在过去的几个月里,大型语言模型(llm)获得了极大的关注,这些模型创造了令人兴奋的前景,特别是对于从事聊天机器人、个人助理和内容创作的开发人员。

大型语言模型(llm)是指能够生成与人类语言非常相似的文本并以自然方式理解提示的机器学习模型。这些模型使用广泛的数据集进行训练,这些数据集包括书籍、文章、网站和其他来源。通过分析数据中的统计模式,LLM可以预测给定输入后最可能出现的单词或短语。
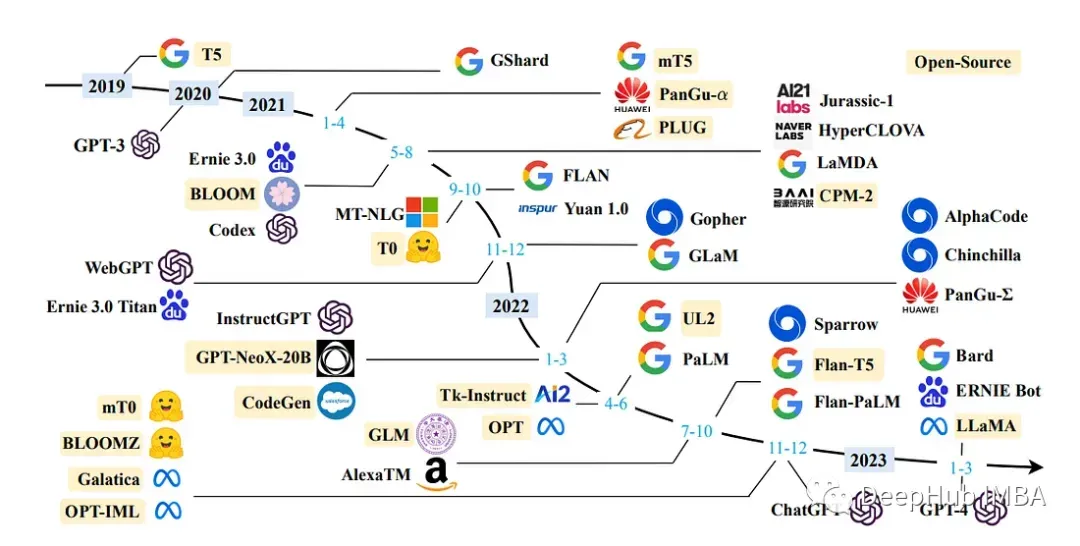
以上是目前的LLM的一个全景图。
在本文中,我将演示如何利用LLaMA 7b和Langchain从头开始创建自己的Document Assistant。
背景知识
1、LangChain 🔗
LangChain是一个令人印象深刻且免费的框架,它彻底改变了广泛应用的开发过程,包括聊天机器人、生成式问答(GQA)和摘要。通过将来自多个模块的组件无缝链接,LangChain能够使用大部分的llm来创建应用程序。
2、LLaMA 🦙
LLaMA是由Facebook的母公司Meta AI设计的一个新的大型语言模型。LLaMA拥有70亿到650亿个参数的模型集合,是目前最全面的语言模型之一。2023年2月24日,Meta向公众发布了LLaMA模型,展示了他们对开放科学的奉献精神(虽然我们现在用的都是泄露版)。
3、什么是GGML
GGML是一个用于机器学习的张量库,它只是一个c++库,允许你在CPU或CPU + GPU上运行llm。它定义了用于分发大型语言模型(llm)的二进制格式。GGML使用了一种称为量化的技术,该技术允许大型语言模型在消费者硬件上运行。
4、量化
我们都知道,模型的权重是浮点数。就像表示大整数(例如1000)比表示小整数(例如1)需要更多的空间一样,表示高精度浮点数(例如0.0001)比表示低精度浮点数(例如0.1)需要更多的空间。量化大型语言模型的过程涉及降低表示权重的精度,以减少使用模型所需的资源。GGML支持许多不同的量化策略(例如4位、5位和8位量化),每种策略在效率和性能之间提供不同的权衡。
