Mixture-Rank Matrix Approximation(论文阅读笔记)
存在的问题
- 在现有的LRMA方法中,秩k被认为是固定的,即采用相同的秩来描述所有的user-item。
- 然而,在现实世界,许多的user/item评级矩阵中,如莫维伦斯和Netflix,用户/项目的评级数量显著不同,因此具有不同rank的子矩阵是以共存的。
- 例如,包含用户和评级很少的ratings的子矩阵应该具有较低的rank,例如10或20,而包含用户和具有较多ratings的项目的子矩阵应该具有相对较高的rank,例如50或100。
- 对所有用户和项目采用固定的rank,不能完美地建模评级矩阵的内部结构,从而导致不完美的近似,推荐精度下降。
本文提出的方案
- 对于每一个user/item,都用拉普拉斯概率分布来描述其与不同LRMA模型之间的关系。
- 采用user/item对的联合分布来描述user-item评级与不同的LRMA模型之间的关系。
- 针对与MRMA相关的非凸优化问题,提出了一种利用迭代条件模式(ICM)的学习算法,这种算法通过迭代地最大化每个变量的概率,得到联合概率的局部最大值。
问题推论
使用的符号变量
R, U, V表示矩阵
K表示矩阵近似的秩
对于目标user-item rating矩阵R∈Rm×n,m表示用户数,n表示项目数
R(i,j)表示第i个用户对第j个项目的评分
ˆR(R of head)表示R的低秩近似
k-rank矩阵近似的一般目标是确定用户和项目的特征矩阵
U ∈ Rm×k,V ∈ Rn×k,such that R ≈ ˆR = U VT
问题重现
In real-world rating matrices, e.g., Movielens and Netflix, users/items have a varying number of
ratings, so that a lower rank which best describes users/items with less ratings will easily underfit the
users/items with more ratings, and similarly a higher rank will easily overfit the users/items with less
ratings.
使用PMF分别在K=5/50的条件下,然后比较那些评分小于10分且评分超过50分的user/item的均方根误差(RMSEs)。
结果如下:
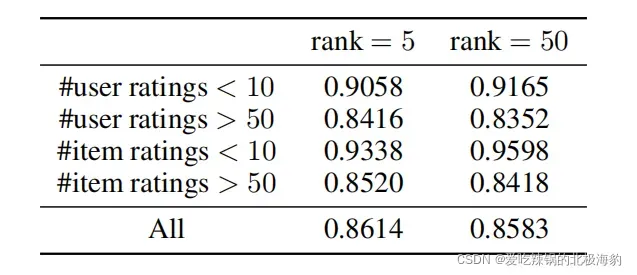
- 如图所示,当rank=5时,user ratings小于10的user/tiem获得的RMSE低于rank=50时的情况。
- 这表明,当k=为50时,PMF模型overfit了ratings小于10的user/tiem。
- 此外,k=50的PMF比k=5的PMF获得了更低的RMSE(更高的准确性),但改进牺牲了用户和少量评级的项目,例如,小于10。
实验程序
- 将MRMA分别用在三个数据集上: MovieLens 1M dataset;MovieLens 10M dataset ;Netflix
Prize dataset - 将数据集按找9:1的比例随机划分为训练集和测试集
- All results are reported by averaging over 5 different splits.
- 使用RMSE衡量准确性
- 用NDCG来measure the item ranking accuracy of different algorithms
- convergence threshold = 0.00001,maximum number of iterations=300
- 使用的rank是{10, 20, 30, …, 300}
- 将结果与其它6个基于近似矩阵的协同过滤算法进行比较( BPMF,GSMF,LLORMA,WEMAREC,MPMA, SMA)
MRMA VS PMF
Mixture-Rank Matrix Approximation vs. Fixed-Rank Matrix Approximation
- 给定一个固定的秩k,MRMA中对应的秩k模型与PMF相同
- 比较在不同的rank下,MRMA和PMF的RMSE
- 学习率是0.01,用户特征正则化因子是0.01,物品特征正则化因子是0.001
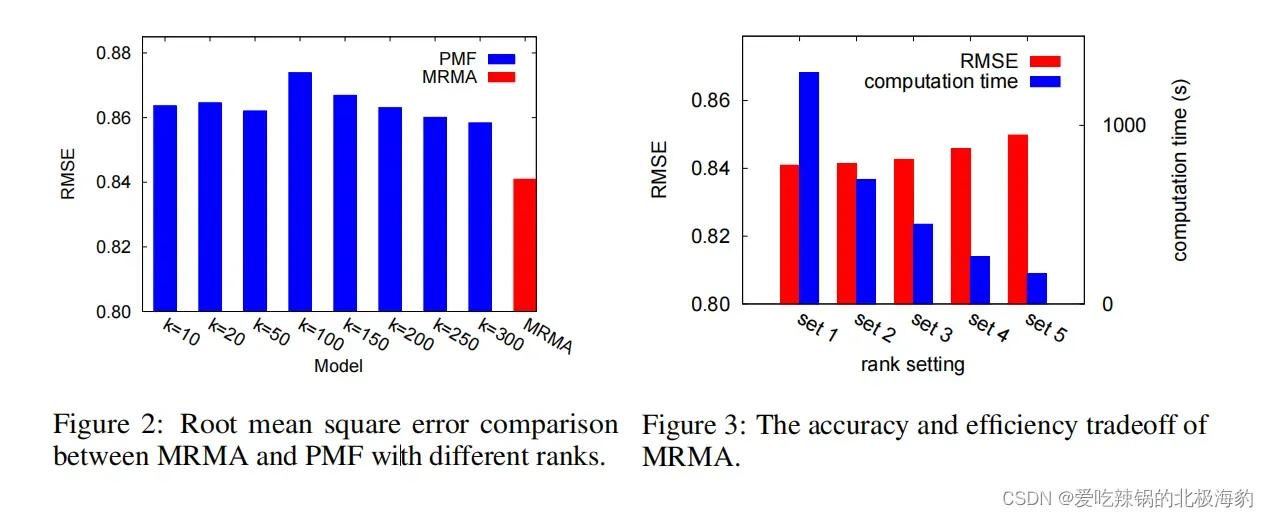
- 从左图观察发现,当K<=100时,PMF随着K的变化,其准确率也在不断波动,并不稳定。因为固定秩的近似矩阵不可能对所有用户和项目都是完美的,因此许多用户和项目在固定秩小于100的情况下是欠拟合的或过拟合的。
- 当K>100时,K越大PMF的RMSE越小,因为正则化项可以帮助提高泛化能力。
- 然而,所有等级的PMF的准确率都低于MRMA,因为个体用户/项目可以在MRMA中给具有最优等级的子模型更高的权重,从而缓解过拟合或过拟合。
Terminology
LRMA
概率矩阵分解
ICM
非凸优化问题
在实际建模中,判断一个优化问题是否为凸优化问题,一般看以下几点:
NDCG(Normalized Discounted cumulative gain, 归一化折损累计增益)
- 具有高相关性的结果比具有中等相关性的结果对最终指标得分的影响更大
- 当具有高相关性的结果出现在较高位置时,该指标越高
RMSE(Root Mean Square Error)均方根误差,越小越好
测量值与真实值之间的偏差。
它通常被用作衡量机器学习模型预测结果的标准。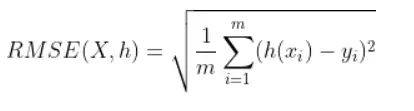
文章出处登录后可见!