前言
试了很多的sd训练,尤其是sd的lora的训练,问题一大堆,现在写个博客汇总一下
一、一些理论知识
记录一些杂七杂八各种博客看到的训练经验。
1. 对于sd1.5训练出来2G左右大小就是有效模型,WebUI默认FP16。
【AI绘画】模型修剪教程:8G模型顶级精细?全是垃圾!嘲笑他人命运,尊重他人命运 – 哔哩哔哩 (bilibili.com)
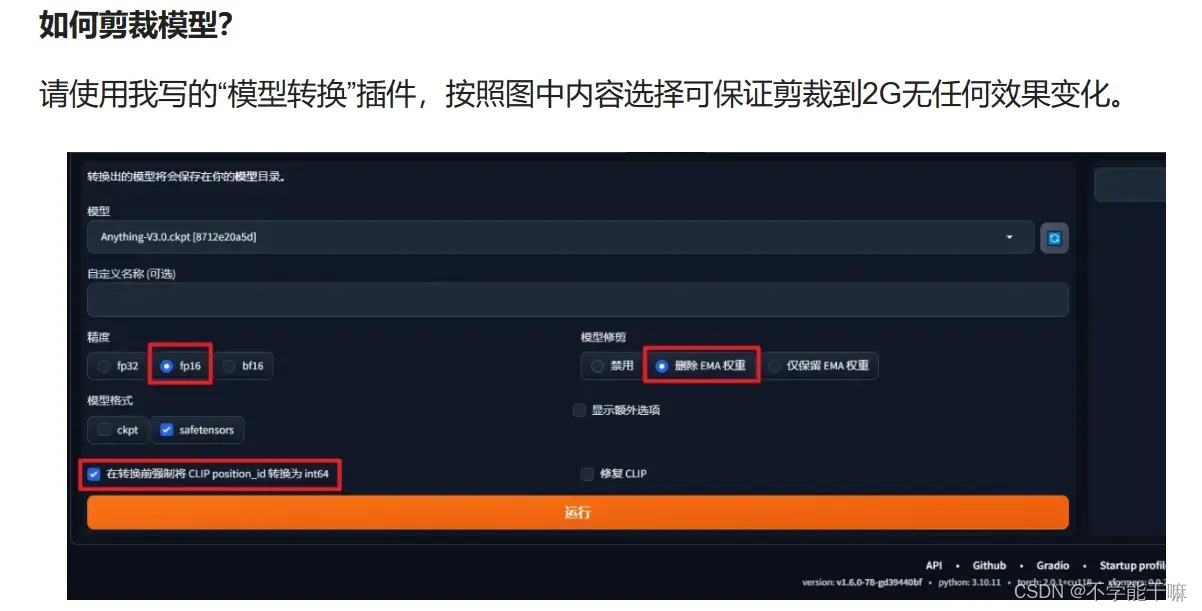
2. 各种模型种类分类讲解
【AI绘画】全部模型种类总结 / 使用方法 / 简易训练指导——魔导绪论 – 哔哩哔哩 (bilibili.com)
二、数据集处理
1. 素材准备
Stable diffusion训练Lora全集 – 知乎 (zhihu.com)
后面参数学习回来,这里强调一点,最重要的就是这里的素材的准备,选择的图像质量越高越好, 数量也不用过多,对于小白来说,30来张就可以了,重点在于质量,这里选好点的。高质量高分辨率的情况下,还可以追求角度的多样性,全局局部,各个方向的视角等。
2. 高清修复
由于我的数据集图像就是模糊不清晰的,且尺寸小于512*512,所以先进行高清修复,它有个缩放功能,修复的同时放大4倍,先修复再裁剪统一尺寸
需要先去SDWebUI的高清修复一遍,修复板块详解放在另外一篇博客里SDwebui的后期处理功能理解/高清修复-CSDN博客
3. 裁剪
数据集图像尺寸要一致,通常512*512、512*768、768*768、1024*1024,这里嫌麻烦直接和下面打tag的一起在丹炉里直接预处理了。
但是由于我的数据集图像不是人物,直接裁剪会把有些重要内容给我裁掉了,这里就可以选裁剪工具,工具好在是可以自己调整裁剪的部分,但是它没办法放大,还可以用美图秀秀/ps等图像编辑软件,功能更强大,看个人需求~BIRME – Bulk Image Resizing Made Easy 2.0 (Online & Free)
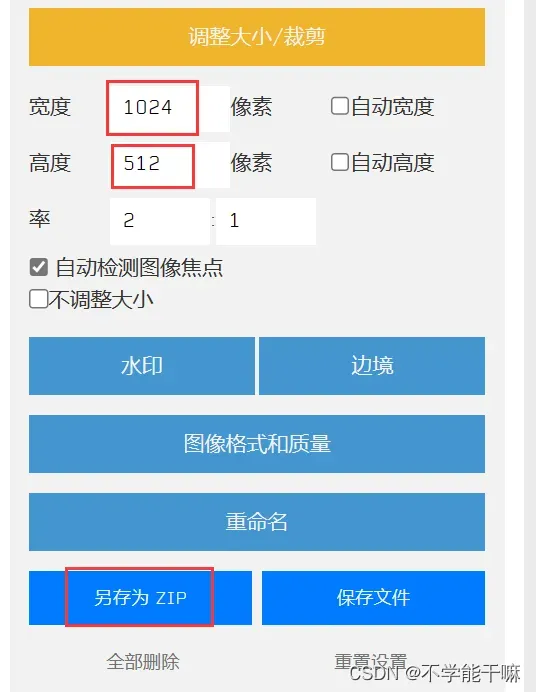
自定义裁剪好了最好是点zip保存,直接保存文件可能会下载不全。网站要是一直显示什么“image-xxx”下载保存不了文件,换一个浏览器试试,我用edge不行后换谷歌可以了。
4. 打tag
stable diffusion LORA模型训练最全最详细教程 – 知乎 (zhihu.com)
4.1 预处理/自动反推tag
先试着用的赛博丹炉的整合包,根据链接教程把训练集进行裁剪和打标签的预处理,别忘了分训练集/测试集(比例7:3/8:2都行)。
模式选择看个人,人脸裁剪/抠图留白都更适合人脸的,但我是物体,所以选择的是聚焦裁剪。
后面分辨率改成768*512,我的数据集有些图像过长用聚焦裁剪512的话给我裁掉了,无需裁剪模式图片的分辨率不会变,保持原始。

训练结束,图像和tag都一起保存在右上角的“训练数据集” ,路径为…\cybertronfurnace1.4\train\image\50_photo_focus
注意如果要重新预训练,调整比较预训练效果的话,之前预训练的结果记得复制保存到其他位置,不然重新预训练会直接覆盖之前的训练结果,重命名也不可以,只能把之前的换一个保存路径。
或者如果是已经有预训练好的数据集,或者想在丹炉里打标签炉里便捷式打标签,可以把自己的预处理文件(图像和对应标签在一个文件夹里)放到这个路径下,丹炉会自动识别出图像和标签,然后方便在丹炉的标签里手动编辑tag。
4.2 手动编辑tag
