引言:
北京时间:2023/9/1/21:15,下午刚更新完博客,同理再接再厉,这样整天不需要干什么,除了玩手机的日子不多了,马上就要开学,每天需要签到签退的日子就要来临,烦躁,照我预料下学期我们学校应该会开一门Java的专业课,现在这种线下课给我的第一感觉就是摆烂,学了跟没学是一样的,从上学期的MySql就能看出,对于MySql而言,目前就会一些简单的指令操作,别的没有,没有一种框架的感觉,这就是线下课独有的魅力,哈哈哈!当然等我们在猴年之后把网络学完,我们应该也就会进入MySql的学习,此时的MySql是属于我们自己的MySql,到时候肯定能领略到其的美丽,嘻嘻!然后就是《一念永恒》这本小说,不知不觉间居然快追完了,哎,某些人别的本事没有,看小说倒是挺上道,此时心想,如果能把看小说的时间挤出来拿去做题,烦恼不就统统烟消云散了嘛,哈哈哈!乐观,无所谓,还是那句话,时间咱还有,慢慢搞,该摆摆,该烂烂,咱不急,开学再说,呀呀呀!开心,还能耍。下面我们就正式进入该篇博客的学习,有关服务端中日志和守护进程相关的知识。

深入服务端相关知识
在上篇博客中,我们重点对TCP版本的套接字通信进行了原理分析和代码实现,并在代码实现中我们分为了单执行流服务端和多执行流服务端的区分,最后在博客尾部我们以多线程的方法来改进多进程方式下的服务端多执行流,并在结尾提出使用线程池来进一步提高该服务端效率,但因为服务端除了最关键的使用套接字进行网络通信之外,对于服务端而言,还有许多非常重要的组件,当然对于上层应用层协议和下层TCP协议有关的知识或者组件目前我们先不了解,我们此时就服务端而言先来简单看看其不可或缺的组件:日志组件,本质就是一个服务端代码执行过程的打印步骤,在将其保存到特定文件中之后,我们就能轻易的从该文件中定位到该服务端代码执行过程的错误位置以及错误信息,进而便与我们改良。所以为了完善我们的服务端,该篇博客我们就来学习一下有关日志的知识,最后再将我们的服务端实现守护进程化,具体下述详解。
服务端中的日志组件
首先强调,对于目前的我们而言,日志是一个基础知识,所以我们只是简单的实现以及理解,因为日志在大型项目中非常重要,具体编写也较为复杂,我们目前还没有具体的场景以及实例,有待以后深入学习,现在我们只需要简单看一看日志的大致实现过程以及具体内容就行。并且明白,虽然日志没有我们想象的那么简单,但是这是基于我们没有见过大型的实战项目而言,对于日志本身而言,如上述所说,它只是一个程序执行过程中信息的打印而已。
为什么服务器中一定需要使用日志组件?
讲日志相关知识,我们就一定需要追本溯源,本质就是搞懂因果关系,因为什么,所以什么,到底为什么,在上述中我们谈过了,日志的本质就是在程序执行过程中在特定位置将我们想要获取的信息保存在特定的文件中,然后从该文件中根据日志信息定位到程序的错误位置,当然这就是我们在服务器中使用日志的目的,但此时会有问题,我为什么不直接使用cout或者printf直接将错误信息打印出来,然后改善呢?而是需要封装一个组件来获取日志信息呢?本质两点原因:首先,如果我们直接在服务端代码中使用cout或者printf,那么日志信息就会被直接打印到标准输出,也就是控制台上,那么此时就会涉及很强的IO过程,加上如果该日志信息打印非常频繁的话,最终就会导致该服务器的性能和运行速度被影响,其次,也就是我们需要将日志信息存储在一个特定的文件中,所以为了避免代码冗余,也就是多次进行将日志存储到文件的这一编码过程,我们就需要使用日志组件,每次调用该日志组件内的接口,让其帮我们完成一系列日志存储工作。
