🚀个人主页:为梦而生~ 关注我一起学习吧!
💡相关专栏:
深度学习 :现代人工智能的主流技术介绍
机器学习 :相对完整的机器学习基础教学!
💡往期推荐:
【机器学习基础】一元线性回归(适合初学者的保姆级文章)
【机器学习基础】多元线性回归(适合初学者的保姆级文章)
【机器学习基础】决策树(Decision Tree)
【机器学习基础】K-Means聚类算法
【机器学习基础】DBSCAN
【机器学习基础】支持向量机
【机器学习基础】集成学习
【机器学习 & 深度学习】神经网络简述
【机器学习 & 深度学习】卷积神经网络简述
💡本期内容:R-CNN系列算法是经典的two-stage的目标检测算法,相较于one-stage精度更高,但是速度略有下降。从R-CNN到Fast R-CNN和Faster R-CNN,整个思路是:候选框选取——特征提取——对候选框进行分类(判定类别)和回归(修正候选框位置)。R-CNN系列算法在目标检测领域有着重要的影响和应用,是计算机视觉领域的重要算法之一。
文章目录
0 前言
RCNN在2013年在目标检测领域首次使用深度学习和卷积神经网络,他与Alex net一起引爆了21世纪第二个十年计算机视觉领域的技术爆炸。
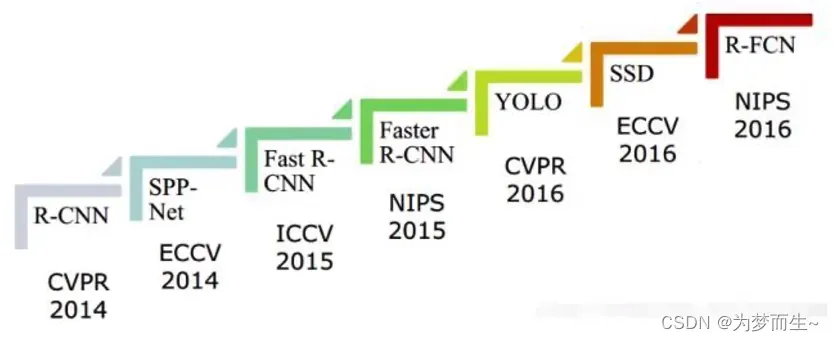
后续所有基于深度学习的目标检测——特别是两阶段目标检测算法。如Fast RCNN Faster R-CNN,都是在R-CNN上进行的迭代升级。
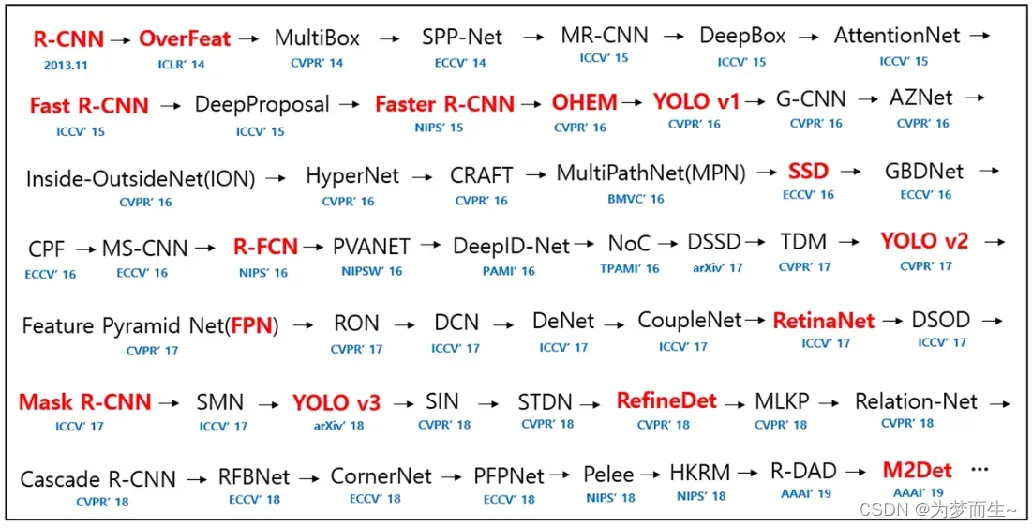
所以弄懂RCNN特别重要。甚至可以说,没弄懂RCN后边的算法根本就看不懂。
1 R-CNN
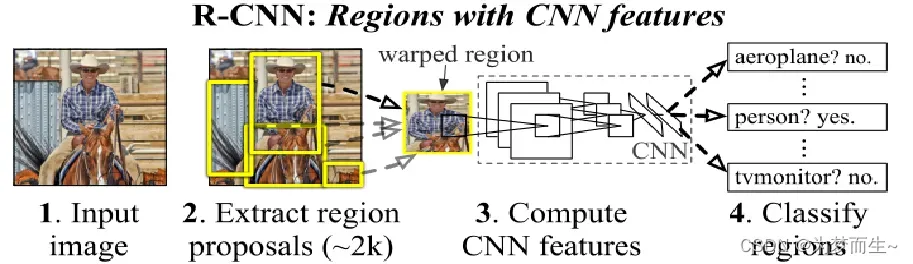
