大语言模型学习之LLAMA 2:Open Foundation and Fine-Tuned Chat Model
自从开源以来,LLAMA可以说是 AI 社区内最强大的开源大模型。但因为开源协议问题,一直不可免费商用。近日,Meta发布了期待已久的免费可商用版本LLAMA 2。

在这项工作中,我们开发并发布了LLAMA 2,这是一系列预训练和微调的大型语言模型(LLMs),规模从70亿到700亿个参数不等。我们的微调LLMs,称为Llama 2-Chat,专为对话场景进行了优化。我们的模型在大多数我们测试的基准中表现优于开源对话模型,并且根据我们的人工评估,其有益性和安全性使其成为闭源模型的合适替代品。我们详细描述了我们对Llama 2-Chat的微调和安全性改进方法,旨在让社区能够在我们的工作基础上发展并为负责任的LLM发展做出贡献。
项目地址:https://github.com/facebookresearch/llama
论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
快速了解
简单来说,LLaMa 2 是 LLaMA 的下一代版本,具有商业友好的许可证。它有 3种不同的尺寸:7B、13B 和 70B。预训练阶段使用了2万亿Token,SFT阶段使用了超过10w数据,人类偏好数据超过100w。7B & 13B 使用与 LLaMA 1 相同的架构,并且是商业用途的 1 对 1 替代。
