本文参考文献:基于Transformer的目标检测算法综述
网络首发时间:2023-01-19 15:01:34
网络首发地址:https://kns.cnki.net/kcms/detail//11.2127.TP.20230118.1724.013.html
在本文中约90%的文字和80%的图片来自该论文,这里只作为学习记录,摘录于此。
1.摘要
深度学习框架Transformer具有强大的建模能力和并行计算能力,目前基于Transformer的目标检测算法已经成为了研究的热点。为了进一步探索目标检测的新思路、新方向,对基于Transformer的目标检测算法进行归纳总结。概述多种目标检测数据集及其应用场景,并从特征学习、目标估计、标签匹配策略和算法应用四个方面梳理了Transformer目标检测的相关算法,将其与卷积神经网络的目标检测算法进行对比,分析了Transformer在目标检测任务中的优点和局限性,并提出了Transformer目标检测模型的一般性框架。最后,对Transformer在目标检测领域中的发展趋势进行了展望。
2.关键词
Transformer;图像处理;目标检测;深度学习;卷积神经网络
3.什么是目标检测?
目标检测任务就是对于给定图片或视频,将待检测目标在图像中的位置找出来并识别其类别。
随着设备计算能力的提高以及深度学习技术的发展,基于深度学习的目标检测算法已经成为了研究的热点,并取得了显著的成果。自2014年Girshick等人提出R-CNN以来,卷积神经网络(Convolutional Neural Network, CNN)在目标检测领域一直占据着主导地位,利用CNN由浅入深的抽取图像的语义特征,受益于卷积核的平移不变性和局部敏感性,CNN可以充分的提取局部时空特征以实现较高精度的检测和识别,但是卷积操作缺乏对图像全局信息的感知,无法建模特征之间的依赖关系。因此,研究者们尝试将自然语言处理领域中的Transformer模型迁移到计算机视觉任务中。相较于CNN,Transformer可以建模图像的全局依赖关系,能够更加充分的利用上下文信息,其已经被证实可以应用到多种视觉任务中,如:图像分类、目标检测和图像分割等,并展现出了巨大的潜力。