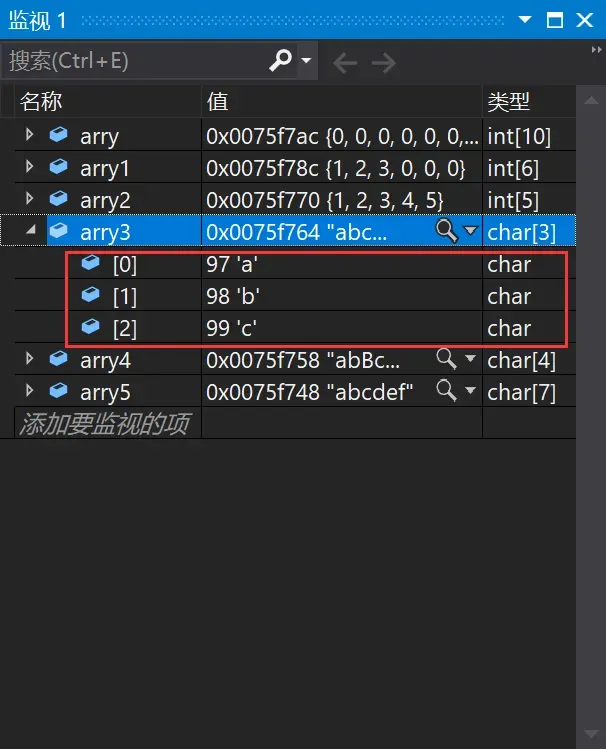
4、char arry3[] = { 'a','b','c' };//完全初始化
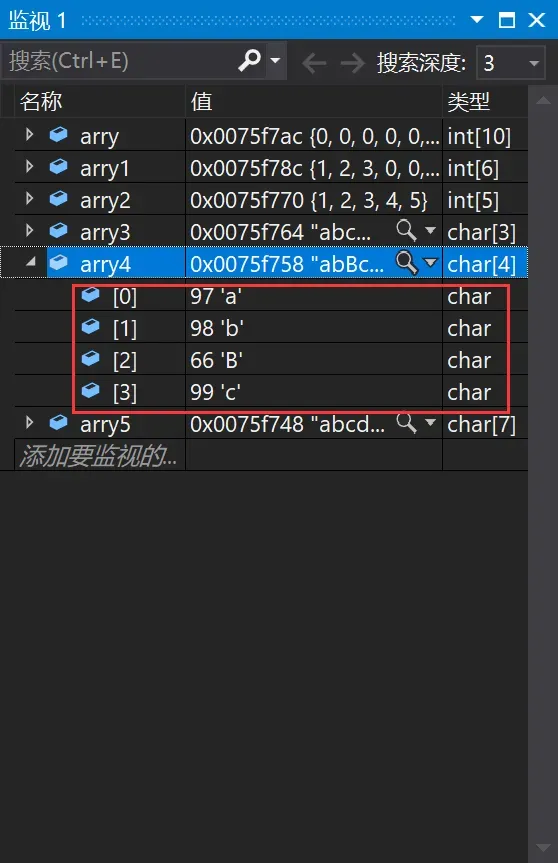
5、char arry4[] = { 'a','b',66,'c' };//完全初始化
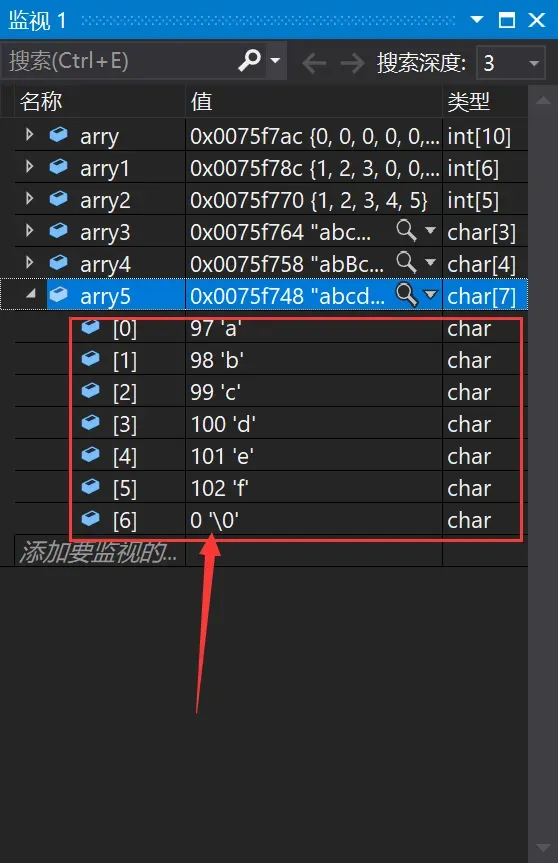
6、char arry5[] = "abcdef";//完全初始化
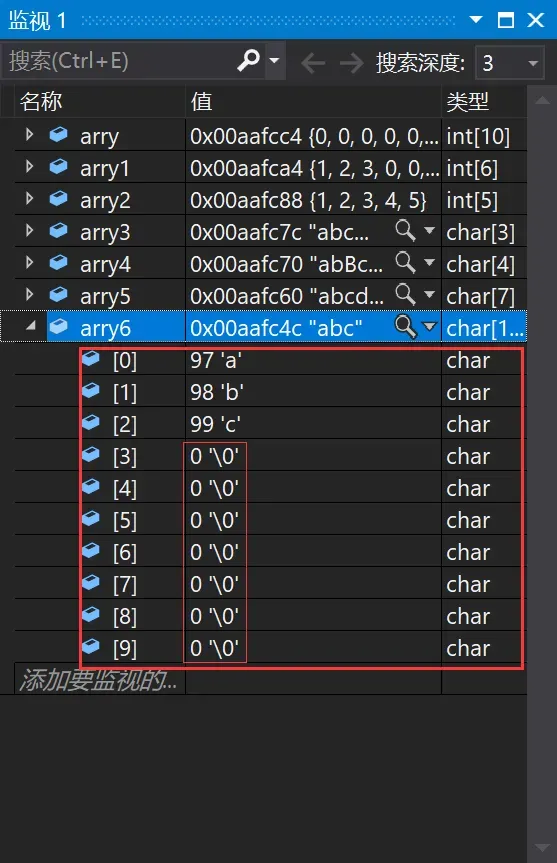
7、char arry6[10] = "abc";//不完全初始化以上代码1~7我依次来讲解:
1、int arry[10] = { 0 };arry数组是完全初始化,10个元素全是0
2、int arry1[6] = { 1,2,3 };arry1数组是不完全初始化,我们初始化了前三个元素,剩余的三个元素默认初始化为0。那么前三个元素是1,2,3。后三个元素是0,0,0。
3、int arry2[5] = { 1,2,3,4,5 };arry2数组是完全初始化,5个元素都初始化了。
4、char arry3[] = { ‘a’,’b’,’c’ };arry3数组是完全完全初始化,它不指定元素的个数。但编译器通过初始化内容来确定该数组元素的个数。
5、char arry4[] = { ‘a’,’b’,66,’c’ };arry4也是完全初始化,它也没指定元素的个数,编译器通过初始化内容来确定该数组元素个数。其中66虽然是整型数字,但是数组类型是char所以编译器也认为66对应的是字符B。B的ASCLL码是66。
6、char arry5[] = “abcdef”;arry5数组是完全初始化,未给定数组大小,编译器通过初始化内容来确定元素个数,但由于初始化是用双引号(””)引起来,所以编译器自行在字符串末尾加上字符串结束标识符(转义字符)’\0’。因此虽输入5个字符,实际大小为6个字符。