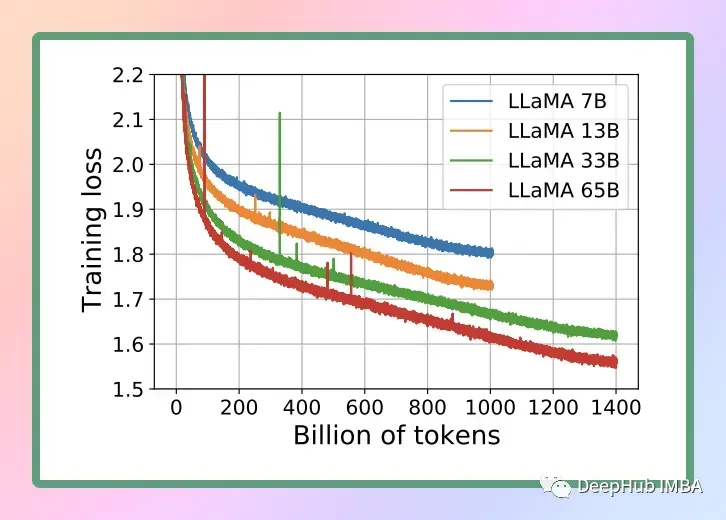
下面是量化后模型大小的对比:

5、Streamlit🔥
Streamlit 是一个用于构建数据科学和机器学习应用程序的开源 Python 库。它旨在使开发人员能够以简单快速的方式构建交互式应用程序,无需繁琐的前端开发。Streamlit 提供了一组简单的 API,可用于创建具有数据探索、可视化和交互功能的应用程序。只需要通过简单的 Python 脚本就可以创建一个 Web 应用程序。可以利用 Streamlit 的丰富组件库来构建用户界面,例如文本框、滑块、下拉菜单和按钮,以及可视化组件,例如图表和地图。
1、建立虚拟环境和项目结构
设置虚拟环境为运行应用程序提供了一个受控和隔离的环境,确保其依赖关系与其他系统范围的包分离。这种方法简化了依赖关系的管理,并有助于维护不同环境之间的一致性。
然后就是创建我们的项目,一个好的结构会加速我们的开发,如下图所示
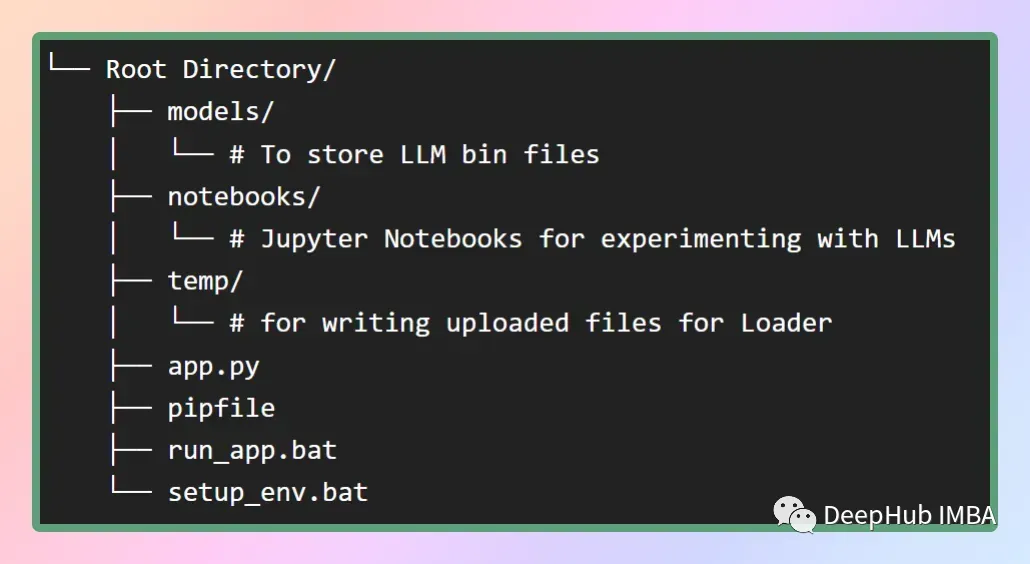
在models的文件夹中,我们要存储下载的llm,setup_env.bat将从pipfile中安装所有依赖项。而run_app.bat则是直接运行我们的app。(以上2个文件都是windows环境下的脚本)
2、在本地机器上安装LLaMA
为了有效地使用模型,必须考虑内存和磁盘。由于模型需要完全加载到内存中,因此不仅需要有足够的磁盘空间来存储它们,还需要足够的RAM在执行期间加载它们。比如65B模型,即使在量化之后,也需要40gb的RAM。
所以为了在本地运行,我们将使用最小版本的LLaMA,也就是LLaMA 7B。虽然它是最小的版本,但是LLaMA 7B也提供了很好的语言处理能力,我们能够高效地实现预期的结果。
