文章目录
论文:
《High-Resolution Image Synthesis with Latent Diffusion Models》
github:
https://github.com/CompVis/latent-diffusion
摘要
为了使得DM在有限计算资源下训练,同时保留其生成质量及灵活性,作者将其应用于预训练编解码器的隐空间。基于表征训练扩散模型达到降低计算量及细节保留的最优点。作者引入cross-attention层,增强DM生成能力,在图像修复、条件图像生成、文本图像生成、无条件图像生成、超分取得新SOTA。
背景
扩散模型 VS. GAN
优点:扩散模型不存在GAN中模式坍塌以及训练不稳定问题;
缺点:扩散模型训练(150 – 1000 V100 days)及推理(50k samples 5 days a A100)成本大;
现有扩散模型训练分为两阶段:
1、感知压缩阶段:移除高频信息但仍学到语义变化
2、生成模型学习语义压缩过的数据的语义和概念组成
作者训练自编码器提供低维表征空间,其余数据空间感知上等价。隐空间复杂度降低使得可通过简单网络进行高效图像生成。
本文贡献如下:
1、跟纯Transformer方法相比,本文方法更适用于高维数据,因此可以在压缩维度上提供逼真的细节重构,可以生成高分辨率图片;
2、在无条件图像生成、图像修复、超分领域达到有竞争力的表现,同时显著降低计算成本;
3、不需要精细调整模型重构及生成权重;
4、对于超分、图像修复等密集任务,本模型可以生成1024*1024分辨率图片;
5、基于cross-attention设计条件机制,可用于跨模态训练,比如类别条件、文本到图像生成、layout到图像
算法
为了降低计算量,作者将压缩与生成训练阶段分离,具体的:使用autoencoding模型学习感知上等价于图像空间的隐空间,降低计算复杂性。
该方法有以下好处:
1、扩散模型在低维空间采样,计算更加高效;
2、使用扩散模型从UNet结构获得的归纳偏置,对于有空间结构数据格外有效;
3、通用压缩模型的隐空间可用于训练多种生成模型用于其他采样应用。
3.1. Perceptual Image Compression
通过感知损失及基于patch的对抗损失训练autoencoder;
具体而言,对于图像,编码器
将其编码进隐空间
,解码器基于隐空间重构图像为
为避免隐空间高方差,作者使用两种不同正则化方法:
KL-reg,在可学习隐空间对标准归一化增加KL惩罚;
VQ-reg,在decoder中使用量化层;
隐空间z为二维结构,具有相对温和压缩率,达到更好重构效果。
3.2. Latent Diffusion Models
去噪自编码器,用于预测step t去噪后变体或者说所增加噪声,扩散模型目标函数如式1.
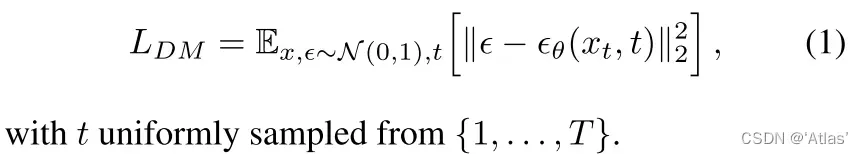
3.3. Conditioning Mechanisms
为了将DM转变为灵活有条件图像生成器,通过交叉注意力机制(高效学习各种各样输入模态)增强潜在UNet主干。为了预处理输入条件y,作者通过特定编码器将y映射为中间表征
,通过cross-attention层将其映射到UNet中间层,其中
为UNet中间表征,
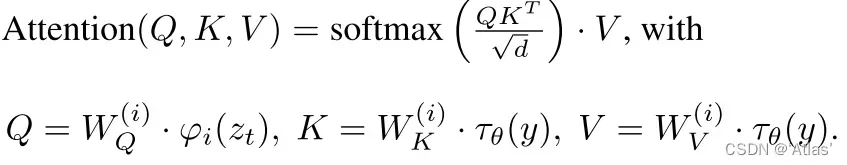
实验
4.1. On Perceptual Compression Tradeoffs
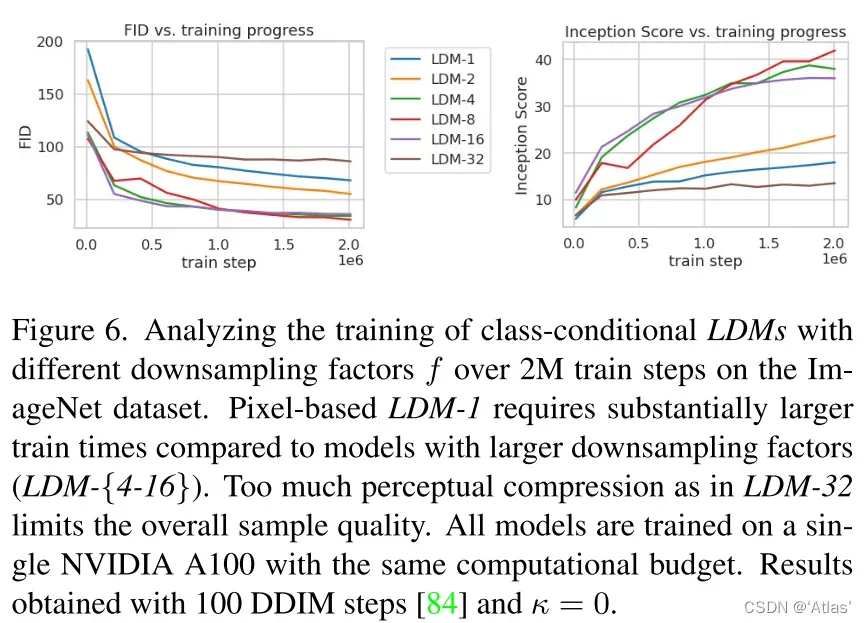
图6表明低降采样率导致训练慢;过高降采样率导致失真。LDM-{4-16}在效率及感知真实性达到较好平衡;
4.2. Image Generation with Latent Diffusion
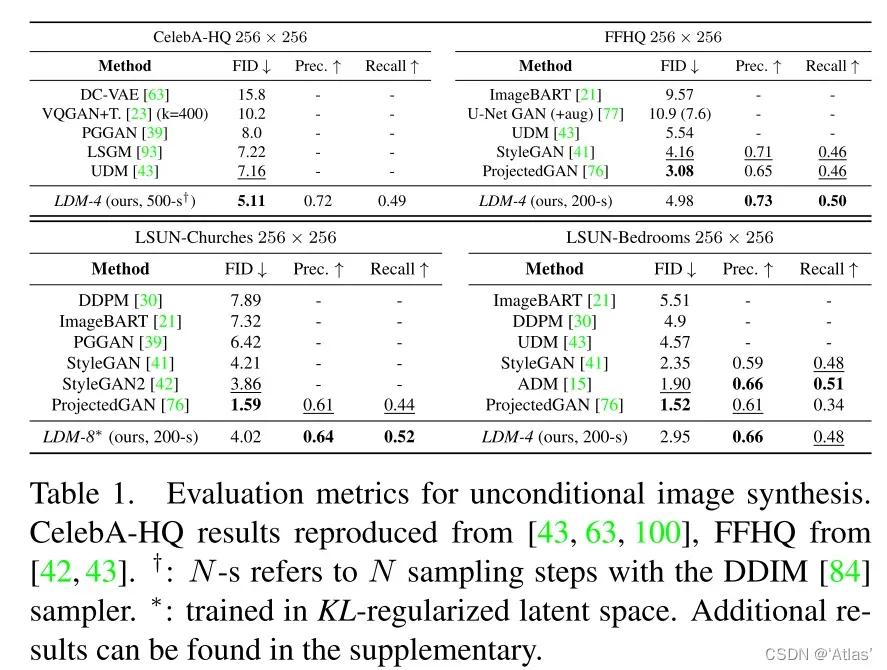