2020年Carion等人提出了一种新型的Transformer目标检测框架DETR(Detection Transformer),为Transformer在目标检测任务中的应用奠定了重要的基础,后续出现了大量基于DETR的改进算法。2020年Beal等人提出的ViT-FRCNN则是用Transformer代替卷积骨干的代表性算法,基于注意力机制对图像全局特征进行编码。由于Transformer目标检测算法在标准数据集上取得了优异的性能,所以研究者们便尝试将其应用到各种实际场景中,为各领域提供了更新的解决方案,涌现了许多优秀的Transformer目标检测模型。
本文以目标检测模型训练过程中的特征学习、目标估计和标签匹配三个关键环节为角度进行切入,综述相关文章的设计方案和改进思路,可以更清晰的揭示Transformer在目标检测任务中应用的原理和思路。另外,本文注重对Transformer和CNN做多方位的对比,并提出了Transformer目标检测模型的一般性框架。
4.常用目标检测数据集
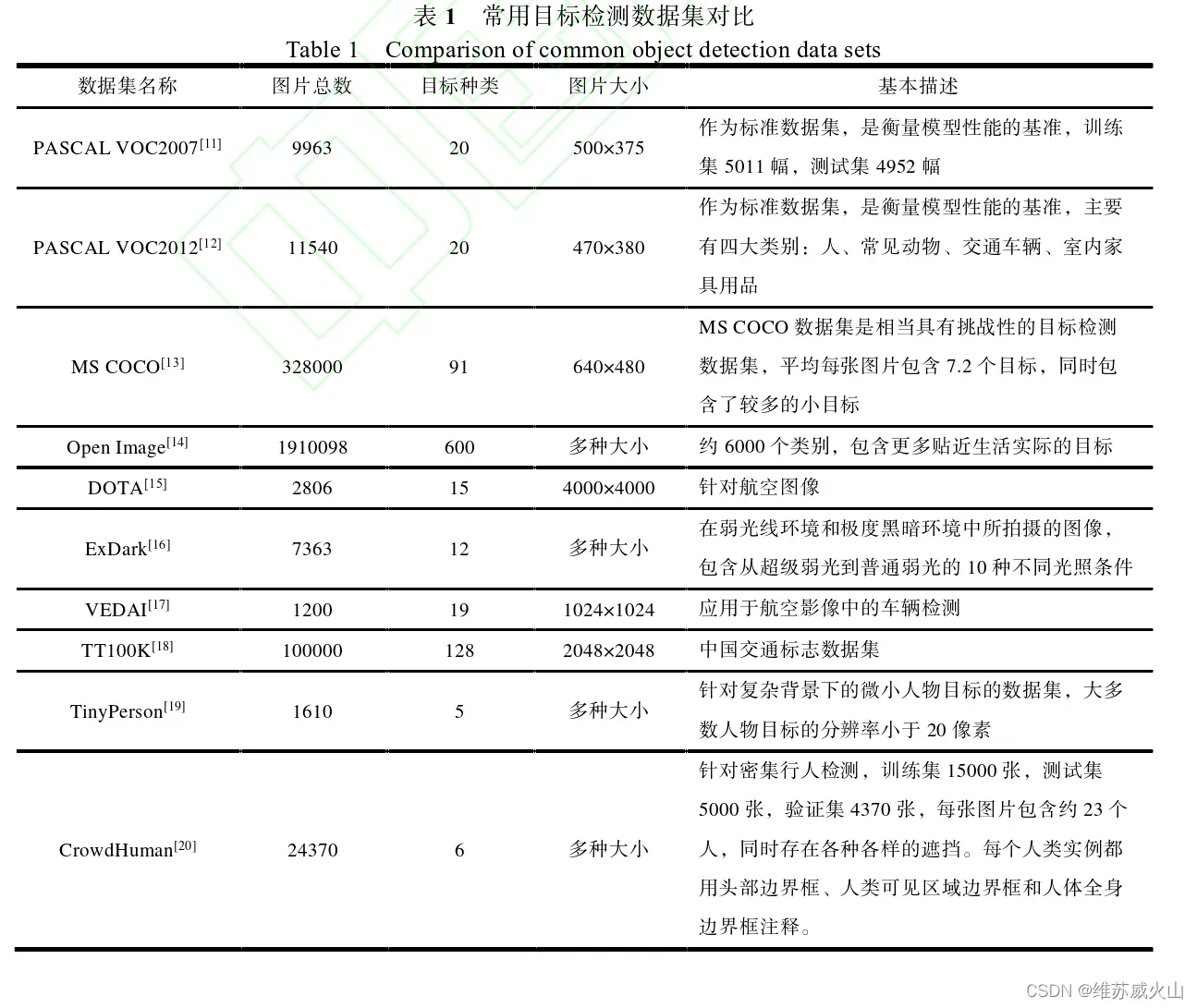
5.基于Transformer的目标检测算法
基于CNN的目标检测算法的训练流程主要由特征学习、目标估计和标签匹配策略三部分组成,而基于Transformer的目标检测算法拓展并促进了上述三个过程的实现方式:
(1)特征学习:基于Transformer的特征学习方式主要有两大类:直接编码序列化后的图像块和对CNN输出的特征做进一步的编码。
(2)目标估计:CNN目标检测算法依赖于卷积、池化和对齐等机制来获取局部特征,并对局部特征内目标的位置和类别信息进行处理和预测,而Transformer目标检测算法基于注意力机制,使用目标查询向量聚合图像特征,以形成对象的代表。
(3)标签匹配策略:CNN目标检测算法的标签匹配依赖于先验设计,如:重叠度(IoU)、锚框(Anchor)、网格(Grid)和宽高比等。而Transformer目标检测算法一般采用集合预测的方式,设计了不依赖先验知识的标签匹配方法。
5.1 基于Transformer的特征学习
谷歌在ICLR2020上提出的ViT(Vision Transformer)是将Transformer应用在视觉领域的先驱。在特征学习方面,Transformer相较于CNN有更大的感受野、更灵活的权重设置方式以及对特征的全局建模能力,因此基于Transformer的骨干网络有潜力为下游任务提供更高质量的特征输入。