封装日志组件预备知识
明白了上述知识,此时我们就有了很强的目的性,很强的抓手,我们为什么要封装日志组件,哦,原来本质就是为了让其帮我们对特定信息进行存储,有了这部分的认识,此时就可以很好的引出我们接下来要讲的可变参数相关知识,首先还是为什么需要认识可变参数呢?通过上述的铺垫,此时很好的就能明白,因为我们需要利用日志组件(头文件)中对应的接口,所以在调用接口时,我们就需要自己对日志信息进行格式化控制(类比使用printf),所以谈到格式化控制我们就需要使用可变参数,当然具体此时我们使用的是C语言中的可变参数,而不是C++中的可变参数包,所以接下来我们就需要认识几个有意思的宏定义以及格式化控制接口,如下所示:
-
va_list功能:用于声明一个指向参数的指针变量,所以该类型可以声明一个指针变量,如:va_list p,在使用时,需要对其进行初始化,也就是让该参数指针指向某参数我们需要明确,并且一般就是用于指向参数列表的第一个参数。 -
void va_start(va_list ap, last);功能:同理va_list中所说,该宏用于初始化va_list声明的参数指针,也就是让其指向对应参数列表的第一个参数,第二个参数last:表示函数参数中最后一个非省略运算符(…)的参数,当然依据用法,也就是我们需要格式化的字符串,注意:虽然我们没有直接将可变参数列表(…)传递给va_start接口 ,但是其会根据format参数(last)的位置和大小等信息来计算出可变参数列表的起始位置,然后用于初始化ap。 -
type va_arg(va_list ap, type);功能:将参数指针当前指向参数列表中的参数依据format(格式化信息)中对应的字符转化为对应的类型,如:format中识别到d,我们就将该参数转化为int,s转化为字符指针,c转化为字符,同理此时以%为识别依据,这也是为什么我们使用printf接口时,需要使用%d/%s/%x的原因,下文代码附上。第一个参数:参数指针,在该参数指针当前指向参数被转化为对应类型之后,自动指向参数列表中的下一个可变参数,第二个参数:该参数对应类型。 -
void va_end(va_list ap);功能:关闭可变参数列表,本质也就是销毁指向参数列表的指针。
注意:上述宏定义都在头文件 <strarg.h> 中,本质都是为了识别可变参数列表中对应参数类型而已,具体va_arg识别过程,如下代码所示:

同理,再次强调,我们需要使用可变参数以及进行格式控制,本质是因为我们需要自己实现日志组件中对应接口对服务端传过来的参数以及格式化信息进行控制,也就是我们的日志组件需要有能力去处理服务端中想要获取的日志信息,也就是对应参数表示的含义以及想要进行的格式化控制。当然,根据上述代码可以看出,我们对数据类型的控制比较麻烦,所以这个过程我们一般不会自己进行编码,而是直接使用对应的接口完成,所以下面我们就来认识一下有关格式化控制的接口吧!如下所示:
-