对于无条件生成256*256分辨率图像,表1表明在CelebA-HQ数据集达到SOTA,5.11;
4.3. Conditional Latent Diffusion
表2表明在MS-COCO数据集文本引导图像生成任务,LDM使用较少参数,但是与最近扩散模型及自回归方法达到相近性能。LDM-KL-8-G表示classifier-free diffusion guidance

表3表明在ImageNet数据集基于类别有条件的图像生成任务,LDM超越SOTA方法ADM
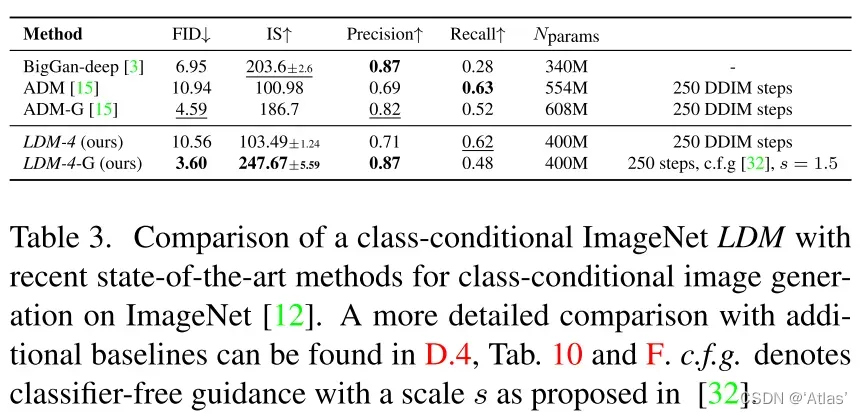
图9表明即使在输入为256*256分辨率,也可生成高分辨率图像;

4.4. Super-Resolution with Latent Diffusion
表4表明LDM在LDDM-SR领域取得更佳效果;

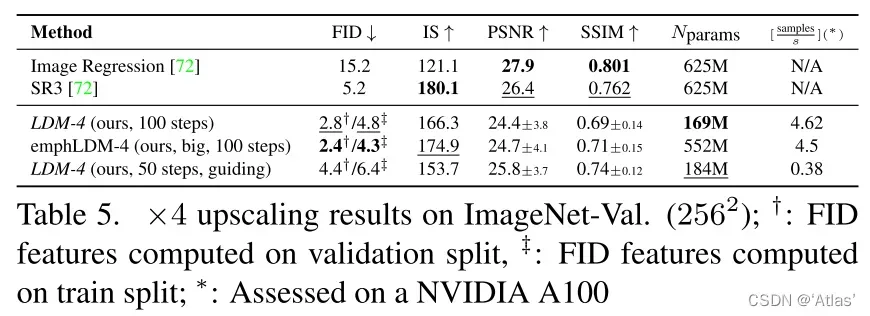
表5表明LDM在FID上超越SR3,但是在IS上SR3更佳;
4.5. Inpainting with Latent Diffusion
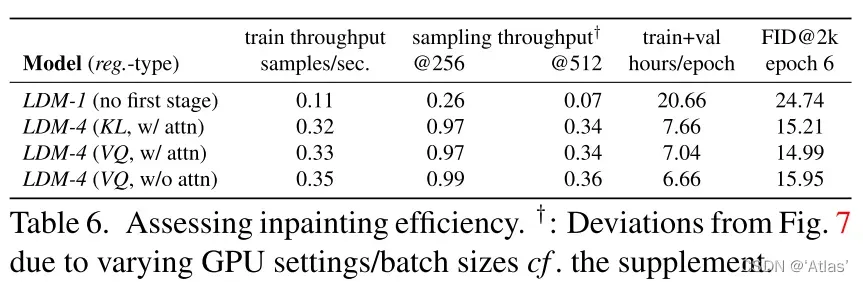
表6展示在分辨率及
训练及抽样的吞吐量;
限制
1、虽然LDM与基于像素空间扩散方法相比,降低计算需求,但仍慢于GAN。
2、LDM在像素空间精度准确难以实现;
结论
作者提出的LDM在不降低质量情况下,大幅提升扩散模型训练及采样效率。在多个有条件图像生成领域,不需要特定任务结构基于cross-attention有条件机制即可达到SOTA或接近SOTA效果。
版权声明:本文为博主作者:‘Atlas’原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_41994006/article/details/130024149