5.1.1 ViT-FRCNN
ViT-FRCNN是将Transformer作为骨干网络用以编码图像特征的代表性算法,模型结构如图1所示,编码器对序列化的图像输入进行全局交互以编码图像特征,为了充分利用图像特征,将编码器所有的输出重构为空间特征,馈入Faster R-CNN检测头对目标的类别和位置进行推理。ViT-FRCNN引入了基于Transformer的骨干网络,并取得了有竞争力的目标检测性能,证明了可以将ViT(Vision Transformer)学习到的分类特征有效的转移到目标检测任务上,并在拥有足够多的数据做预训练的情况下,ViT的特征提取能力将超过CNN。
论文地址:Toward Transformer-Based Object Detection

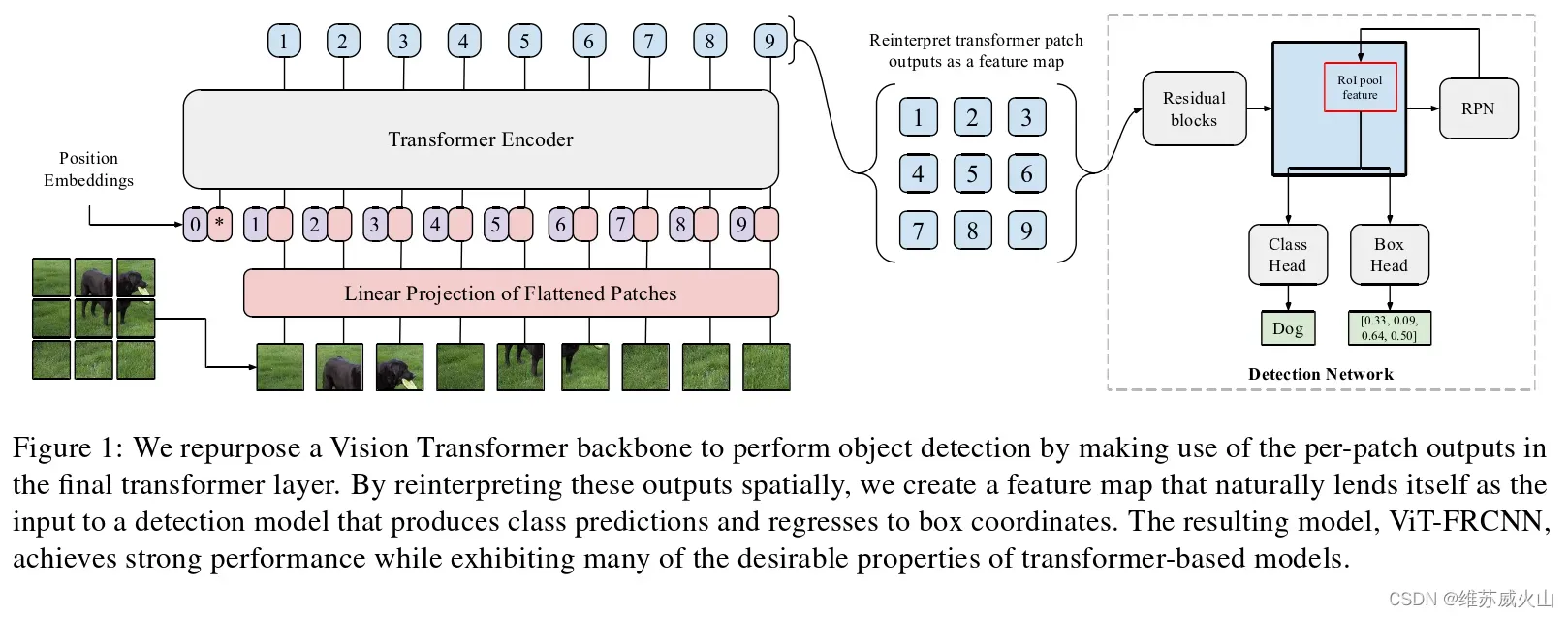
但ViT-FRCNN在处理高分辨率图像时产生了较大的计算量,对于目标检测模型,是否能高效的处理高分辨图像是十分关键的,高分辨的输入可以使顶层特征包含更丰富的语义信息,尤其是小目标的信息。另外,将Transformer骨干引入到目标检测模型中的研究仍处于起步阶段,一方面,序列化操作破坏了图像的空间特征,另一方面,ViT-FRCNN直接采用标准Transformer编码器结构编码图像特征,并且只将编码器最终层和中间层的输出加以重构利用,因此,其在特征表达能力方面仍需要进一步的改进。
5.1.2 降低Transformer的计算量
Transformer的计算量主要来自于注意力机制,因此,缩短注意力层的输入序列是降低计算量的有效手段,具体方法可以分为约束注意力机制关注范围以及输入下采样两大类。
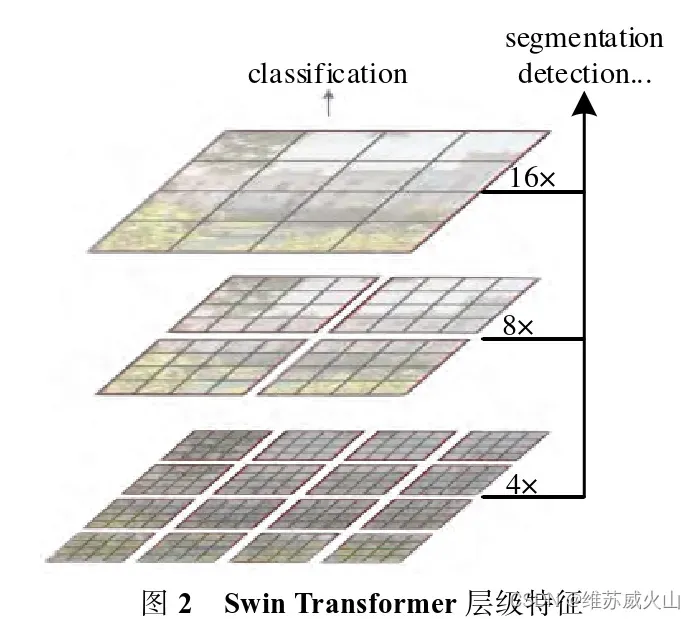