7、char arry6[10] = “abc”;arry6数组是不完全初始化,初始化了前三个字符,其余字符由编译器默认为转义字符’\0’。
我们可以用sizeof取出数组占的总字节数然后除以siz该数组的首元素字节数就可以得出该数组的元素个数。例如:sizeof(arry)/sizeof(arry[0])。
🤼♀️ 那么如果我们想要将定义的数组以字符串的形式打印,我们该怎么做呢。有以下代码:
#include<stdio.h>
int main()
{
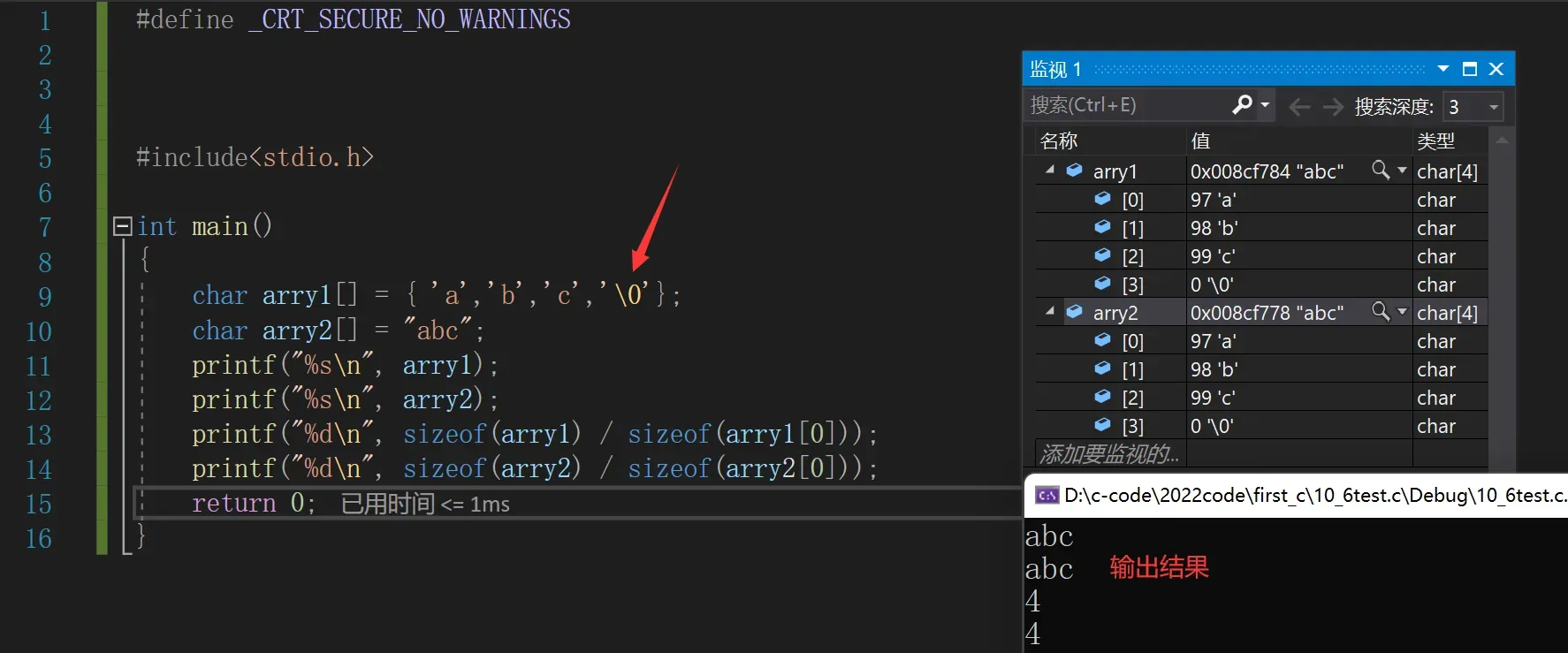
char arry1[] = { 'a','b','c' };
char arry2[] = "abc";
printf("%s\n", arry1);
printf("%s\n", arry2);
return 0;
}输出结果:
abc烫烫烫烫?烫烫烫?d
abc我们可以看到只有arry2输出了正确的值,为什么会这样呢。我们在{}里面定义的虽然是完全初始化了,但是要以字符串的形式打印出来我们需要在{}里结尾处加上一个结束标识符‘\0’。
在{}字符结尾加上‘\0’后:
当我们取这两个数组的长度时’\0’也算作一个字符,但字符串输出时并不显示’\0’,’\0’只是做一个结束标识,但还是得占一个字符内存。

1.3一维数组的使用
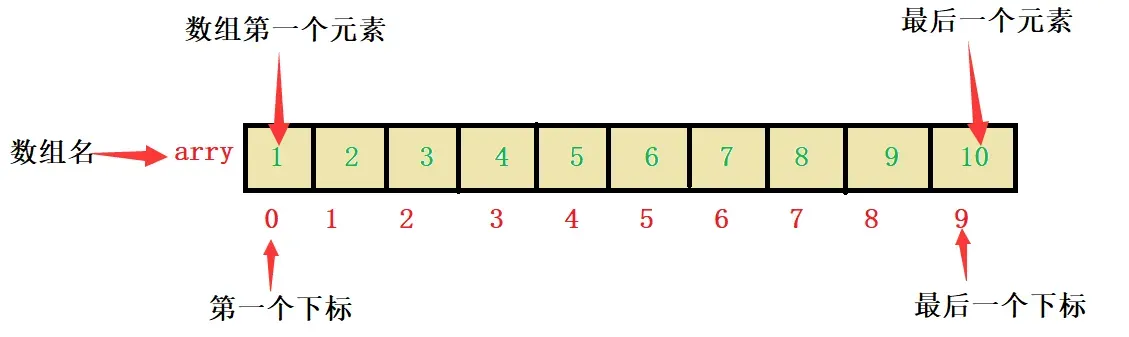
我们先来介绍一个操作符: [] ,下标引用操作符。它其实就是数组访问的操作符。数组的下标是从0开始到元素的个数减1结束。我们来看程序,有一程序,定义一个一维数组,顺序打印和逆序打印出这个这个数组。
#include<stdio.h>
int main()
{
int arry[10] = {1,2,3,4,5,6,7,8,9,10};//定义一个数组元素为1-10