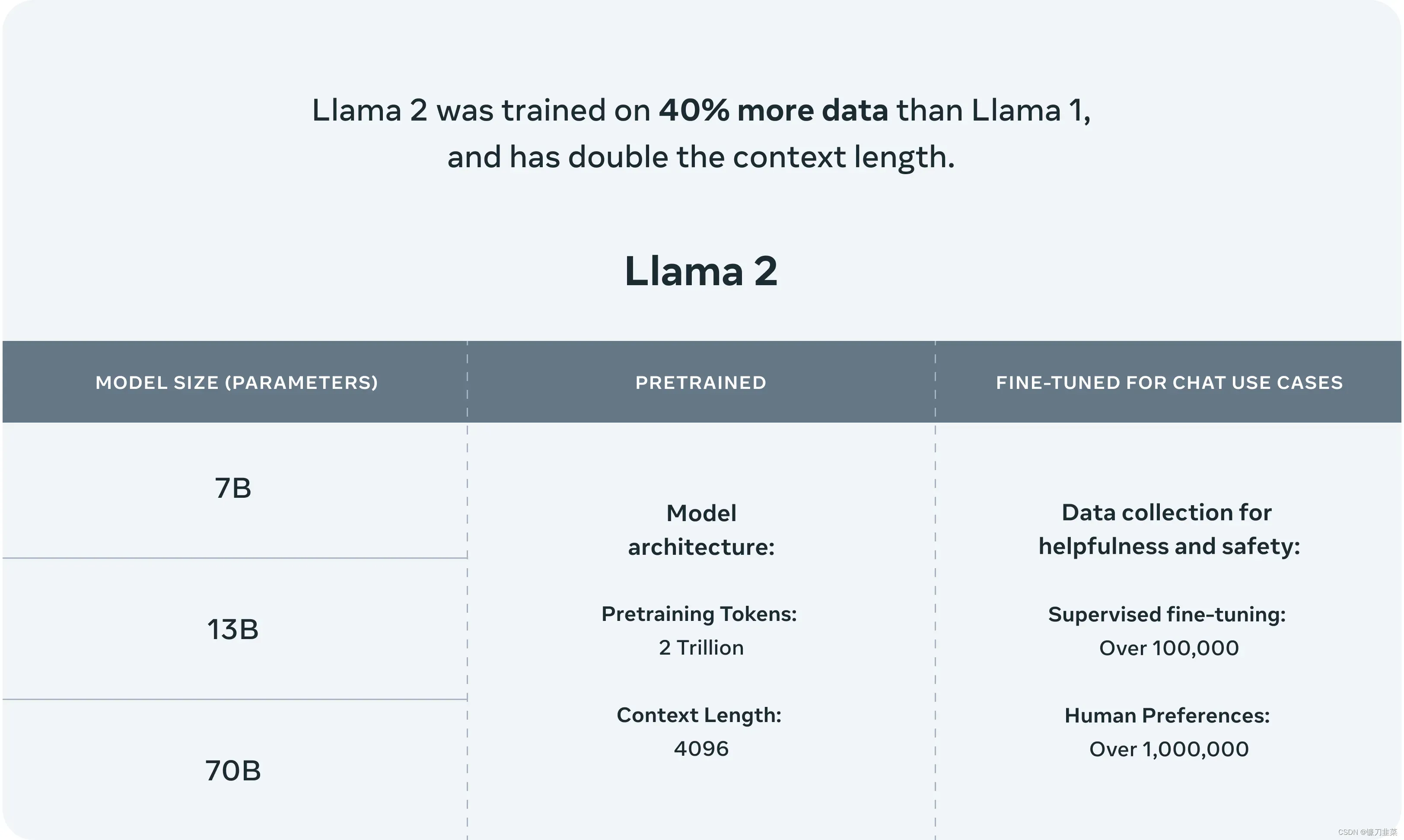
另外大家最关心的Llama2和ChatGPT模型的效果对比,在论文里也有提到,对比GPT-4,Llama2评估结果更优,绿色部分表示Llama2优于GPT4的比例,据介绍,相比于 Llama 1,Llama 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制,可以理解和生成更长的文本。。
LLAMA 2体验链接:
- https://www.llama2.ai/
- https://replicate.com/a16z-infra/llama13b-v2-chat
- https://huggingface.co/meta-llama
总的来说,作为一组经过预训练和微调的大语言模型(LLM),Llama 2 模型系列的参数规模从 70 亿到 700 亿不等。其中的 Llama 2-Chat 针对对话用例进行了专门优化,使用来自人类反馈的强化学习来确保安全性和帮助性。
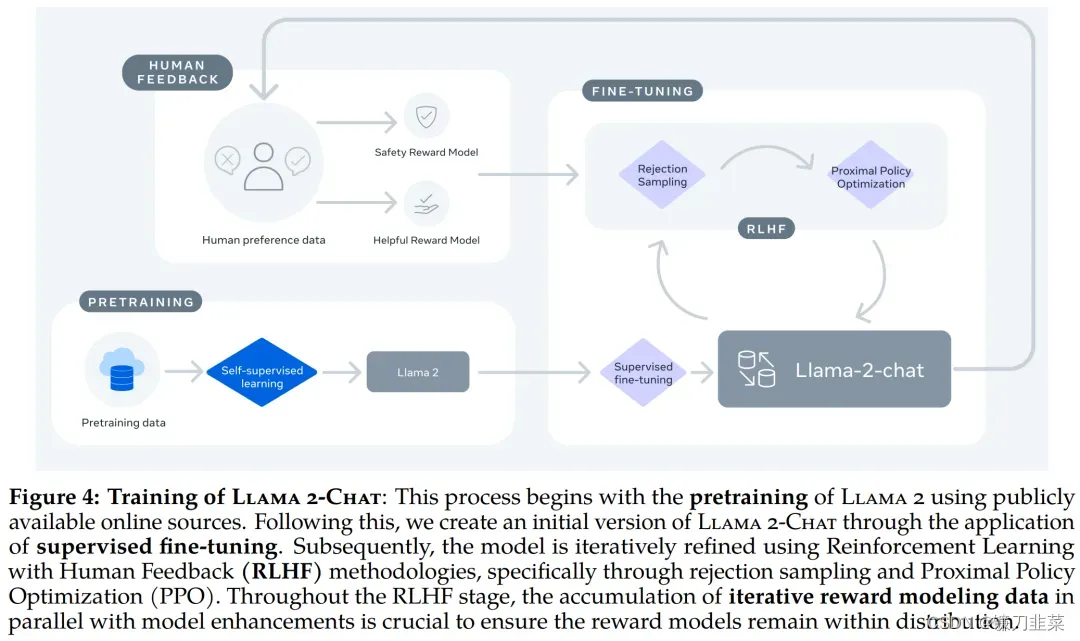
