文章目录
1. OCR 算法流程
OCR (Optical Character Recognition,光学字符识别) 是指提取图像中的文字信息。
1.1 传统 OCR 方法
传统 OCR 方法一般包含预处理、版面处理、字符切分、字符识别、后处理等五个步骤:
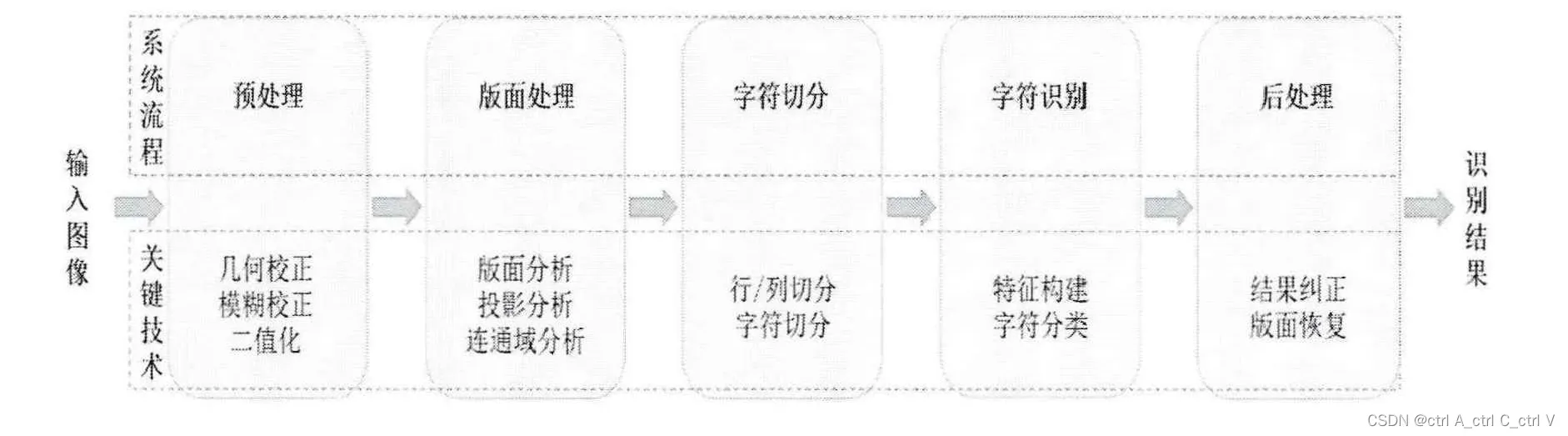
传统 ORC 方法的缺点有:
- 预处理和版面分析都是基于传统图像处理方法以及人工定义的规则,通常是基于固定场景开发的,无法迁移到其它场景中,应用范围有限。
- 字符识别方法基于人工特征,鲁棒性不足,在字体变化或者背景干扰情况下,分类器的识别效果会大打折扣。
- 流程繁杂,各个模块互相独立,导致难以整体调优,同时各个模块串联也会导致误差传递,造成整体识别精度不高。
总体来讲,受传统算法的局限性,传统 OCR 仅在比较规整的印刷文档上表现比较好,但在复杂场景(图像模糊、低分辨率、干扰信息)中,文字检测和识别性能都不够理想。
1.2 深度学习 OCR 方法
深度学习时代的 OCR 算法更为简洁,主要可以分为两种思路:
- two-stage方法:文字检测+文字识别,分别由检测网络和识别网络来完成。
- 端到端方法:直接输出识别后的文本,由一个大网络来完成。

1.2.1 two-stage方法:文字检测+识别
二阶段 OCR 是目前主流的,也是效果较好的方法,一般包括文字检测和文字识别两部分:
- 文字检测:将图片中的文字区域位置检测出来
- 文字识别:对文字区域中的文字进行识别
这篇博客主要研究 two-stage 方法。
1.2.2 端到端方法
近几年也有统一了文字检测检测和识别的端到端的 OCR 方法,如 STN-COR,FOTS 和 ABCNet。
STN-COR 由定位网络和识别网络两部分组成。定位网络的输入是场景文本图片,输出是N个变换矩阵,每个矩阵经网格后形成一个采样网格,每个采样网格代表一个文本区域。识别网络是单字符识别网络的改进,可以识别多个字符。
但端到端的模型仍有几个问题等待解决:
- 特征共享问题:
文字检测和识别需要的特征的粒度不同,文本检测只需要区分出当前区域是否包含文本即可,使用粗粒度的特征即可满足要求。但识别需要区分不同文字的差别,需要细粒度的特征。检测和识别分支的特征如何有效共享是个仍待解决的问题。 - 模型训练的问题:
识别分支的收敛速度远慢于检测分支,需要的数据量远大于检测分支。因此端到端训练时数据量和收敛速度问题如何平衡仍需关注。
本节参考硕士论文:苗文强. 基于深度学习的文本识别算法研究与实现[D].北京邮电大学,2022.DOI:10.26969/d.cnki.gbydu.2022.002445.