为了在本地CPU上执行LLM,我们使用GGML格式的本地模型。这里直接从Hugging Face Models存储库直接下载bin文件,然后将文件移动到根目录下的models目录中。
上面我们已经是说了,GGML是c++库,所以还需要使用Python调用C++的接口,好在这一步很简单,我们将使用llama-cpp-python,这是LLaMA .cpp的Python绑定,它在纯C/ c++中充当LLaMA模型的推理。cpp的主要目标是使用4位整数量化来运行LLaMA模型。这样可以可以有效地利用LLaMA模型,充分利用C/ c++的速度优势和4位整数量化🚀的优势。
llama.cpp还支持很多其他模型,下图是列表:

准备好GGML模型和所有依赖项之后,就可以开始LangChain进行集成了。但是在开始之前,我们还需要做一下测试,保证我们的LLaMA在本地使可用的:
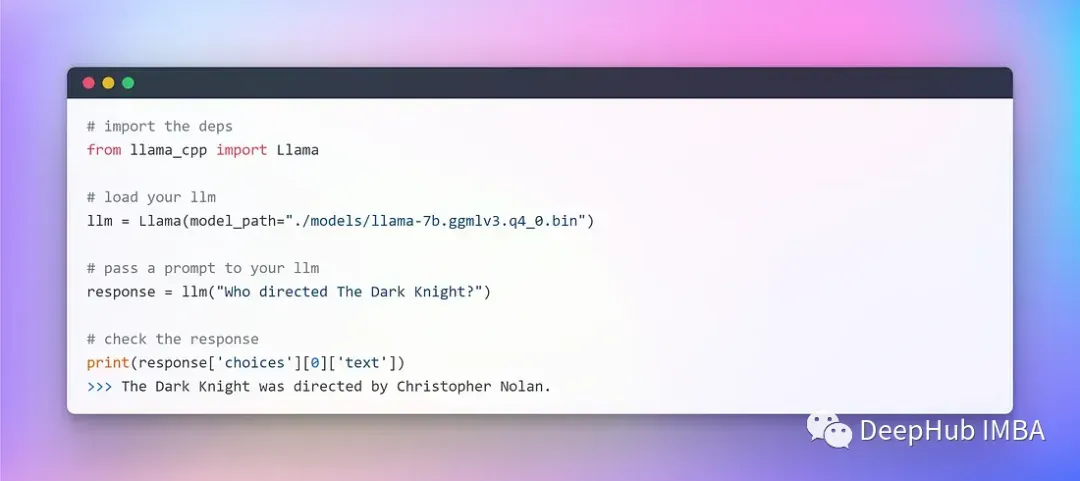
看样子没有任何问题,并且程序是完全脱机并以完全随机的方式(可以使用温度超参数)运行的。
3、LangChain集成LLM
现在我们可以利用LangChain框架来开发使用llm的应用程序。
为了提供与llm的无缝交互,LangChain提供了几个类和函数,可以使用提示模板轻松构建和使用提示。它包含一个文本字符串模板,可以接受来自最终用户的一组参数并生成提示符。让我们先看几个例子。
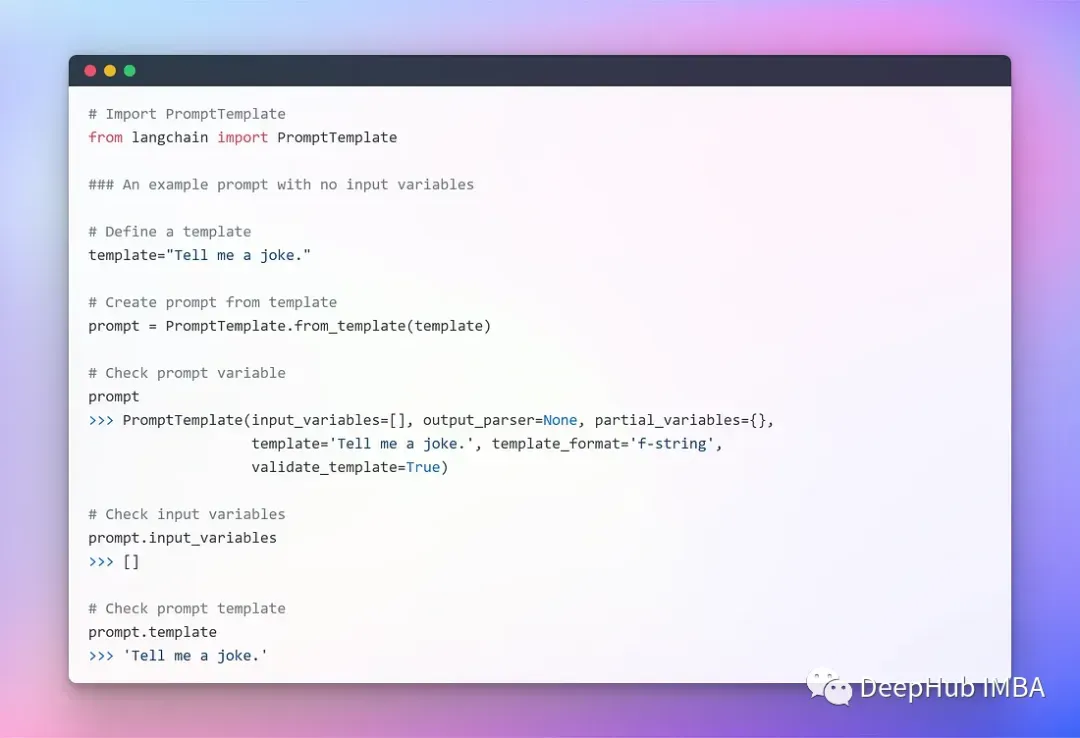
没有输入参数的模板
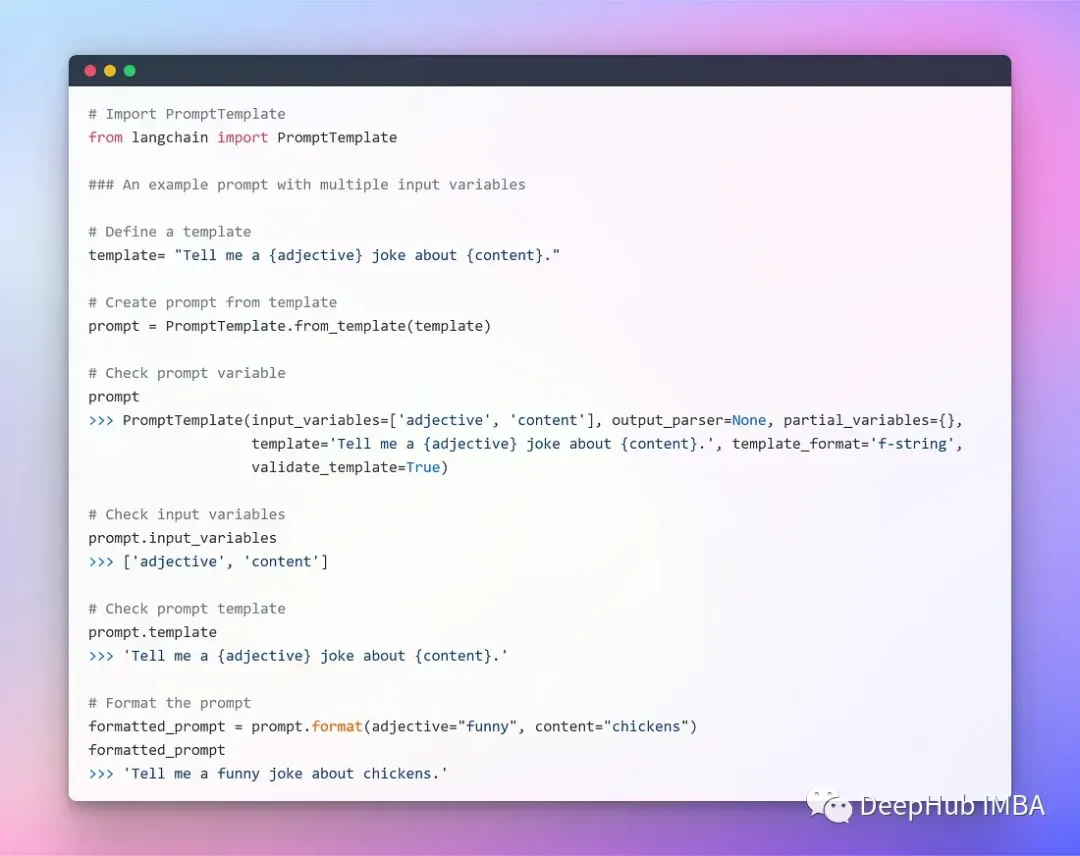
多个参数的模板
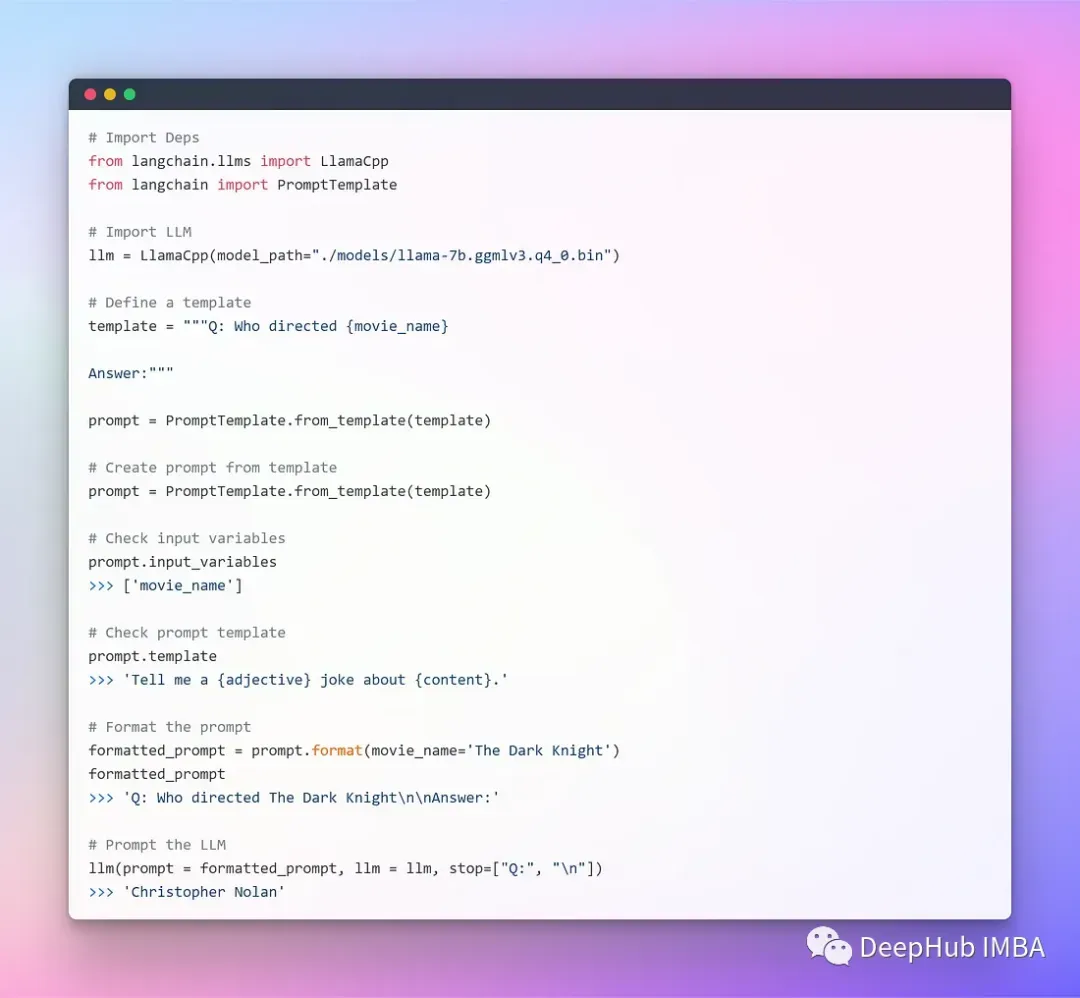
下面我们可以使用LangChain进行集成了
