原文链接:https://www.techbeat.net/article-info?id=4375
作者:seven_
最近的一些工作向我们展示了AIGC在创造性生成图像、视频等方面的潜力,相信已有很多研究者在沿着这一方向进行拓展式的挖掘和创新。目前已有很多衍生应用出现在了大家眼前,例如仅通过手绘草图生成具有真实感的照片,该工作可以应用在很多设计领域,将设计师寥寥数笔画下的草图进行加工,可以提高工作效率。再比如另一个非常新奇的新功能,模型根据用户输入的指令就可以对目标图像进行P图修改,这一功能受到了广泛的关注。

论文链接:
https://arxiv.org/abs/2211.09800
代码链接:
https://www.timothybrooks.com/instruct-pix2pix
今天介绍的这篇文章就是这一应用的最新研究进展,来自加州大学伯克利分校。本文作者提出了一种可以完全根据人类指令来对图像进行编辑的模型,命名为InstructPix2Pix。需要注意的是,InstructPix2Pix与之前类似的方法不同,之前的方法在接收编辑指令时,更多的是倾向于描述编辑后的目标状态,例如在下图最左侧的“向日葵-玫瑰花”示例中。

之前方法输入的指令可能是“一个花盆中插满了玫瑰花”,其实这种描述首先带有一定的不确定性。而对于图像编辑任务本身而言,我们需要让模型关注的是要编辑的主体,以及编辑的最终效果。因此,最合适的编辑指令设置为“将向日葵更换为玫瑰花”即可,这样也更加符合人类的直觉。
InstructPix2Pix的提出就是为了解决这一问题,其整合了目前较为成熟的两个大规模预训练模型:语言模型GPT-3[1]和文本图像生成模型Stable Diffusion[2],生成了一个专用于图像编辑训练的数据集,随后训练了一个条件引导型的扩散模型来完成这一任务。此外,InstructPix2Pix模型可以在几秒钟内快速完成图像编辑操作,这进一步提高了InstructPix2Pix的可用性和实用性。
一、本文方法
InstructPix2Pix模型的整体构建流程分为两大部分:(1)生成一个专用于图像编辑任务的数据集。(2)使用生成的数据集训练一个条件扩散模型,该模型可以按照人类的指令对目标图像进行各种形式的编辑操作,例如替换物体、更改图像本身的风格、修改图像的背景环境等等。如下图所示,当给InstructPix2Pix输入简单的更换背景指令“Make it Pairs”,模型会将画面的背景更改为埃菲尔铁塔,当输入指令为“Turn this into 1900s”,模型会将整个画面风格转换为20世纪拍摄的胶片风格,效果也是非常的逼真生动。

下图展示了InstructPix2Pix构建的框架图,作者还介绍到,InstructPix2Pix对任意输入的真实环境图像和人类指令都实现了zero-shot的泛化。下面我们将详细介绍上述步骤的具体实现细节。