4.2.1 从这六个方面来思考和编辑tag
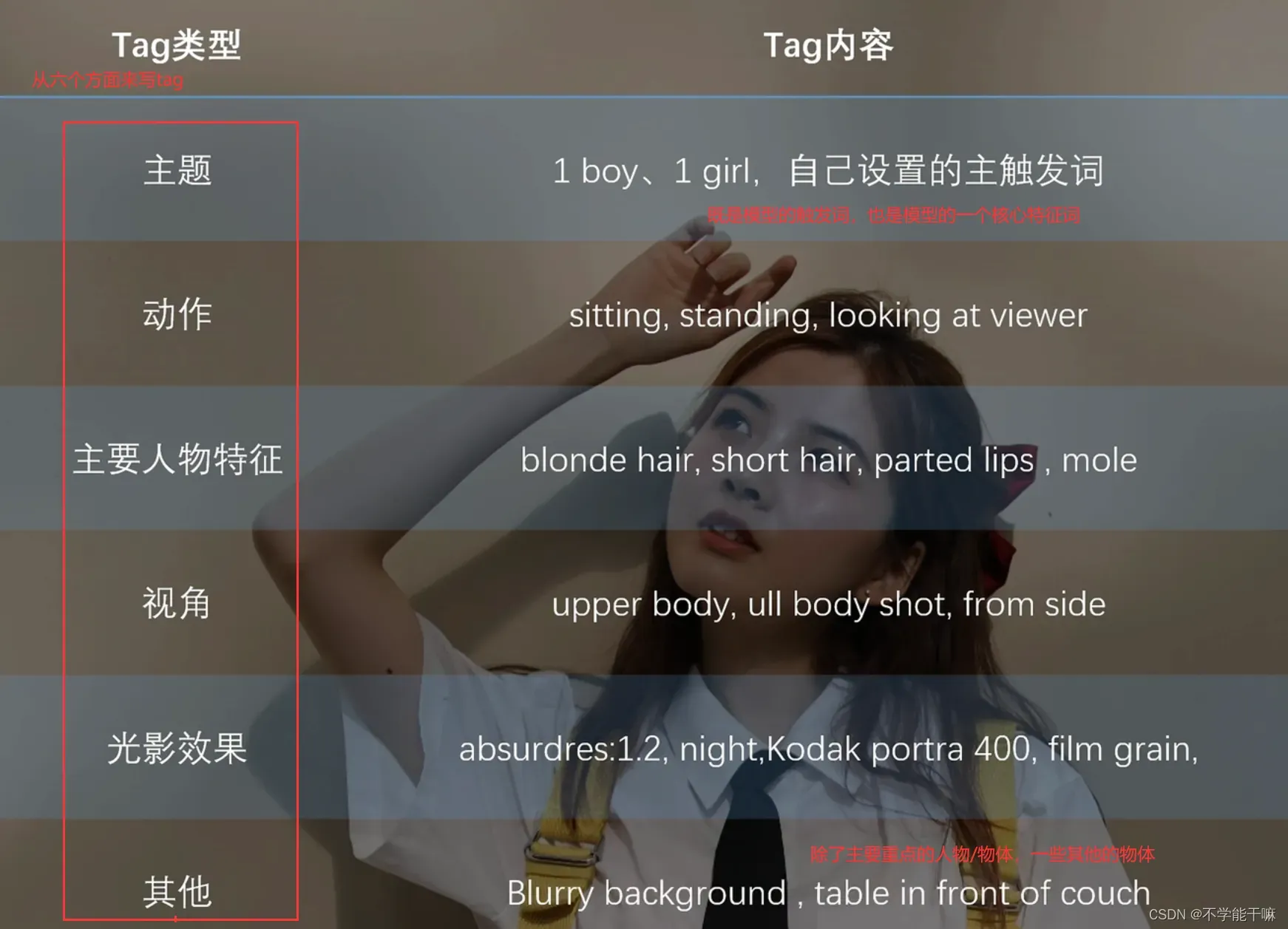
还有一个重要的点,就是你想固化的特征不要去打tag,打的tag不是单纯的对图片进行描述,还要考虑到是否是变量, tag尽量都是变量,也就是说是你期望模型生成的时候可以根据你的文字改变的。举个例子,一个红头发女孩,如果tag里面有red hair,AI会认为这个是可变量,后面模型生成的时候你输入white hair就可以生成白发女孩,但如果tag里面没有red hair,AI会认为红发是这个女孩的本身特征是固定的,即使模型后面输入white hair,生成的女孩也只会是红发不会变白发。
如何从零开始训练一个高质量的LoRA模型 – 哔哩哔哩 (bilibili.com)
参考这篇博客对于tag部分的说明。所以总而言之,tag是变量,是未来想灵活调整的可以被替换的内容,如果不想被替换的就不要写。
4.2.2 丹炉里的实际编辑操作
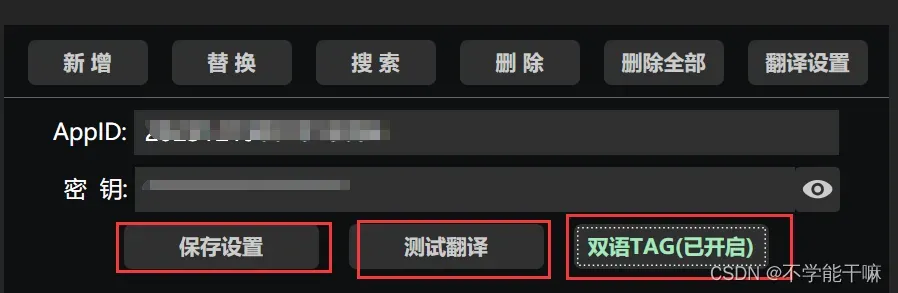
首先因为是英文的,按照上面的链接教程百度翻译开放平台 (baidu.com)导入一个翻译api,具体操作步骤看链接,很简单,一定量的翻译是免费的,暂不确定收费界限,后面写,然后把个人的密钥信息填进来,保存设置/测试翻译按钮都点一遍,然后开启双语tag,英文tag就转中文了。
手动编辑tag,主要用到红框标注的: 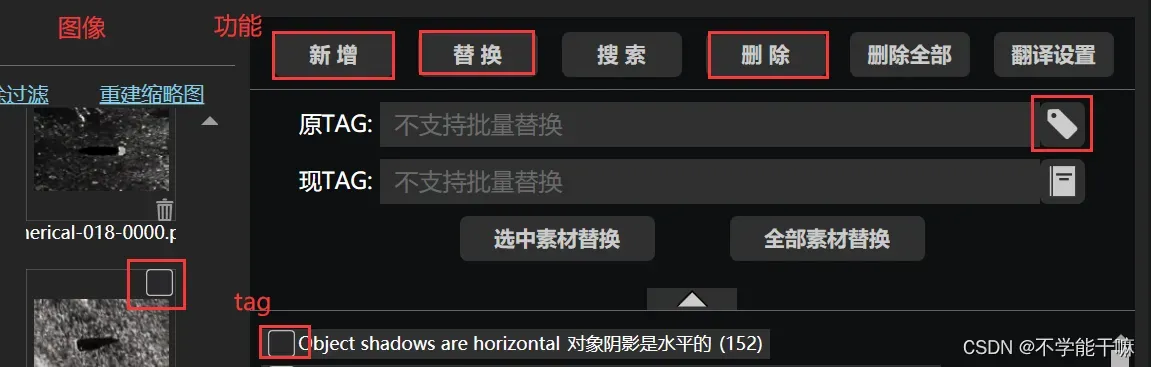
手动编辑的思路就是先整体新增没有的tag,删除不要的tag;在一张一张图的检查调整细节tag。
分为图像区域、功能区域和tag区域三个part。
新增:就是新增没有的tag,可以选择选中素材(图像那里选中图像)或者全部素材新增,新增这个还可以选择新增位置是头部/尾部,tag位置也蛮重要的;
替换:替换就是当点击一张张图片检查的时候,对于这张图片的部分tag替换,tag比较繁琐可以先选中要替换的tag然后在原tag那里点右边的便利贴按钮就可以自动添加原tag,小技巧;
删除:选中要删除的tag,点击删除就可以一次性删除。注意不要点删除全部,这里的删除全部是所有tag都会被删。
三、训练(炼丹)
1. 训练参数分析
必看视频!!![全网最细lora模型训练教程]这时长?你没看错。还教不会的话,我只能说,师弟/妹,仙缘已了,你下山去吧!_哔哩哔哩_bilibili
1.1 步数相关 repeat / epoch / batch_size

【1】epoch多轮次比单轮次要好,通过设置可以每轮保存一组模型,多轮次说明有多组模型,得到好概率的可能是比单轮次就一个模型的概率是要高的,epoch一般设置5~10;
【2】batch_size要是高,一是可能显存带不动,二是值越高训练越快 越可能学得囫囵吞枣收敛得慢。
 BS从1到2,Ir就要*2
BS从1到2,Ir就要*2
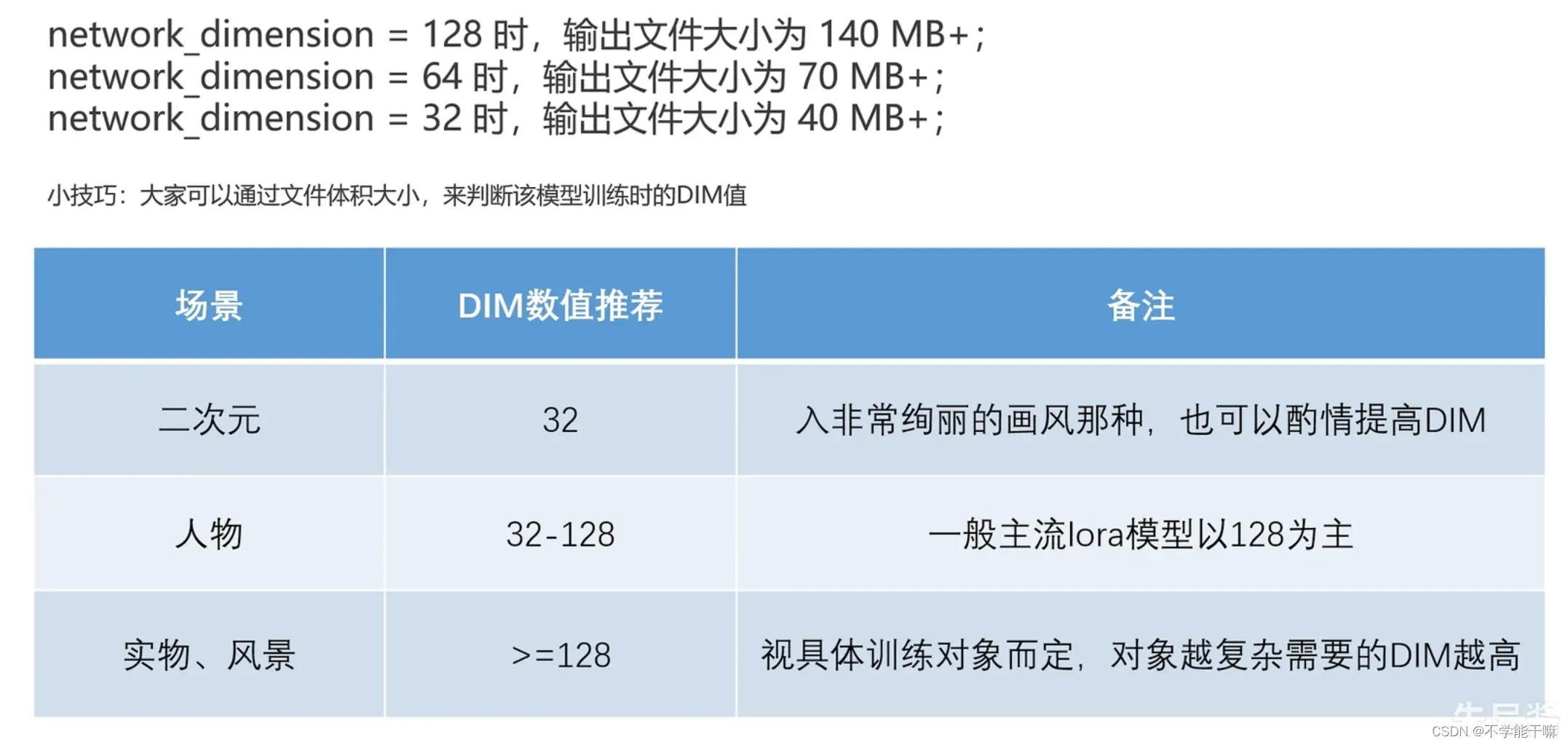
1.2 速率/质量相关 Ir学习率 / Dim网络维度 / Optimizer优化器

学习率Ir,控制了每次参数更新的幅度,过低参数更新幅度小 训练收敛就慢 陷入局部最优解 训练时间增加,过低也会导致训练初期无法有效学习到特征;过高,参数更新幅度大 错过全局最优解附近的局部最优解 找不到稳定的收敛点,常用cos的学习率衰减策略,初始使用较大的学习率快读接近全局最优解,在随着训练的进行逐渐减小学习率,使得逐渐细化搜索空间,找到全局附近的局部最优解,提高收敛的稳定性。