训练 Llama-2-chat:Llama 2 使用公开的在线数据进行预训练。然后通过使用监督微调创建 Llama-2-chat 的初始版本。接下来,Llama-2-chat 使用人类反馈强化学习 (RLHF) 进行迭代细化,其中包括拒绝采样和近端策略优化 (PPO)。
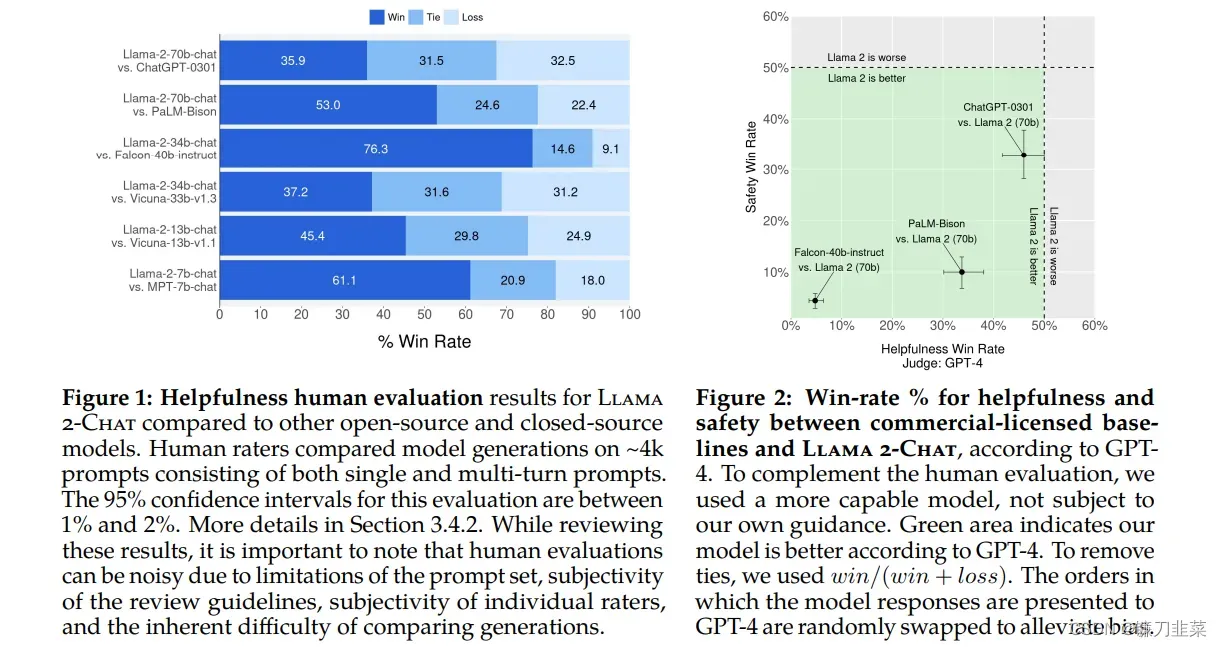
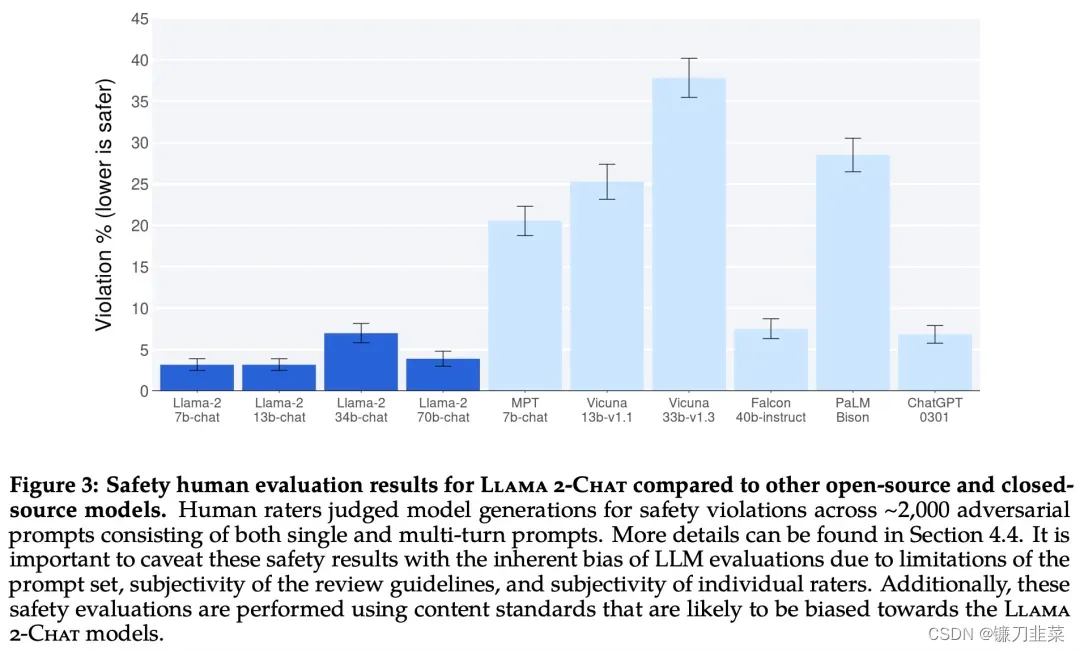
Llama 2 模型系列除了在大多数基准测试中优于开源模型之外,根据 Meta 对有用性和安全性的人工评估,它或许也是闭源模型的合适替代品。
预训练
为了创建全新的 Llama 2 模型系列,Meta 以 Llama 1 论文中描述的预训练方法为基础,使用了优化的自回归 transformer,并做了一些改变以提升性能。
(1)数据方面
具体而言,Meta 执行了更稳健的数据清理,更新了混合数据,训练 token 总数增加了 40%,上下文长度翻倍。下表 1 比较了 Llama 2 与 Llama 1 的详细数据。
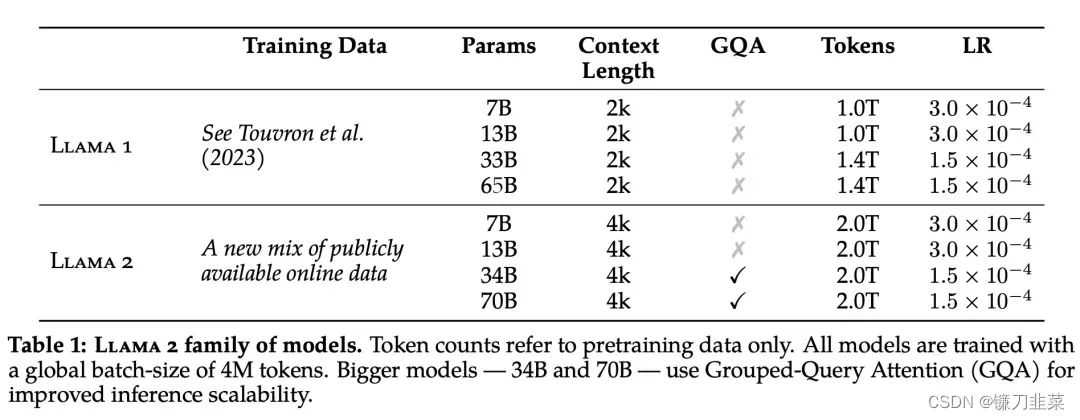
Llama 2 的训练语料库包含了来自公开可用资源的混合数据,不包括 Meta 产品或服务相关的数据。而且努力从某些已知包含大量个人信息的网站中删除数据,注重隐私。对 2 万亿个token的数据进行了训练,因为这提供了良好的性能与成本权衡,对最真实的来源进行上采样,以增加知识并抑制幻觉,保持真实。同时进行了各种预训练数据调查,以便用户更好地了解模型的潜在能力和局限性,保证安全。
