前言
卷积神经网络在图像数据的处理中大放异彩。最早发布的卷积神经网络LeNet已经能取得与支持向量机相媲美的结果,深度学习时代又诞生了各种深度网络,特点和适用背景也各不相同。本文按时间顺序介绍几种经典的卷积神经网络模型,内容包括其特点、原理、模型结构及优缺点。
一、LeNet
发布最早的卷积神经网络之一,它结构简单,只有五层,包括两个卷积层和三个全连接层。该网络在当时的一个主要应用场景是手写数字识别。该网络中,第一个卷积层有六个不同的卷积核,每个卷积核都将接收输入图片并对其进行卷积操作和激活,得到特征图的一个通道的输出,所以多个卷积核可以改变特征图的通道数。汇聚层(池化层)不能改变通道数,也没有参数可以学习,只能缩小特征图的尺寸。第二个汇聚层的输出展平成向量后输入全连接层,经过三个全连接层的计算后输出10种可能结果的概率。概率最大的输出类别即为该网络给出答案。
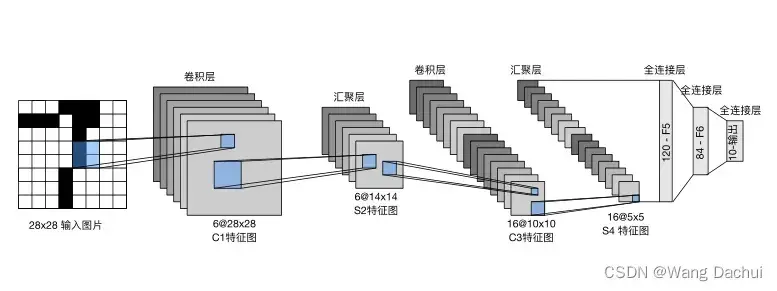
LeNet虽然简单,但包含了卷积神经网络的基本要素,便于学习和理解。之后发展的卷积网络也大致遵循这一脉络,先对图像进行许多层卷积和汇聚操作,再在结尾部分使用全连接层分类。
二、AlexNet
AlexNet与LeNet的设计理念基本相同,只不过AlexNet在LeNet的基础上加深了网络层次,更换了激活函数。
受限于数据规模和硬件运算速度,深层的神经网络在LeNet时代并不流行,处理较多较大的数据时人们还是会选择需要人工找特征的机器学习方法,神经网络端到端的优势无法发挥出来。AlexNet的发明者Alex Krizhevsky首先实现了可以在GPU上运行的深度卷积神经网络,这是一个巨大突破,直接推动了深度学习的热潮。
解决了硬件问题之后,Alex Krizhevsky及其合作者开始尝试加深网络结构,AlexNet便诞生了。
