1.最短路径问题
1.1 带权图的最短路径
最短路径问题是指在一个加权图中寻找两个顶点之间的最短路径,其中路径的长度由边的权重确定。
常见的最短路径算法包括:
-
Dijkstra算法:适用于解决单源最短路径问题,即从一个固定的起点到图中所有其他顶点的最短路径。该算法通过不断选择当前路径上权重最小的顶点来逐步扩展最短路径树,直到找到所有顶点的最短路径。
-
Bellman-Ford算法:适用于解决带有负权边的图的单源最短路径问题。该算法通过对图中所有边进行松弛操作,反复迭代更新每个顶点的最短距离估计,直到收敛并得到最终的最短路径。
-
Floyd-Warshall算法:适用于解决图中所有顶点之间的最短路径问题,即多源最短路径问题。该算法通过动态规划的思想,依次考虑所有顶点作为中间节点,更新任意两个顶点之间的最短距离。
-
A*算法:适用于在带有启发式函数的图中寻找单源最短路径。该算法结合了Dijkstra算法和启发式搜索的思想,通过启发式函数预估剩余路径的代价,并选择最有希望的顶点进行扩展,以尽快找到最短路径。
这些算法在不同的应用场景和图的特性下具有不同的优劣势,选择合适的算法取决于具体的问题要求和图的规模。
1.2 无权图的最短路径
在无权图中,最短路径问题是指寻找两个顶点之间的最短路径,其中边没有权重或者权重都相同。在无权图中,最短路径的长度由路径中的边数确定。
常见的解决无权图最短路径问题的算法有:
-
广度优先搜索(BFS):广度优先搜索是一种基于图的遍历算法,它可以用于解决无权图的最短路径问题。从起点开始,逐层地向外扩展搜索,直到找到目标顶点或者遍历完所有可达顶点。在广度优先搜索中,首次访问到目标顶点时,路径长度就是最短路径的长度。
-
迪杰斯特拉算法(Dijkstra):迪杰斯特拉算法可以用于解决无权图的单源最短路径问题,即从一个固定的起点到图中所有其他顶点的最短路径。在迪杰斯特拉算法中,使用优先队列(最小堆)来维护当前最短路径的顶点,并不断更新与其相邻的顶点的最短距离,直到找到所有顶点的最短路径。
-
Floyd-Warshall算法:虽然Floyd-Warshall算法主要用于解决有权图的最短路径问题,但在无权图中也可以使用。在无权图中,Floyd-Warshall算法会计算任意两个顶点之间的最短路径长度,即使边的权重都是相同的。
这些算法在解决无权图的最短路径问题时,具有不同的特点和适用范围。选择合适的算法取决于具体的问题要求和图的规模。对于无权图而言,广度优先搜索是最简单且常用的方法。
2.Dijkstra 算法的原理和模拟
Dijkstra算法是一种用于解决单源最短路径问题的贪心算法。它可以找到从起点到图中所有其他顶点的最短路径。
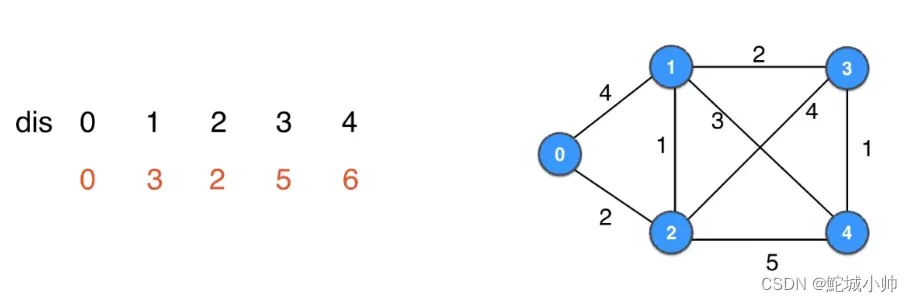
以下是Dijkstra算法的基本原理:
-
创建两个集合:一个是已访问顶点集合,表示已经找到最短路径的顶点;另一个是未访问顶点集合,表示尚未找到最短路径的顶点。
-
初始化距离数组:将起点到所有其他顶点的距离初始化为无穷大,起点到自身的距离初始化为0。
-
选择起点:将起点加入已访问顶点集合,并更新起点相邻顶点的距离。
-
迭代更新:重复以下步骤,直到找到所有顶点的最短路径或者无法继续更新:
- 从未访问顶点集合中选择一个距离最小的顶点,将其加入已访问顶点集合。
- 更新该顶点的相邻顶点的距离。如果经过当前选中顶点到达相邻顶点的路径距离小于之前记录的距离,则更新距离。
-
输出结果:得到起点到每个顶点的最短路径和对应的距离。
Dijkstra算法的核心思想是从起点开始,逐步扩展已访问的顶点集合,通过不断更新距离数组来找到最短路径。在每次迭代中,选择距离最小的顶点进行扩展,通过该顶点更新其相邻顶点的距离。算法保证每次迭代加入的顶点都是当前最短路径的一部分,最终得到起点到每个顶点的最短路径。
需要注意的是,Dijkstra算法要求图中的边权重必须为非负数。如果存在负权边,Dijkstra算法将无法正确计算最短路径,此时可以考虑使用其他算法,如Bellman-Ford算法。
3. 实现 Dijkstra 算法
package WeightedGraph;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
/**
* Dijkstra算法用于计算带权图中从指定起点到其他顶点的最短路径。
* @author wushaopei
*/
public class Dijkstra {
private WeightedGraph G; // 带权图对象
private int[] dis; // 起点到每个顶点的最短距离数组
private int s; // 起点
private boolean[] visited; // 记录顶点的访问状态
/**
* 构造函数,初始化Dijkstra对象
*
* @param G 带权图对象
* @param s 起点
*/
public Dijkstra(WeightedGraph G, int s){
this.G = G;
this.s = s;
CC cc = new CC(G); // 创建连通分量对象
if (cc.count() > 1){ // 如果图的连通分量数量大于1,即图不连通
throw new IllegalArgumentException("The graph is not connected.");