目前我们使用了单独的组件,通过提示模板对其进行格式化,然后使用llm,在llm中传递这些参数以生成答案。对于简单的应用程序,单独使用LLM是可以的,但是更复杂的应用程序需要将LLM链接起来——要么相互链接,要么与其他组件链接。
LangChain为这种链接🔗应用程序提供了Chain接口。我们可以将Chain定义为对组件的调用序列,其中可以包含其他Chain。Chain允许我们将多个组件组合在一起,以创建一个单一的、一致的应用程序。例如,可以创建一个Chain,它接受用户输入,使用Prompt Template对其进行格式化,然后将格式化后的响应传递给LLM。我们可以通过将多个Chain组合在一起,或者与其他组件组合在一起,来构建更复杂的Chain。这其实就和我们一般数据处理中的pipeline是类似的。
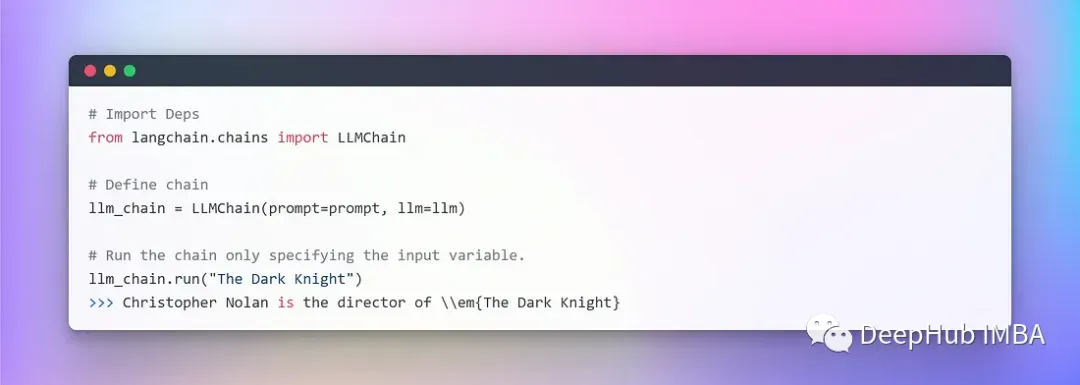
创建一个非常简单的Chain🔗,它将接受用户输入,用它格式化提示符,然后使用我们已经创建的上述各个组件将其发送到LLM。
4、生成嵌入和向量库
在许多LLM应用程序中,需要特定于用户的数据,这些数据不包括在模型的训练集中。LangChain提供了加载、转换、存储和查询数据的基本组件,我们这里可以直接使用
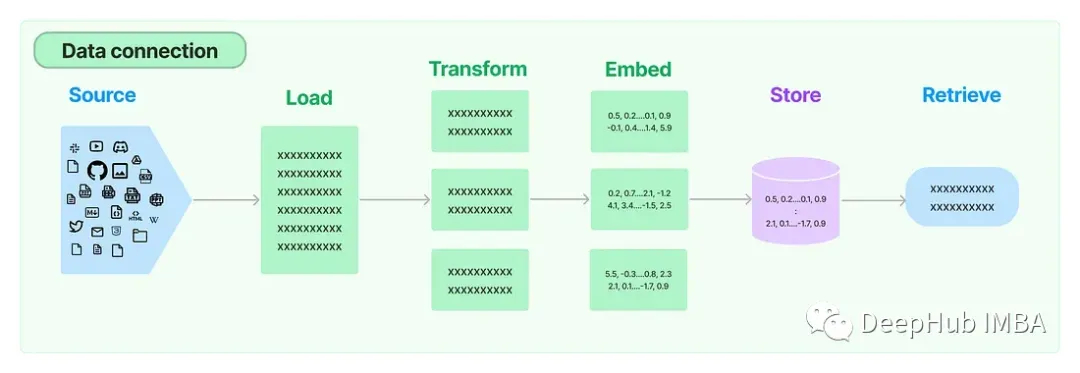
上图包含了5个组件:
- 文档加载器:它用于将数据加载为文档。
- 文档转换器:它将文档分成更小的块。
- 嵌入:它将块转换为向量表示,即嵌入。
- 嵌入向量存储:用于将上述块向量存储在矢量数据库中。
- 检索器:它用于检索一组向量,这些向量以嵌入在相同Latent空间中的向量的形式与查询最相似。
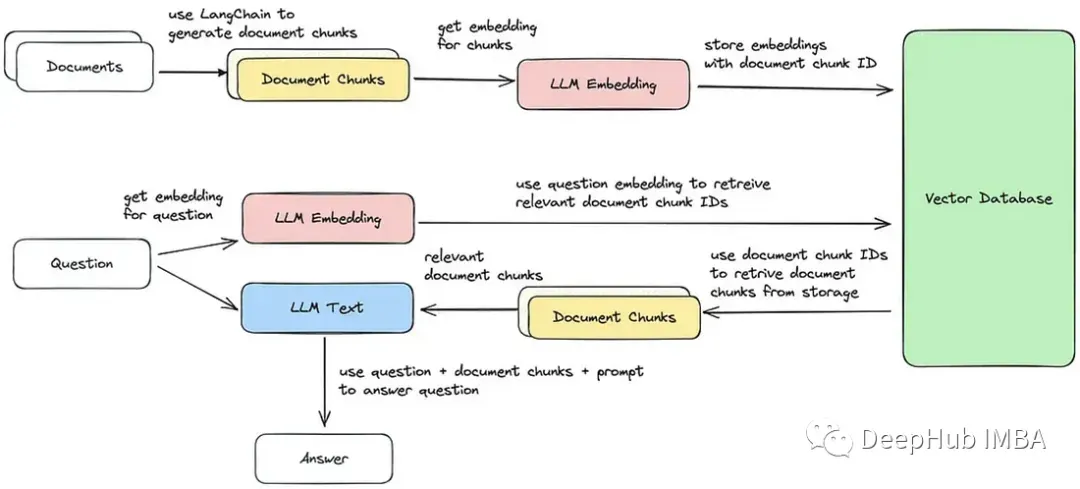
我们将实现这五个步骤,流程图如所提供的下图所示。