1.1 多模态编辑任务训练数据集构建
上文提到,作者在InstructPix2Pix中整合了两个大规模预训练模型:语言模型GPT-3和文本图像模型Stable Diffusion,同时利用这两个模型中蕴含的知识构建了一个多模态训练数据集,该数据集主要包含了由文本编辑指令和编辑前后对应图像构成的图像对。在构建过程中,作者首先从文本编辑指令出发,生成成对的图像描述。随后再根据这些描述生成对应的成对图像构成训练样本。
1. 生成成对的图像描述
在这一过程中,需要先给定一个图像文本描述,例如“一个女孩骑马的照片”,如上图(a)中所示,随后需要根据该文本描述生成一些合理的编辑指令,例如“让一个女孩骑龙”,更合理一点的描述为“一个女孩骑龙的照片”,这一操作可以通过GPT-3类似的文本大模型完成。需要注意的是,这些操作完全在文本域中进行,这样做可以生成大量的、多样性的编辑指令,同时能够保证图像变化和文本指令之间的对应关系。
具体来说,作者对GPT-3进行了专门的微调,首先收集了一个规模相对较小的人工编辑三元组数据集,三元组包含(1)输入的图像描述,(2)编辑指令,(3)输出的图像描述,数据集详细介绍如下表所示。
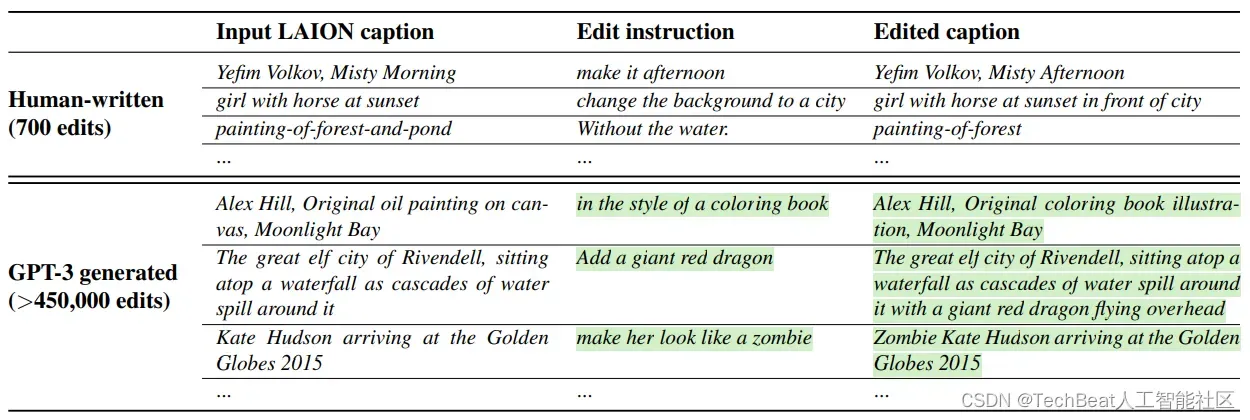
作者首先收集了700条图像描述样本,然后手动编写了编辑指令和输出图像描述,然后使用这700条样本对GPT-3模型进行微调,微调后的模型可以自行生成详细的训练样本,上表非常鲜明的展示了作者手动生成的样本和GPT-3随后生成样本的对比。
2. 根据图像描述对生成图像
在得到成对的编辑指令后,作者使用文本图像模型Stable Diffusion将这两个文本提示(即编辑前和编辑后)转换为一对相应的图像,如上图(b)所示。然而这一过程仍然面临一个重大挑战:目前的文本到图像模型无法保证图像内容身份信息的一致性,即使在输入的条件提示变化非常小的情况下。
例如,我们为模型指定两个非常相似的文本提示:“一张猫的照片”和“一张黑猫的照片”,模型可能会产生两只截然不同的猫的图像,这对本文图像编辑的目的来说是不合理的。为了解决这一问题,作者想到使用这些成对数据来训练模型编辑图像,而不是遵循这些模型原本的生成模式去生成随机图像。
作者使用了最近新提出的Prompt-to-Prompt方法[3]来完成操作,该方法可以针对一个输入文本生成多代近似的图像,且这些图像彼此之间含有相同的身份信息,Prompt-to-Prompt通过在去噪过程中使用交互注意力权重来实现。下图展示了使用Prompt-to-Prompt方法和使用随机方法生成的图像效果对比。