1.1 算法步骤
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
1.1.1 候选区域的生成
利用selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。

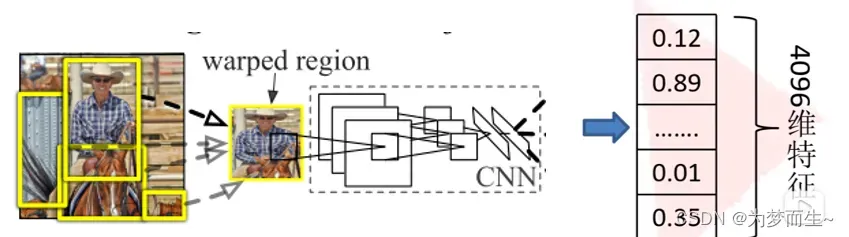
1.1.2 提取特征
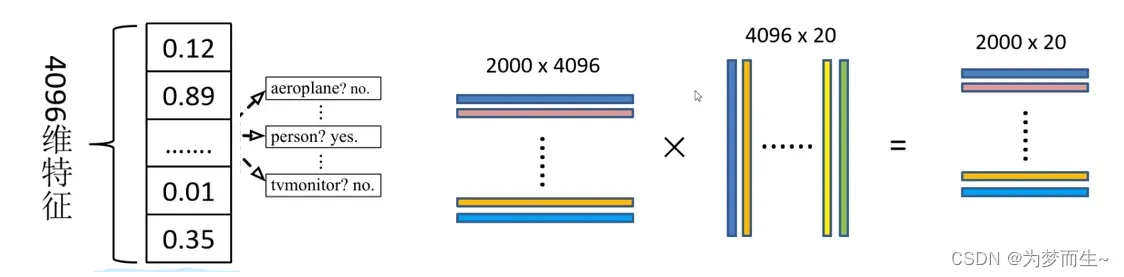
将2000候选区域缩放到227x227pixel,接着将候选区域输入事先训练好的AlexNet CNN网络获取4096维的特征得到2000×4096维矩阵。
1.1.3 判定类别
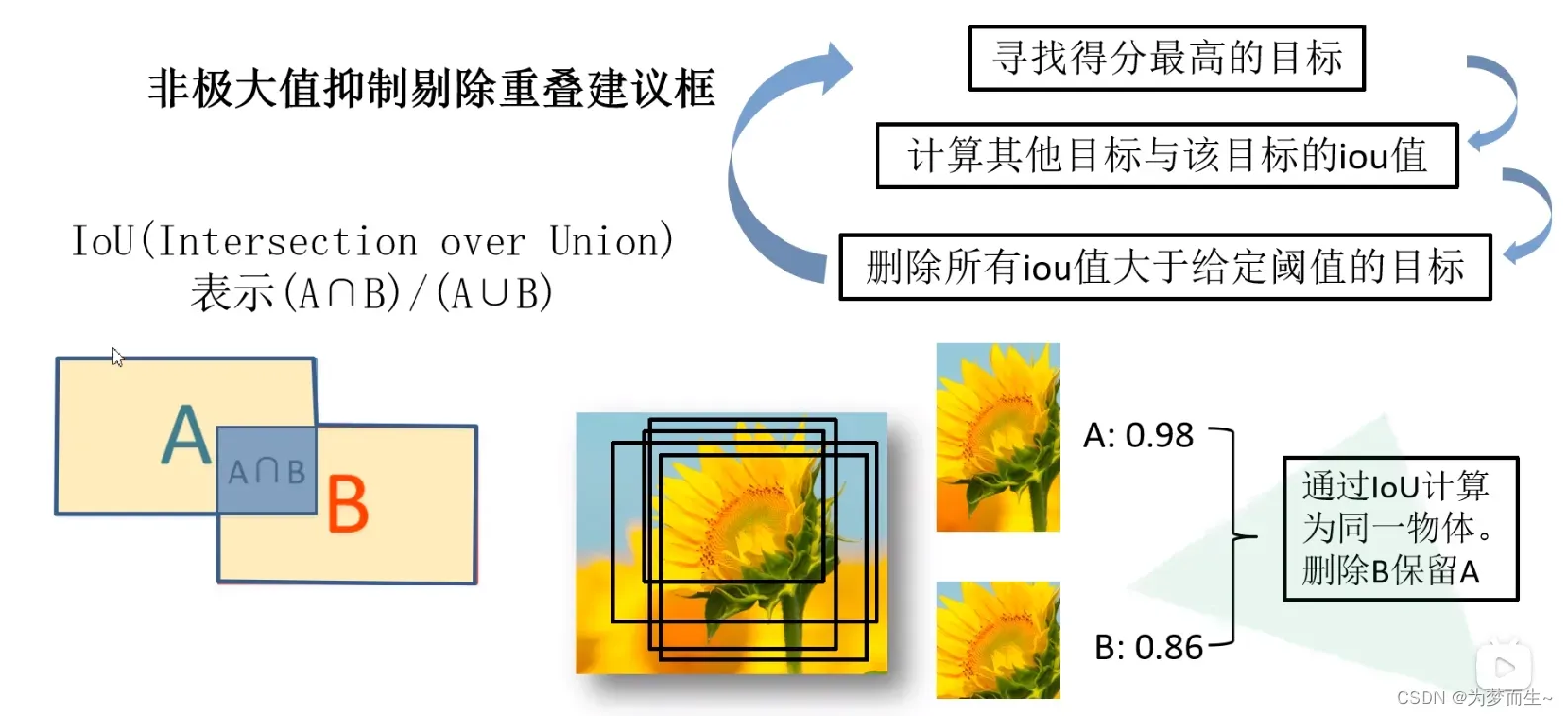
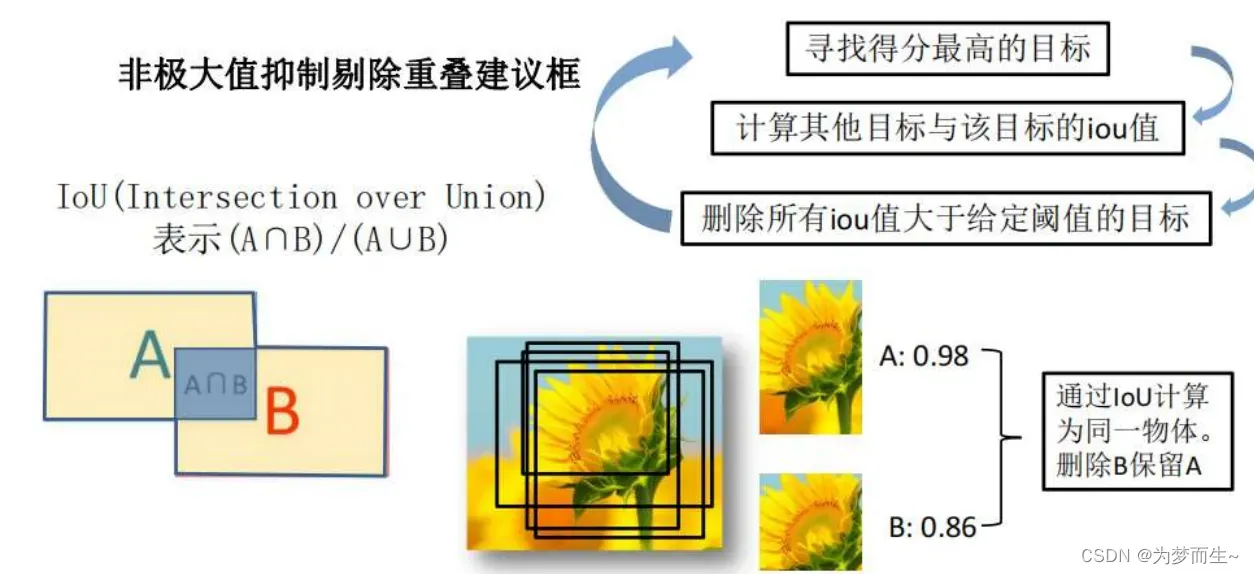
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘,获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
进行非极大值抑制处理
1.1.4 精细修正候选框的位置
对NMS处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
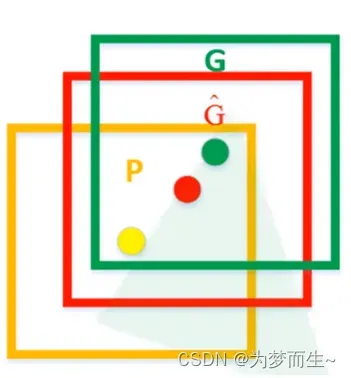
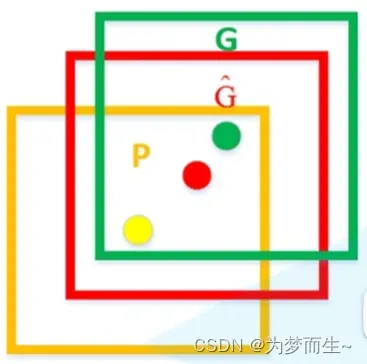
如图,黄色框口P表示建议框Region Proposal,绿色窗口G表示实际框Ground Truth,红色窗口表示Region Proposal进行回归后的预测窗口,可以用最小二乘法解决的线性回归问题。
