下载编译llama.cpp
cd ~/Downloads/ai/
git clone --depth=1 https://gh.api.99988866.xyz/https://github.com/ggerganov/llama.cpp
cd llma.cpp
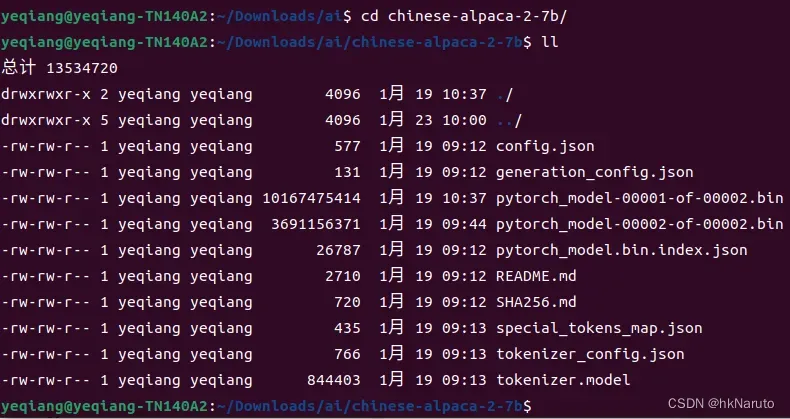
make -j8下载模型到/home/yeqiang/Downloads/ai/chinese-alpaca-2-7b目录
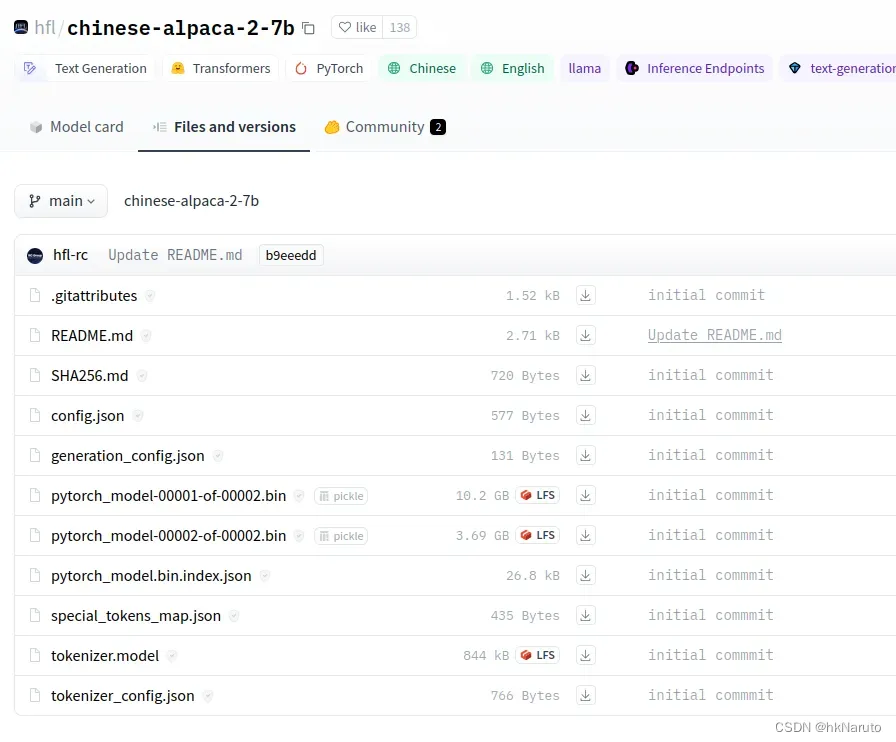
hfl/chinese-alpaca-2-7b at main
转换模型
安装venv
sudo apt install python3.10-venv配置pip国内镜像(阿里云)
创建~/.pip/pip.conf,内容如下
[global]
index-url=http://mirrors.aliyun.com/pypi/simple
[install]
trusted-host=mirror.aliyun.com安装依赖(失败)
cd ~/Downloads/ai/llama.cpp
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt

没有匹配的版本,为节约时间,放弃在arm64下安装python依赖,回到x86_64 ubuntu上转换模型
生成量化版模型
(venv) yeqiang@yeqiang-MS-7B23:~/Downloads/ai/llama.cpp$ python convert.py ~/Downloads/ai/chinese-alpaca-2-7b/
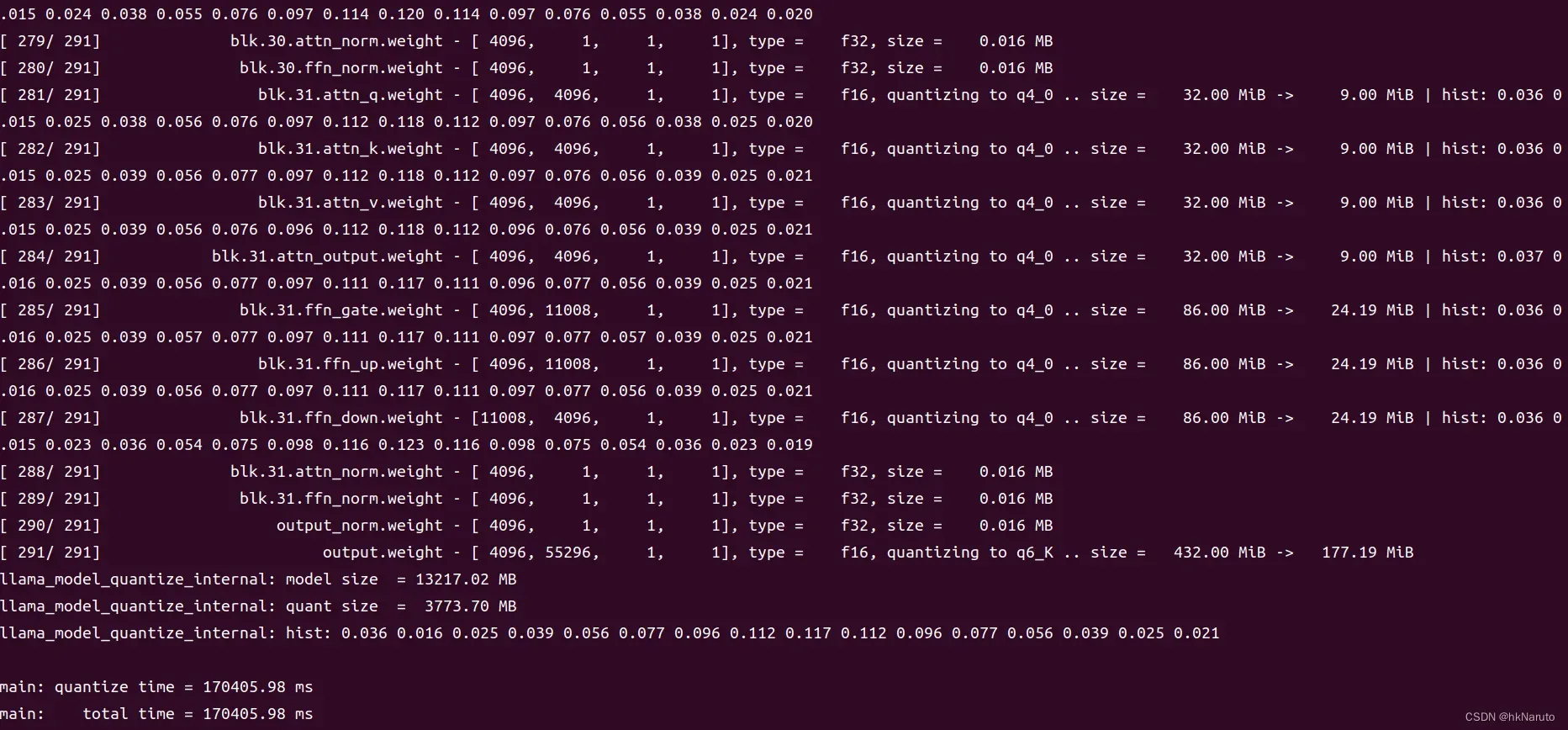