前面提到的“bs提高,Ir也要提高”是因为bs较大时会导致参数更新的方差减小从而使得梯度更新幅度也减小,这时就需要Ir也相应地增大。我这里还在思考bs、Ir都提高了的话,训练速度是不是也会大幅度提高?chat告诉我不一定,因为bs大占用的内存和计算量也增加,Ir大模型容易不稳定不收敛,理论上肯定是会增加训练速度,但实际上还是要根据你的显卡来设置bs值,训练速度变向是看钞能力,跑起来才是王道,先优先考虑生成效果再训练速度吧~
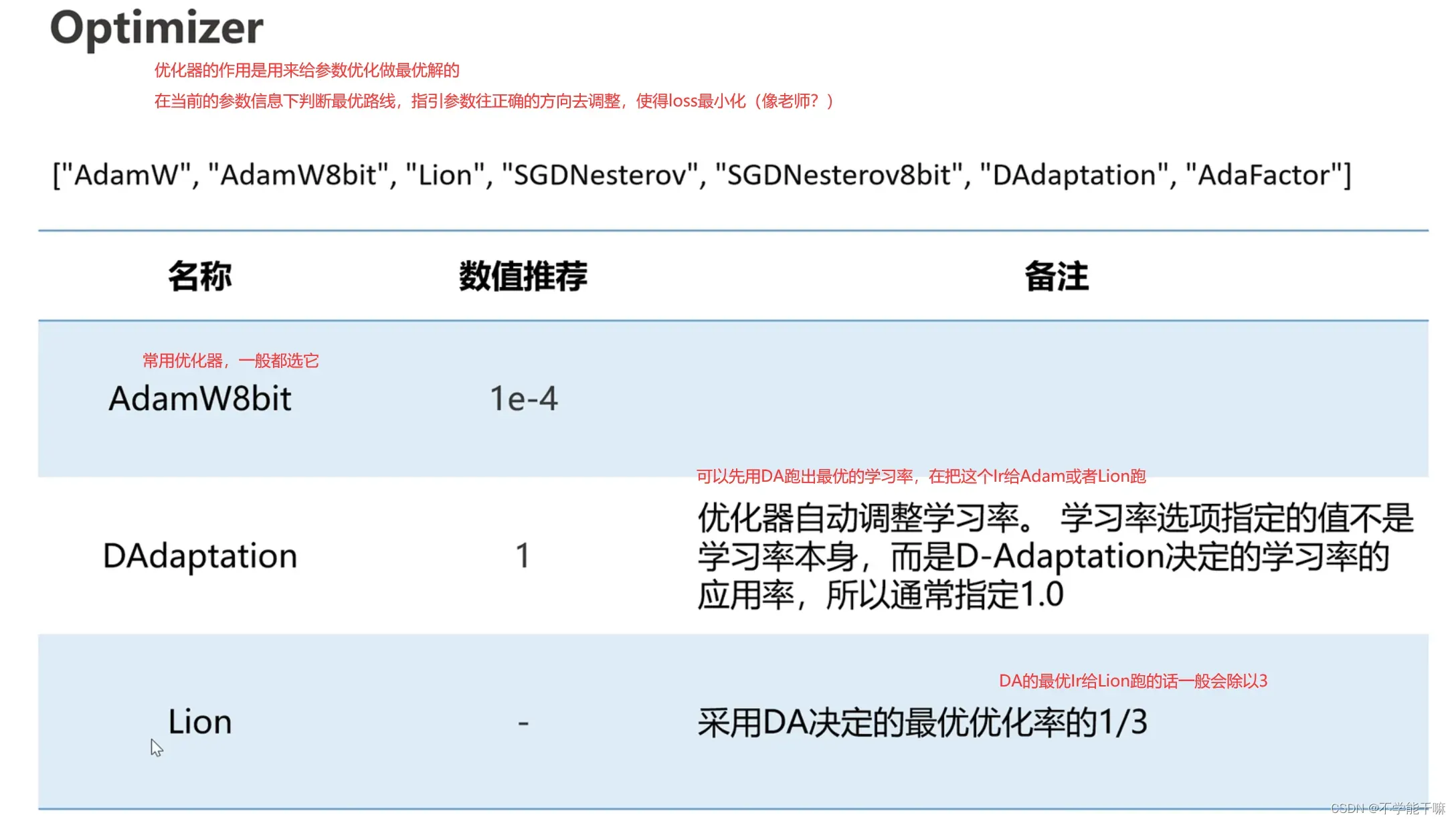
优化器(Optimizer) – 知乎 (zhihu.com)
Lion比AdamW8bit的优点是更快,总训练步数在3k-1w内都可以考虑选它。
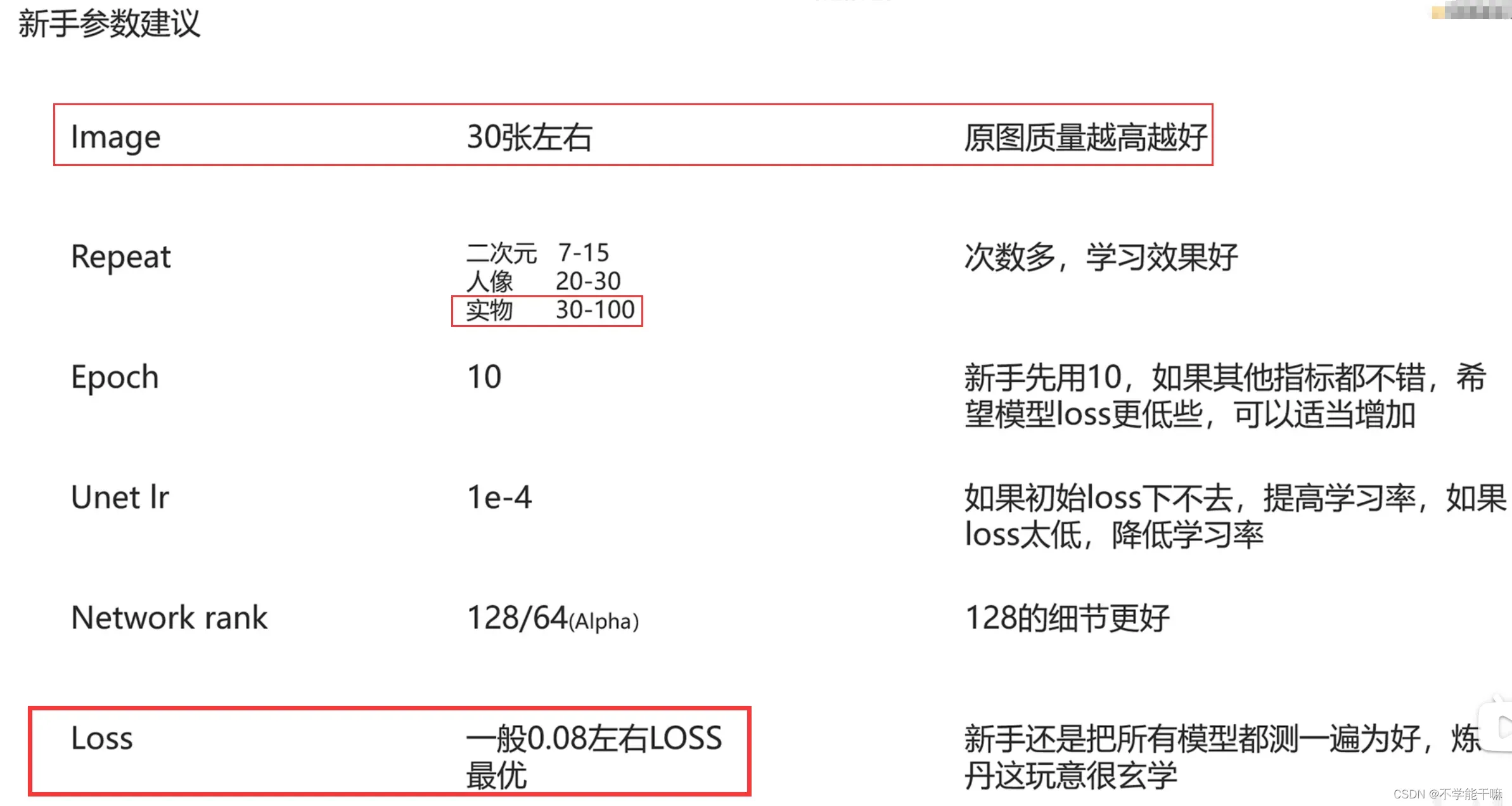
图像这里居然不要很多,作者这里是考虑到耗费时间等因素,我觉得有道理,如果我训练效果不好,我将尝试将重新创建我的数据集,只选出质量最高的30来张图像来做训练。
loss值的最优区间0.07-0.09,但loss值只是一个参考,但更多的还是要通过XYZ测试来看模型的好坏,原图VS根据原图tag测试模型生成的图片。
2. 实际操作
2.1 选择底模
先提前选择下载好要训练的底模,底模的选择也很关键,后面有报错就是因为底模有些东西不对,搞了两天,千算万算没想到是底模的问题,放模型的位置也有点玄学讲究,具体看你选择一下哪种工具来训练。
stable diffusion 常用大模型解释和推荐(持续更新ing) – 知乎 (zhihu.com)
【LoRA训练用什么底模】最新LoRA训练进阶教程6_哔哩哔哩_bilibili
 选择的底模要画风一致的,分为二次元动漫类/2.5次元游戏类/三次元现实类,实际上不同画风之间的转换是不容易的,先确定底模和你的需求的画风一致。 我要训练的是三次元的物体,目前在尝试用v1.5-pruned模型训练,有推荐说炼亚洲人用ChilloutMix。
选择的底模要画风一致的,分为二次元动漫类/2.5次元游戏类/三次元现实类,实际上不同画风之间的转换是不容易的,先确定底模和你的需求的画风一致。 我要训练的是三次元的物体,目前在尝试用v1.5-pruned模型训练,有推荐说炼亚洲人用ChilloutMix。
另外,大家在下载模型的时候,会看到pruned、emaonly(ema)之类的后缀,pruned是完整版,emaonly是剪枝版。剪枝版比完整版通常小很多,方便下载。如果只是使用的话,两者差别不大,如果是想要自己练模型的话,需要下载完整版。
c站网址(要科学上网)
8款 Stable Diffusion「逼真写实大模型」推荐 – 知乎 (zhihu.com)
2.2 脚本训练(青龙)
【LoRa专题】【StableDiffusion妈妈级教学01】1小时超详细LoRa训练流程全解,一步到胃_哔哩哔哩_bilibili
install-cn-qinglong.ps1用powershell运行创建环境,创建完成会显示“创建完毕”的字眼。
自己新建models文件夹装自己的底模,新建train装数据集,数据集是“…\train\face\30_face\图像和对应文本”这样的格式,这里的“30_”就是repeat数。
train.ps1用记事本或notepad++来修改训练参数;修改并保存完了再右键点它用powershell运行。
不要打开任何魔法和梯子!!