1)注意力局部化:Liu等人(2021)提出了一种使用滑动窗口的Swin Transformer模型,构建了一种层次化Transformer,并引入局部化思想,将注意力计算限制在窗口内,设计了Transformer层级特征,如图2所示。这种层级特征使得Swin Transformer能够很方便的利用一些多尺度特征处理技术来进行密集预测,例如特征金字塔网络(Feature Pyramid Networks, FPN)和语义分割网络U-Net等。Swin Transformer相较于ViT,计算量大幅降低,并可以作为通用的视觉骨干网络。进一步的,Liu等人从视觉大模型的角度出发,在Swin Transformer的基础上设计了Swin TransformerV2,它是具有30亿参数的稠密视觉模型,极大的拓展了模型的容量和分辨率,在迁移到各大视觉任务中时取得了极佳的性能。但是,Swin Transform仍然沿用CNN目标检测模型的检测网络,这导致了模型依赖精细的先验设计,这为调参和端到端的训练都带来了很大的困难,此外,Swin Transformer对相邻patch的合并操作会导致局部细节信息的丢失。
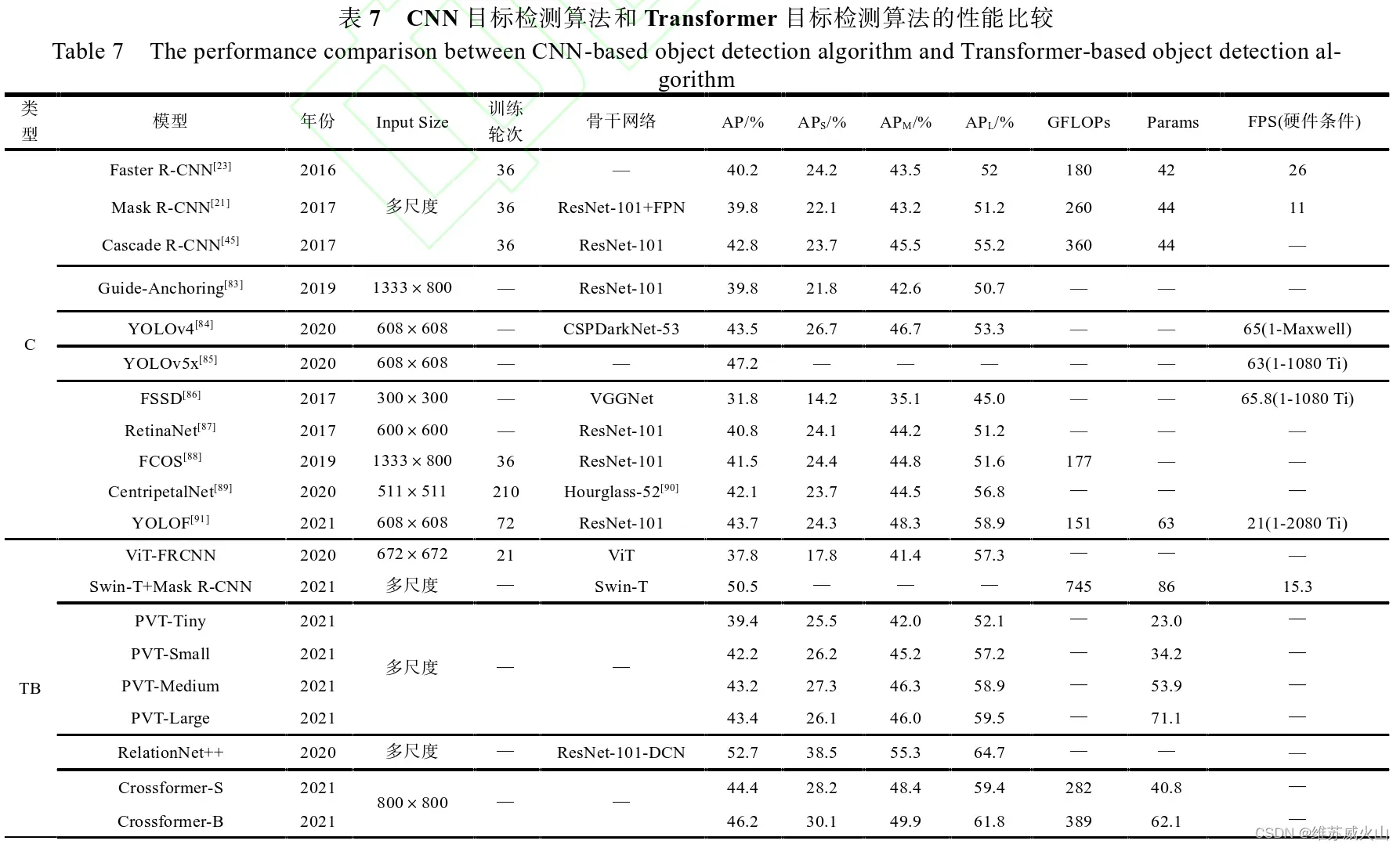
2)输入下采样:Wang等人(2021)提出了基于Transformer的无卷积主干网络PVT(Pyramid Vision Transformer),设计了一种渐进式衰减金字塔结构(Progressive Shrinking Pyramid)和一种空间缩减注意力(Spatial-Reduction Attention)机制,**通过图像分辨率的层级式衰减来降低输入序列的长度,减少了模型的计算量。**表2展示了在COCO数据集上,采用不同骨干网络的RetinaNet在目标检测任务中的性能对比,表中,T、S、M和L分别表示PVT的Tiny、Small、Medium和Large版本。可以看出,当模型的参数量相当时,PVT的性能显著优于其他模型,但当输入图像的分辨率超过640×640时,计算效率有所下降。


5.1.3 增强Transformer的特征表达能力
增强Transformer的特征表达能力是提升目标检测性能的关键环节,一方面可以借鉴传统目标检测中多尺度特征的思想,综合多种特征表征形式实现特征的增强,另一方面可以将Transformer的全局交互能力和CNN的局部性特点相结合来丰富特征多样性,此外,对单一的全局自注意力机制进行拓展,设计新颖的注意力机制从多角度聚合特征也是增强Transformer特征表达能力的重要方法。还有被设计主要用于实现分类任务的模型也提出了多种增强特征表达能力的方法,这对目标检测任务同样有十分重要的借鉴意义,例如:
DeepViT提出了增加词嵌入维度和重注意力(Re-attention)机制来避免注意力塌陷现象;DiversePatch提出的丰富特征多样性的方法以及Refiner提出的注意力扩张(Attention expansion)和注意力缩减(Attention reduction)模块等方法。
(1)改进特征表征形式
(2)多尺度特征交互
(3)Transformer与CNN相结合
- CNN是基于临近像素具有较大相似性这一假设而形成的归纳偏置,局部性是它的典型特征,而Transformer则对特征进行全局交互,因此,二者特征学习的方式和特征编码的内容有较大的差异,图3展示了在浅层和深层中ResNet-101和DeiT-S的特征图的对比,可以看出,CNN充分保留了局部信息,Transformer建模了全局信息,但提取到的局部细节信息明显恶化,将Transformer和CNN相结合是提高模型特征提取能力的有效手段,下面从结构融合、特征融合和机理融合三个层面介绍Transformer和CNN结合的方法。

1)结构融合:旨在通过对多个模块进行有效的组合形成新的网络结构。Guo等人(2021)设计的CMT通过深度卷积提取图像的局部特征,注意力模块在此基础上建模特征的全局依赖关系,并在模型多处采用残差链接保留局部特征,并实现局部特征与全局特征的结合。MobileViT将Transformer视为一个模块,集成到卷积神经网络中,使模型同时具备局部性和全局性。MPViT采用多路并行的Encoder和卷积实现全局特征和局部特征的共享,达到了SOTA性能;
2)特征融合:该方式从特征层面入手,一般采用并行分支结构,融合CNN和Transformer提取到的特征来增强特征表达能力。Peng等人(2021)提出的Conformer模型设计了并行的CNN和Transformer分支,采用桥接模块实现特征融合。将Conformer作为Backbone,在COCO上的m AP达到了44.9%。Chen等人(2022)提出的Mobile-Former同样采用了并行分支和桥接模块,其设计了基于轻量化跨注意力机制的特征桥接方式,使得特征的融合更加有效。