int printf(const char *format, ...);功能:依据格式化数据以及参数列表将预期内容输出到标准输出文件中。第一个参数:格式化字符串,用于指定输出格式,第二个参数:省略运算符,表示可变参数,可以接收任意类型,任意数据的参数,提供格式化字符串中需要被输出参数的值。 -
int sprintf(char *str, const char *format, ...);功能:同理上述所说,只不过此时是将数据输出到指定字符数组中。第一个参数:字符指针,用于接收字符数组的首元素地址(数组名),第二个参数:同理格式化字符串,第三个参数:同理可变参数,接收任意类型、数量的参数,提供给格式化字符串使用。 -
int fprintf(FILE *stream, const char *format, ...);功能:同理,将数据输出到指定文件中,只不过在使用之前,需要使用fopen接口以特定的方式打开某个指定文件,然后获取该打开文件的返回值FILE* 类型的一个文件指针,最后才能将格式化完成的数据成功写入该文件,下述我们保存日志信息时,就会使用到该接口。第一个参数:FILE*的文件指针,本质就是一个被打开文件,底层是对open的封装,内含缓冲区、文件描述符等… ,本质就是向操作系统对应进程的文件描述符表申请了一个文件描述符而已,此时再根据该文件的打开方式(位运算+判断)来进行该文件数据读取或者写入。第二个参数:同理,第三个参数:同理。 -
int snprintf(char *str, size_t size, const char *format, ...);功能:同理,将数据输出到字符数组中,只不过此时提供了更加安全的输出方式,限制了输出字符的大小,防止因为数据过大导致的溢出问题,第一个参数:同理字符指针,用于指向字符数组的首元素地址,注意:本质是先有字符数组,后有字符指针,也就是本质是因为我们需要将数据存储到字符数组中,所以此时使用字符指针来接收,当然我们也可以是会用char str[],字符数组来接收,第二个参数:同理,第三个参数:同理。
这里简单对上述四个接口进行一次分析,强调,上述四个接口在我们的日志组件中是不可能被使用的,本质还是那个道理,我们需要的是自己实现一个日志打印接口,所以服务端传过来的一定是需要进行格式化控制的信息和对应的参数,所以我们自己的日志接口就一定需要是一个可变参数接口,也就是使用了省略运算符的接口,所以我们不能使用上述三个接口进行对可变参数列表的控制,而必须使用下述四个接口,如下所示:
-
int vprintf(const char *format, va_list ap);功能:同理printf接口,唯一区别,最后一个参数此时不是省略运算符(…)的可变参数,而是一个va_list 类型的参数指针,用于存储可变参数列表。本质同理上述所说,前者用于接收任意类型,任意数量的参数,后者用于存储接收到的这些任意类型,任意数量的参数列表的第一个参数。 -
int vsprintf(char *str, const char *format, va_list ap);功能:同理sprintf接口,唯一区别同理,一个用于获取任意类型任意数量的参数,一个用于存储获取到的任意类型任意数量的可变参数列表的第一个参数。 -
