目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于深度学习的垃圾分类识别方法
课题背景和意义
随着我国的生活水平不断提高,垃圾问题也逐渐成为人们关注的问题。在生 活的过程中,我们或多或少都会制造垃圾。尤其是我国是全世界人口最多的国家, 可以想象到在一天里所制造的生活垃圾的数目是多么惊人。在由生态环境部所公 布的《2019 年全国大、中城市固体废物污染环境防治年报》中显示,在 2018 年 里,在全国中的 200 个大、中城市里生活垃圾产生量为 21147.3 万吨,处置量为 21028.9 万吨,处置率达到了 99.4%。虽然垃圾分类问题已经变成社会重点关注的问题之一,但这个问题也依旧没 有很好地解决。尽管垃圾投放处放置了用来投放不同分类的垃圾的垃圾桶,但是 由于垃圾分类投放的意识还未深入人心,还是会出现大量垃圾没有进行分类的情 况,把各类不同的垃圾混杂在一起投放。这种情况也导致了给后续垃圾场的垃圾 分类、垃圾回收、垃圾处理等工作带来不小的麻烦。最后主要的分类手段还是垃 圾场员工进行人工分类。所以我们可以帮助进行垃圾分类进而提高垃圾分类的效 率或者监督人们进行垃圾分类从最开始在投放垃圾时就减少未分类的垃圾的数 量,进而减少垃圾场的工作量。
实现技术思路
一、目标检测算法对比研究
SSD
SSD 算法的英文全名是 Single Shot MultiBox Detector,从名字中的 Single Shot 就能看出 SSD 算法是属于 one-stage 目标检测算法,从 MultiBox 可以看出 SSD 算法采用了多框预测的方法。
1、设计理念
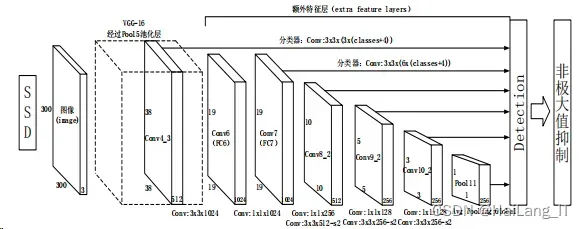
SSD 算法只通过了一个卷积神经网络对不同的特征图做处理。SSD 的基本 框架如图所示。SSD 算法的设计想法引入多尺度特征图。该算法用卷积进行 检测,并对先验框进行设置。
第一,在检测的过程中,使用不同大小的特征图。就 CNN 网络而言,开始 的特征图较大。之后通过 conv 层和 pooling 层来缩小特征图。如图所示,把 一个大的特征图和小的特征图都做检测。这样就可以更合理的检测物体,较小的 物体可以用较大的特征图进行检测,而较大的物体可以用较小的特征图进行检测。
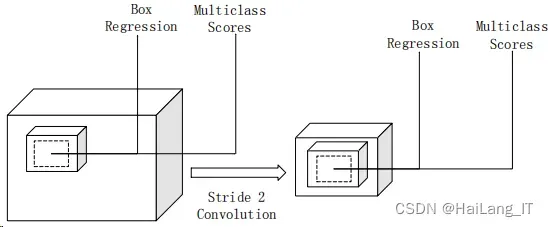
特征图如下图所示,图中有很多网格,每个网格都可以当成 anchor,每个网 格都对应于原图片中的一组特征,然后对这些特征进行分类和回归。
第二,SSD 算法对所有的特征图做提取。在对形状大小不一的特征图进行检 测时,如大小为a × b × c的特征图,都只用大小为3 × 3 × c的卷积核。
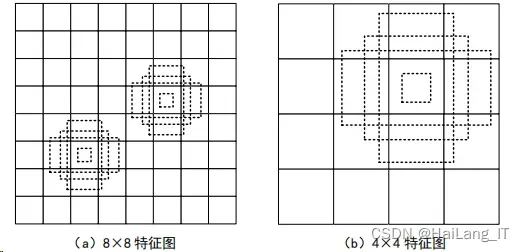
第三,在 YOLO 算法中会在每个单元中预测多个边界框。但实际被检测的 物体的形状往往是各有不同的,所以就需要 YOLO 算法在训练中逐步适应检测 物体的形状。
在 SSD 中,不同的先验框有它们特殊的检测值。这一套检测值都表示着一 个边界框,每套检测值都是由两个值组成。编码公式如下式所示。
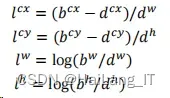
上面四个公式是边界框的编码公式。而当我们需要得到真实值时,我们就可以用编码公式变化得到,反向推得真实值。
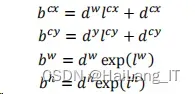
2、网络结构
SSD 模型是用 VGG-16 做了一些改进。他在 VGG-16 之后添加了 conv 层。 这些 conv 层都为最后的检测提供数据。其中 SSD 模型的网络结构如下图所 示。
Faster R-CNN
Faster R-CNN 是 2016 年 Ross B. Girshick 在对 Fast R-CNN 进行改进后提出 的新模型。它引入了 anchor box 和用 RPN 代替了 Fast R-CNN 中的 Selective Search 方法提取候选框。在结构上,Faster R-CNN 已经把目标检测的所有步骤都放到了 一个网络中。.