1.2 算法总结

R-CNN算法可以分为以下步骤:
- 候选区域生成:利用Selective Search算法在每张图像上生成约2000个候选区域。这些候选区域被认为是可能包含目标的区域。
- 特征提取:将每个候选区域缩放为227×227,然后输入到预训练的CNN网络中,提取出4096维的特征向量。这一步将每个候选区域转换为固定大小的向量。
- 分类和回归:对于每个候选区域,使用SVM分类器进行分类,判断是否属于该类。然后使用回归器精细修正候选框的位置。
到后面我们会看到,这几个部分会不断融合,形成一个端到端的框架。
1.3 存在问题
- 测试速度慢:
测试一张图片约53s (CPU)。用Selective Search算法提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。 - 训练速度慢:
过程及其繁琐 - 训练所需空间大:
对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07训练集上的5k图像上提取的特征需要数百GB的存储空间。
2 Fast R-CNN
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用vGG16作为网络的backbone,与R-CNN相比训练时间快9倍,测试推理时间快213倍,准确率从62%提升至66%(再Pascal voc数据集上)。

2.1 算法步骤
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
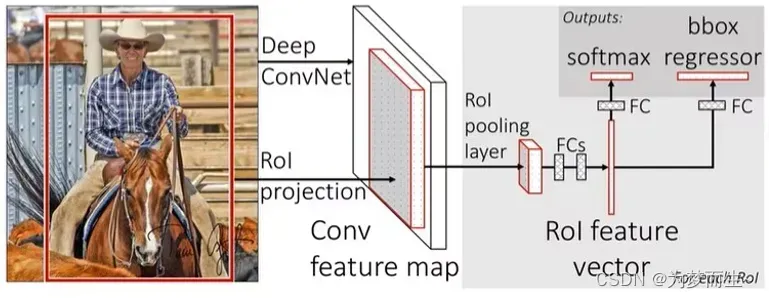
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
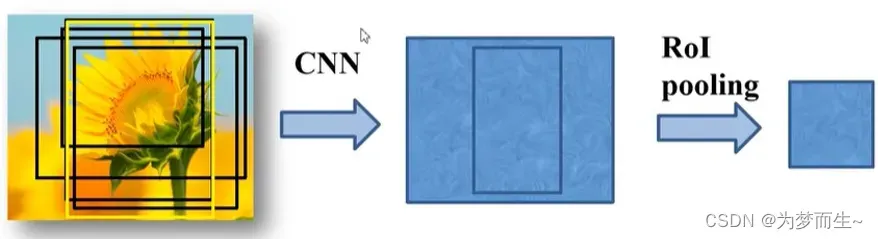
- 将每个特征矩阵通过ROI pooling层缩放到7×7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
2.2 与Fast R-CNN的区别
2.2.1 共享卷积层
一次性计算整张图像特征
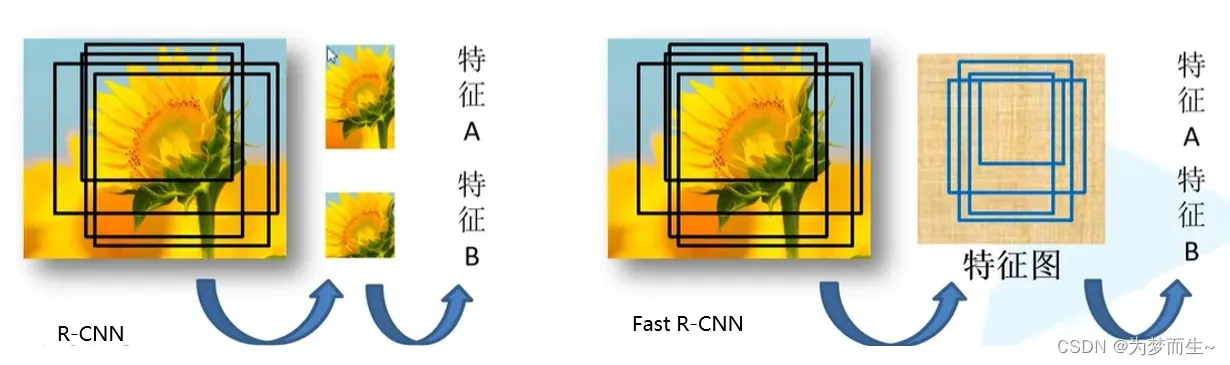
R-CNN依次将候选框区域输入卷积神经网络得到特征。
Fast-RCNN将整张图像送入网络,紧接着从特征图像上提取相应的候选区域。这些候选区域的特征不需要再重复计算。
2.2.2 ROI pooling
不限制输入图像的尺寸,便于计算
统一缩放为7×7大小的特征图
2.2.3 分类器和边界框回归器
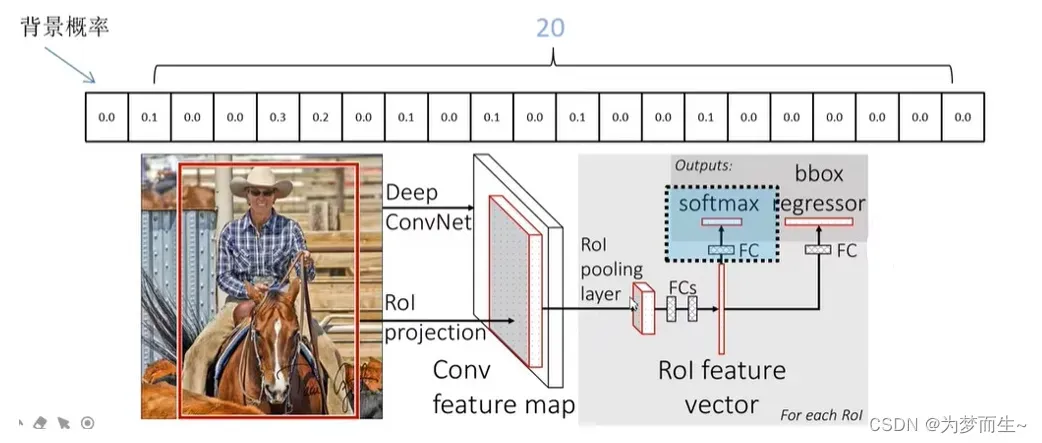
该网络的框架是这样的:
- 首先将图像输入到CNN网络得到feature map
- 再根据共享卷积层的映射关系对应到相应的特征矩阵
- 之后通过ROI pooling层缩放为7×7大小的矩阵
- 然后进行展平处理,在经过两个全连接层之后,得到feature vector
- 在feature vector的基础上,再并联两个全连接层
- 一个是分类器用于分类概率的预测,另一个回归器用于边界框回归参数的预测
分类器输出N+1个类别的概率(N为检测目标的种类,1为背景)共N+1个节点
边界框回归器输出对应N+1个类别的候选边界框回归参数(dx, dy, dw, dh),共(N+1)x4个节点