int vfprintf(FILE *stream, const char *format, va_list ap);功能:同理fprintf,向某个被打开文件以某种方式写入数据,同理唯一的区别就是一个用于获取任意类型任意数量的参数,一个用于获取可变参数列表中第一个参数的地址,第一个参数:使用fopen接口打开之后的一个文件流,第二个参数:同理格式化字符串,第三个参数:同理。 -
int vsnprintf(char *str, size_t size, const char *format, va_list ap);功能:同理snprintf,唯一区别同理,参数同理。
同理,所以此时我们应该使用上述四个接口来完成我们对参数列表的识别以及format的格式控制,本质就是因为这四个接口的最后一个参数不是省略运算符,而是va_list类型的参数指针,也就意味着我们自己的接口中可以使用省略运算符(…)来接收服务端提供给我们的任意类型,任意数量的参数 。
正式实现日志组件
现在搞定了上述有关C语言可变参数和对应格式控制接口相关的知识,此时我们就可以正式进入日志组件的封装,当然上述强调过,我们目前只是简单了解,目的就是为我们的服务端提供日志功能而已,所以当我们学习完日志组件的实现之后,我们就可以将我们上篇博客剩余的线程池实现服务端代码和日志组件结合在一起啦!如下就是一个日志的简单实现:
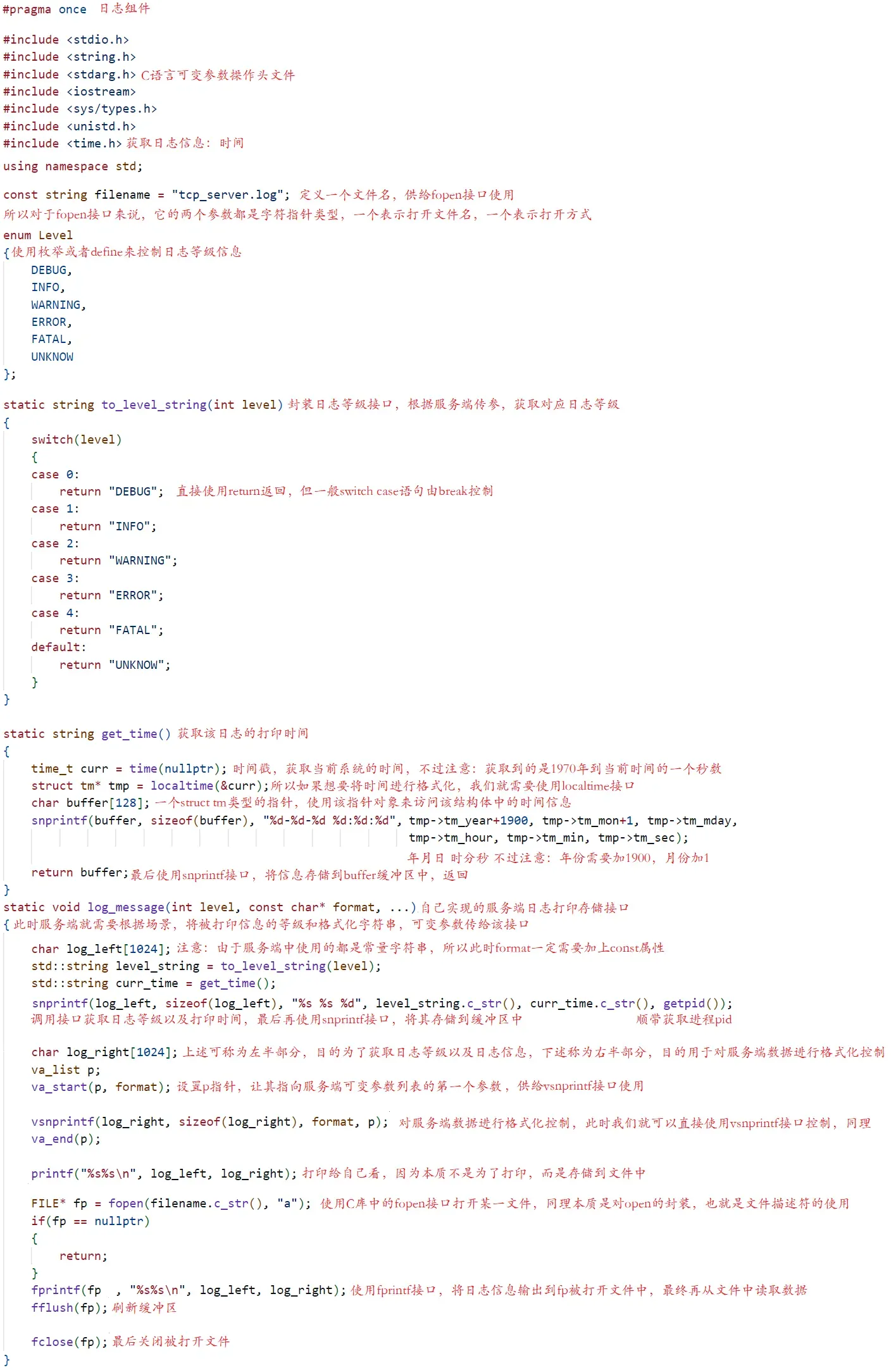
行文来到此处,对于日志相关的知识我们就有了一个简单的认识啦!剩余就是上篇博客欠下线程池版本服务端结合日志组件的这块知识,当然在此再次强调,上述我们实现的日志组件,只是一个婴儿版的日志组件,如果遇到大型项目,我们一般使用的是专门的日志组件,并且上述是经典的C语言实现代码,具体C++如何使用可变参数包实现,感兴趣的小伙伴可以去了解,接下来我们就正式来看看如何实现线程池版本的服务端,并且使用日志组件存储日志信息。
线程池加日志组件版本服务端实现
有关线程池知识,在当初系统中学习线程时,我们有进行重点强调,但是由于时间过去较久,所以此时我们需要对相关知识进行一定的回顾,在当时讲解线程池时,我们重点对什么是池化技术(资源管理方式),什么是单例模式(饿汉/懒汉)进行了讲解,最终利用饿汉模式封装了一份属于自己的线程池代码,最终结合上述知识,我们明白线程池的本质就是事先创建好一批线程,然后在任务队列中有任务需要被执行的时候,利用这一批线程去执行任务队列中对应的任务而已,本质使用线程池的目的就是为了让其完成某种任务,所以在接下来服务端使用线程池的过程中,我们本质就只是将对应服务端需要执行的任务交给该线程池去完成而已,当然此时我们使用的线程池就是我们之前对应封装的线程池,如下图所示:

在上图中,我们就将服务端以线程池的方式实现,并在对应场景下,我们使用日志组件中对应的日志接口很好的将特定信息进行了保存,所以有关服务端使用线程池以及日志组件实现的知识我们就了解完啦!只不过接下来我们需要回顾一下对应代码的执行过程,也就是上述我们是如何创建好任务,然后用线程池单例对象执行该任务,并且在线程池中线程是如何回调该任务,具体如下图所示:

ok,搞定了上图,有关线程池和日志实现服务端的知识我们就全部搞定,多的没有,全在图中,认真看图就行,再不行可以回顾我之前有关线程池的博客,反正本质就是因为我们自己实现了线程库,所以进行了两次线程回调函数的回调,线程库回调线程池,线程池回调任务类,任务类再回调服务端,看着挺复杂,本质其实就是类的组合以及函数指针相关知识,充分发现类的组合,可以直接构造类,然后加上函数值指针的这个用法,真的非常好用,在以后服务端需要实现更多功能的时候,就可以直接封装成一个一个模块,也就是一个一个类,然后直接将对应服务端中的参数传过去,再在类中利用这些参数,我们就能让我们的服务端实现各种各样的功能啦!
理解守护进程
当我们将一个服务端使用多执行流控制,并且添加了池化技术以及日志组件,那么该服务端在socket网络通信层面就基本较为完整了,剩余有关上层序列化、反序列化、http协议等应用层方面知识,我们将在下篇博客中具体了解,接下来我们学习最后一个有关服务端的知识,也就是守护进程及其相关知识,同理,对于一个新的概念,想要快速入门以及掌握,还是经典的两步走,不是图解,就是利用已学过知识,进行对比或者延伸,所以接下来我们就从两个方面来追本溯源,彻底搞定守护进程相关知识。
什么是守护进程
首先单从名字来看,守护进程一定是一个进程,与我们之前在学习进程相关知识中的僵尸进程、孤儿进程、父子进程有一定的可对比性,但为什么我们当时在系统中学习进程时,没有讲解什么是守护进程呢?同理,因为在之前的学习中,并没有特定的场景来供给我们学习守护进程,当然也就是服务端场景,而当此时我们有了服务端这个场景,那么我们就可以对其进行学习,但由于守护进程是一个全新的概念,所以此时我们通过服务端与守护进程之间的关系,我们先来简单介绍一下守护进程,守护进程是操作系统中一个在后台独立运行的进程,它不受其它进程和会话影响,在系统运行期间持续运行。明白了守护进程的概念,那么此时我们就很好的可以明白为什么服务端与我们的守护进程相关了,本质就是想让服务端拥有守护进程的特性,也就是对服务端进行守护进程化,具体为什么需要让服务端守护进程化,如下所述。
服务端为什么需要使用守护进程?
明白了上述有关守护进程的介绍,那么现在我们对于服务端和守护进程之间的关系就非常明确了,本质就是想让服务端代码的执行过程不被其它进程和会话影响,让服务端代码可以在系统后台执行运行。那么此时问题就来了,为什么服务端代码有可能被其它进程或者会话影响呢?所以想要搞懂这个问题,也就是深入理解守护进程,此时我们就需要引入几个其它的概念,如:前台进程/后台进程、进程组、会话、进程终端等…,首先我们对前台进程和后台进程做一个对比,这点虽然之前在学习进程有关知识时,我们有了解过,此时再来回顾一下,明白,前台进程与后台进程最大的区别就在于前台进程拥有终端的控制权,也就是它可以向终端写入数据,也可以获取终端中的数据,所以它可以接收Ctrl+C或者Ctrl+Z这类的终止信号,从而让某个前端进程终止,反之,因为后台进程与终端无直接联系,所以它无法直接使用终端信号终止,必须使用Kill指令进行终止。 最后明白,对于一个程序而言,它是前台进程还是后台进程,这都是我们可以控制的,如:我们可以在程序后加上取地址符号(&)用于表示该程序在后台执行,并且,在进程的状态属性中,如果是S+那么表示的就是前台进程,S则表示后台进程,明白这些知识之后,此时如下图,我们就从进程属性来深入理解守护进程相关知识吧!