}
dis = new int[G.V()];
Arrays.fill(dis,Integer.MAX_VALUE);
visited = new boolean[G.V()];
dis[s] = 0;
while (true){
int curdis=Integer.MAX_VALUE, cur=-1; // 当前距离和顶点
for (int v = 0; v < G.V(); v ++){
if (!visited[v] && dis[v] < curdis){
curdis = dis[v];
cur = v;
}
}
if (cur == -1){
break;// 所有顶点都已访问,结束循环
}
visited[cur] = true; // 将当前顶点标记为已访问
for (int w : G.adj(cur)) {
if (!visited[w]){
// 如果经过当前选中顶点到达相邻顶点的路径距离小于之前记录的距离,则更新距离
if ( G.getWeighted(cur,w) + dis[cur] < dis[w] ){
dis[w] = G.getWeighted(cur,w) + dis[cur];
}
}
}
}
}
/**
* 判断指定顶点是否与起点连通
* @param v 指定顶点
* @return 如果连通则返回true,否则返回false
*/
public boolean isConnectedTo(int v){
G.validateVertex(v);
return visited[v];
}
/**
* 获取起点到指定顶点的最短距离
* @param v 指定顶点
* @return 起点到指定顶点的最短距离
*/
public int distTo(int v){
G.validateVertex(v);
return dis[v];
}
}
上述代码是Dijkstra算法的实现。其中,通过优先队列选择最短路径的顶点,然后更新其相邻顶点的距离。通过循环迭代,直到找到起点到所有其他顶点的最短路径。
4.Dijkstra 算法的优化
package WeightedGraph;
import java.util.Arrays;
import java.util.PriorityQueue;
/**
* Dijkstra算法用于计算带权图中从指定起点到其他顶点的最短路径。
* @author wushaopei
*/
public class DijkstraQueue {
private WeightedGraph G; // 带权图对象
private int[] dis; // 起点到每个顶点的最短距离数组
private int s; // 起点
private boolean[] visited; // 记录顶点的访问状态
private class Node implements Comparable<Node>{
public int v;
public int dis;
public Node(int v, int dis) {
this.v = v;
this.dis = dis;
}
@Override
public int compareTo(Node o) {
return Integer.compare( this.dis,o.dis);
}
}
/**
* 构造函数,初始化Dijkstra对象
*
* @param G 带权图对象
* @param s 起点
*/
public DijkstraQueue(WeightedGraph G, int s){
this.G = G;
this.s = s;
CC cc = new CC(G); // 创建连通分量对象
if (cc.count() > 1){ // 如果图的连通分量数量大于1,即图不连通
throw new IllegalArgumentException("The graph is not connected.");
}
dis = new int[G.V()];
Arrays.fill(dis,Integer.MAX_VALUE);
visited = new boolean[G.V()];
dis[s] = 0;
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.add(new Node(s,0));
while (!pq.isEmpty()){
int cur = pq.remove().v;
if (visited[cur]) continue;
visited[cur] = true; // 将当前顶点标记为已访问
for (int w : G.adj(cur)) {
if (!visited[w]){
// 如果经过当前选中顶点到达相邻顶点的路径距离小于之前记录的距离,则更新距离
if ( G.getWeighted(cur,w) + dis[cur] < dis[w] ){
dis[w] = G.getWeighted(cur,w) + dis[cur];
pq.add(new Node(w,dis[w]));
}
}
}
}
}
/**
* 判断指定顶点是否与起点连通
* @param v 指定顶点
* @return 如果连通则返回true,否则返回false
*/