for (int i = 0; i < 10; i++)
{
printf("%d ", arry[i]);//依次输出arry[0]-arry[9]
}
printf("\n");
for (int j = 9; j >=0; j--)
{
printf("%d ", arry[j]);//依次输出arry[9]-arry[0]
}
return 0;
}输出:
1 2 3 4 5 6 7 8 9 10
10 9 8 7 6 5 4 3 2 1上面我们说到数组的下标是从0开始直到元素的个数减1结束,因此遍历打印数组,for循环是很好的选择。
总结:
- 数组是使用下标来访问的,下标是从0开始
- 数组的大小可以通过sizeof计算得到
1.4一维数组在内存中的存储
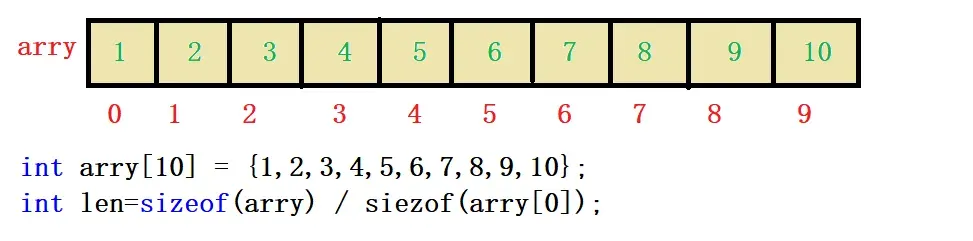
一维数组在内存中是连续着存放的,随着下标的增长下标所在的地址是由低往高增长的。
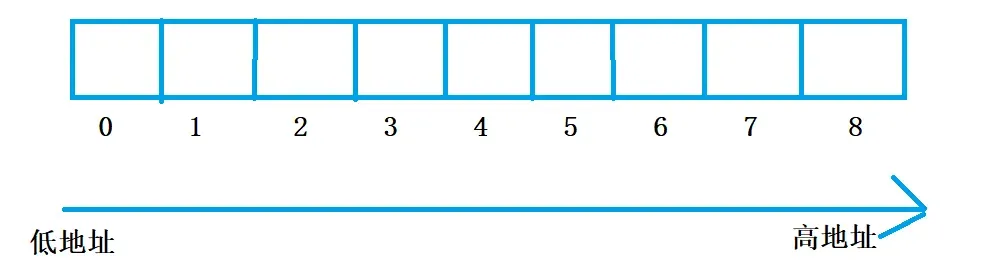
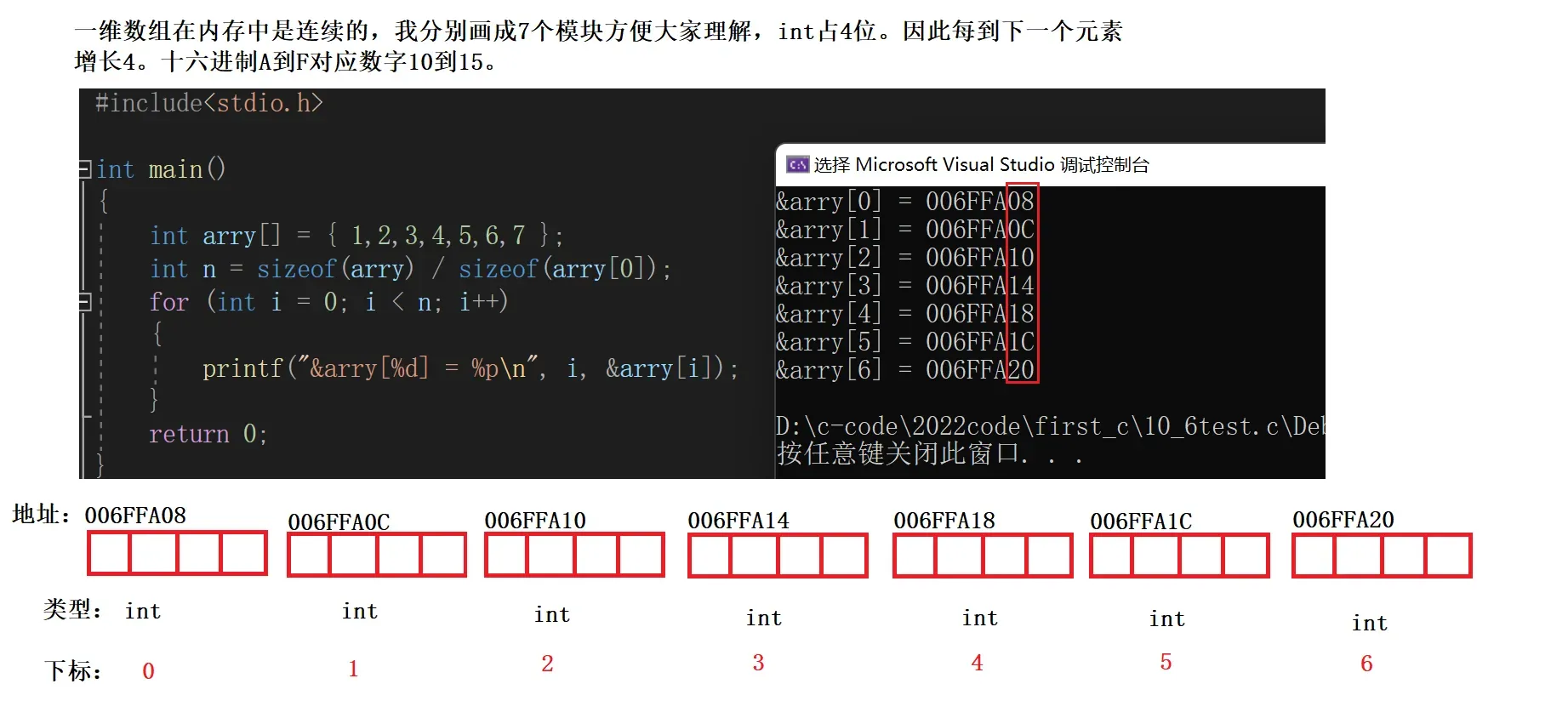
🤼我们来看程序:
#include<stdio.h>
int main()
{
int arry[] = { 1,2,3,4,5,6,7 };
int n = sizeof(arry) / sizeof(arry[0]);
for (int i = 0; i < n; i++)
{
printf("&arry[%d] = %p\n", i, &arry[i]);
}
return 0;
}
输出结果如下图:
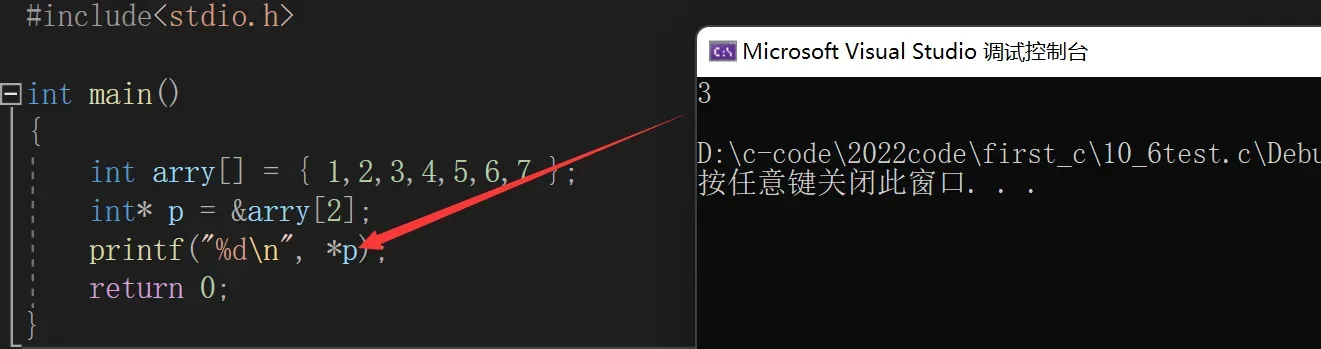
我们可以通过地址找到找到该元素,怎样找呢用指针来找。指针指向数组中元素的地址,再对指针进行解引用就可以找到该元素。比如我想找到数组的第3个元素,我们来看图理解:
第3个元素对应数组的下标是2,指针p指向了下标2对应的地址。再对p进行解引用就可以得到该元素。
2、二维数组的创建与初始化
2.1二维数组的创建格式
上面我们了解到了一维数组的创建格式,那么二维数组的创建格式与一维数组的创建格式相差不大。下面我就来介绍,先看一组代码:
1、int arry1[2][3];
2、char arry2[3][4];
3、float arry3[5][6];我们看到二维数组也是一样由数据类型+数组名+数组大小构成,唯一不同点就是比一维数组多了一个[]。多的一个[]代表列数前面的[]代表行数。
- 1、int arry1[2][3];表示这是一个2行3列的二维数组,arry1里面有6个元素
- 2、char arry2[3][4];表示这是一个3行4列的二维数组,arry2里面有12个元素
- 3、float arry3[5][6];表示这是一个5行6列的二维数组 ,arry3里面有30个元素
2.2二维数组初始化
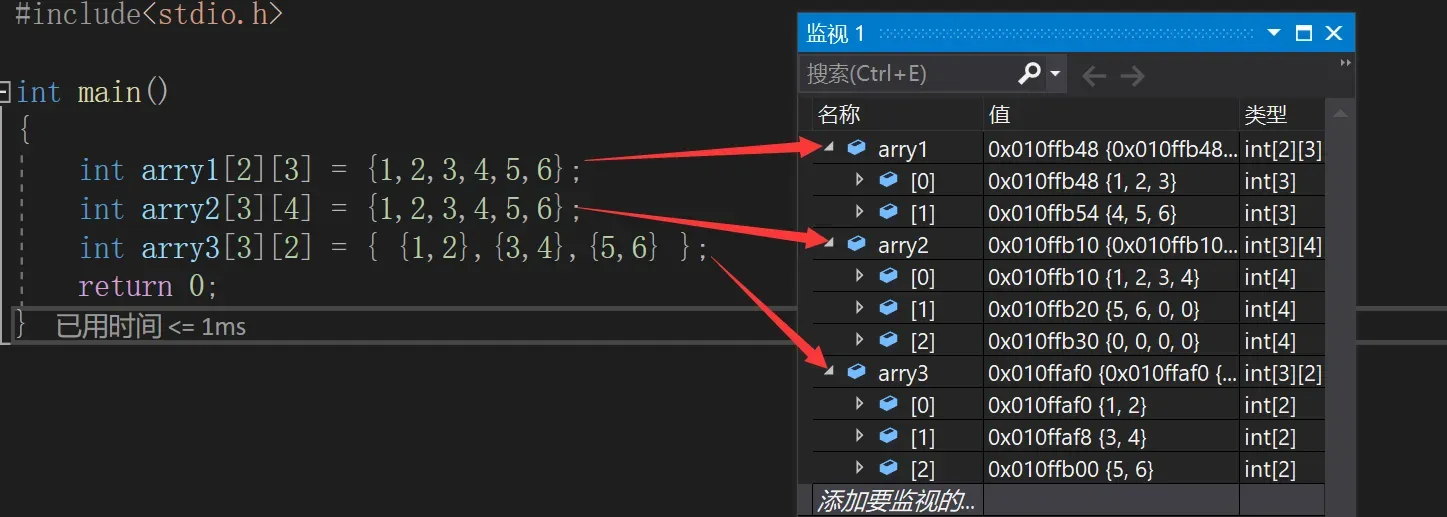
二维数组也也分为完全初始化和不完全初始化,我们来看代码:
int main()
{
int arry1[2][3] = {1,2,3,4,5,6};
int arry2[3][4] = {1,2,3,4,5,6};
int arry3[3][2] = { {1,2},{3,4},{5,6} };
return 0;
}arry1完全初始化,初始化6个元素。
arry2不完全初始化,初始化前两行部分元素,后两行默认为0
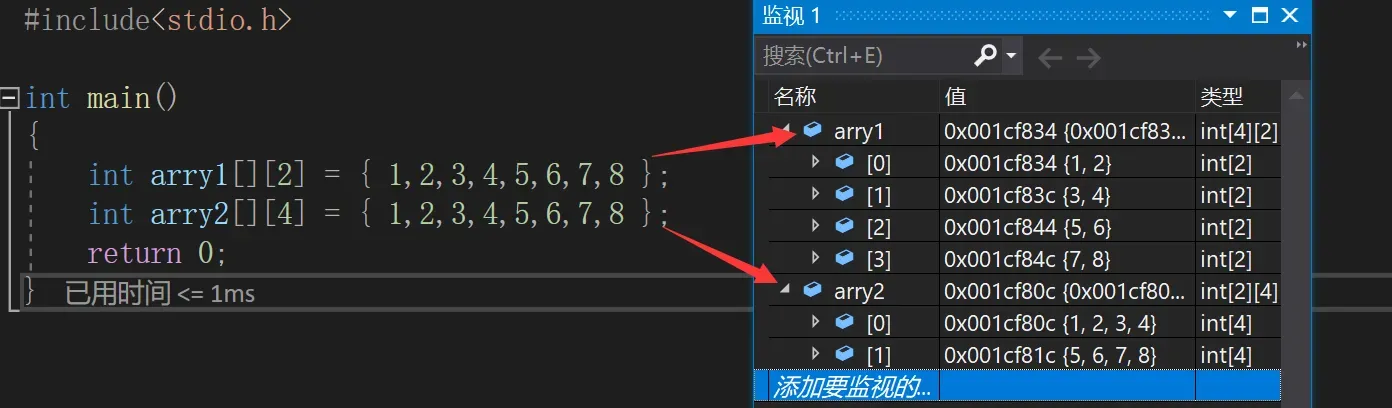
arry3完全初始化,写成{}里面多个{}的形式,怎样理解呢。{}里面的第一个{}代表第一行,第二个{}代表第二行,第三个{}代表第三行。列数就是最外层{}里面{}的个数,我们结合监视窗口来理解:
如何通过下标来访问各个元素呢,我们拿arry2来举例。与一维数组一样行数开始从0开始到总行数减1结束,列也是从0开始到总列数减1结束。
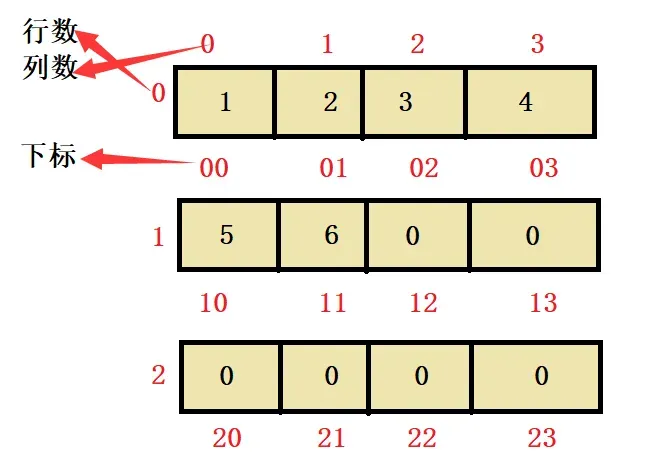
🤼注意,一维数组的数组大小可以省略同过初始化来确定元素个数,二维数组中的行可以省略,列不能省略。如以下代码:
#include<stdio.h>
int main()
{
int arry1[][2] = { 1,2,3,4,5,6,7,8 };
int arry2[][4] = { 1,2,3,4,5,6,7,8 };
return 0;
}结果如下:
行省略话,系统根据初始化的内容会自动生成相应的行数。arry1生成了4行2列的二维数组,arry2生成了2行4列的二维数组。
2.3二维数组的使用
二维数组的使用也是通过下标来找到各个元素的,第一行的起始下标是0最后一行下标是总行数-1,列也是一样的。第一列的起始下标是0最后一列下标是总列数-1。我们可以通过行的下标和列的下标结合起来找到某一元素。如我要找第二行第二个元素:arry[1][1]。
🤼♀️定义一个二维数组,打印出这个数组的各个元素:
#include<stdio.h>
int main()
{
int arry[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 };//定义一个3行4列的二维数组
for (int i = 0; i < 3; i++)//控制行号
{
for (int j = 0; j < 4; j++)//控制列号
{
printf("%d ", arry[i][j]);//输出第i行的元素
}
printf("\n");//每输出一行换行一次
}
return 0;
}输出结果:
1 2 3 4
5 6 7 8
9 10 11 12
2.4二维数组在内存中的存储
🤼♀️有一程序,定义一个二维数组并初始化该数组,打印出各个元素所占的地址:
#include<stdio.h>
int main()
{
int arry[3][4] = { 1,2,3,4,5,6,7,8,9,10,11,12 };
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
printf("&arry[%d][%d] = %p\n",i,j,&arry[i][j]);
}
}
return 0;
}
输出结果:
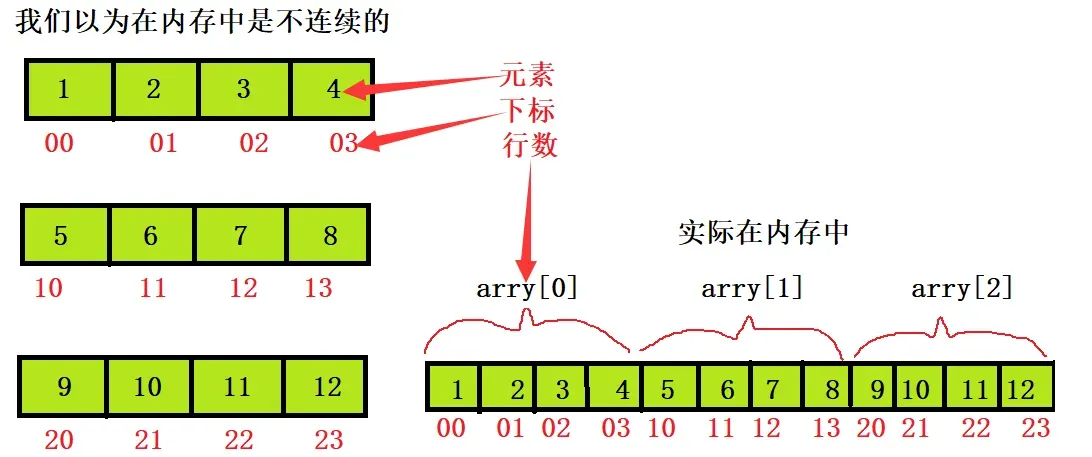
我们发现,二维数组在内存中的地址也是连续的 。
从侧面说明了二维数组也是一个一维数组,只不过定义的时候把它定义成了二维数组。如一个arry[12]定义成arry[3][4]。或者这样理解由三个一维数组组成的一个二维数组。这样我们就不难明白了。

3、越界数组
数组的下标是有范围限制的,设数组有n个元素,数组的下标规定从0开始的,最后一个元素的下标是n-1。如果数组的下标小于0或者大于n-1,此时数据就越界访问了,超出了定义数组时数组的合法空间。这就是为什么我们经常打印出一堆乱码烫烫烫烫什么的。最后C语言本身是不做数组下标的越界检查,编译器也不一定报错,不报错不代表程序就是正确的。所以我们一定要认真调试代码。
🤼♀️我们来看一程序:
#include<stdio.h>
int main()
{
int arry[] = { 6,7,8,9,10 };
int n = sizeof(arry) / sizeof(arry[0]);
for (int i = 0; i <= n; i++)
{
printf("%d ", arry[i]);
}
return 0;
}输出:6 7 8 9 10 -858993460
以上代码for语句中i<=n,超出了下标的最大范围。导致最后一次输出一堆乱码,这就是越界数组。
4、为什么数组下标是从0开始的?