1、整体框架
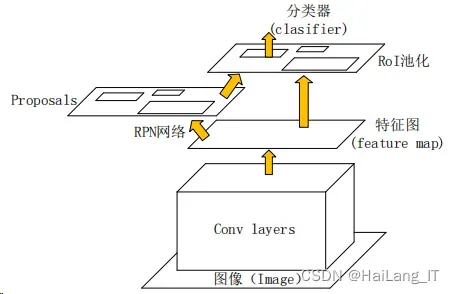
Faster R-CNN 可以分为四个主要内容,Faster R-CNN 基本结构图如下图所示。Faster R-CNN 中主要内容有:
(1)Conv layers。这是一种目标检测的方法。在 Faster R-CNN 中先将整张 图片作为输入。最后输出该图像的 feature map,为后面的使用做准备。
(2)RPN 网络。RPN 网络首先通过 softmax 判断锚框中是前景还是背景。 接着用边框回归(Bounding Box Regression)的方法修正锚框得到更准确的候选 区域。
(3)RoI pooling。感兴趣区域池化层将特征图和候选区域等数据联合处理, 从中得到候选区域的特征图。最后将该特征图输入全连接层计算出候选区域中目 标物体的类别。
(4)Classifier。分类器利用前几步得到的候选区域的特征图判断出候选区 域的类别。最后再次使用边框回归得到检测框的准确位置。
2、网络结构
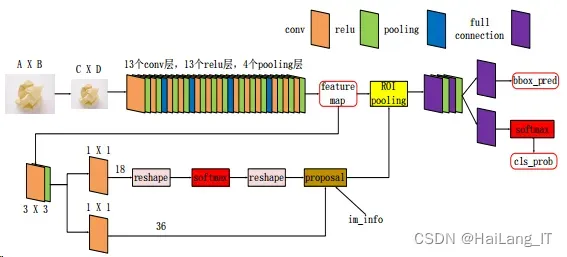
Faster R-CNN 网络可以将任意大小的图片改变到C × D大小。而 Conv layers 中包含了 13 个 conv 层、13 个 relu 层和 4 个 pooling 层。Faster R-CNN 网络结构 图如图所示。
3、Conv layers
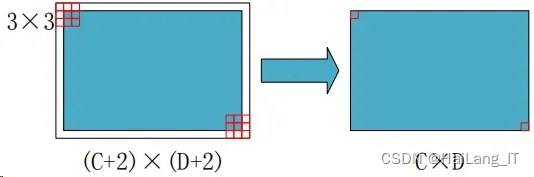
Conv layers 中包含了 conv 层、relu 层和 pooling 层这三种层。并在做卷积时 都要对矩阵做扩边处理。卷积示意图如图所示。
4、RPN网络
它在生成候选框的方法不同于 R-CNN 中的选择性搜索方法,而是用 RPN 网 络来得到候选框。RPN 的使用也成为了 Faster R-CNN 的优点之一。RPN 网络的 结构图如图所示。
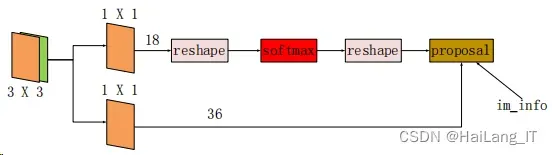
由 RPN 网络结构图看出 RPN 网络可以分为分类和定位 2 个部分。第一个部 分就如上图的上面一条首先通过过滤器进行卷积然后变形,接着使用 softmax 分 类判断窗口里是否含有物体。
5、RoI 池化及Classification
而 RoI 池化层则负责收集候选区域,并计算出候选区域特征图,送入后续网 络。从图 2-6 中可以看到 RoI 池化层有以下 2 个输入:
(1)原始的特征图; (2)RPN 输出的大小各不同的候选框。经过 RoI 池化操作后,输入大小不同的候选框输出结果都会得到固定大小, 这样就实现了固定长度输出。RoI 池化示意图如下图所示。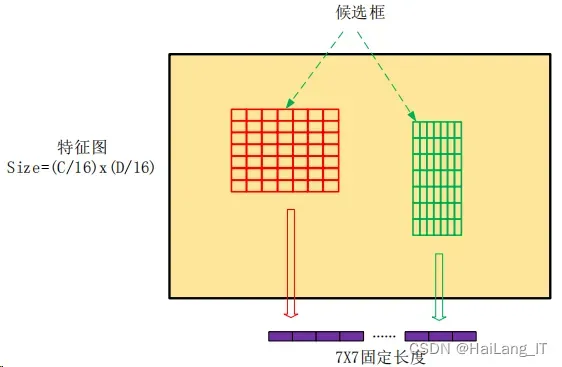
