使用的源码来自于github: GitHub – davabase/whisper_real_time: Real time transcription with OpenAI Whisper.
安装speech_recognition时需要安装依赖包PyAudio、pocketsphinx
还需要安装ffmpeg-python否则会报错
运行效果如下:
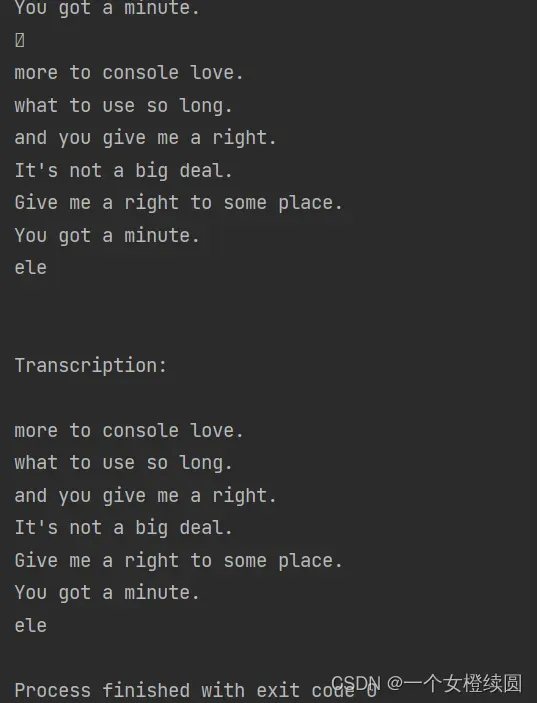
点击运行程序后出现model loaded 没有错误然后直接对着麦克风说话即可
版权声明:本文为博主作者:一个女橙续圆原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_48133091/article/details/131576501