为啥数组下标是从0开始的,是为了数组寻址更方便。按我们平常的思想从1开始不是更方便吗?数组是一种线性表数据结构,它是一相同类型的数据在内存中连续存储的。当我们创建一个数组的时候。
系统会根据以下的寻址公式在内存中开辟一道空间:
a[i]_address = base_address + i * data_type_size
如果是下标从1开始,公式就会变成这样:
a[i]_address = base_address + (i-1)*type_size
我们可以看到,如果是从1开始每次寻找该数组的地址都要进行减1 ,别看这一个小小的减1。当我们的数组元素过多的时候,进行的减1也变多了。这样程序运行的速度就变慢了,占的内存也更多了。那么如果我们从0开始的话就不会出现每次寻址的时候都要进行减1这样的操作。
5、数组作为函数参数
5.1冒泡排序函数的错误设计
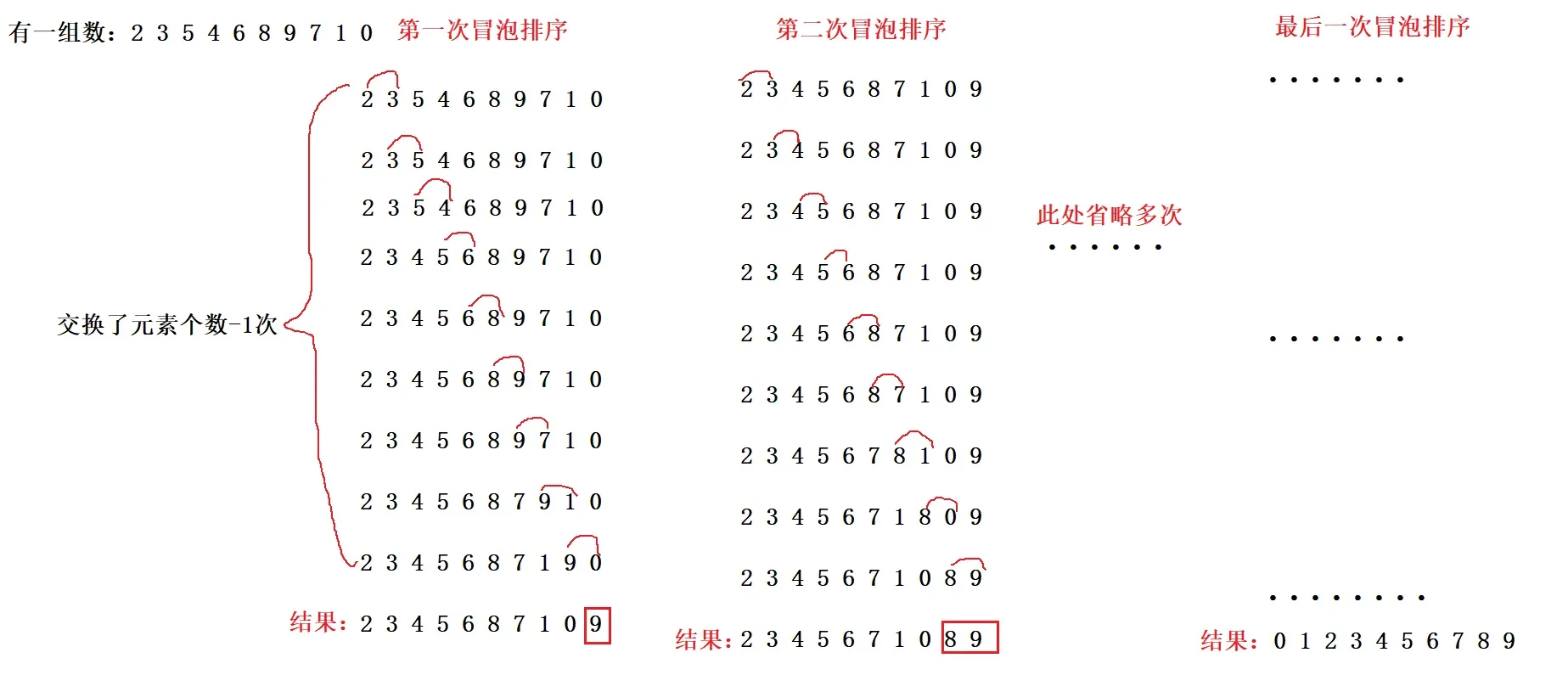
首先我们要知道到冒泡排序是什么意思,冒泡排序就是给你一组无序的数据。让你依次判断两数之间最大的数,直到把最大的数放到最后。假设数组有n个元素,那么就判断n-1次。因为当你判断n-1次的时候最大的数已经是在数组的最后一位了。我们来看一个图来理解:
🤼我们来看错误的设计:
#include<stdio.h>
void MaoPao(int arry[])
{
int n = sizeof(arry) / sizeof(arry[0]);//数组大小
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - 1 - i; j++)
{
int tmp = 0;
tmp = arry[j];
arry[j] = arry[j + 1];
arry[j + 1] = tmp;
}
}
}
int main()
{
int arry[] = { 2,3,5,4,6,8,9,7,1,0 };//初始化数组
MaoPao(arry);
int n = sizeof(arry) / sizeof(arry[0]);//数组大小
for (int i = 0; i < n; i++)
{
printf("%d ", arry[i]);
}
return 0;
}输出结果:2 3 5 4 6 8 9 7 1 0
因为实参在传参的时候传过去的是arry数组的首地址,sizeof首地址/sizeof首地址=1。所以导致程序没有发生改变。
为什么会出现输出的结果还是原数组的值的,原因就是我们传参过去参数问题。具体解释如下:
5.2数组名到底是什么?