public boolean isConnectedTo(int v){
G.validateVertex(v);
return visited[v];
}
/**
* 获取起点到指定顶点的最短距离
* @param v 指定顶点
* @return 起点到指定顶点的最短距离
*/
public int distTo(int v){
G.validateVertex(v);
return dis[v];
}
}
时间复杂度: O(V*ElogE)
在上述代码中,我们引入了一个名为Node的内部类,用于表示顶点和距离的信息。该类实现了Comparable接口,通过比较节点的距离来确定优先级。我们使用PriorityQueue作为优先队列,每次取出距离最小的节点进行处理,以保证始终选择最短路径的顶点进行更新。通过使用优先队列,可以有效地优化Dijkstra算法的执行时间,减少不必要的遍历。
5.更多关于 Dijkstra 算法的讨论
源点到指定顶点的路径查询:
private WeightedGraph G; // 带权图对象
private int[] dis; // 起点到每个顶点的最短距离数组
private int s; // 起点
private boolean[] visited; // 记录顶点的访问状态
private int[] pre;
private class Node implements Comparable<Node>{
public int v;
public int dis;
public Node(int v, int dis) {
this.v = v;
this.dis = dis;
}
@Override
public int compareTo(Node o) {
return Integer.compare( this.dis,o.dis);
}
}
/**
* 构造函数,初始化Dijkstra对象
*
* @param G 带权图对象
* @param s 起点
*/
public DijkstraQueue(WeightedGraph G, int s){
this.G = G;
this.s = s;
CC cc = new CC(G); // 创建连通分量对象
if (cc.count() > 1){ // 如果图的连通分量数量大于1,即图不连通
throw new IllegalArgumentException("The graph is not connected.");
}
dis = new int[G.V()];
Arrays.fill(dis,Integer.MAX_VALUE);
visited = new boolean[G.V()];
dis[s] = 0;
pre = new int[G.V()];
Arrays.fill(pre,-1);
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.add(new Node(s,0));
pre[s] = s;
while (!pq.isEmpty()){
int cur = pq.remove().v;
if (visited[cur]) continue;
visited[cur] = true; // 将当前顶点标记为已访问
for (int w : G.adj(cur)) {
if (!visited[w]){
// 如果经过当前选中顶点到达相邻顶点的路径距离小于之前记录的距离,则更新距离
if ( G.getWeighted(cur,w) + dis[cur] < dis[w] ){
dis[w] = G.getWeighted(cur,w) + dis[cur];
pq.add(new Node(w,dis[w]));
pre[w]=cur;
}
}
}
}
}
/**
* 判断指定顶点是否与起点连通
* @param v 指定顶点
* @return 如果连通则返回true,否则返回false
*/
public boolean isConnectedTo(int v){
G.validateVertex(v);
return visited[v];
}
/**
* 获取起点到指定顶点的最短距离
* @param v 指定顶点
* @return 起点到指定顶点的最短距离
*/
public int distTo(int v){
G.validateVertex(v);
return dis[v];
}
public Iterable<Integer> path(int t){
ArrayList<Integer> res = new ArrayList<>();
if (!isConnectedTo(t)) return res;
int cur = t;
while ( cur != s){
res.add(cur);
cur = pre[cur];
}
res.add(s);
Collections.reverse(res);
return res;
}
public static void main(String[] args) {
WeightedGraph weightedGraph = new WeightedGraph("src/dijkstra.txt");
