PG-Video-LLaVA: Pixel Grounding Large Video-Language Models

https://github.com/mbzuai-oryx/Video-LLaVA
将基于图像的大型多模态模型(LMM)扩展到视频领域是具有挑战性的。最近将基于图像的LMM扩展到视频的方法要么缺乏grounding定位能力(例如,VideoChat,Video-ChatGPT,Video-LLaMA),要么不利用音频信号来更好地理解视频(例如,Video-ChatGPT)。
为解决这些问题,提出PG-Video-LLaVA,第一个具有像素级grounding能力的LMM,通过转录音频提示为文本来丰富视频上下文的理解。框架用一个现成的跟踪器和一个新颖的grounding模块,使其能够根据用户的指令在视频中空间上和时间上定位对象。
使用基于视频的生成和问答基准测试评估了PG-Video-LLaVA,并引入了专门为测量基于提示的视频对象grounding性能而设计的新基准测试。此外,提出用Vicuna来替代VideoChatGPT中使用的GPT-3.5,用于基于视频的对话基准测试,以确保结果的可重复性,这是有关GPT-3.5的专有性质的一个问题。框架建立在最先进的基于图像的LLaVA模型基础上,并将其优势扩展到视频领域,在基于视频的交流和参照任务中取得了有希望的成果。
XAGen: 3D Expressive Human Avatars Generation

https://github.com/magic-research/xagen
GAN模型使得生成逼真和可控的人体图像成为可能。然而,现有方法主要关注主要身体关节的控制,忽视了表情、颌位、手势等表达属性的操纵。
这项工作提出XAGen,第一个能够对人体角色进行身体、面部和手部表情控制的3D生成模型。为了提高面部和手部等小尺度区域的保真度,设计一种多尺度和多部分的3D表示方法来模拟细节。基于这种表示方法,提出一种多部分渲染技术,将身体、面部和手部的合成分离开来,以便于模型训练和提高几何质量。
此外,设计了多部分鉴别器来评估生成角色的外观和精细控制能力。实验证明,XAGen在逼真度、多样性和表情控制能力方面超越现有方法。
T-Rex: Counting by Visual Prompting