在 Classification 中也分为分类和定位两部分。第一部分用在 RoI 池化后得到 7 × 7大小的候选区域特征图,经过全连接层和 softmax 推测出该目标物体的种 类,并得到 cls_prob。第二部分则是利用边框回归得到 bbox_pred。这两个部分就 是 Classification 里做的工作。Classification 部分网络结构如图所示。
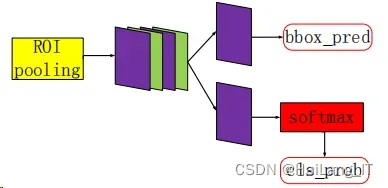
其中第一部分里的全连接层简单的示意图如图所示。
它的计算公式如下式所示。
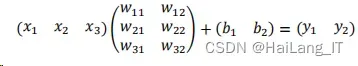
YOLOv3
YOLOv3 主要的改进之处有:利用多尺度特征进行对象检测; 由于 softmax 不适用于多分类,所以用 Logistic 分类器替换了 softmax;调整了网 络结构,并提出了一个新的网络结构 Darknet-53。
1、Darknet-53网络
Darknet-53 在 YOLOv2 的 Darknet-19 的基础上加入了类似残差网络的残差 单元的结构。该结构成功克服了梯度爆炸的难题。所以 Darknet-53 网络中增加了 网络层数。
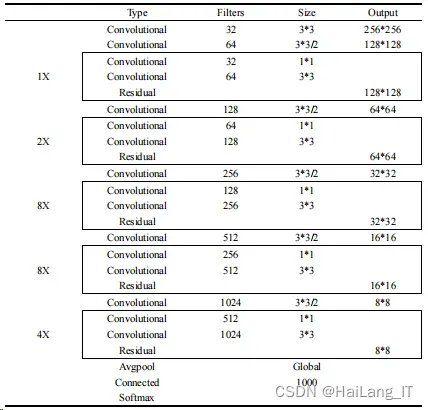
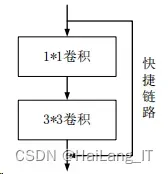
Darknet-53 是全卷积网络,使用了大量的残差的跳层连接。YOLOv3 将 YOLOv1、YOLOv2 网络中的 pooling 进行删除。并直接采用 stride 为 2 的卷积来 改变大小。其中 Darknet-53 中的残差基本单元如下图所示。
2、构建多尺度特征
YOLOv3 采用了 FPN 的构建多尺度特征的方法,在不同尺度大小的情况下 进行特征的提取。YOLOv3 构建了三个不同尺度大小的特征图,它们都是通过上 采样的方式对特征图进行构建的。
3、anchor box聚类
YOLOv2 借鉴了 Faster R-CNN 和 SSD 中使用的锚(anchor)机制,YOLOv3 也和 YOLOv2 一样的引入锚框(anchor box)做检测。
计算框和类中心之间的距离的计算公式如 下式所示。
![]()
4、位置预测及非极大值抑制
在进行位置预测时,YOLOv3 会按照不同特征图的尺度将每个图像平均分为 S × S份。就可以得到S × S个格子,其中特征图里的每个格子都会预测 3 个边界 框。在每个框中都会对该框的位置、置信度和类别概率这三个参数进行预测。