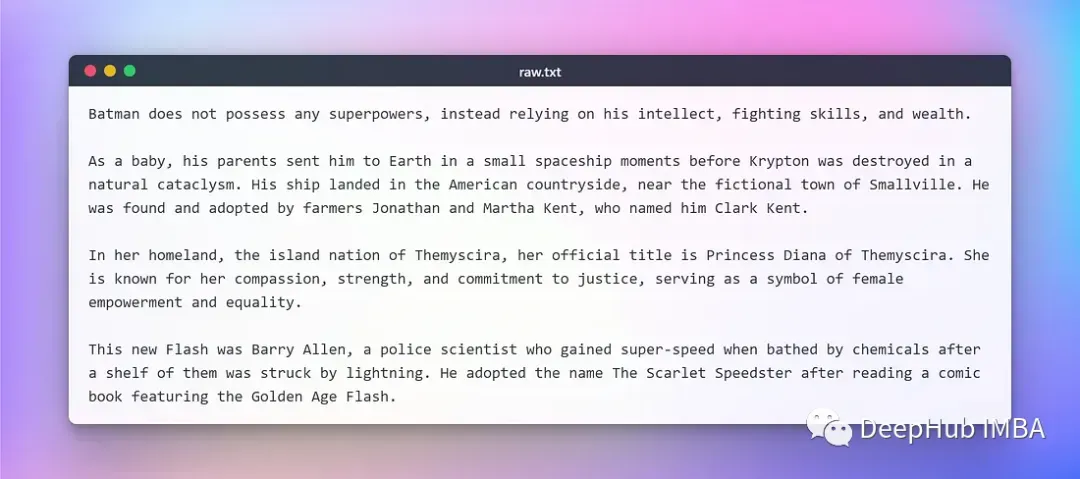
我们这里使用维基百科上复制的一段关于一些DC超级英雄的文本作为开发测试使用。原文如下:
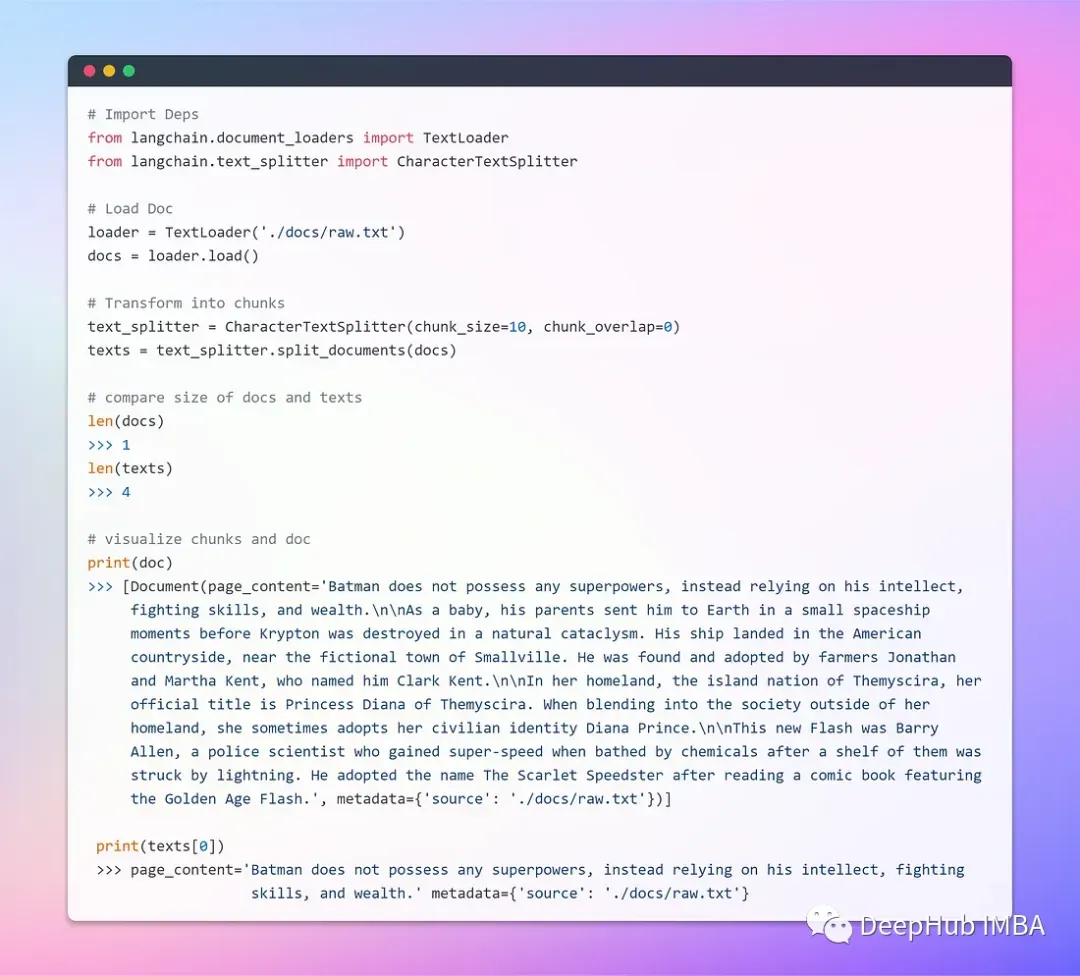
a.加载和转换文档
使用文本加载器创建一个文档对象(Lang chain提供了对多个文档的支持,可以根据文档使用不同的加载器),使用load方法检索数据,并将其作为文档从预配置的源加载。
加载文档之后,通过将其分解为更小的块来继续转换过程。使用TextSplitter(默认情况下,拆分器以’ \n\n ‘分隔符分隔文档)。如果将分隔符设置为null并定义特定的块大小,则每个块将具有指定的长度。这样就得到了列表长度将等于文档的长度除以块大小的一个块列表。
b.Embeddings
词嵌入只是一个词的向量表示,向量包含实数。词嵌入通过在低维向量空间中提供词的密集表示来解决简单的二进制单词向量由于维数高的问题。
LangChain中的基Embeddings类公开了两个方法:一个用于嵌入文档,另一个用于嵌入查询。前者接受多个文本作为输入,后者接受单个文本作为输入。
因为后面的检索也是检索嵌入在相同潜在空间中最相似的向量,所以词向量必须使用相同的方法(模型)生成。
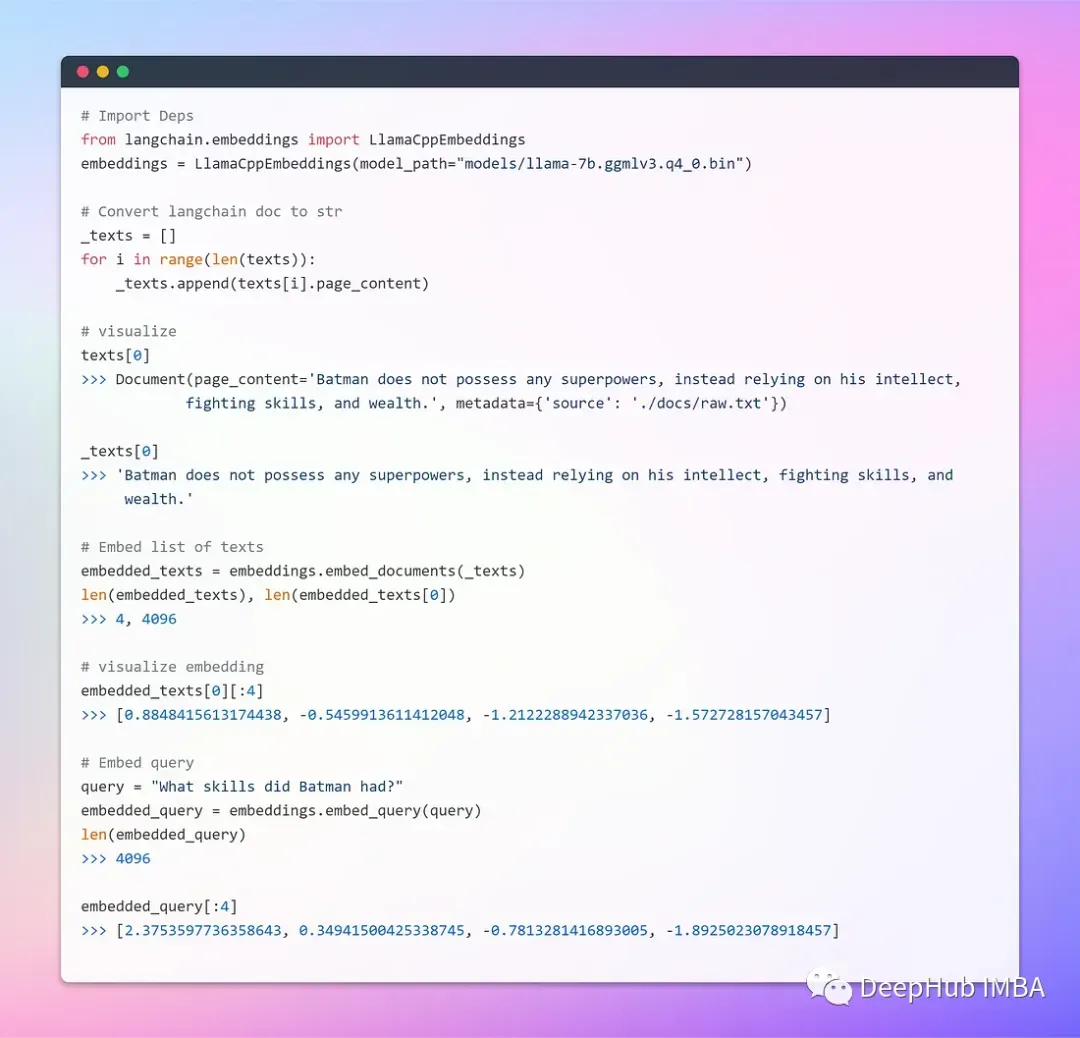
c.创建存储和检索文档
矢量存储有效地管理嵌入数据的存储,并加速矢量搜索操作。我们将使用Chroma,一个专门用于简化包含嵌入的人工智能应用程序的开发的矢量数据库。它提供了一套全面的内置工具和函数,我们只需要使用 pip install chromadb 命令将它安装在本地。

现在我们可以存储和检索向量了,下面就是与LLM来整合了。
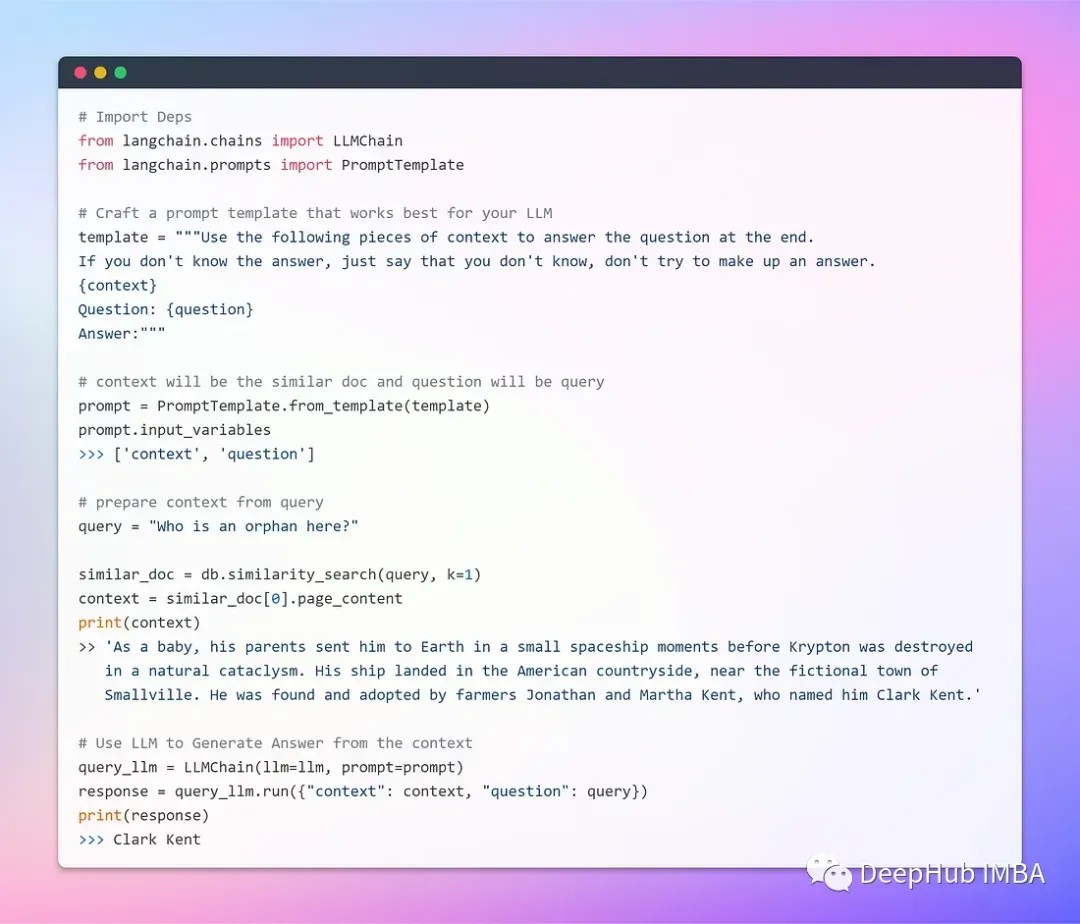