2.3 赛博丹炉(后改名道玄)
我用的还是单纯的训练lora就是丹炉,道玄多了WebUI的绘图等功能,我自己有就不用了,版本选择看个人需求。这里训练两种方法,分本地电脑和云端的青椒云。
赛博丹炉链接(夸克网盘):https://pan.quark.cn/s/1c3a2a36510d
2.3.1 散修炼丹(本地)
自己电脑显卡可以的,就直接本地用丹炉,有如下一些说明和要求:

赛博丹炉真的很方便,能时刻看到样图,最后也有tensorboard观察,如果自己电脑能带动是最好的,解压好直接先用默认的图片/参数/图像底模来训练一遍,如果没问题了再训练自己的。看上图注意几点,跑起来具体细节还是看终端而不是丹炉;默认的模型chilloutmix下载地址(链接要科学上网才能打开)ChilloutMix – Chilloutmix-Ni-pruned-fp32-fix | Stable Diffusion Checkpoint | Civitai;底模路径放F:\TyrellAI\daoxuan\models\sd。
再次强调,如果训练正常没有报错,不要打开任何梯子!!!!不知道是不是防火墙的问题,但我是关了之后训练没有报错的,看个人。Win10如何关闭防火墙?Win10关闭防火墙的方法 – 知乎 (zhihu.com)
具体的丹炉使用教程可以参考下面云端的视频链接,后半段就是对于丹炉的使用说明。
总结一些步骤就是:首页选择底模-召唤词;上传素材确认好训练集和tag;丹炉的查看进度-参数调优;点击开始训练;查看终端代码是否成功运行,丹炉开始训练,显示训练步数-时间-loss-样图。
说一个题外话,丹炉下面是“停止训练”和“重新训练”,是没有直接继续训练的功能的(参数调优里可以接着),所以点开始训练要慎重,想停止训练也要慎重,不然很浪费时间,开始训练加载要蛮费时的。比较好的是,训练结果不会存在覆盖之前的情况,会接着原来的路径继续保存。
附一下丹炉训练成功的截图,训练过程中右下角还会有样图的输出(首页开启样图展示)。
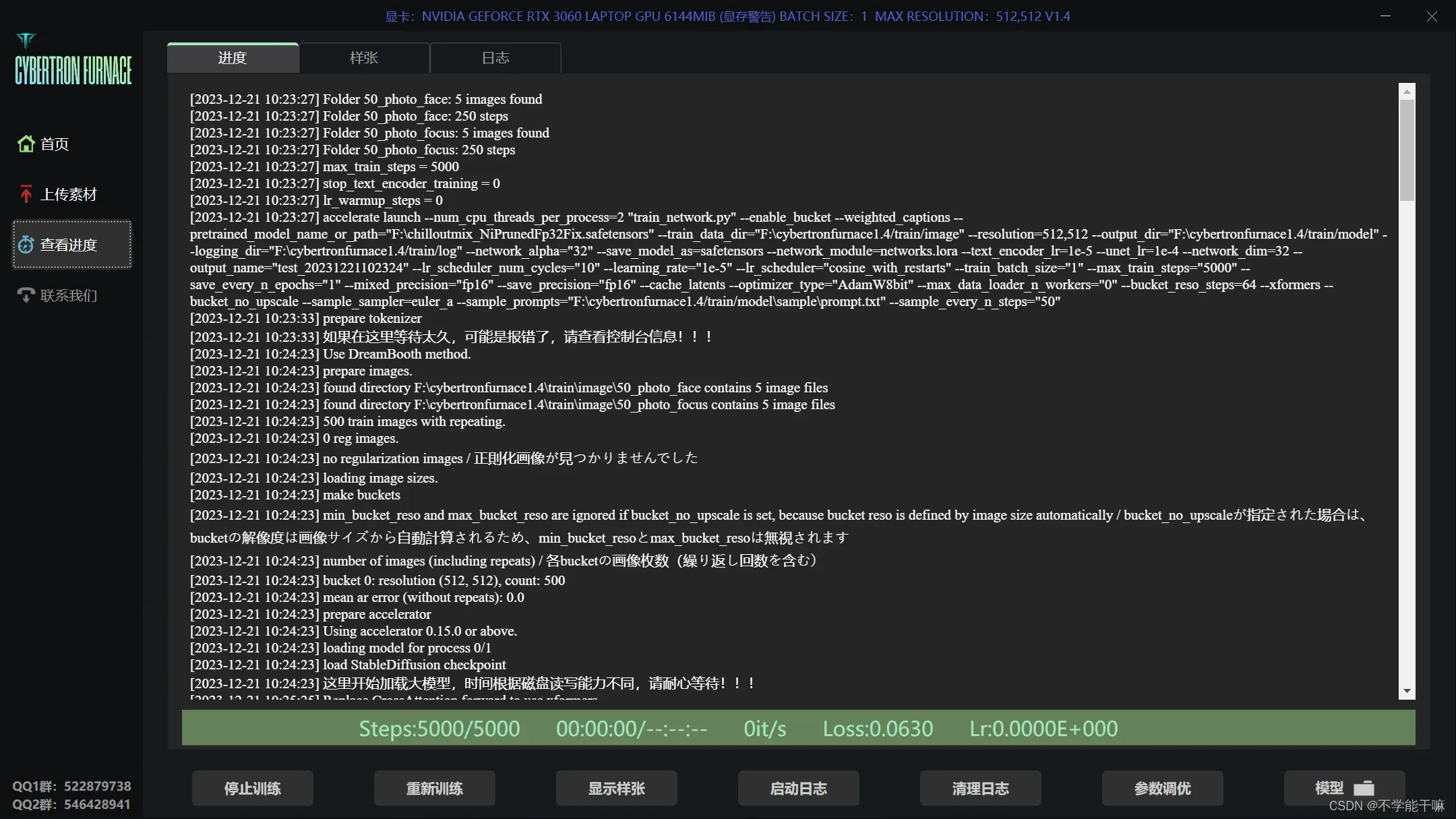
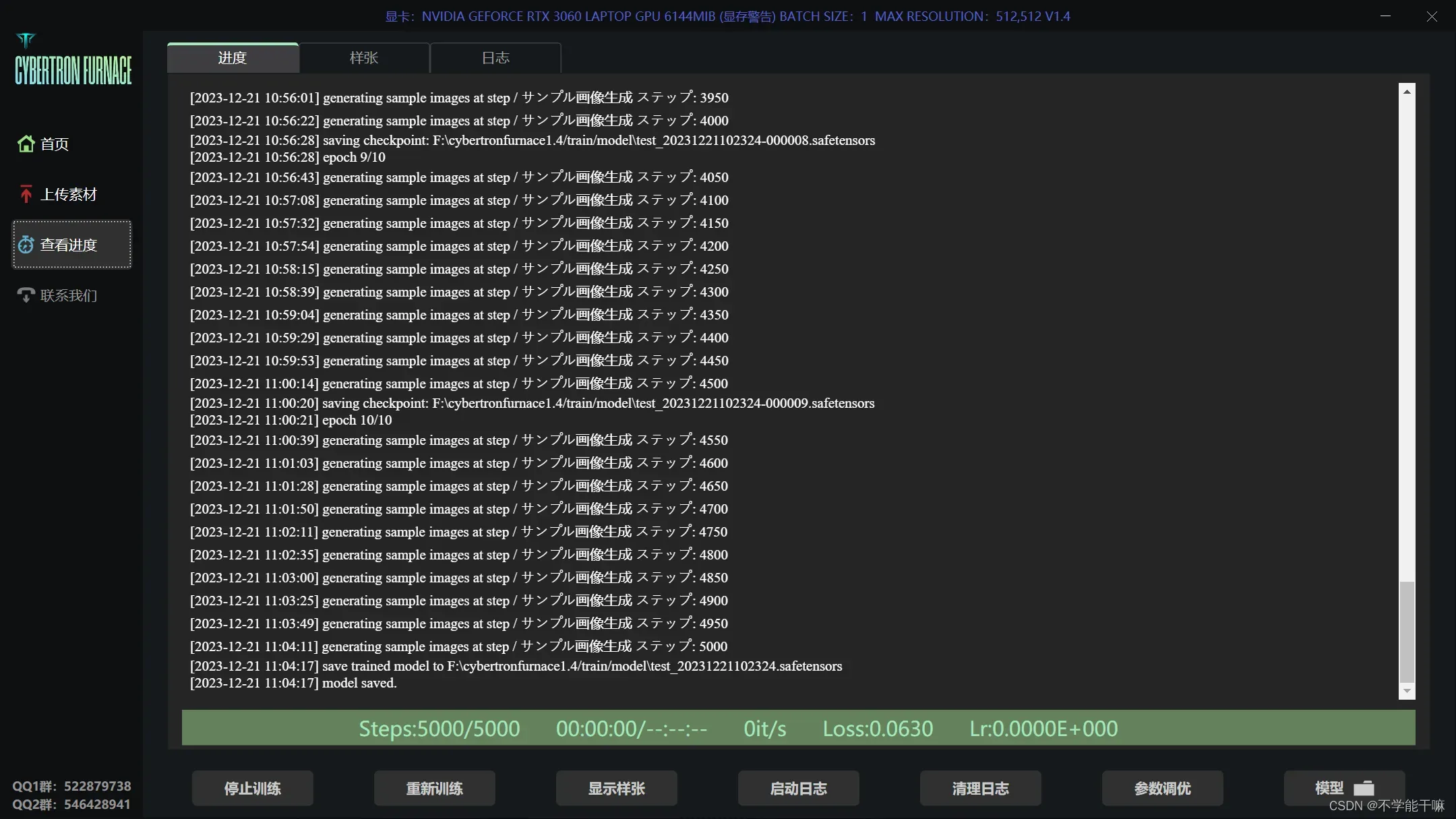
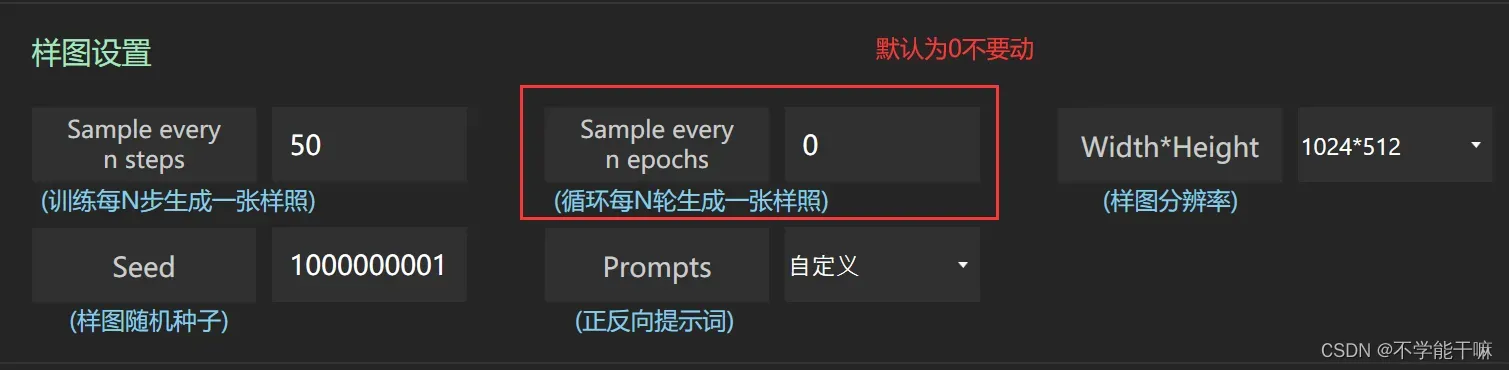
训练出来的模型结果在F:\cybertronfurnace1.4\train\model 路径,也有txt文档记录了当时的训练参数,训练样图在.\sample路径下查看,或者丹炉训练页面的样张选项也能看,但是这里注意样图设置-训练每N轮生成样图设置为0,不然即使设置了训练每50步也不出图。