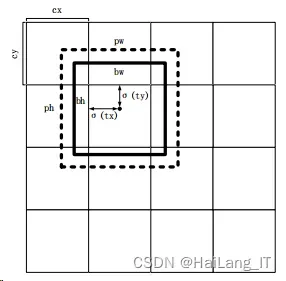
根据每个格子的坐标𝑐𝑥和𝑐𝑦,以及前面得到边界框的宽𝑝𝑤和高𝑝ℎ,预测框可 以对边界框按公式进行计算。
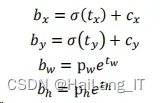
5、类别预测
因为 softmax 分类器无法对多标签进行分类,所以 YOLOv3 则采用了多个 logstic 分类器去把一个多路 softmax 分类器替换掉的方案。同时 YOLOv3 使用了 二元交叉熵。YOLOv3 使用 logstic 分类器取代 softmax 分类器来进行分类的原因有以下两个:
(1)softmax 分类器只能让每个边界框分类到分类得分最高的一个类别中, 而且能用 softmax 分类器的条件是类别必须是互斥的,所以它不适合使用于有包 含属性关系的分类任务中。
(2)softmax 分类器可以由多个独立的 logistic 分类器置换,分类损失函数 也换为二元交叉熵。
二、垃圾数据集的制作
数据集组成
本实验的垃圾数据集的图片来源主要有三部分,分别为:
(1) 实地拍摄垃圾图片;
(2) 2019“添翼杯”人工智能创新应用大赛-智能环保数据集;
(3) 通过上面两个的图片扩增得到的数据集。
其中 2019“添翼杯”人工智能创新应用大赛-智能环保数据集里很多图片是完 好的物品,不属于垃圾,所以选取其中少数符合条件的垃圾图片。
数据集制作
1、PASCAL
VOC2007数据集制作 本文要用 Faster R-CNN 和 YOLOv3 这两种算法模型来用于对垃圾分类进行 识别。而 Faster R-CNN 和 YOLOv3 都可以用 PASCAL VOC2007 格式的数据集。 为了不做重复性工作。所以本次就类比 PASCAL VOC2007 数据集来自制垃圾数 据集。这种数据集的目录结构如图所示。

2、数据集扩充
数据集图片的质量和数量会对网络的训练结果产生很大程度的影响。所收集 到的垃圾数据集中的图片数量不够,会导致检测效果不好,所以为了要得到较好 的训练权重和较好的测试结果,就要扩大垃圾数据集的数量。
扩增前图片:
扩增后图片:

3、数据集标注
本文所有的通过收集和扩充得到的垃圾图片都是使用图像标注工具 Labelling 来标注的。所以本文所制作的数据集共包含 4 个类别的垃圾分类,并都 使用英文标注垃圾的类别。表列举了数据集中 4 个类别的定义名称

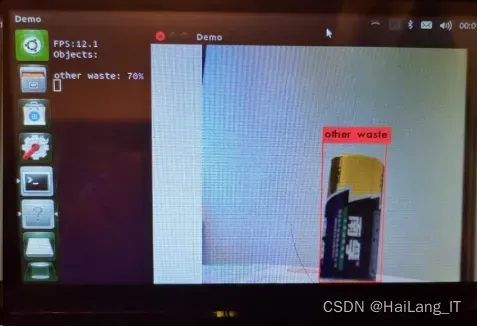
实现效果图样例
垃圾分类识别方法:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
文章出处登录后可见!