https://trex-counting.github.io/
T-Rex12,一种交互式物体计数模型,旨在首先检测,然后计数任意物体。将物体计数形式化为一种集成视觉提示的开放式物体检测任务。用户可以通过在参考图像上标记点或框来指定感兴趣的物体,然后T-Rex可以检测到所有具有相似模式的物体。
在TRex的视觉反馈指导下,用户还可以通过提示缺失或错误检测的物体来交互地改进计数结果。T-Rex在几个类不可知计数基准上取得了最先进的性能。为进一步发挥其潜力,建立一个涵盖多样场景和挑战的新的计数基准。
定量和定性结果均显示,T-Rex具有出色的零样本计数能力。还展示了T-Rex在各种实际应用场景中的潜力,说明其在视觉提示领域的潜力。
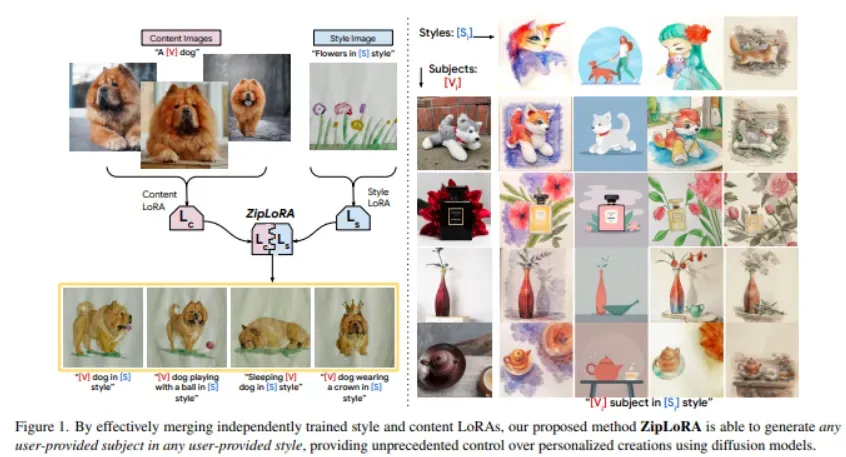
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
https://ziplora.github.io/
目前,为了概念(目标对象)驱动的个性化而对生成模型进行微调的方法,通常能够在以主题(目标对象)驱动或风格驱动为基础的生成中取得较强的结果。最近,低秩适应(LoRA)被提出作为实现概念驱动个性化的一种参数高效的方式。虽然最近的工作探索了将独立的LoRA组合起来实现学习风格和主题的联合生成,但现有技术并未能可靠地解决问题;它们往往要么牺牲主题的准确性,要么牺牲风格的准确性。
提出ZipLoRA,一种廉价且有效地合并独立训练的风格和主题LoRA的方法,以实现在任何用户提供的主题和风格下的生成。在对广泛的主题和风格组合进行的实验中,ZipLoRA能够生成具有显著改进的有意义结果,同时保持了再情景化的能力。
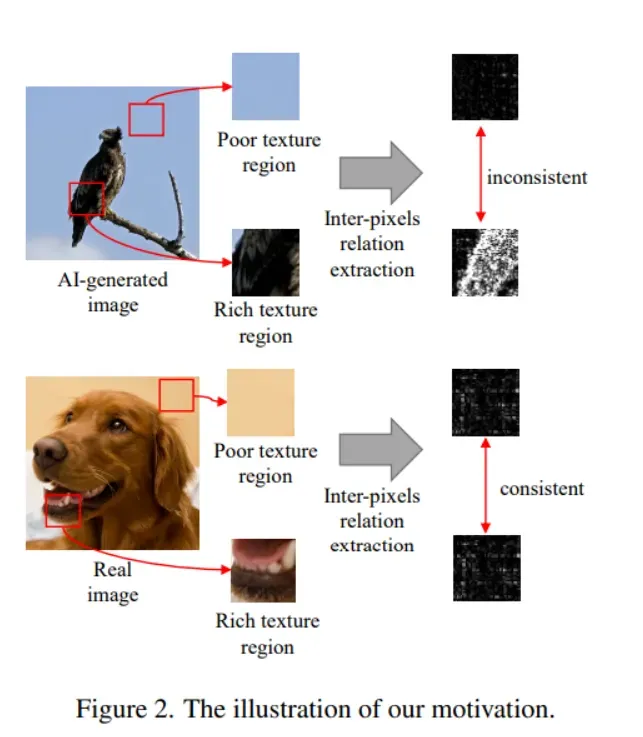
Rich and Poor Texture Contrast: A Simple yet Effective Approach for AI-generated Image Detection
https://fdmas.github.io/AIGCDetect/
AI生成的图像可能会导致普遍的虚假信息传播。因此,开发一种检测器来识别AI生成的图像非常紧迫。大多数现有的检测器对未见的生成模型性能大幅下降。本文提出一种新的AI生成图像检测器,能够识别广泛范围内各种生成模型创建的虚假图像。
方法利用图像中丰富纹理区域与贫纹理区域之间的像素间相关性对比,来检测AI生成的图像。丰富纹理区域的像素比贫纹理区域的像素的波动更大。这种差异反映了丰富纹理区域的熵大于贫纹理区域的熵。对现有的生成模型来说,合成逼真的丰富纹理区域更具挑战性。
基于这个原理,将图像分成多个局部块,并将它们分别重构为由丰富纹理区域和贫纹理区域组成的两个图像。然后,提取丰富纹理区域和贫纹理区域之间的像素间相关性差异特征。这个特征用于AI生成的图像分析,在不同的生成模型中起到了普适指纹的作用。
此外,建立了一个全面的AI生成的图像检测基准,包括16种流行的生成模型,用于评估现有基线方法和我们的方法的有效性。基准为后续研究提供了排行榜。实验结果表明,方法在性能上显著优于现有的基准方法。
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!
文章出处登录后可见!