如果本身的数据集不够,训练过程中好的样图是可以拿来扩增自己原始数据集的。
loss在丹炉训练页面选项里面看,Tensorboard。
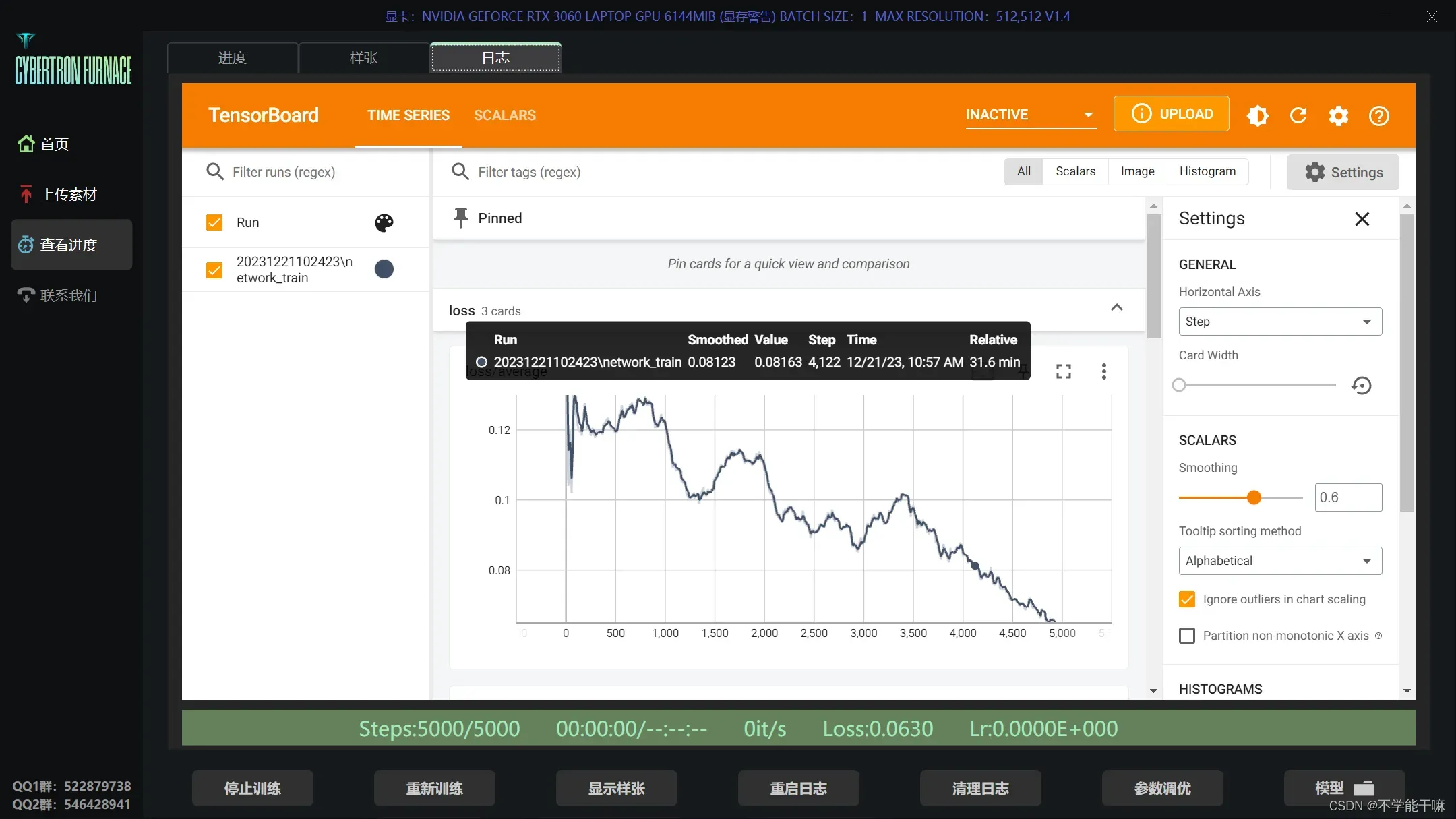
对于自己的数据集而言,整理了一下训练过程中出现的报错,放到另一条博客了~
2.3.2 宗门炼丹(青椒云云桌面)
自己电脑带不动,想用花点玛尼给炼(果然,炼丹师都很有钱!修真小说诚不欺我)
【一键炼LORA教程】云端部署赛博丹炉1.4版发布!_哔哩哔哩_bilibili
这个云端一直连不上说人多,不好用。后面早点来连上了,体验下来,这个远程桌面使用起来比较卡,复制个底模过去等蛮久,体验感一般,实在不行的话才用吧。(但是刚开始不知道是不是实名认证的原因,没花钱免费用了一个小时?所以可以先免费体验再选择是否充值还是很人性化的)
2.4 秋叶(autodl云端)
针对有点丹方在身上的人,用过,感觉有点子繁琐,也可以用,就是注意花钱如流水,特别是还要扩容数据盘训练大模型的同志,尽量不要多花钱扩容,但如果真的扩容了尽量一次性一天就搞完,不然一是大模型本身上传到云盘就很费时,费时就花钱,二是扩容了即使你关闭了数据盘如果忘了缩容回去还是会一直每小时每小时地给你扣钱,我以前不知道这里关机了也会扣,等我知道的时候莫名其妙50.60没了。
附一些链接吧,整体来说使用起来不算太难,但确实比丹炉麻烦点,毕竟在云端。以下这几个内容都是差不多的,分视频版和文字版,尽量完整不漏步骤,不是很长。这里主看第二个视频,视频简介附了云端部署要用的端口转发器,这个是必须要提前下载的,notepad++是类似记事本的东西,但是比记事本方便改txt里的内容,也可以下载一个,用它来改txt的内容,记得设置自动换行。
【AI绘画】LoRA训练界面 AutoDL云端使用教程 – 哔哩哔哩 (bilibili.com)
lora云端布置,3分钟部署教程(全文最详细,最新版本5月31日新版本)_哔哩哔哩_bilibili
stable diffusion LORA模型训练最全最详细教程 – 知乎 (zhihu.com)
SDXL_LORA模型训练详细教程(含云端教程) – 知乎 (zhihu.com)
下面就是云端部署的一些过程截图,仅做参考
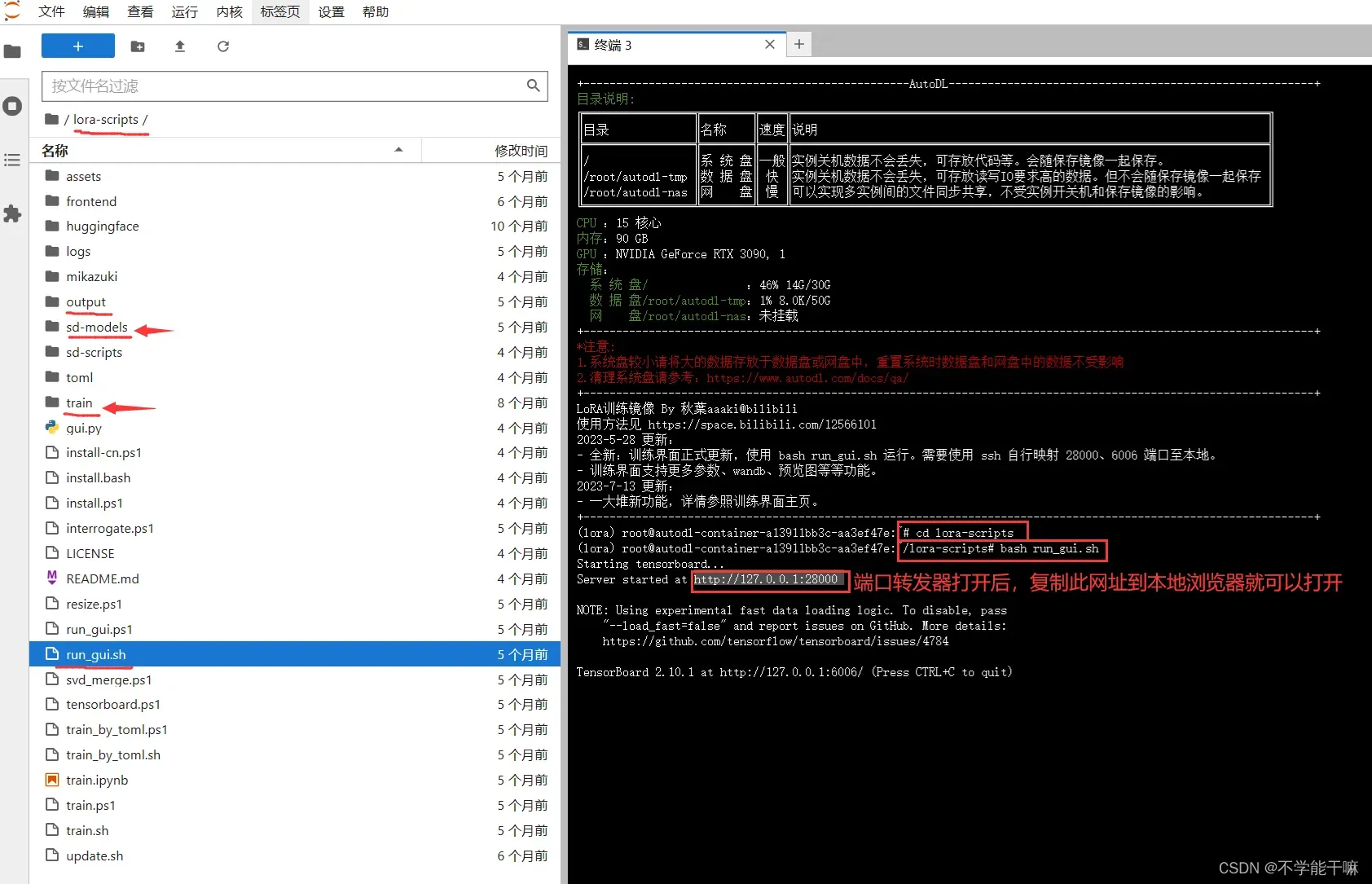
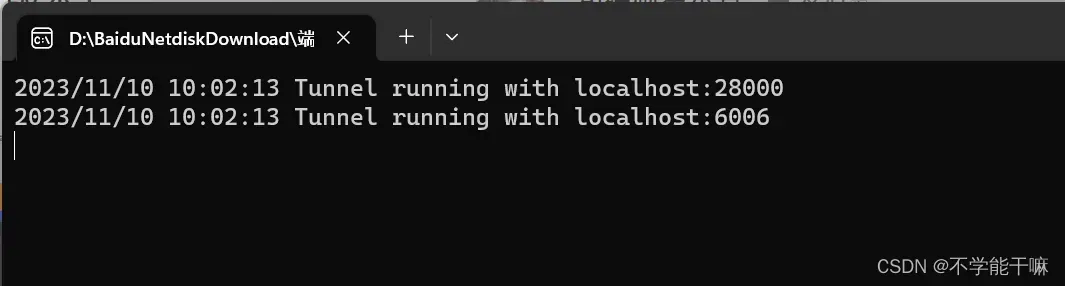
复制 到下载的端口转发器的第一个文件config里,修改登录指令和密码,并保存,保存后双击端口转发器,然后出现以下截图表示成功。
到下载的端口转发器的第一个文件config里,修改登录指令和密码,并保存,保存后双击端口转发器,然后出现以下截图表示成功。