到这一步,已经可以使用本地运行的LLM构建问答机器人了,这个结果还不错,但是我们还有更好的要求,就是一个GUI界面。
5、Streamlit
如果你只喜欢命令行的方式运行,则这一节是完全可选的。因为在这里我们将创建一个允许用户上传任何文本文档的WEB程序。可以通过文本输入提出问题,来对文档进行分析。
因为涉及到文件上传,所以为了防止潜在的内存不足错误,这里只将简单地读取文档并将其写入临时文件夹中并重命名为raw.txt。这样无论文档的原始名称是什么,Textloader都将在将来无缝地处理它(我们这里假设:单用户同时只处理一个文件)。
我们也只处理txt文件,代码如下:
import streamlit as st
from langchain.llms import LlamaCpp
from langchain.embeddings import LlamaCppEmbeddings
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Customize the layout
st.set_page_config(page_title="DOCAI", page_icon="🤖", layout="wide", )
st.markdown(f"""
<style>
.stApp {{background-image: url("https://images.unsplash.com/photo-1509537257950-20f875b03669?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=1469&q=80");
background-attachment: fixed;
background-size: cover}}
</style>
""", unsafe_allow_html=True)
# function for writing uploaded file in temp
def write_text_file(content, file_path):
try:
with open(file_path, 'w') as file:
file.write(content)
return True
except Exception as e:
print(f"Error occurred while writing the file: {e}")
return False
# set prompt template
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# initialize hte LLM & Embeddings
llm = LlamaCpp(model_path="./models/llama-7b.ggmlv3.q4_0.bin")
embeddings = LlamaCppEmbeddings(model_path="models/llama-7b.ggmlv3.q4_0.bin")
llm_chain = LLMChain(llm=llm, prompt=prompt)
st.title("📄 Document Conversation 🤖")
uploaded_file = st.file_uploader("Upload an article", type="txt")
if uploaded_file is not None:
content = uploaded_file.read().decode('utf-8')
# st.write(content)
file_path = "temp/file.txt"
write_text_file(content, file_path)
loader = TextLoader(file_path)