DijkstraQueue dijkstra = new DijkstraQueue(weightedGraph, 0);
for (int v = 0; v < weightedGraph.V(); v ++ ){
System.out.println(dijkstra.distTo(v) + " ");
}
System.out.println(dijkstra.path(3));
}7. Bellman-Ford 算法
Bellman-Ford算法是一种用于解决带有负权边的图的最短路径问题的算法。它可以处理包含负权边但不含负权环的图。该算法以起点为基准,通过逐步松弛边的操作来逐步更新从起点到其他顶点的最短距离。
算法步骤如下:
(1)初始化距离数组:创建一个距离数组`dis`,将起点`s`到每个顶点的最短距离初始化为正无穷大,起点`s`的最短距离初始化为0。
(2)进行V-1次松弛操作:对图中的所有边进行V-1次松弛操作。每次松弛操作都会尝试更新从起点到达每个顶点的最短距离。
– 遍历图的所有边,对于每条边`(v, w)`,如果从起点`s`到顶点`v`的距离`dis[v]`不是正无穷大,并且通过顶点`v`可以缩短到达顶点`w`的距离,则更新`dis[w]`为`dis[v] + weight(v, w)`,其中`weight(v, w)`是边`(v, w)`的权值。
(3)检测负权环:在进行V-1次松弛操作后,再次遍历所有边,如果存在通过松弛操作仍然能够缩短距离的边,则说明图中存在负权环。
– 如果存在通过松弛操作仍然能够缩短距离的边,则抛出异常,表示图中存在负权环。
(4)返回结果:根据最终更新的距离数组`dis`,可以得到起点`s`到其他顶点的最短距离。此外,可以通过记录每个顶点的前驱顶点来还原最短路径。
Bellman-Ford算法的时间复杂度为O(V * E),其中V是顶点数,E是边数。它的优势在于可以处理带有负权边的图,但在一般情况下,Dijkstra算法的时间复杂度更低。因此,如果图中没有负权边,推荐使用Dijkstra算法。
8. 负权环
负权环是指图中存在一个环路,使得环路中所有边的权值之和为负数。在最短路径问题中,负权环会导致无限循环的情况,因为可以通过反复绕着负权环前进来不断减小路径的长度。
在Bellman-Ford算法中,第三步用于检测负权环,判断图中是否存在负权环的方法如下:
(1) 进行第V次松弛操作:再进行一次松弛操作,遍历所有边,对于每条边`(v, w)`,如果从起点`s`到顶点`v`的距离`dis[v]`不是正无穷大,并且通过顶点`v`可以缩短到达顶点`w`的距离,则说明存在负权环。
– 如果在第V次松弛操作后,仍然存在通过松弛操作能够缩短距离的边,则说明图中存在负权环。
(2)返回结果:如果存在负权环,则算法无法给出最短路径,可以抛出异常或者返回特定的结果来表示负权环的存在。
检测负权环的原理是利用了图中最短路径不可能包含负权环的性质。因为负权环会导致路径长度无限减小,所以不存在从起点到达负权环中的任何顶点的有限长度的最短路径。
需要注意的是,在检测负权环时,Bellman-Ford算法需要进行额外的一次松弛操作,这会导致算法的时间复杂度增加到O(V * E)。
9. 实现 Bellman-Ford 算法
package WeightedGraph;
import java.util.Arrays;
/**
* @author wushaopei
*/
public class BellmanFord {
private WeightedGraph G; // 带权图对象
private int s; // 起点
private int[] dis; // 从起点到每个顶点的最短距离数组
private boolean hasNegativeCycle; // 是否存在负权环的标志
public BellmanFord(WeightedGraph G, int s){
this.G = G;
this.s = s;
dis = new int[G.V()];
Arrays.fill(dis, Integer.MAX_VALUE); // 将最短距离数组初始化为正无穷大
dis[s] = 0; // 起点到自身的距离为0
// 进行V-1轮松弛操作
for (int pass = 1; pass < G.V(); pass++){
// 遍历所有顶点
for (int v = 0; v < G.V(); v++){
// 遍历顶点v的所有邻接顶点
for (Integer w : G.adj(v)) {
// 如果从起点到顶点v的距离不是正无穷大,并且通过顶点v可以缩短到达顶点w的距离
if (dis[v] != Integer.MAX_VALUE && dis[v] + G.getWeighted(v, w) < dis[w]){
dis[w] = dis[v] + G.getWeighted(v, w); // 更新到达顶点w的最短距离
}
}
}
}
// 检测负权环
for (int v = 0; v < G.V(); v++){
for (Integer w : G.adj(v)) {
// 如果从起点到顶点v的距离不是正无穷大,并且通过顶点v可以缩短到达顶点w的距离
if (dis[v] != Integer.MAX_VALUE && dis[v] + G.getWeighted(v, w) < dis[w]){