🤼数组名就是数组首元素的地址,我们来验证一下:
#include<stdio.h>
int main()
{
int arry[] = { 1,2,3 };
printf("%p\n", &arry[0]);
printf("%p\n", arry);
printf("%d\n", *arry);
return 0;
}输出:
012FF7AC
012FF7AC
1第一个printf输出的是1的地址,就是首元素的地址。
第二个printf输出的是arry数组名的地址,同时输出的也是首元素的地址,可见数组名就是首元素的地址。
第三个printf输出的是对arry数组名的地址的解引用,输出1说明了数组名就是一个地址且是数组首元素的地址。
以上三个例子都说明了,数组名等同于数组首元素地址。也就是以后我们可以通过数组名来进行操作数组。
但是有两个例外:
- sizeof(数组名),这里的sizeof取的是整个数组的大小。
- &数组名,这里的数组名表示整个数组,&数组名取出的是整个数组的地址。
🤼♀️我们再来看一个代码:
#include<stdio.h>
int main()
{
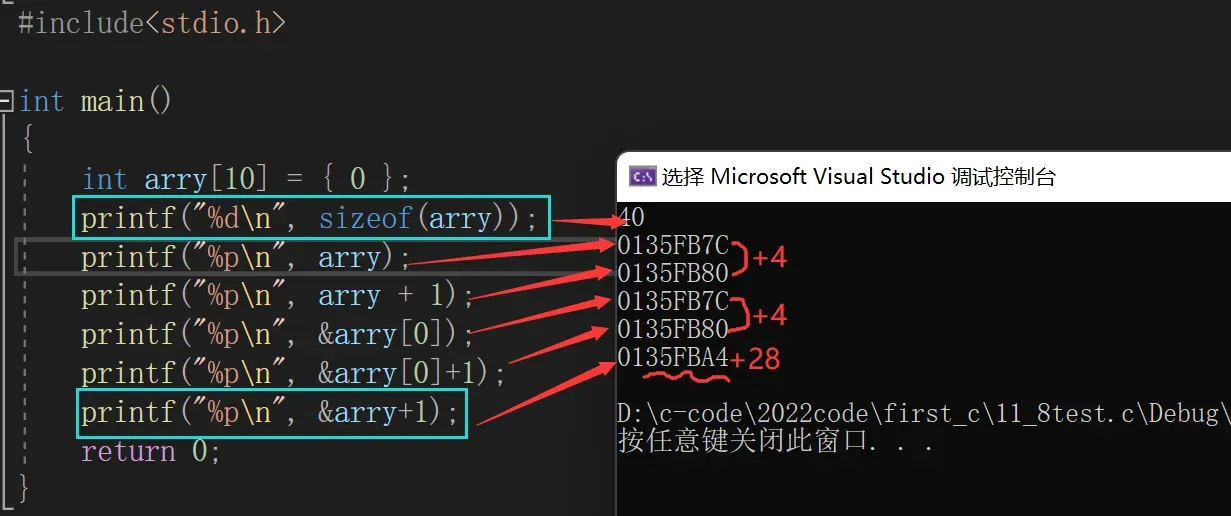
int arry[10] = { 0 };
printf("%d\n", sizeof(arry));
printf("%p\n", arry);
printf("%p\n", arry + 1);
printf("%p\n", &arry[0]);
printf("%p\n", &arry[0]+1);
printf("%p\n", &arry+1);
return 0;
}输出:
40
012FF77C
012FF780
012FF77C
012FF780
012FF7A4第一个printf证明了sizeof(数组名)是取整个数组的大小。最后一个printf证明了&数组名取的是整个数组地址,只能说数组名的地址是首元素的地址也是整个数组的地址。不同的情况具体分析。
可能还有小伙不懂上图中是怎样观察到不同的,这就与我们的十六进制知识有关了。我们只看后两位,7C到80加4H(4D),7C到A4+28H(40D)。H代表十六进制,D代表十进制。也就是说最后一个printf输出的整个数组的地址+1后的地址值。
5.3冒泡排序函数的正确设计
#include<stdio.h>
void MaoPao(int arry[],int n)
{
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - 1 - i; j++)
{
int tmp = 0;
if (arry[j] > arry[j + 1])
{
tmp = arry[j];
arry[j] = arry[j + 1];
arry[j + 1] = tmp;
}
}
}
}
int main()
{
int arry[] = { 2,3,5,4,6,8,9,7,1,0 };
int n = sizeof(arry) / sizeof(arry[0]);
MaoPao(arry,n);
for (int i = 0; i < n; i++)
{
printf("%d ", arry[i]);
}
return 0;
}
输出:0 1 2 3 4 5 6 7 8 9
以上我们在传参之前就求好数组元素的个数,再把求好的数组元素个数传给MaoPao函数。这样就可以做到万无一失了。
本期博客到这里就结束,感谢各位的耐心观看。

Nave Give Up
拳击哥的主页
文章出处登录后可见!