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(docs)
db = Chroma.from_documents(texts, embeddings)
st.success("File Loaded Successfully!!")
# Query through LLM
question = st.text_input("Ask something from the file", placeholder="Find something similar to: ....this.... in the text?", disabled=not uploaded_file,)
if question:
similar_doc = db.similarity_search(question, k=1)
context = similar_doc[0].page_content
query_llm = LLMChain(llm=llm, prompt=prompt)
response = query_llm.run({"context": context, "question": question})
st.write(response)
看看我们的界面:
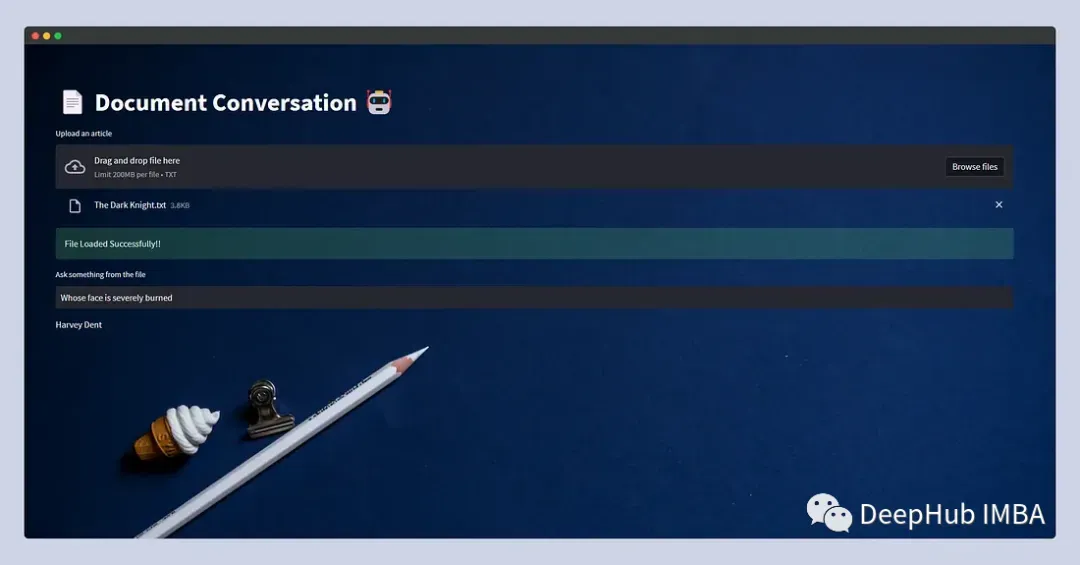
这样一个简单的并且可以使用的程序就完成了。
总结
通过LangChain和Streamlit我们可以方便的整合任何的LLM模型,并且通过GGML我们可以将大模型运行在消费级的硬件中,这对我们个人研究来说使非常有帮助的。
如果你对本文感兴趣,这里是本文的全部源代码,可以直接下载使用:
https://avoid.overfit.cn/post/f6d24e1b178540379b762708bb2dfa37
作者:Afaque Umer
文章出处登录后可见!