MobileFormer在处理高分辨率图像时有更快的推理速度,但当输入分辨率下降时,推理速度被MobileNetV3超越,这是由于桥接模块的代码实现不高效,该模块的计算量并不会随着分辨率而改变。DeiT结合知识蒸馏的思想,通过将CNN学习到的特征引入到Transformer的训练过程中,实现两种特征的融合。
3)机理融合:结构融合与特征融合通过串行或并行的方式实现Transformer与CNN的结合,但注意力机制和卷积仍然是不同的两个部分,没有充分的利用它们之间的相关性,而机理融合通过深入挖掘二者之间的内在联系,合理的集成注意力和卷积。ACmix
深入分析了自注意力与卷积特征提取机理的相似性,通过共享特征映射参数实现自注意力和卷积的机理融合,ACmix同时具有局部性和全局性,在迁移至目标检测任务中时,在COCO上的mAP达到了51.1%。
(4)注意力内容多样化
现有的Transformer目标检测模型仅采用单一的多头自注意力机制聚合图像特征,随着网络的加深,会出现注意力塌陷(Attention collapse)现象,即随着网络层数的加深,深层注意力图的相似性逐渐增加甚至趋同,导致深层Transformer的特征表达能力趋于饱和。DeepViT通过增加词嵌入维度以及对多头注意力进行动态组合来多样化注意力内容,提高深层注意力之间的差异性,以提高其特征表达能力。ViDT在原输入序列中加入了可学习的检测编码Detection Token并设计了相应的重置注意力模块(Reconfigured Attention Module,RAM),RAM涉及三种注意力:原输入序列之间的全局自注意力、Detection Token之间的自注意力以及原输入序列与Detection Token之间的交叉注意力,从三个不同的角度聚合图像特征,增强了模型的特征表达能力,但ViDT为了减少计算量和加快推理速度所采用的Encoder-free结构使得检测精度有所下降。
上述的ViT-FRCNN、Swin Transformer、PVT以及基于局部和整体交互的Cross Former、Conformer等算法都被成功迁移到了RetinaNet、Mask R-CNN、 Cascade R-CNN和Sparse R-CNN等经典的目标检测算法中,代替AlexNet、VGGNet和ResNet等卷积神经网络骨架,并取得了更高的准确率。