如上图所示,当时我们在学习进程相关知识时,我们学习了如何在Linux系统内部查找进程,而在查找进程之前,我们在后台运行了三个sleep进程,并且让这三个进程处于等待状态,所以当我们查找sleep进程之后,我们就可以查找出正在后台等待的三个进程,发现:它们的父进程(PPID)都是27952,也就是bash命令行解释器,它们的进程编号(PID)分别是29803/30008/30014;而它们的进程组编号(PGID)是29803/30008/30014,从进程组编号可以发现,进程组编号和PID编号相同,所以从这点我们可以看出,每一个进程它们自成一个进程组,所以明白,进程组不仅可以是多个进程,也可以是只有一个进程,同理也就是如果在父进程中创建了子进程,那么父进程和子进程肯定属于同一个进程组,或当同时运行多个进程时,这些进程也同属于一个进程组;而它们的SID(会话编号),可以发现与父进程(PPID)是相同的,也就是说,这三个进程不仅都是bash命令行解释器的子进程,并且也同属于bash命令行解释器这个会话中,具体下述提供一幅图解;而它们的控制终端(TTY),同理表示的就是这三个进程,它们使用的都是pts/2这个终端,该终端一般在根目录下的dev目录中,并且因为它们同属于27952(bash)会话中,所以该终端本质也就是该bash所处的终端,而对于终端而言,它本质也就是一个文件,而对于bash而言,它本质就是Linux系统创建的一个会话(进程),并且分配对应的终端给其使用,所以在bash命令行解释器中使用ls、touch、cd、rm等指令,本质就是系统对对应指令进行处理,处理完成之后,将返回值写入到终端中,也就是pts/2文件中,最终我们在终端看到数据。而其中如果TTY(控制终端)为 ?,那么表示的就是该进程与终端无关;然后是它们的控制终端进程组ID(TPGID),本质也就是bash命令行解释器所处的进程组ID,所以同理,Linux系统在创建bash命令行解释器时,可以是一个一个的创建,也可以是多个同时创建,然后分为不同的bash进程组,本质就是一个套娃过程,后面什么STAT、UID属性我们就不谈了,直接来一幅图示,让我们可以更好的理解bash命令行解释器与Linux系统之间的关系。

从上图我们就可以看出,每次我们在使用远程登录软件登录Linux机器时,远程Linux系统内部就会创建一个进程组(任务),这个进程组可以是只有一个进程,也可以是多个进程,然后让该进程组的组长进程(会话首进程)去执行命令行解释器相关代码,让其成为bash进程,专门负责处理用户输入的指令以及代码,然后再创建对应的终端文件供给给bash命令行解释器,让用户可以实现与bash进程的交互,本质该终端文件,有点类似于套接字文件,本质就是用户将数据输入到该终端文件,然后Linux服务端从该终端文件中获取数据,处理数据,最终将返回值再返回到该终端文件,从而让用户在终端看到对应数据处理结果,当然具体概念差异很大,从功能层面分析而已。
总:通过上述对进程属性以及图解的分析,总结起来就是在Linux系统中,我们可以使用多个会话,一个会话表示的就是一个bash命令行解释器,表示的就是一个进程组,使用的就是一个终端文件,其中就包含着不止一个进程(进程组)。
ok,讲了这么多,那我们不还是不知道为什么服务端需要使用守护进程吗?别急,哈哈哈!下面让我们明白最后一个点,有关进程组操作的知识,明白完该知识之后,我们就能搞懂为什么服务端一定要使用守护进程来实现啦!在上述我们谈到有关前台进程和后台进程,通过平时对bash命令行解释器的使用,我们知道bash命令行解释器进程是一个前台进程,因为它具有对应终端的控制权,而如果当我们在终端通过bash运行一个其它前台进程,那么我们会发现,此时bash进程就会被终止,前台开始运行新的程序,此时对于bash命令行解释器来说,它就被挂起,成为了一个后台进程,只有当我们终止正在运行进程,此时bash进程才能重新变成前台进程,供给用户使用,所以明白对于终端而言,当然也就是对于会话而言,它只能同时运行一个前台进程,系统中大部分进程都是以后台进程在运行,所以接下来我们对后台进程的操作进行一个了解。