hasNegativeCycle = true; // 存在负权环
break;
}
}
}
}
public boolean hasNegativeCycle(){
return hasNegativeCycle;
}
public boolean isConnected(int v){
G.validateVertex(v);
return dis[v] != Integer.MAX_VALUE; // 判断顶点v是否与起点连通,即判断从起点到顶点v的距离是否不是正无穷大
}
public int distTo(int v){
G.validateVertex(v);
if (hasNegativeCycle) throw new RuntimeException("exist negative cycle."); // 如果存在负权环,则抛出异常
return dis[v]; // 返回从起点到顶点v的最短距离
}
}
松弛操作与负权环检测:
(1)执行V-1轮松弛操作:
- 外层循环
pass控制轮数,从1到V-1,其中V是图中顶点的数量。 - 中层循环
v遍历所有顶点。 - 内层循环
w遍历顶点v的所有邻接顶点。 - 如果从起点
s到顶点v的距离不是正无穷大,并且通过顶点v可以缩短到达顶点w的距离,则更新到达顶点w的最短距离。
(2)检测负权环:
- 遍历所有顶点
v。 - 再次遍历顶点
v的所有邻接顶点w。 - 如果从起点
s到顶点v的距离不是正无穷大,并且通过顶点v可以缩短到达顶点w的距离,则说明存在负权环,将hasNegativeCycle标志设置为true。
总体而言,该代码通过V-1轮松弛操作来计算起点到其他顶点的最短距离,并检测是否存在负权环。如果存在负权环,则最短距离无意义。该算法的时间复杂度为O(V * E),其中V是顶点数量,E是边的数量。
10. 更多关于 Bellman-Ford 算法的讨论
从 s 到 t 的最短距离:
private int[] pre;
public BellmanFord(WeightedGraph G, int s){
this.G = G;
this.s = s;
pre = new int[G.V()];
dis = new int[G.V()];
Arrays.fill(dis, Integer.MAX_VALUE); // 将最短距离数组初始化为正无穷大
dis[s] = 0; // 起点到自身的距离为0
pre[s] = s;
// 进行V-1轮松弛操作
for (int pass = 1; pass < G.V(); pass++){
// 遍历所有顶点
for (int v = 0; v < G.V(); v++){
// 遍历顶点v的所有邻接顶点
for (Integer w : G.adj(v)) {
// 如果从起点到顶点v的距离不是正无穷大,并且通过顶点v可以缩短到达顶点w的距离
if (dis[v] != Integer.MAX_VALUE && dis[v] + G.getWeighted(v, w) < dis[w]){
dis[w] = dis[v] + G.getWeighted(v, w); // 更新到达顶点w的最短距离
pre[w] = v;
}
}
}
}
// 检测负权环
for (int v = 0; v < G.V(); v++){
for (Integer w : G.adj(v)) {
// 如果从起点到顶点v的距离不是正无穷大,并且通过顶点v可以缩短到达顶点w的距离
if (dis[v] != Integer.MAX_VALUE && dis[v] + G.getWeighted(v, w) < dis[w]){
hasNegativeCycle = true; // 存在负权环
break;
}
}
}
}
/**
* 从s 到 t 的最短路径
* @param t
* @return
*/
public Iterable<Integer> path(int t){
ArrayList<Integer> res = new ArrayList<>();
if (!isConnectedTo(t)) return res;
int cur = t;
while ( cur != s){
res.add(cur);
cur = pre[cur];
}
res.add(s);
Collections.reverse(res);
return res;
}11. Floyd 算法
Floyd算法是一种用于解决带权有向图中所有顶点对之间的最短路径的动态规划算法。它通过逐步迭代更新路径长度来求解最短路径。
下面是Floyd算法的基本思想和步骤:
-
创建一个二维数组
dist,用于存储任意两个顶点之间的最短路径长度。初始时,dist[i][j]表示顶点i到顶点j的直接距离,如果两顶点之间没有直接边相连,则距离为无穷大(或者设置为一个较大的数)。 -
对于每个顶点k,遍历所有顶点对(i, j):
- 如果
dist[i][j]大于dist[i][k] + dist[k][j],则更新dist[i][j]为dist[i][k] + dist[k][j],表示通过顶点k可以缩短顶点i到顶点j的距离。
- 如果
-
重复步骤2,直到遍历完所有顶点k。这样,每一轮迭代都会更新顶点对之间的最短路径。
-
最终,