5.2 Transformer目标检测算法的目标估计和标签匹配策略
基于Transformer的目标检测算法通过查询机制实现对位置和类别信息的处理和预测。另一方面,基于CNN的目标检测算法的标签匹配过程依赖于一些先验设计,而基于Transformer的目标检测算法则拓展了标签匹配策略,DETR(Detection Transformer)就是其中的代表性算法。
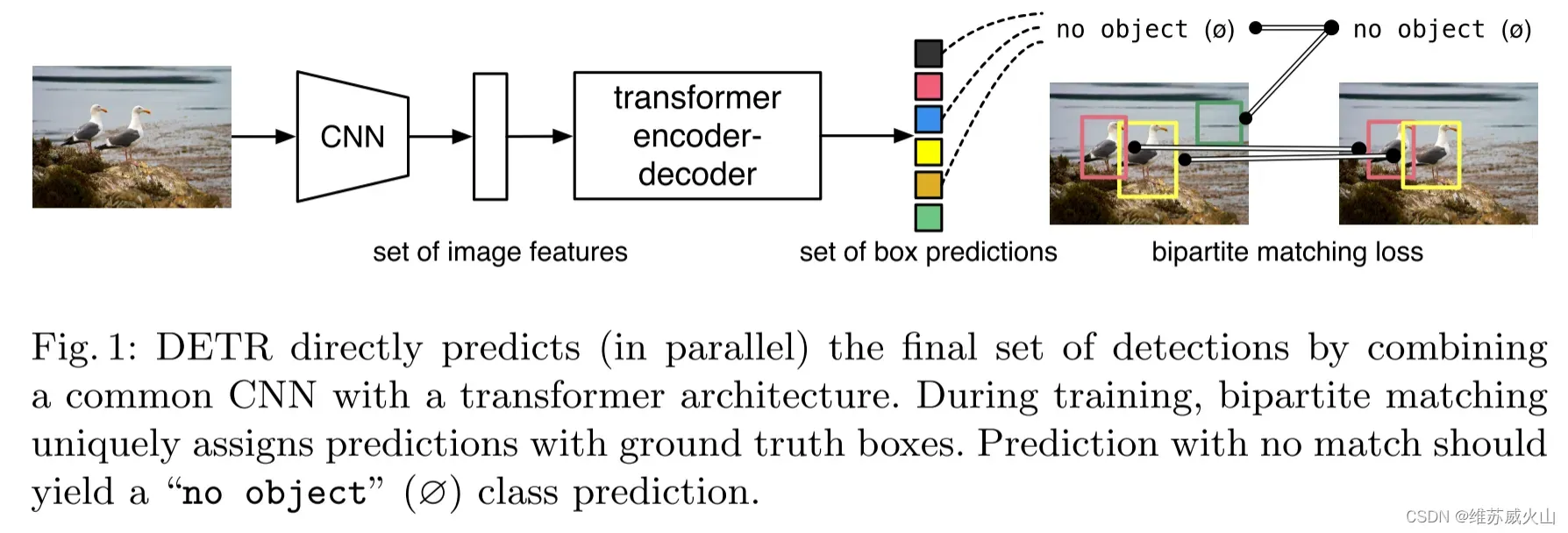
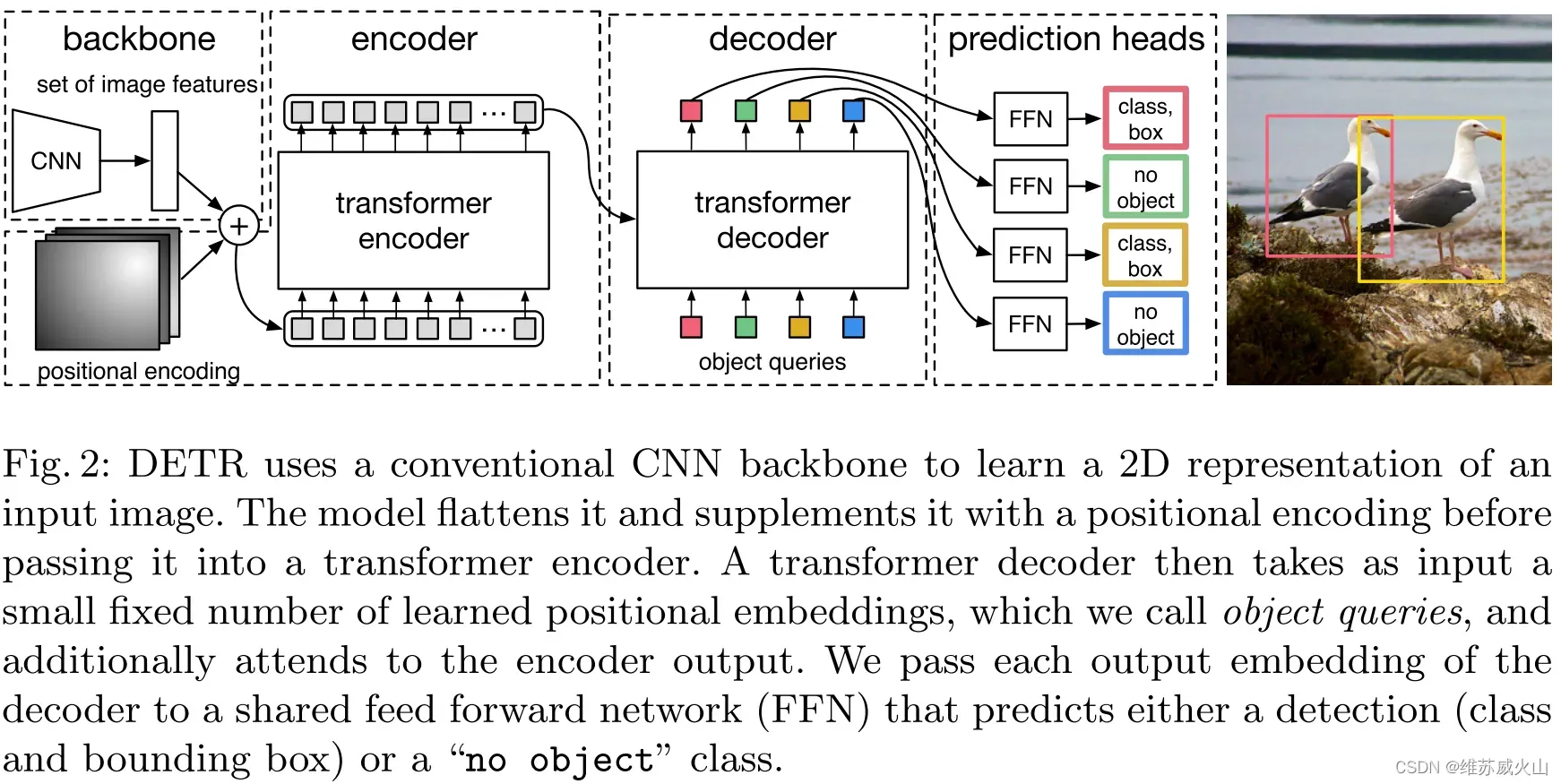
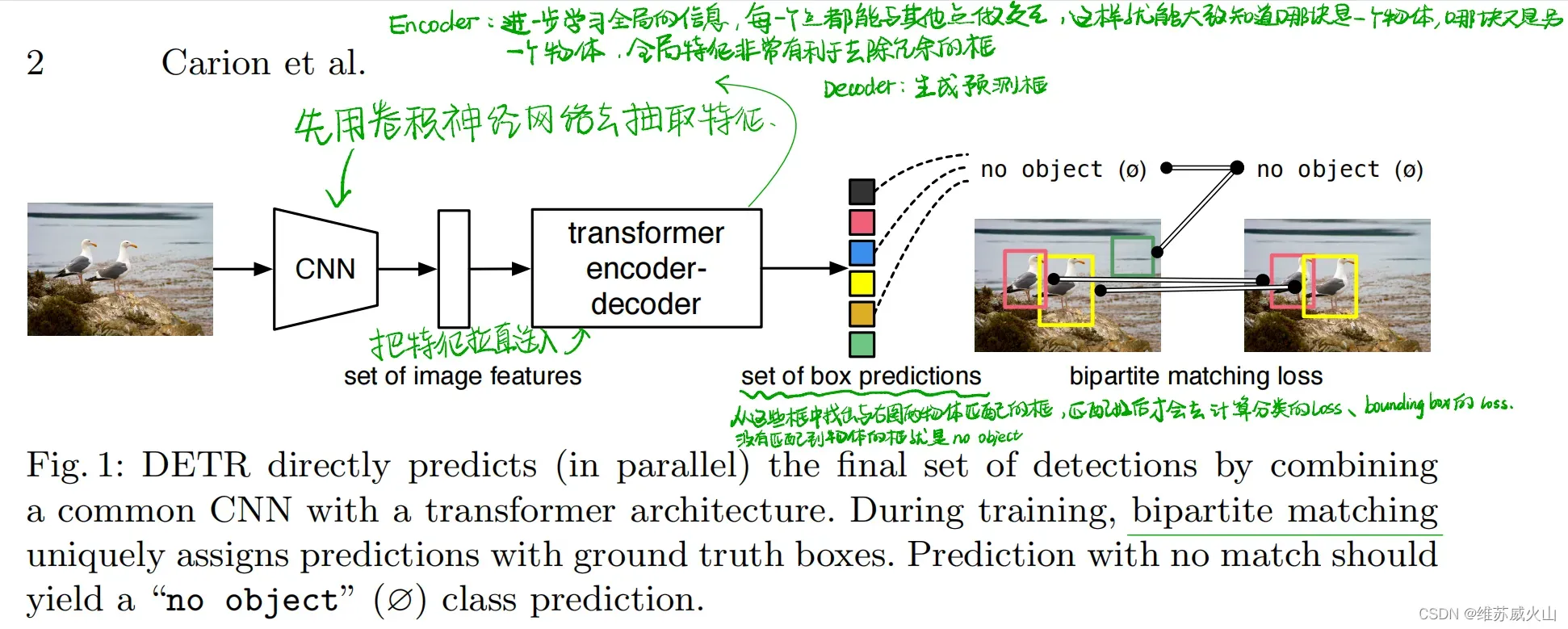
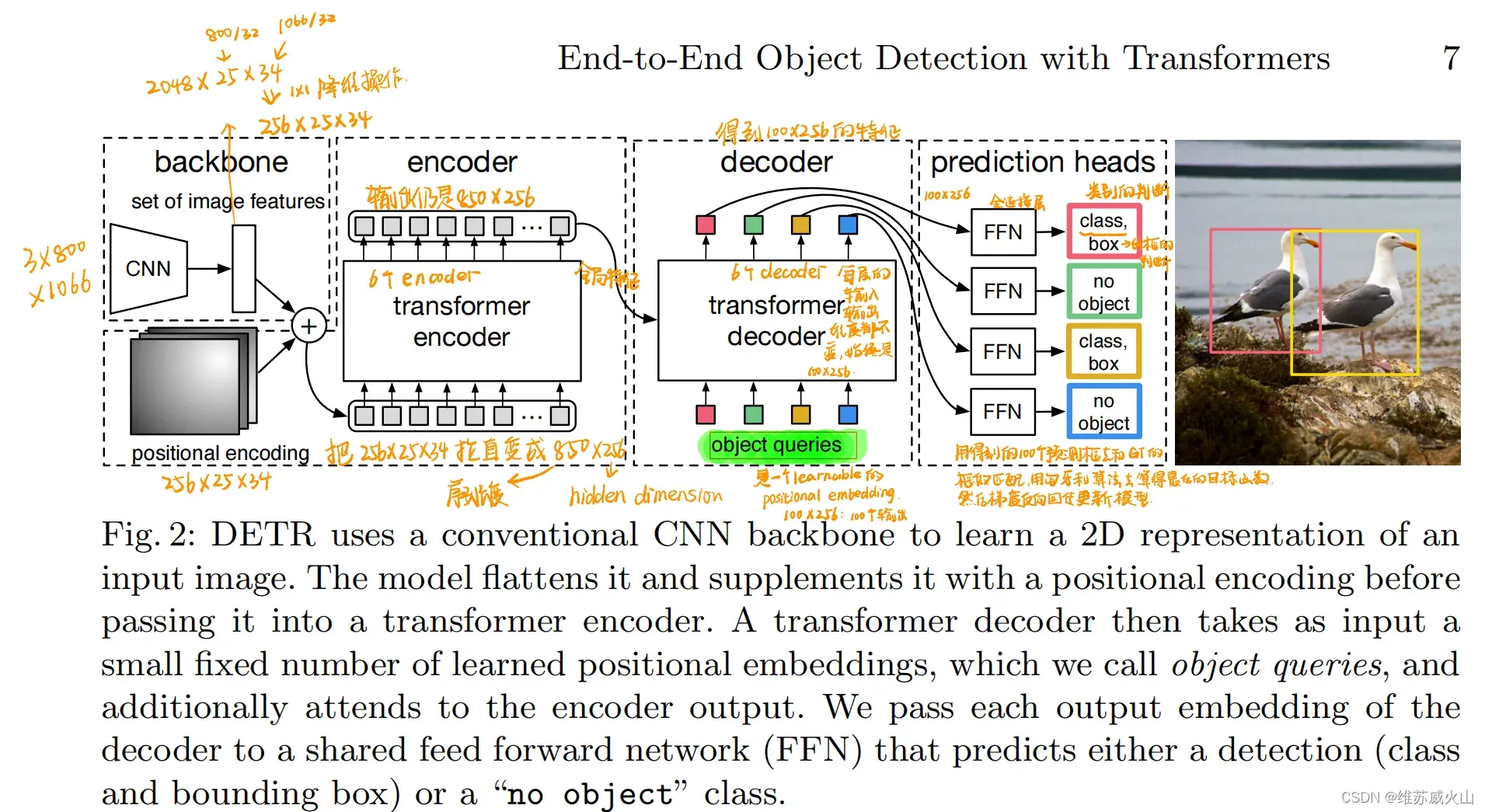
DETR将目标检测任务视为集合预测问题,一次性预测包含所有目标的集合,模型去除了先验设计和手工操作。DETR模型结构如图所示。特征学习模块采用CNN和Transformer相结合的方式进一步增强特征,然后通过目标查询向量和注意力机制关注到潜在目标的信息,从而实现了从全局信息中抽取特定的目标信息,利用FFN分析每个目标查询中的对象信息,得到预测结果集合,并使用二分匹配为结果集合赋予对应的标签,二分匹配是在得到预测结果后进行的,不依赖先验设计,且避免了大量的重复预测。
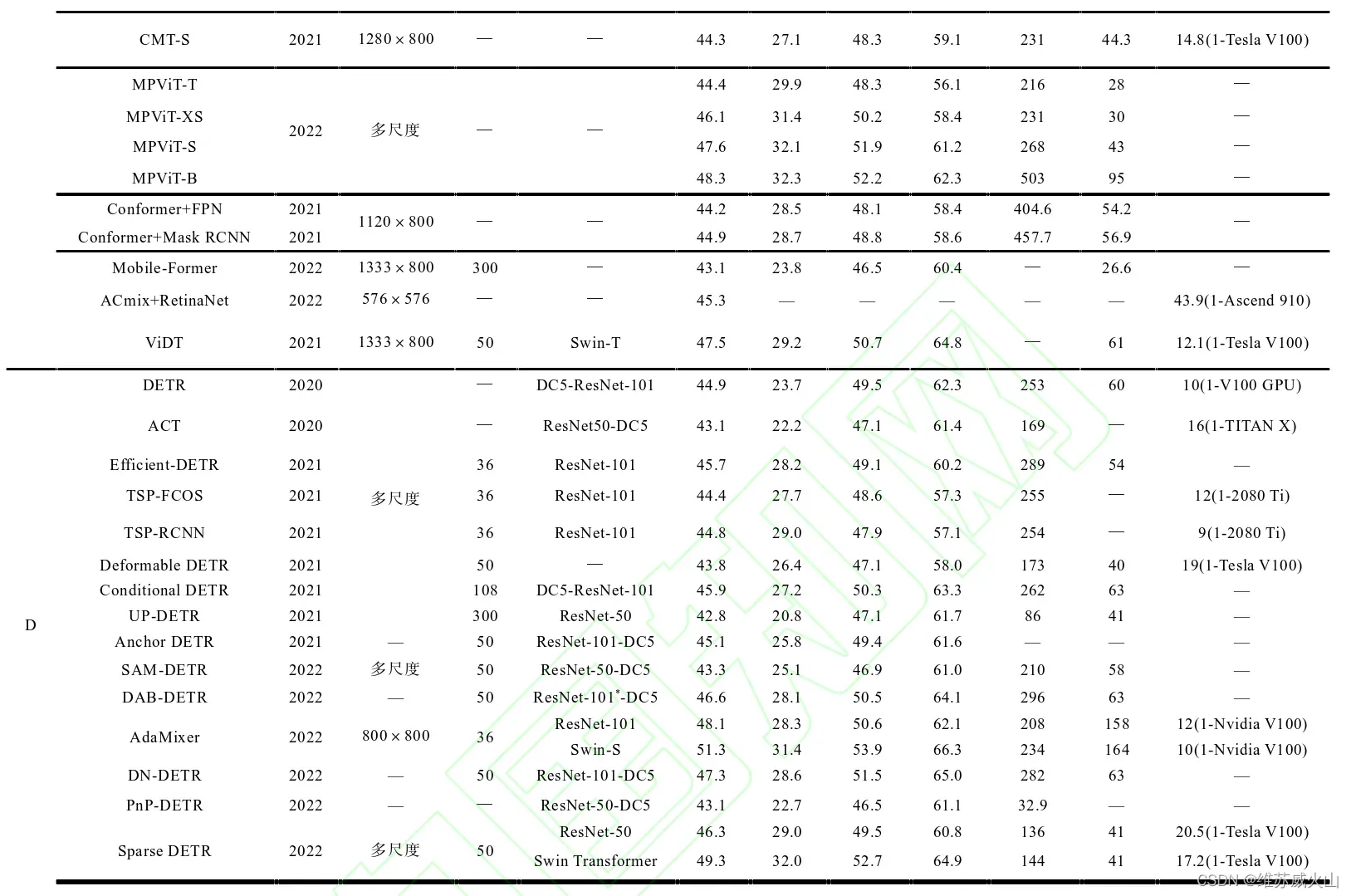
虽然DETR(COCO/44.9%mAP)取得了较高的检测精度,但DETR采用固定长度的目标查询向量与图像特征进行全局交互,这种方式需要长时间的注意力权重训练才能关注到特征图上稀疏且关键的位置,导致模型收敛时间过长,在COCO上,需要500个epochs才能收敛,比Faster R-CNN慢10-20倍,其次,对小目标检测效果较差,这主要是由于DETR仅使用单一尺度的特征进行预测以及在处理高分辨率输入时有很高的计算复杂度;最后,相较于CNN目标检测算法,DETR更加依赖数据的规模,当采用小规模数据训练时,模型性能明显下降。

6.DETR学习整理