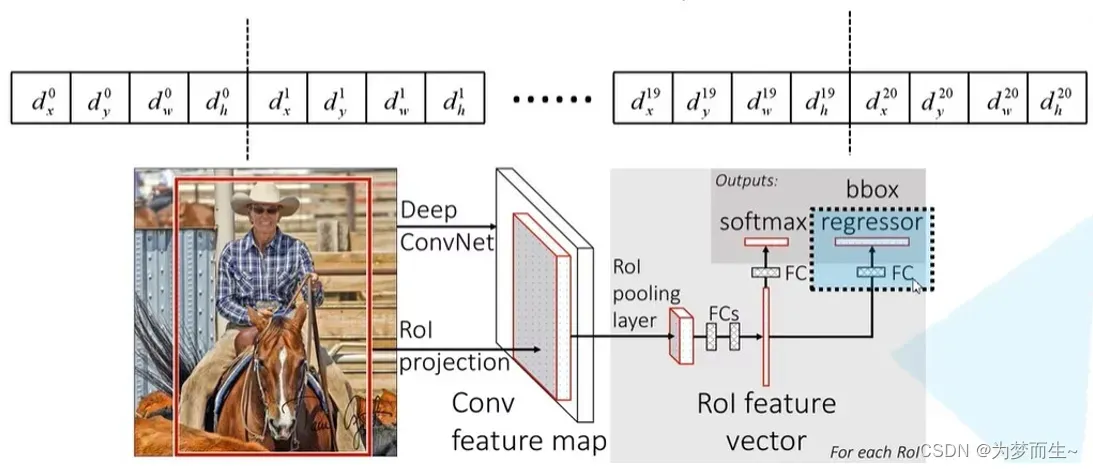
回归的具体计算如下图所示:
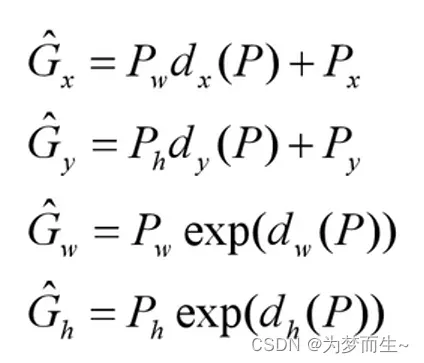
分别为候选框的中心x,y坐标,以及宽高
分别为最终预测的边界框中心x,y坐标,以及宽高
2.2.4 损失函数
它的损失函数分为分类损失和边界框回归损失

- p是分类器预测的softmax概率分布
- u对应目标真实类别标签
对应边界框回归器预测的对应类别u的回归参数
- v对应真实目标的边界框回归参数
其中,分类损失在原论文中说的是使用log损失
边界框回归损失为:
2.3 算法总结

该算法首先还是使用selective search寻找候选框
但是后面的特征提取,分类和回归已经融入到了一个网络,进一步提高了速度。
3 Faster R-CNN
Faster R-CNN是作者Ross Girshick继Fast R-CNN后的又一力作。同样使用vGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在2015年的ILSVRC以及cOCO竞赛中获得多个项目的第一名。

3.1 算法步骤
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7×7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
实际上就是RPN+Fast R-CNN
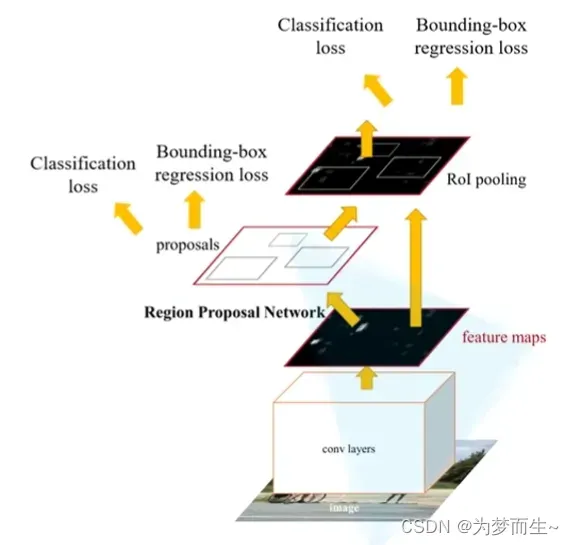
所以,接下来只需要详细介绍一下RPN网络结构
3.2 RPN