dist数组中存储的就是所有顶点对之间的最短路径长度。
Floyd算法的时间复杂度为O(V^3),其中V是顶点的数量。它适用于解决任意两个顶点之间的最短路径问题,包括有向图和无向图。
需要注意的是,Floyd算法也可以检测负权环,如果存在负权环,则最短路径将无意义。通过检查dist[i][i]是否小于0,可以判断图中是否存在负权环。
12. 实现 Floyd 算法
public class Floyed {
private WeightedGraph G; // 带权图对象
private int[][] dis; // 保存每个顶点对之间的最短距离
private boolean hasNegativeCycle; // 是否存在负权环
public Floyed(WeightedGraph G){
this.G = G;
dis = new int[G.V()][G.V()];
// 初始化dis矩阵
for (int i = 0 ; i < dis.length; i ++) {
dis[i] = new int[G.V()];
Arrays.fill(dis[i], Integer.MAX_VALUE);
}
// 初始化dis矩阵,将边的权重赋值给对应位置的顶点对
for (int v = 0 ; v < G.V(); v++){
dis[v][v] = 0;
for (int w : G.adj(v)) {
dis[v][w] = G.getWeighted(v,w);
}
}
// 计算最短路径
for (int t = 0 ; t < G.V(); t ++){
for (int v = 0; v < G.V(); v ++){
for (int w = 0 ; w < G.V(); w ++){
if (dis[v][t] != Integer.MAX_VALUE && dis[t][w] != Integer.MAX_VALUE && dis[v][t] + dis[t][w] < dis[v][w]){
dis[v][w] = dis[v][t] + dis[t][w];
}
}
}
}
// 检查是否存在负权环
for (int v = 0; v < G.V(); v ++){
if ( dis[v][v] < 0 ){
hasNegativeCycle = true;
break;
}
}
}
/**
* 判断两个顶点之间是否连通
* @param v 顶点v
* @param w 顶点w
* @return 如果连通则返回true,否则返回false
*/
public boolean isConnectedTo(int v, int w){
G.validateVertex(v);
G.validateVertex(w);
return dis[v][w] != Integer.MAX_VALUE;
}
/**
* 获取两个顶点之间的最短距离
* @param v 顶点v
* @param w 顶点w
* @return 顶点v到顶点w的最短距离
* @throws RuntimeException 如果两个顶点之间不存在路径或存在负权环,则抛出异常
*/
public int distTo(int v , int w){
if (!isConnectedTo(v,w)) throw new RuntimeException("exits negative cycle.");
return dis[v][w];
}
/**
* 判断是否存在负权环
* @return 如果存在负权环则返回true,否则返回false
*/
public boolean hasNegativeCycle(){
return hasNegativeCycle;
}
}
Floyd算法(弗洛伊德算法)用于解决带权图中所有顶点对之间的最短路径问题。其原理基于动态规划的思想,通过逐步更新顶点对之间的最短距离来求解最短路径。
算法步骤如下:
- 初始化dis矩阵,将每个顶点对之间的距离初始化为正无穷(表示不可达),但对角线上的元素初始化为0(表示顶点到自身的距离为0)。
- 根据图的边权重信息,更新dis矩阵,将边的权重赋值给对应位置的顶点对。如果顶点v到顶点w之间有直接边相连,则dis[v][w]的值为边的权重。
- 通过三层循环遍历每一个顶点作为中间节点,逐步更新dis矩阵中的距离。对于每个顶点对(v, w),如果存在顶点t使得从v到t再到w的路径距离更短,则更新dis[v][w]的值为dis[v][t] + dis[t][w]。
- 最终得到dis矩阵,其中的值表示每个顶点对之间的最短距离。
在更新dis矩阵的过程中,会进行多次迭代,每次迭代中都会考虑增加一个中间节点对距离的影响。通过逐步迭代,可以找到所有顶点对之间的最短路径。
在Floyd算法的最后一步,我们检查dis矩阵的对角线元素。如果存在顶点v使得dis[v][v] < 0,则说明存在负权环,即图中存在一条环路,使得沿着该环路的路径距离不断减小。这种情况下,无法找到最短路径,因为可以无限次绕着负权环进行循环,使得路径距离无穷小。
总结来说,Floyd算法通过动态规划的思想,逐步更新顶点对之间的最短距离,从而求解带权图中所有顶点对之间的最短路径。算法的时间复杂度为O(V^3),其中V为顶点数。同时,Floyd算法还能检测负权环的存在。
文章出处登录后可见!