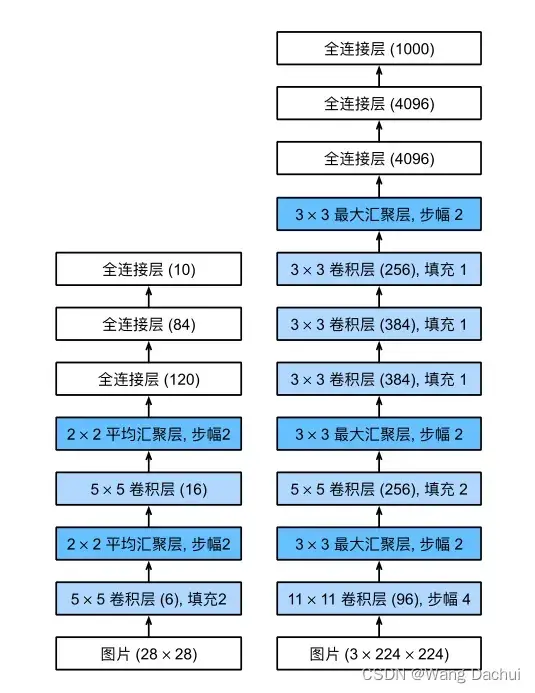
上图便是LeNet(左)与AlexNet(右)的结构图。
为了挑战ImageNet数据集,AlexNet在规模上做了很多扩展。由于图片尺寸相较于手写数字图片显著增大,AlexNet的第一个卷积层采用11×11的尺寸,每层的输出通道数也扩充了一个量级。激活函数也替换成了在深度网络中表现更好的ReLU。
三、VGGNet
VGGNet也是在前两种卷积网络上的扩展,它是第一个对卷积层进行抽象的网络。VGG将多个卷积层和其后的汇聚层打包起来,称作块。网络设计者在设计时可以自由选取块,像搭积木一样用各种块搭出一个网络。这样的思想在计算机领域非常常见,如底层的晶体管、逻辑门,编程语言中的函数、类、框架。
原始VGG网络有5个卷积块,其中前两个块各有⼀个卷积层,后三个块各包含两个卷积层。第⼀个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
四、GoogLeNet
GoogLeNet采用一种叫Inception的块结构,称为Inception块。
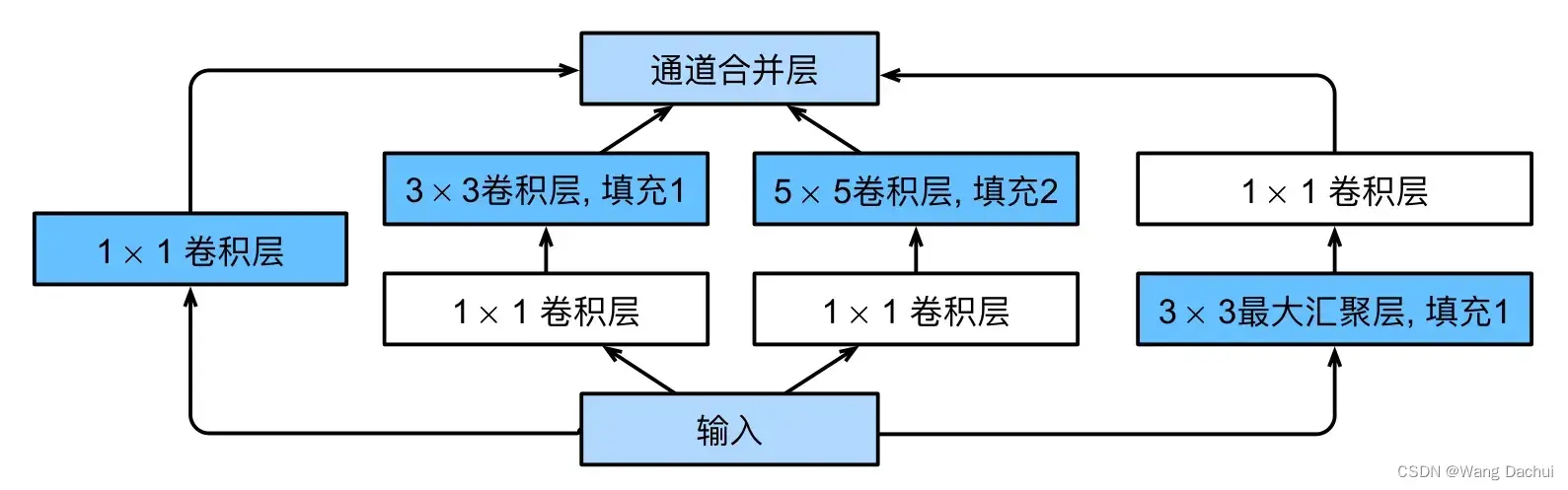
每一个块的输入都将分成四条路线,在各自的路线上进行相应操作之后四个不同的输出(使用不同填充来保证输出与输入的尺寸一致)将在通道维上叠加,作为整个块的输出继续向网络的更深层传递。
Inception块为什么使用四条并行路径?
论文给出的答案是使用不同大小的卷积核组合是有利的。对于相同的输入使用不同大小的卷积核探索图像,可以得到同一图像中不同尺寸上的细节,比起只用一个卷积核,用四种不同的卷积核所得到的信息更多样,更全面。
为什么在最后使用全局平均汇聚层?