在Faster R-CNN的训练过程中,RPN网络的训练是第一步。在这个阶段,使用ImageNet预训练的模型初始化RPN网络,并通过端到端的微调来优化网络参数,使其能够生成高质量的候选区域。在后续的训练步骤中,RPN网络和Fast R-CNN网络会共享卷积层,构成一个统一的网络,从而进一步提高目标检测的准确性和效率。
原论文给出的RPN网络的结构:
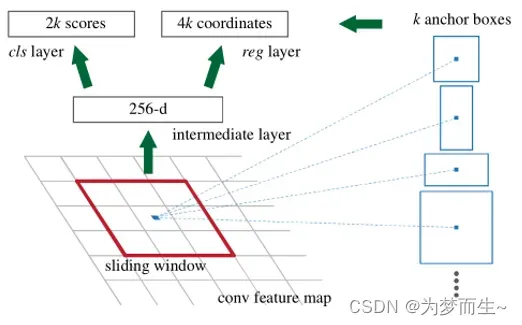
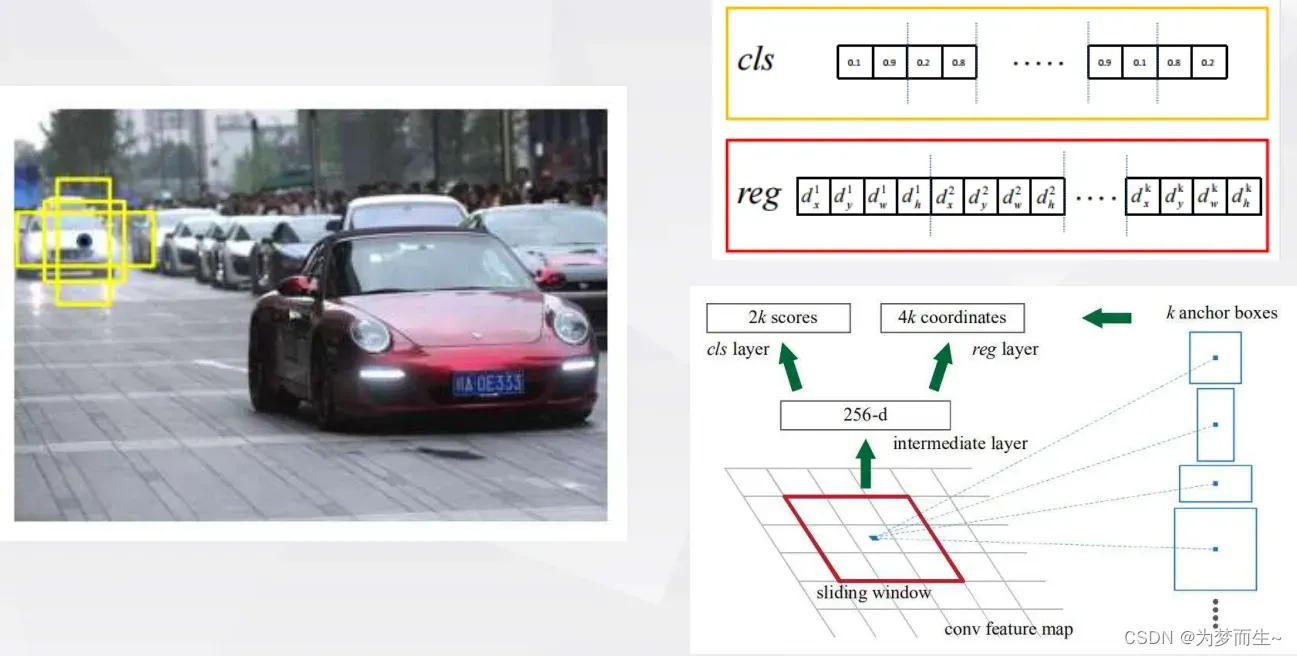
- 该网络使用滑动窗口在feature map上面进行滑动,每次滑动时都会生成一系列候选框(即anchors)
- 输出的通道数为256-d,再分别连接两个1x1conv,输出2k个score和4k个坐标,
- 对于k个anchor,得出2k个预测概率和4k个边界框回归参数
- 分类概率分别为前景和背景的概率,边界框回归参数还是Fast R-CNN提到的那四个
- 向量的维度与backbone有关,这里使用ZF网络所以是256维,如果是VGG16,那就是512维
3.2.1 anchor
RPN(Region Proposal Network)网络中的anchor是Faster R-CNN中的一个核心概念。Anchor是在特征图上预先定义的一组矩形框,用于在图像中滑动并检测可能包含目标物体的区域。其主要目的是提供一种在图像中搜索目标物体的方式,通过不同尺度和长宽比的矩形框来覆盖图像中的不同区域。
在RPN网络中,每个anchor都对应一个特征图上的点,这个点称为anchor的中心点。以这个中心点为基准,根据设定的尺度和长宽比,在特征图上生成一个矩形框,这个矩形框就是anchor。因此,anchor的数量和特征图的大小以及设定的尺度和长宽比有关。