对后台进程进行操作
从上述我们明白,在Linux系统中,大部分的进程都是后台进程,并且一个进程是允许进行前台进程和后台进程的切换的,所以接下来我们就学习一下有关前后台进程的切换,首先查看系统中所有的后台进程,指令:jobs,当我们在系统后台运行了多个进程时,如下图,此时我们就能看到许多的后台进程。
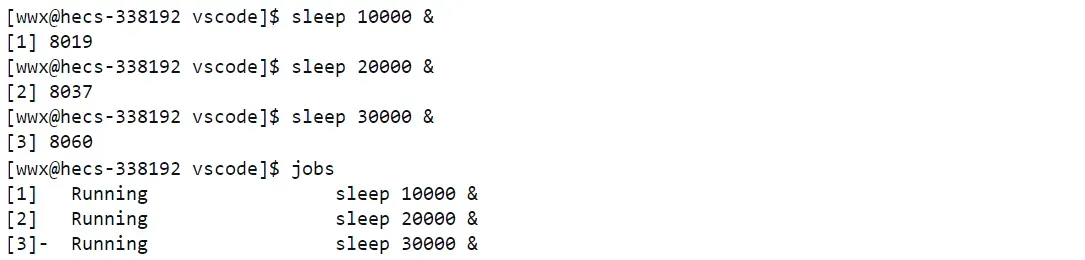
从上图我们就可以看出,当我们在系统后台运行了三个sleep暂停进程,此时后台进程就会将该进程的进程组ID和后台进程编号返回给我们,当我们使用jons查看所有后台进程时,此时我们就看到了我们刚刚运行的后台进程,而如果我们想让其中某个后台级进程从后台进程变为前台进程,那么此时我们就可以使用指令:fg 1/2/3(fg + 对应后台进程的编号),所以当我们将某个后台进程变为了前台进程,那么此时bash就会被挂起到后台,此时程序执行被fg的后台进程,同理此时我们就可以使用终端对被fg后台进程进行操作,如:Ctrl+C终止该fg后台进程,或Ctrl+Z暂停该fg后台进程,并且如果一个前台进程被暂停(Ctrl+Z),那么同理会被挂起到后台,并显示其状态会暂停状态,若想让其重新运行,此时就可以使用指令:bg,所以以上操作流程就是后台进程的所以操作方法,明白了这些之后,此时我们对一个系统中的进程就有了很强的理解。所以此时我们就可以引出上述问题,为什么服务端需要使用守护进程?
铺垫完成,正式回答服务端使用守护进程问题
无论是上述对进程属性中进程组ID,会话ID,终端控制等理解,还是对前/后台进程操作的理解,我们明白,想要执行我们的服务端代码,启动服务端,当然也就是完成对应的任务,那么我们就需要利用Linux系统分配的会话(进程),然后在该会话中去执行对应的任务,并且该任务可以是一个前台任务,也可以是一个后台任务,但是如果当我不想使用该会话,也就是退出Xshell或者是某个会话,那么此时就有可能导致该会话内部的任务被影响,同理会话(进程组)就是用来供给用户完成某些任务,内含非常多的其它进程(进程组);当然如果正常理解,我们关闭某个会话,就是等同于关闭系统中的某个进程,所以此时进程中的子进程自然就会被直接销毁,当时由于系统的设计不同(Windows/Linux),所以关闭会话不一定就会将该会话中的进程销毁,所以只能说是影响,不能说是销毁,但我们的服务端不容许被影响,所以此时该问题就需要被解决,解决方法很简单:就是使用我们一直在强调的守护进程。本质也就是让我们后台运行的服务器不会被用户的登录、注销等操作影响(用户需要在会话中启动服务端),也就是让其自成一个会话,不受其它会话的影响,也就是让服务端从之前的包含关系变为并列关系(会话),这也就是我们让服务端守护进程化的根本原因。
服务端守护进程化代码实现