论文地址:End-to-End Object Detection with Transformers
论文视频解读:DETR论文精读【论文精度】
对于给定的图片,我们要做的就是在其上预测出一些框,不仅要知道这些框的位置坐标,还要知道被框住的物体类别,在以往的R-CNN系列里,建议框的数量约为2000个,最后仍需经过后处理NMS操作,来筛选最恰当的预测框,在DETR中,将每张图片上的建议框看为一个集合,使用集合预测的方式进行目标检测。成功实现了端到端预测,去除了许多先验知识,如:非极大值抑制、生成anchor。

DETR文中新提出的目标函数,通过二分图匹配方法强制模型去输出一组独一无二的预测,不会输出冗余的框,每个物体只输出一个框。使用匈牙利算法,输入cost matrix,输出和GT最匹配的框。
将learned object queries 和 global image context进行联系,通过不停去做注意力操作,从而让模型直接输出最后一组预测框,而且时并行输出。2017提出的Decoder应用于NLP,采用自回归方式一点一点地预测出,而在视觉任务上,一次性地全部输出,在预测图片时没有先后顺序,无法使用自回归预测,而且并行出框比一个一个出框实时性好得多。

代码如下:

DETR算法总结
DETR检测性能强大,模型结构简单,并采用集合预测的方式,不依赖于先验设计,实现了端到端的训练。DETR逐渐成为了Transformer目标检测算法的基本框架之一。但其收敛速度慢、在小目标检测上效果较差的问题也十分明显。下表总结了类DETR系列目标检测算法的机制、优点、局限性和应用场景。针对DETR的改进主要围绕目标查询机制和模型结构简化两方面展开,例如,加快收敛速度的方法有:优化目标查询初始化、查询与特征的优化匹配、增强目标查询定位能力以及通过Decoder增强来简化Encoder部分的结构等方法;DETR解码器动态的生成注意力分布去关注不同预测对象的关键特征,DETR解码器倾向于关注对象的末端位置。


下表中,C表示基于CNN的算法,TB表示Transformer BackBone,D表示DETR系列算法。可以明显看出基于Transformer的目标检测算法的平均准确率(AP)相较于基于CNN的目标检测算法有着较大的提升。
文章出处登录后可见!