2. 文本检测算法
文本检测算法可以分为两大类:基于回归和基于分割
- 基于回归的方法:借鉴目标检测算法,采用预测图片边界框的方法实现对文本的定位,典型的模型有 CTPR 和 RRD
- 基于分割的方法:将文本检测问题看成一个二分类任务,判断每个像素是否是文本,之后再聚合像素组成文本行,典型的网络有 PSENet 和 DBNet
3. 文本识别算法
文本识别算法可分为两类:基于分割的单字符识别方法,基于序列标注的文本行识别方法。
- 基于分割的单字符识别方法:通常包含字符分割和字符识别两个步骤。首先从输入文本实例图像中定位每个字符的位置,该过程通常使用分割网络如 FCN 实现;然后将分割后的字符输入字符分类器进行分类;最后再组合字符得到字符串作为最终识别结果。
- 基于序列标注的文本行识别方法:通过 Encoder-Decoder 框架将整个文本行图片直接映射为目标字符串序列,从而避免了字符分割带来的误差。
其中基于序列标注的文本行识别方法是目前的主流方法。
3.1 基于分割的单字符识别方法
基于分割的单字符识别方法通常包含字符分割和字符识别两个步骤。该方法尝试从输入文本实例图像中定位每个字符的位置,该过程通常使用分割网络如 FCN 实现,然后将分割后的字符输入字符分类器进行分类,最后再组合字符得到字符串作为最终识别结果。
因为这种方法已经取得了重大进展,但仍然存在一些明显的缺陷:
- 场景文本中字符分割的难度极大,而字符分割不准确会影响后续的字符分类。
- 该方法串联了一个分割子网络和一个字符识别子网络,导致误差累积,造成整体识别效果不佳。
- 该方法无法结合字符的上下文信息辅助识别当前字符,导致识别难度增大。如小写字母 “l” 和 数字 “1” 难以区分,如果有前后文信息,比如字符前后都是数字,那么是 数字 “1” 的可能性更大。
3.2 基于序列标注的文本行识别方法
基于序列标注的文本行识别方法通过 Encoder-Decoder 框架将整个文本行图片直接映射为目标字符串序列,从而避免了字符分割带来的误差。这种方法包括四个流程:预处理、视觉特征提取、序列建模、解码预测。
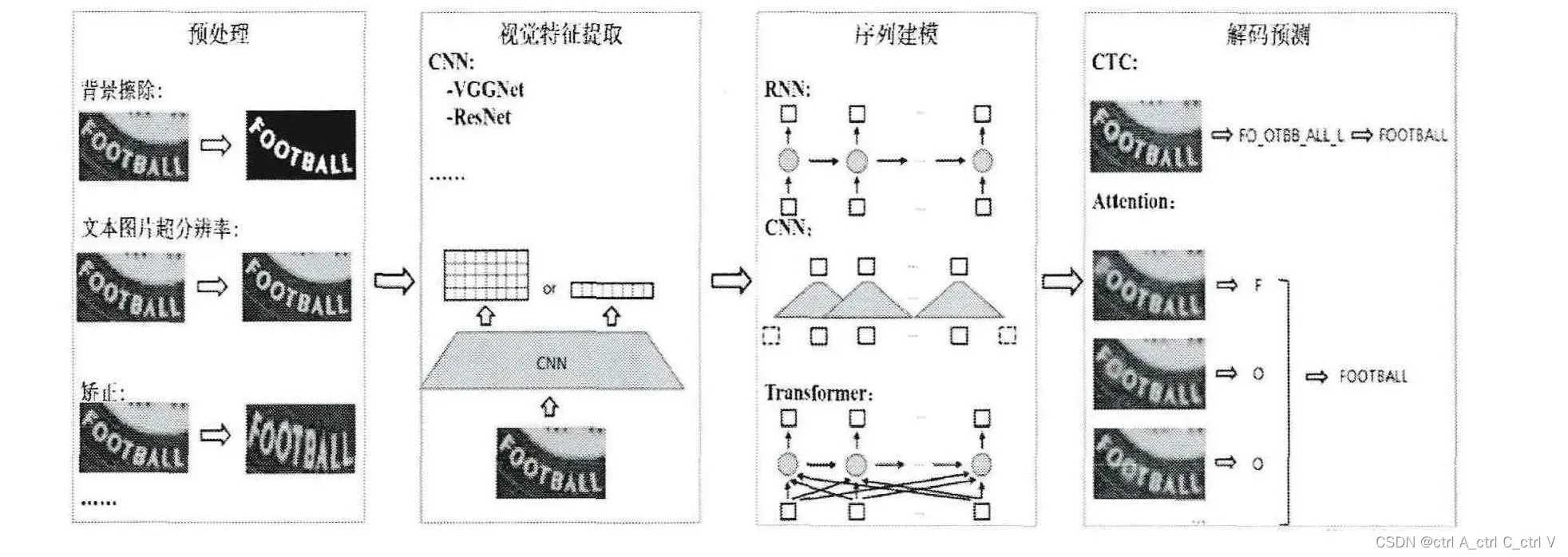
- 预处理:预处理包括图片背景擦除,清晰化(超分辨率)和图像矫正等操作,这会给整个识别流程增加额外的时间消耗,考虑到速度与准确率的平衡,预处理操作不是必须的。
- 视觉特征提取:通常使用 CNN 来提取特征,如 VGG 和 ResNet
- 序列建模:通过使用双向 RNN,如双向 LSTM 和 Transformer
- 解码预测:OCR 主流的三大解码算法是 CTC、Attention、ACE
版权声明:本文为博主作者:ctrl A_ctrl C_ctrl V原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_43799400/article/details/135125949