在自己实现守护进程之前,我们首先需要明白,系统中已经存在直接让服务端守护进程化的接口daemon ,使用方法:int daemon(int nochdir, int noclose); 其中第一个参数表示是否更改服务端的工作路径,第二个参数表示是否更改服务端的标准输出、标准输入、标准错误文件描述符。明白了该接口之后,此时我们自己对服务端守护进程化代码进行编写,本质利用的是setsid接口,同理daemon接口就是一个对setsid接口的封装,只不过是进行了更加丰富的细节处理而已,此时明白想要自己实现守护进程代码,不仅只是使用setsid接口,还需要进行几个方面的细节处理,如:我们需要将服务端的标准输入、标准输出、标准错误文件描述符关闭,目的:避免因为服务端在后台运行时,服务端内部存在向终端(标准输出)打印,从而影响用户的使用(守护进程服务端自成一个会话,拥有独立的终端);还需要在服务端中忽略某些信号,如SIGHUP/SIGINT/SIGPIPE,这样可以避免我们在关闭服务端终端时,系统向服务端发送某些信号,从而导致服务器被终止;同时也需要对服务端的工作路径做改变,本质同理,就是因为服务端被守护进程化,那么它就是一个独立的会话,此时它的工作路径就不再是原进程启动时的那个工作路径,而是新会话中的某个进程工作路径,所以此时当服务端需要使用原工作路径下的数据时,就需要将其工作路径进行修改,从新工作路径修改为服务端进程启动工作路径(一个程序被启动,它的工作路径就是当前目录路径);最后想要让服务端实现守护进程化,还需要确保调用setsid接口的进程不能是组长进程,本质原理同理,还是因为如果一个服务端被守护进程化,那么它就拥有了自己的会话,拥有了自己的终端,所以如果让服务端的启动进程(组长进程)去执行setsid接口,那么此时就会导致该进程同时存在于两个会话,拥有两个终端,这样是不合理的,所以此时我们就需要让服务端启动进程创建一个子进程,让子进程去执行setsid接口,成为守护进程新会话的会首进程,最终让服务端独立于所有会话。
明白了上述有关服务端守护进程实现的细节知识,此时我们根据步骤就可以很好的在自己的代码中使用setsid接口,封装属于自己的守护进程,然后再提供给服务端使用啦!具体如下图代码所示:

在上述代码,我们就很好的利用setsid接口,对服务端的守护进程过程进行了封装,对其中忽略信号、子进程作为话首进程、修改标准输入、输出、错误等过程我们就有了一个更深的认识,并且通过对其分析,可以看出,守护进程的本质也是一种孤儿进程,独立于所有进程,只收到系统的管控,所以以上就是守护进程的所有知识,具体服务端只需要在初始化服务端之后,运行上述Daemon接口,此时服务端就会被守护进程化啦!
总而言之:结合守护进程是什么的概念和服务端持续运行的概念,最后明白,服务端与守护进程是不可分割的,一个服务想要实现持续运行的效果,那么它就需要被守护进程化,具体过程如上述所说。
总结:有关日志组件和守护进程的概念,以及使用日志组件和守护进程实现服务端的知识就这样啦!See you!
⭐好书推荐

清华社【秋日阅读企划】领券立享优惠,IT好书 5折叠加10元 无门槛优惠券:即点即领
活动时间: 9月4日-9月17日,先到先得,快快来抢
《C++高性能编程》

【内容简介】
《C++高性能编程》详细阐述了与C++高性能编程相关的基本解决方案,主要包括性能和并发性简介,性能测量, CPU架构、资源和性能,内存架构和性能,线程、内存和并发,并发和性能,并发数据结构,C++中的并发,高性能C++,C++中的编译器优化,未定义行为和性能,性能设计等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。 本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
📚 京东购买链接:【C++高性能编程】
📚 当当购买链接:【C++高性能编程】
版权声明:本文为博主作者:狂小伍的博客原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_74004489/article/details/132630971