(2)模型结构
Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构、使用 RMSNorm 的预归一化、SwiGLU 激活函数和旋转位置嵌入RoPE。与 Llama 1 的主要架构差异包括增加了上下文长度和分组查询注意力(GQA)。
- 上下文长度
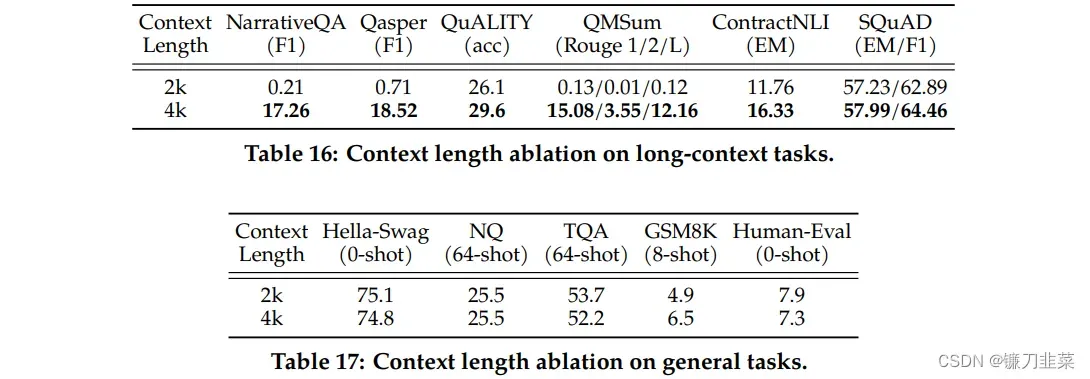
Llama 2 的上下文窗口从 2048 个标记扩展到 4096 个字符。越长上下文窗口使模型能够处理更多信息,这对于支持聊天应用程序中较长的历史记录、各种摘要任务以及理解较长的文档。多个评测结果表示较长的上下文模型在各种通用任务上保持了强大的性能。
表 16 比较了 2k 和 4k 上下文预训练在长上下文基准上的性能。 两个模型都针对 150B 令牌进行训练,保持相同的架构和超参数作为基线,仅改变上下文长度。 观察到 SCROLLS 的改进,其中平均输入长度为 3.5k,并且 SQUAD 的性能没有下降。 表 17 显示较长的上下文模型在各种通用任务上保持了强大的性能。
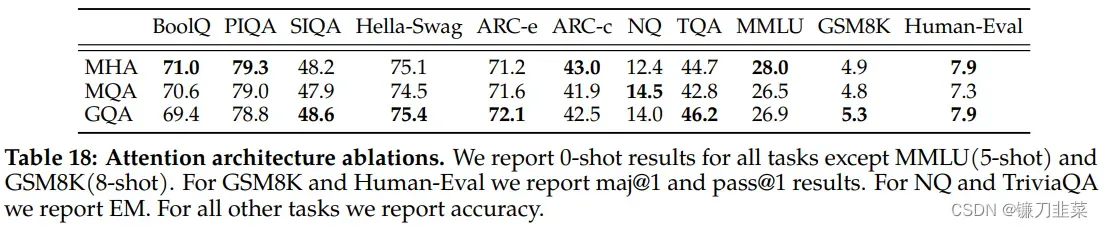
- Grouped-Query Attention 分组查询注意力
- 自回归解码的标准做法是缓存序列中先前标记的键 (K) 和值 (V) 对,从而加快注意力计算速度。然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA) 模型中与 KV 缓存大小相关的内存成本显着增长。对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能。可以使用具有单个 KV 投影的原始多查询格式(MQA)或具有 8 KV 投影的分组查询注意力变体(GQA)。
- Meta 将 MQA 和 GQA 变体与 MHA 基线进行了比较,使用 150B 字符训练所有模型,同时保持固定的 30B 模型大小。为了在 GQA 和 MQA 中保持相似的总体参数计数,增加前馈层的维度以补偿注意力层的减少。对于 MQA 变体,Meta 将 FFN 维度增加 1.33 倍,对于 GQA 变体,Llama将其增加 1.3 倍。从结果中观察到 GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均优于 MQA 变体。
(3)参数方面
在超参数方面,Meta 使用 AdamW 优化器进行训练,其中 ,
文章出处登录后可见!