全连接层的参数开销是非常大的,应该尽量避免,使用全局平均汇聚层可以代替全连接层,一定程度上减少参数开销。
五、ResNet
神经网络的层是越多越好吗?表面上看,更多的层可以增强网络的表达能力,但层数多了不仅会带来各种问题,如梯度消失,参数开销增大、容易过拟合等,而且随意增加的层数并不一定会起到好的作用。
ResNet的核心思想正好可以解决这一问题。假设一个设计好的神经网络可以表达一部分函数,但是要拟合的目标函数不包含在神经网络可表达的范围内,因此这一网络只能在可选范围内找到一个最接近目标函数的参数组合。增加层虽然可以扩大可表达函数的范围,但却也有可能让可选范围变得离最优解更远。但如果增加的层可以实现恒等映射,那么当其为恒等映射时,整个神经网络与之前并无区别,而增加的这一层参数又可以变化,实现了表达能力的增强,拓宽了可表达函数的范围,这时增加的层才是有益的。
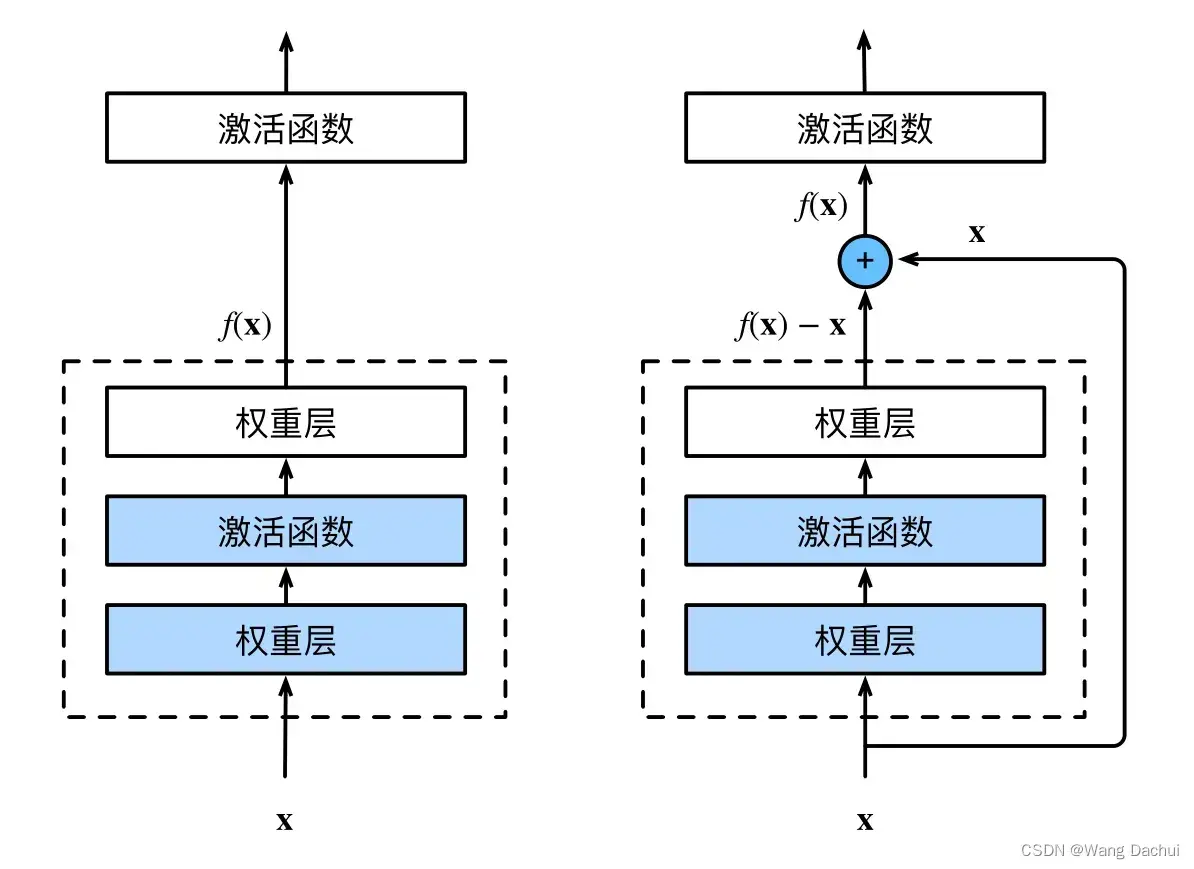
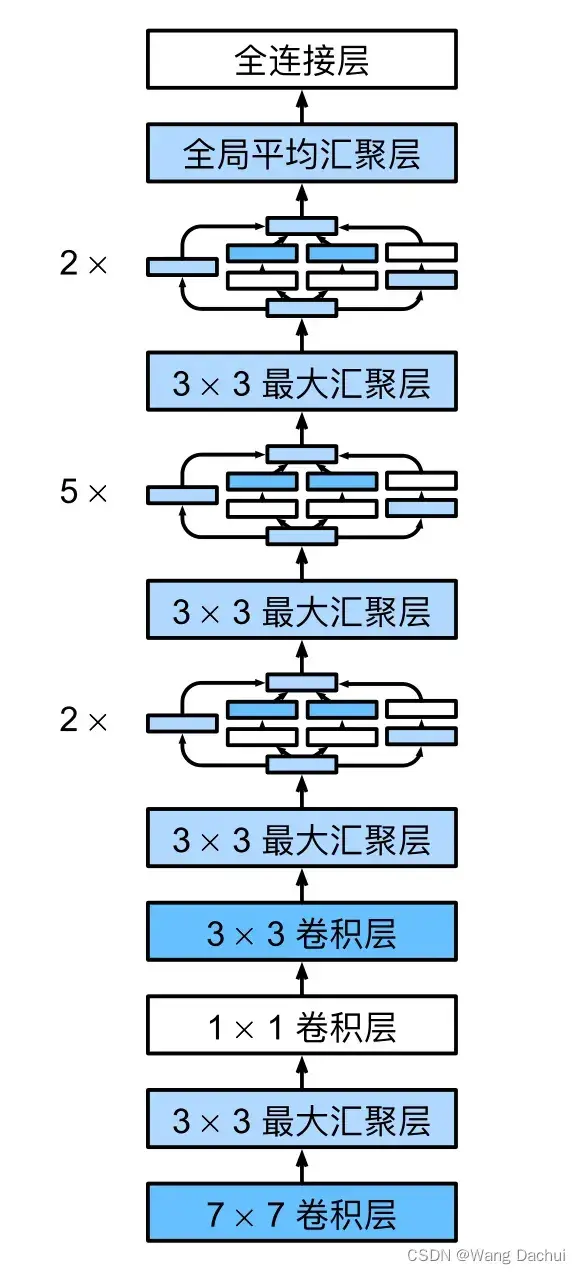