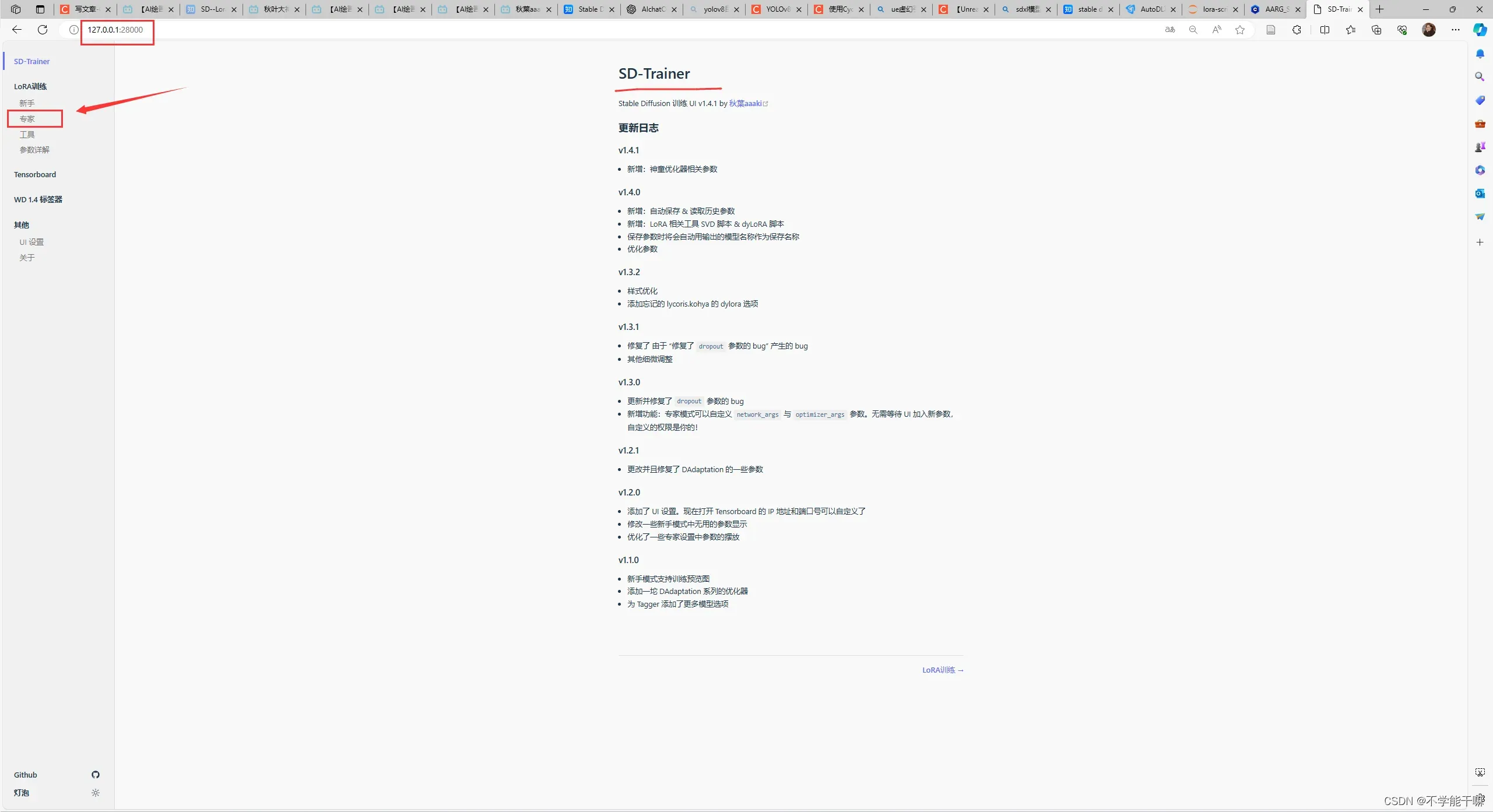
 复制云端部署bash后出现的网址到本地浏览器就可以打开炼丹炉了,如图表示打开,然后点专家模式开始修改训练参数,具体参数修改参考附的知乎链接。
复制云端部署bash后出现的网址到本地浏览器就可以打开炼丹炉了,如图表示打开,然后点专家模式开始修改训练参数,具体参数修改参考附的知乎链接。
 SDXL_LORA模型训练详细教程(含云端教程) – 知乎 (zhihu.com)
SDXL_LORA模型训练详细教程(含云端教程) – 知乎 (zhihu.com)
2.5 训练重要小技巧
2.5.1 用DAdaptation找到最优学习率
首先声明,DA找最优Ir不需要你跑完,就跑一段时间取到最优学习率就行,不要浪费太多时间。并且即使是同样的训练参数和数据集,得到的最优学习率也不会是固定的一组数据,可以考虑多次找最优然后取其平均值,或者根据训练样图和loss值选择其中效果最好的Ir值。
前面第三章1.2节降到优化器和学习率,说了可以先通过DAdaptation来找到最优的学习率,而不是只会用默认的1e-4。修改如下图的6个训练参数:
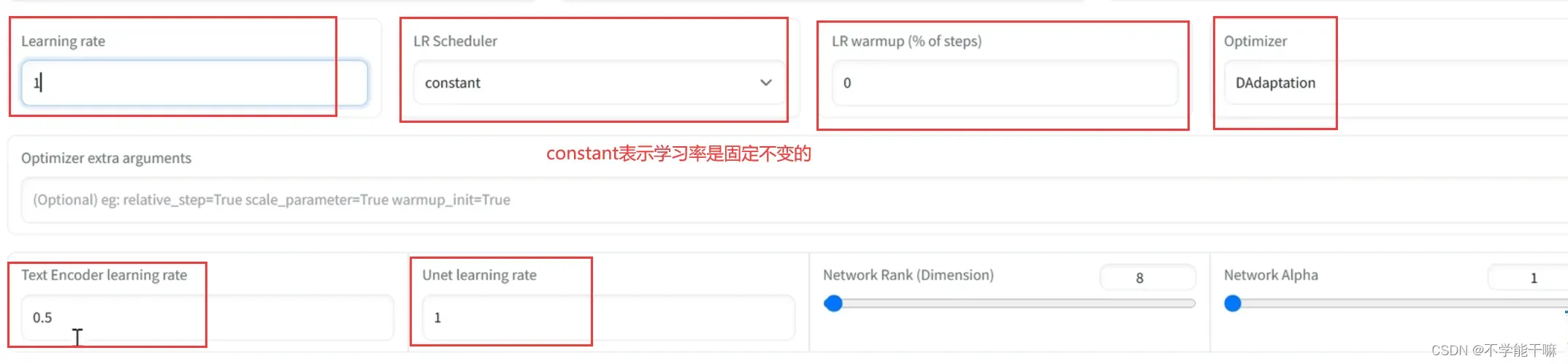
然后开始训练,在TensorBoard/TIME SERIES或SCALARS往下找到Ir/d*Ir,此时达到稳定不变的值即恒定不变的d*Ir的横线所显示的value就是最优的学习率。
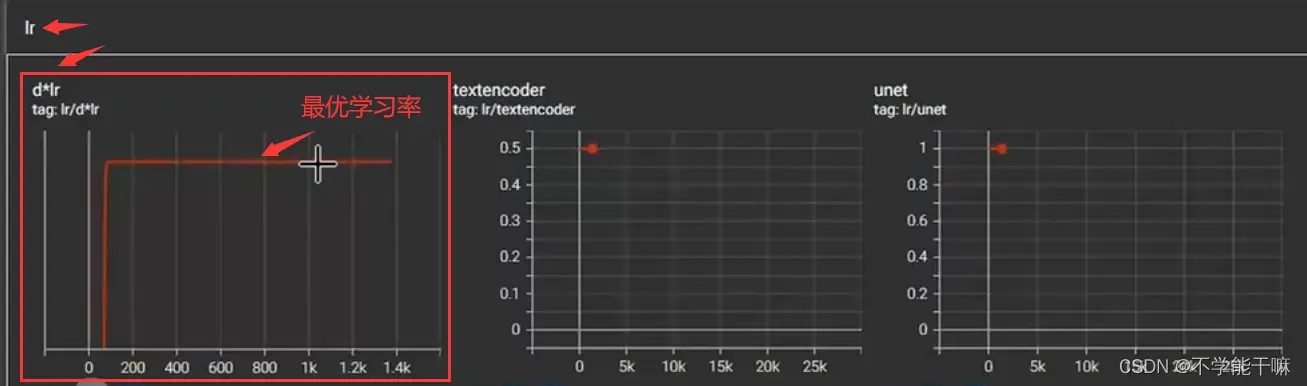
后面试了一下我的数据集大一点的还是要跑好一会儿才会出现最优,五六分钟吧,有时候日志可能显示不及时,多重启或者多等一会儿,而且一定要先记录下最优学习率再停止训练!如下图,左TIME SERIES,右SCALARS,数据都是一样的,只是图标颜色可能不一致,然后右边学习率精确度更高比如到6.5807e-5,但是正常取左边的值比如6.58e-5就够了。
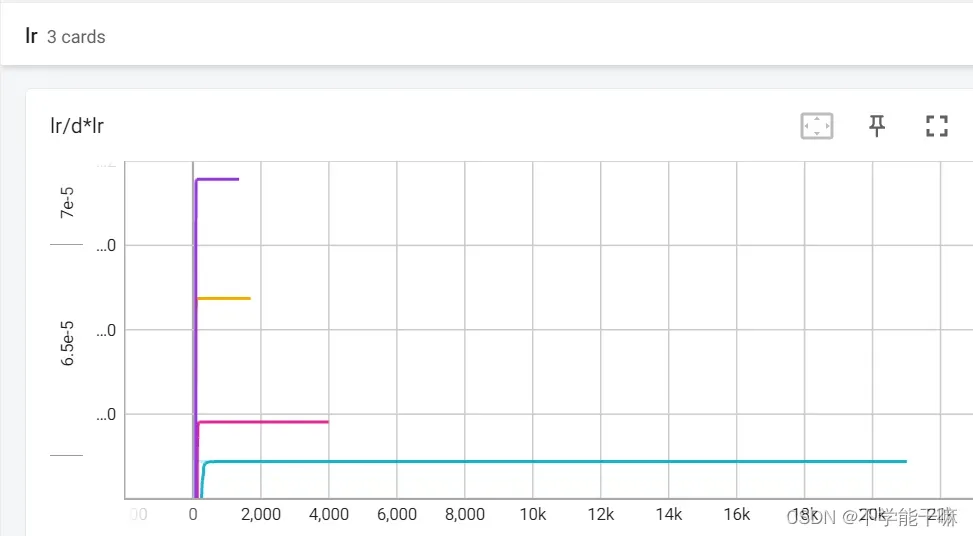
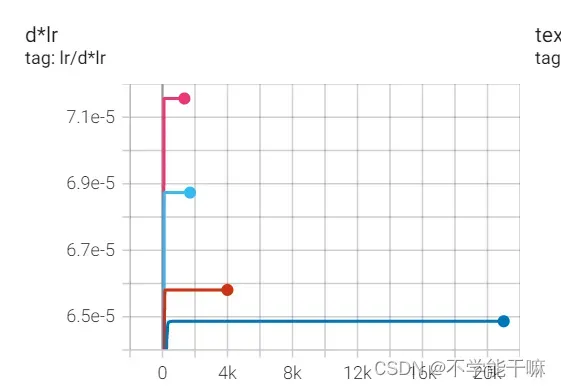
训练过程中要是日志左边没有出现训练时刻的代表的图标,如图 ,可以点重启日志,重启日志不会影响之前的训练结果或者训练过程(清理日志没点过,不要轻易尝试)。
,可以点重启日志,重启日志不会影响之前的训练结果或者训练过程(清理日志没点过,不要轻易尝试)。
确定了最优Ir之后就然后修改训练参数,如下图:
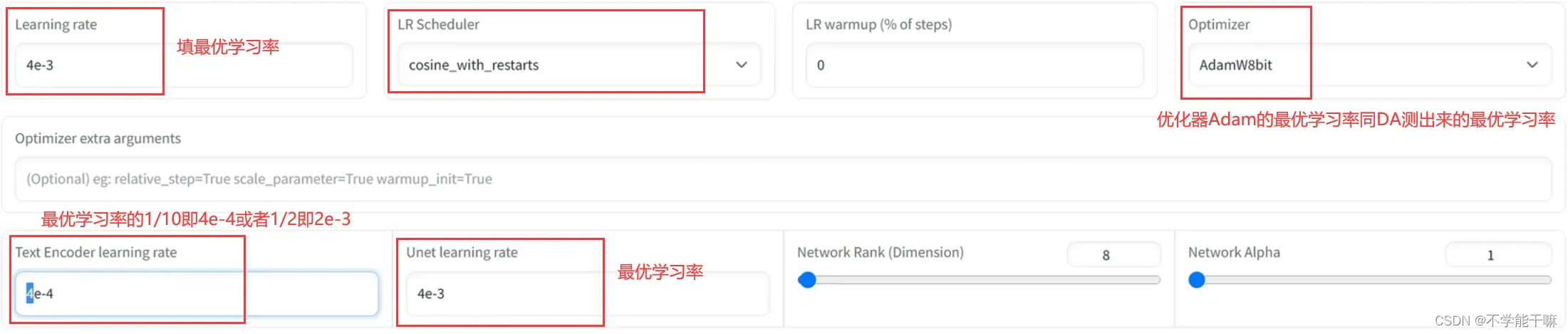