1.2 条件扩散模型InstructPix2Pix
InstructPix2Pix的建模本质是从隐空间扩散模型(Latent Diffusion)演变而来,Latent Diffusion通过在带有编码器 和解码器
的预训练变分自动编码器的隐空间中运行来提高扩散模型的效率和质量。对于一个图像
,扩散过程将噪声添加到编码的隐层向量
中,产生一个噪声隐变量
,其中噪声等级随时间步数
而增加。然后训练一个网络
,它可以预测在给定的图像条件
和文本指令条件
下添加到噪声隐变量
中的噪声信息,然后通过以下目标函数来优化模型:
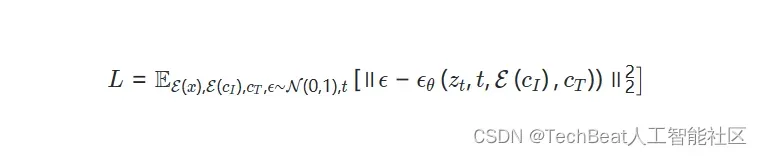
为了进一步提高图像生成效果以及模型对输入条件的遵循程度,作者在InstructPix2Pix中也引入了Classifier-free引导策略。Classifier-free扩散引导是一种权衡扩散模型生成的样本质量和多样性的方法。其中隐式分类器 会将更高的可能性分配给条件
,以提高生成图像的视觉质量并使采样图像更好地与输入条件相符合。Classifier-free引导的训练需要同时联合训练有条件和无条件去噪的扩散模型,并在推理时结合两个分数进行估计。
对于本文的任务,作者设计了一个评分网络 ,其中有两个条件:输入图像
和文本指令
。在训练过程中,使InstructPix2Pix能够针对两个或任一条件输入进行有条件或无条件去噪。为此,作者引入了两个指导尺度
和
,可以对其进行调整以权衡生成的样本与输入图像的遵循程度以及它们与编辑指令的遵循程度,评分网络的分数估计如下:
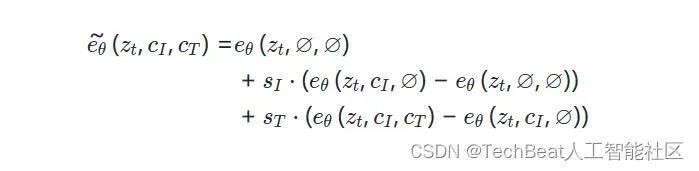
二、实验结果
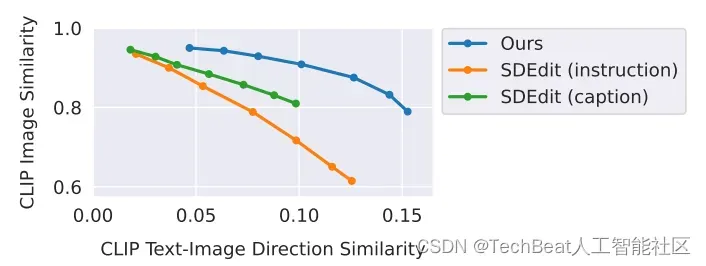
在实验部分,作者分别将本文提出的InstructPix2Pix与最近提出的几个相似的图像编辑模型SDEdit和Text2Live进行定性和定量的实验对比,如下图所示。我们可以观察到,虽然SDEdit和Text2Live等模型也可以在对图像整体风格基本保持不变的情况下对图像主体进行编辑,但其会丢失图像主体的一部分身份信息,尤其是在进行较大更改时。此外这些方法需要更加完整的图像生成描述,而不是编辑指令。

- 生成图像与输入图像之间的CLIP嵌入余弦相似度(用来刻画编辑图像与输入图像的内容或身份一致性程度)。
- 生成图像与指令文本的定向CLIP嵌入相似度(用来刻画编辑图像与指令文本中包含的变化一致性程度)。
通过这两个指标,可以清晰地展现出模型在图像编辑过程中对图像主体的保留程度以及编辑效果。从结果来看,InstructPix2Pix具有更明显的优势。
三、总结
本文分别借助语言大模型GPT-3和图像文本模型Stable Diffusion构建出一个具有更高智能的图像编辑模型InstructPix2Pix。InstructPix2Pix的出现解决了之前方法中存在的编辑指令不直接、不确定的问题。作者通过手动收集了700条标注数据对现有大模型进行微调,进而完成了整个框架的训练,这一过程也为我们明确了对现有大模型装置的二次研究路径,增强了我们对AIGC社区开发更多更好应用的信心。
参考文献
[1] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[2] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
[3] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel CohenOr. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
[4] Tengfei Wang, Ting Zhang, Bo Zhang, Hao Ouyang, Dong Chen, Qifeng Chen, and Fang Wen. Pretraining is all you need for image-to-image translation. arXiv preprint arXiv:2205.12952, 2022.
Illustration by Manypixels Gallery from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com
文章出处登录后可见!