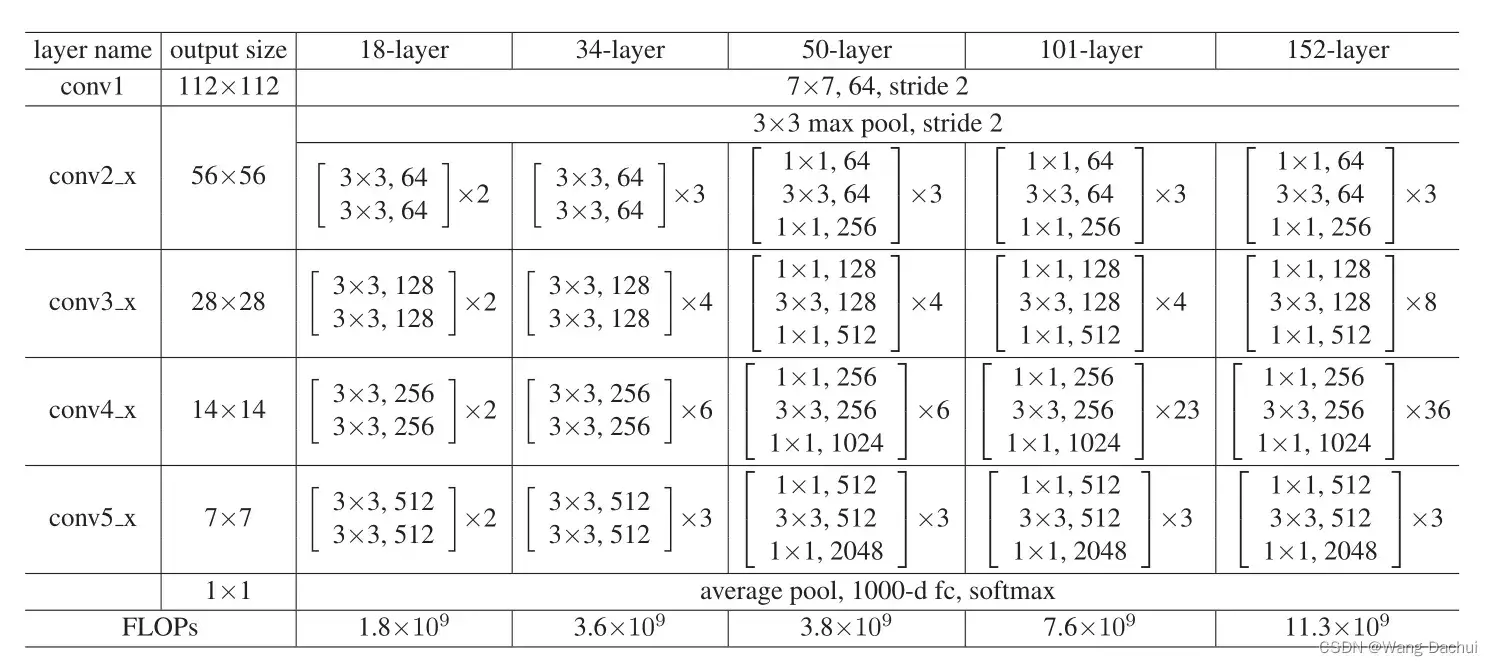
上图(右)是ResNet中的一个残差块,该块的聪明之处就在于将整个块的输出f(x)-x(称之为残差)与输入x相加后再送入激活函数,如果块的输出f(x)-x可以是零,那么加上输入后就是x,这就是一个恒等映射了,增加的这个块最差也是相当于不存在,更何况它还能通过改变参数实现更丰富的表达。事实上直到现在残差网络都是工业界最流行的网络模型,下图是原论文中给出的网络结构。
六、DenseNet
DenseNet是ResNet的扩展,如果ResNet意味着函数可以在网络中被拆成f(x)=x+g(x),那么是否意味着一个函数也可以被拆成超过两部分?DenseNet就是基于这一思路而诞生的。
DenseNet与ResNet的一个主要区别是ResNet是块输出与输入的数值相加,而DenseNet是通道维上的连结。
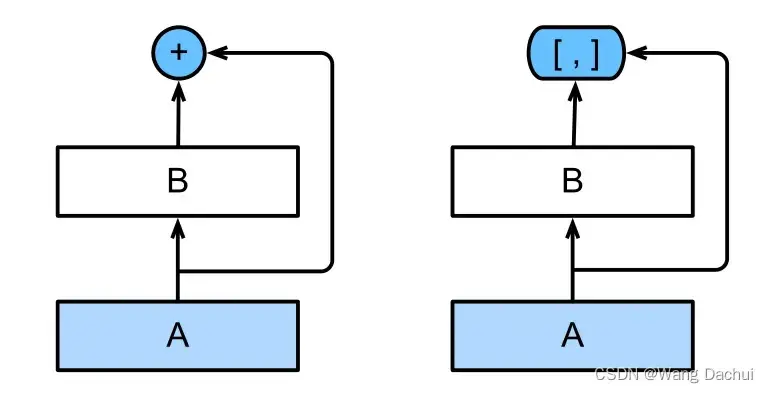