文本学习率是最优学习率的1/10、1/8、1/4、1/2都可以,自己摸索。
如果优化器选择的是“LION”,那么最优学习率就调整为DA的1/3,即4e-3变1.3e-4,同理修改。
2.5.2 参考好的模型的训练参数
要是没有安装可附加网络(lora)插件可以手动到下面地址下载,然后把文件放到…\sd-webui-aki-v4.4\extensions路径下,重启SDWebUI应该就有了。
Ranting8323 / Sd Webui Additional Networks · GitCode
当生成效果一般的时候,可以去c站(科学上网)找到和自己数据集或者说内容相似的lora模型,然后下载放到附加网络的lora里,…\sd-webui-aki-v4.4\extensions\sd-webui-additional-networks\models\lora路径下,然后打开SDWebUI的可选附件网络(lora插件)Additional Networks,选择要参考的模型,就可以在页面看到它对应训练的信息,包括tag的使用量、具体的训练参数,通过参考好的模型来调整自己的模型参数。
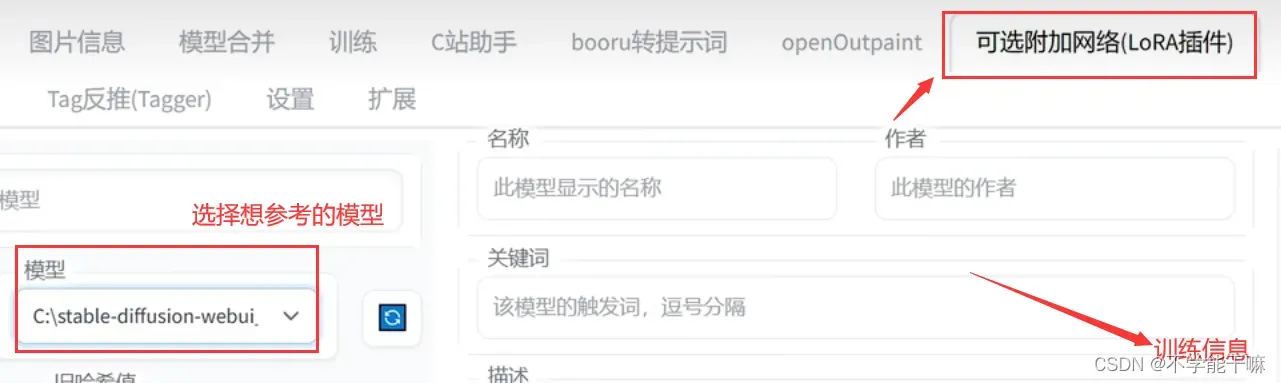
后面这个模块还可以用于XYZ测试,具体详见3.2.2节。
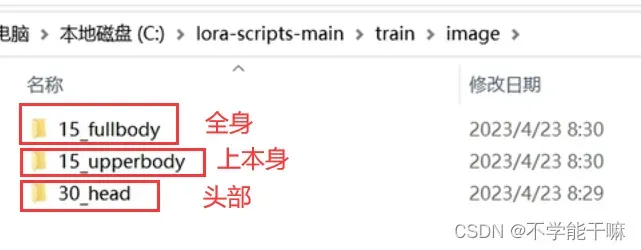
2.5.3 细分类数据集/概念集
想让AI更有意识地去学习某些更精细的部分,就把数据集分类,然后直接正常训练即可。
3.测试模型效果
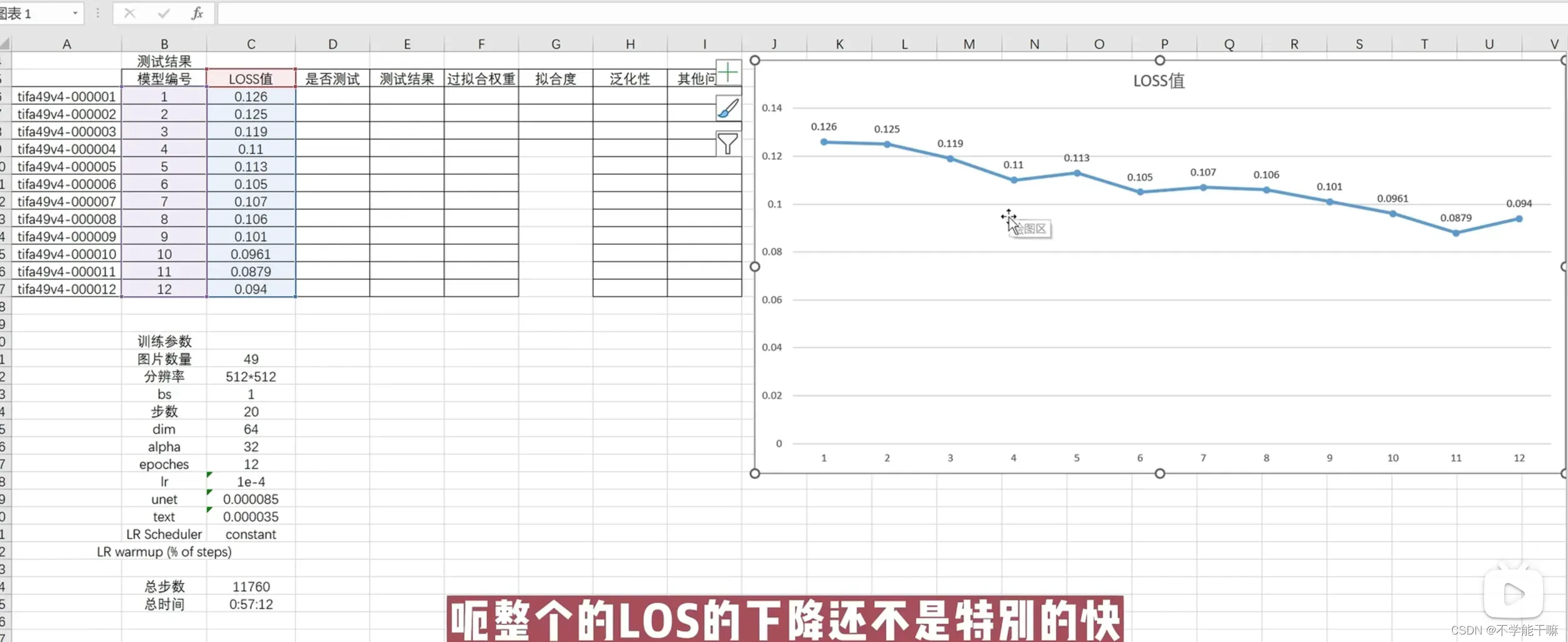
3.1 做个表格清晰观察和比较
loss训练在终端看到数据或者Tensorboard
3.2 在SDWebUI加载模型做XYZ测试
3.2.1 SDWebUI加载lora
模型结果在F:\cybertronfurnace1.4\train\model里面,有每个epoch下保存的模型,然后没有标号的是最后epoch的模型数据。把图中最后的模型名称改为-000010与前面的模型的序号对齐。
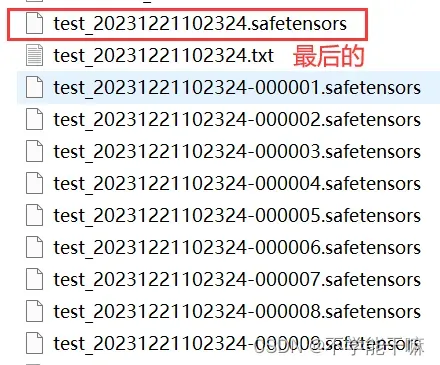
然后把所有模型保存到SDWebUI的文件夹的 …\sd-webui-aki-v4.4\models\Lora文件夹下,打开SDWebUI。要是WebUI打开、刷新后,还是看不到lora部分的自己训练的模型,可以参考我另外一篇博客的处理方法SD整合包,Lora模型下载了放models/Lora文件夹里,但是webui页面加载不出来(已解决)-CSDN博客