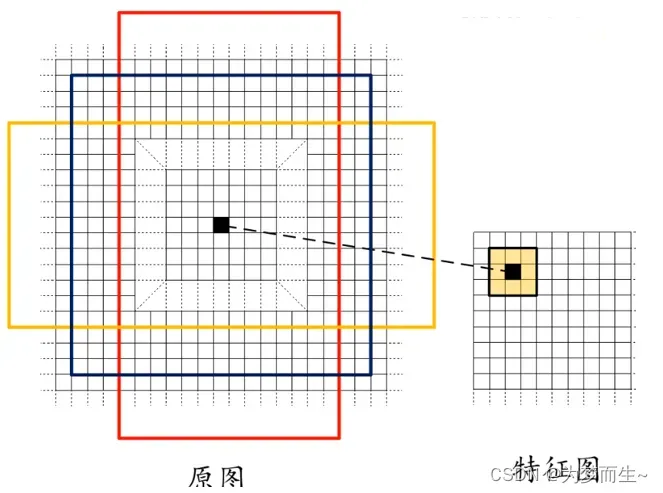
RPN网络中的anchor具有两个重要的作用:
- 一是用于生成候选区域(proposals),即可能包含目标物体的区域;
- 二是用于训练RPN网络,使其能够区分正样本和负样本,并对候选区域进行边框回归,调整其位置和大小。
anchor三种尺度(面积){1282,2562,5122}
anchor三种比例{ 1:1, 1:2, 2:1 }
每个位置在原图上都对应有3×3=9 anchor
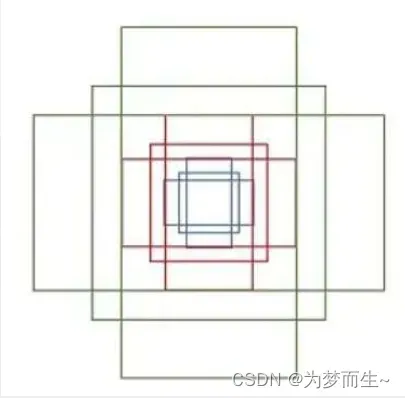
对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩2k个候选框。
3.2.2 IOU
在训练阶段,RPN网络会为每个anchor生成一个二分类标签(正样本或负样本),以及一个边框回归值。正样本是指与真实目标边界框(ground-truth box)重叠程度较高的anchor,而负样本则是指与真实目标边界框重叠程度较低的anchor。
通过不断优化网络参数,RPN网络可以逐渐学习到如何区分正样本和负样本,并对候选区域进行准确的边框回归。

对于如何确定正负样本,原论文给出了这样的定义:
- 首先,与ground-truth的交并比大于0.7的anchor为正样本
- 其次,如果所有ground-truth与anchor的交并比都小于0.7,选择与ground-truth有最大交并比的anchor作为正样本
- 最后,选择与ground-truth的交并比小于0.3的anchor为负样本
3.2.3 损失函数
原论文中给出的损失函数:

表示第i个anchor预测为真实标签的概率
当为正样本时为1,当为负样本时为0
表示预测第i个anchor的边界框回归参数
表示第i个anchor对应的GT Box
表示一个mini-batch中的所有样本数量256
表示anchor位置的个数(不是anchor个数)约2400
分类损失:
分类损失在原论文中给出的是一个softmax cross entropy
边界框回归损失:
这一部分与Fast R-CNN的边界框回归损失是一样的
论文中给出的是smooth L1损失
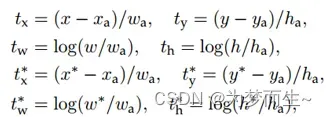
3.3 Faster R-CNN的训练
现在的很多地方都是直接采用RPN Loss+ Fast R-CNN Loss的联合训练方法
原始的训练方法是这样的:
- 利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数;
- 固定RPN网络独有的卷积层以及全连接层参数,再利用lmageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框去训练Fast RCNN网络参数。
- 固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数。
- 同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
3.4 算法总结

版权声明:本文为博主作者:为梦而生~原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/z135733/article/details/136005255