如图(右)表示一个稠密块,假设A的输出是,B的输出是
,那么该稠密块的输出就是
,该输出继续向前传递进入下一个稠密块,下一个稠密块也会保留自己的输入等待与输出拼接,而输出是
,拼接后第二个稠密块的输出就变成了
,这就实现了最后一层与之前所有层的紧密相连。为避免模型太过复杂,DenseNet对稠密块的输出采用过渡层来降低模型复杂度,具体做法是用1×1卷积减小通道数,用平均汇聚层减小尺寸。
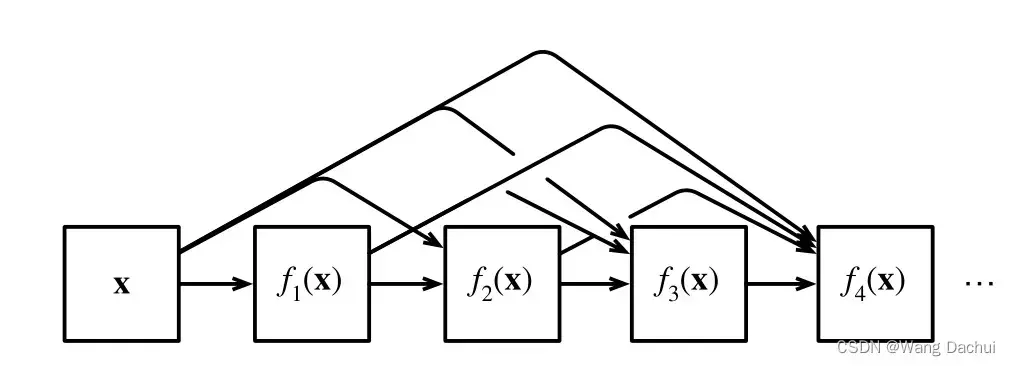
以上图为例,的计算同时依赖于
和
,因此
算出来后表示为
之后
又要与
和
拼接才可用于
的计算,这样层层连接下去,就形成了函数之间稠密的网络,但在模型的具体实现上其实只需将稠密块简单堆叠就可实现这一效果。
总结
本文按发展时间顺序简单介绍了几种经典的卷积神经网络,可以看到每个网络基本都是在之前网络的基础上做出创造性的改进,平地起高楼是很难的,研究者们都是站在了巨人的肩膀上。正是每一位科研人员的创造和贡献,才构筑起宏伟的科学大厦。
文章出处登录后可见!