3.2.2 做XYZ测试
有两种方法,一是用直接样本,二是结合使用附加网络(lora插件)的。
1)直接用样本
加载出lora模型后,点击其中一个,然后修改成如下图所示 。这里的提示词首先是原图像的tag,如果还想同时看泛化性可以在lora后加上要泛化改变的词。

文生图页面往下,找到脚本选项,如下图修改,修改好之后点上面的“生成” 按钮。
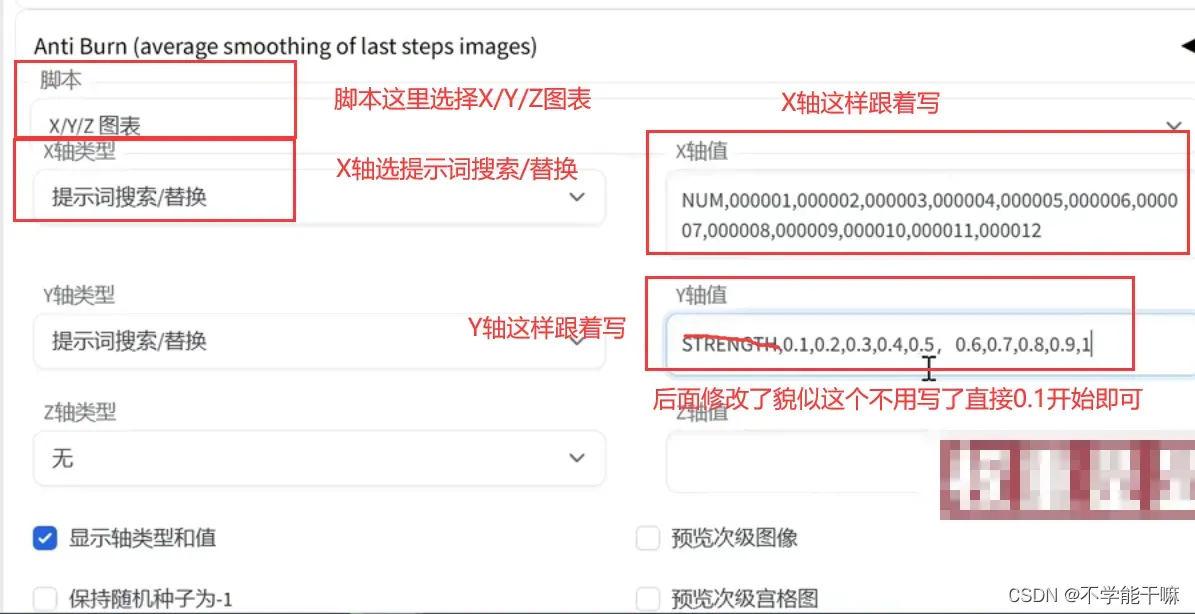
会生成一个xyz轴来进行生成图的比较,x轴是模型编号,y轴是权重,从相似性、泛化性来确定生成效果最好的模型和它最适合的权重。
但是我这里X轴没有提示词搜索/替换的选项,就用的方法2插件的。
2)结合附加网络插件
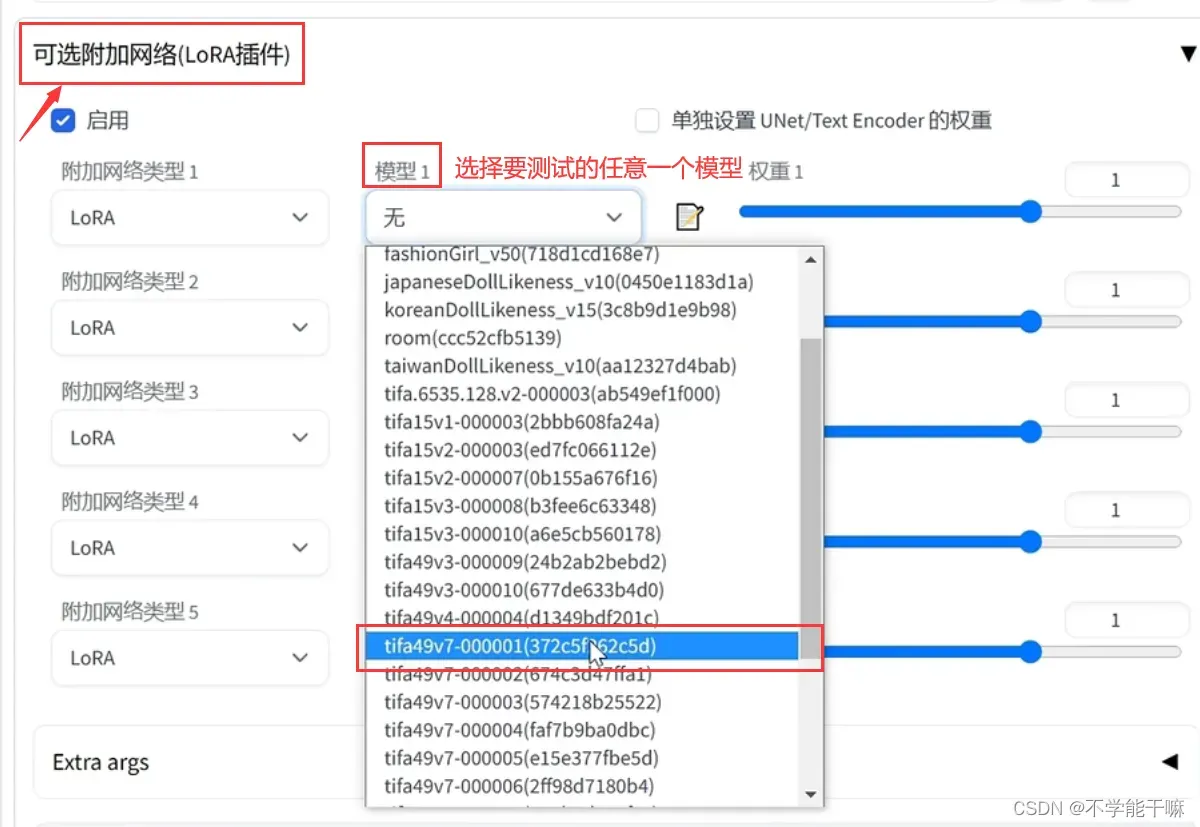
这个插件安装教程看2.5.2节,这里是首先将要测试的模型放到/SD/extensions/sd-webui-additional-networks/models/lora路径下(一定要修改最后的模型名称与前面的序号对齐),模型没出来点一下“刷新模型列表”,再直接在文生图界面下面找到插件板块,选择其中任意一个模型,选一个就行,脚本那里会批量选择。
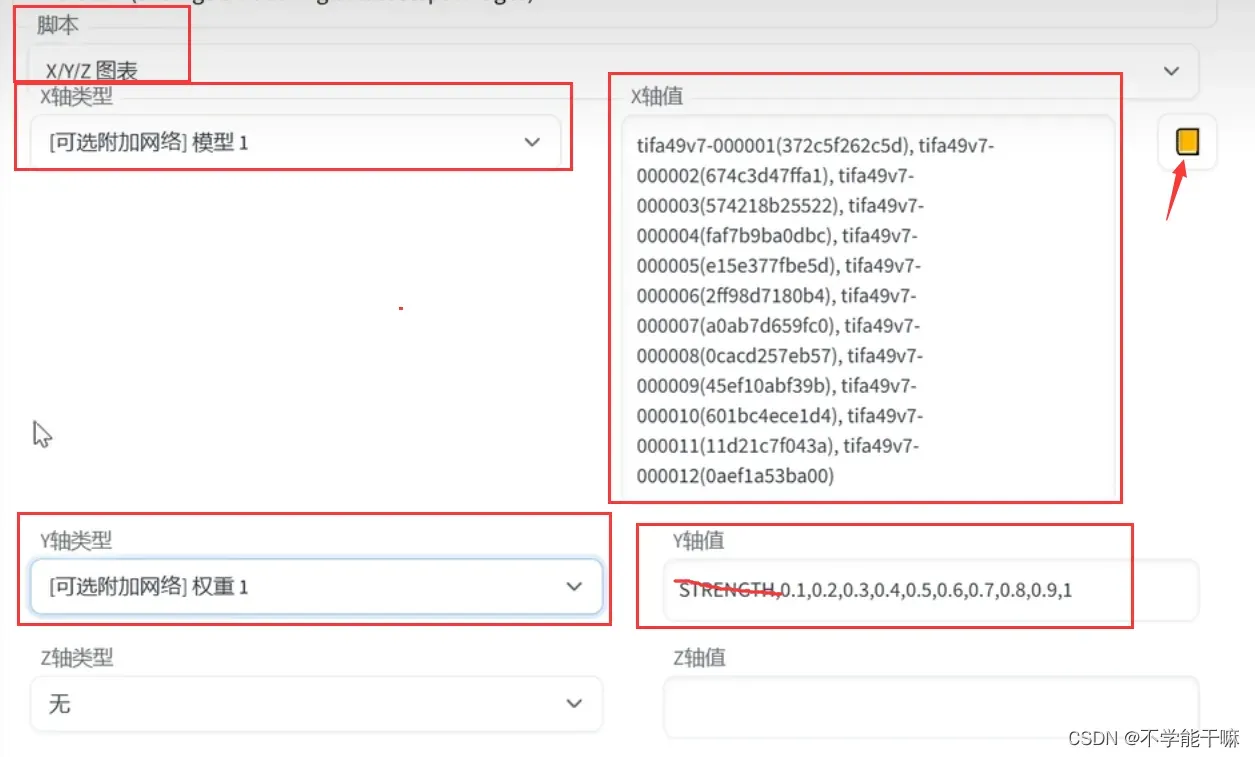
下面脚本同理, 按图上修改,X轴值点小黄书会出来所有的模型,只选择要测试的模型,其他的删掉;Y轴值改了不用写strength,直接从0.1写起即可。
调参的一些经验文章,持续更新:
【1】 [AI绘图]一些lora模型训练心得 – 知乎 (zhihu.com)
【2】【AI绘画】LoRA模型训练常见问题QA 4月刊 – 哔哩哔哩 (bilibili.com)
【3】Stable Diffusion——LoRA模型的训练详解(4万字详细解读) – 知乎 (zhihu.com)
这个讲的很详细,于我而言重点在触发词/样本设置的part上。
【4】炜哥的AI学习笔记——SuperMerger插件学习 – 哔哩哔哩 (bilibili.com)
在思考把lora和底模融合会不会效果更好?
【5】 SD文生图细节/为什么我的SD1.5模型生成效果很模糊_sd模型欠拟合会模糊吗-CSDN博客
我做XYZ测试的时候出现的问题,VAE没有选择合适,这里文生图就和样图的差别很大。
啦啦啦啦啦啦~坚持!
版权声明:本文为博主作者:不学能干嘛原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_59805198/article/details/135070297