进一步对FP16模型进行4-bit量化
(venv) yeqiang@yeqiang-MS-7B23:~/Downloads/ai/llama.cpp$ ~/Downloads/ai/llama.cpp/quantize /home/yeqiang/Downloads/ai/chinese-alpaca-2-7b/ggml-model-f16.gguf /home/yeqiang/Downloads/ai/chinese-alpaca-2-7b/ggml-model-f16-q4_0.bin q4_0
再生成一个q8_0版本的
(venv) yeqiang@yeqiang-MS-7B23:~/Downloads/ai/llama.cpp$ ~/Downloads/ai/llama.cpp/quantize /home/yeqiang/Downloads/ai/chinese-alpaca-2-7b/ggml-model-f16.gguf /home/yeqiang/Downloads/ai/chinese-alpaca-2-7b/ggml-model-f16-q8_0.bin q8_0
拷贝到D2000笔记本上去。
测试
在llama.cpp项目下创建chat.sh
#!/bin/bash
# temporary script to chat with Chinese Alpaca-2 model
# usage: ./chat.sh alpaca2-ggml-model-path your-first-instruction
SYSTEM_PROMPT='You are a helpful assistant. 你是一个乐于助人的助手。'
# SYSTEM_PROMPT='You are a helpful assistant. 你是一个乐于助人的助手。请你提供专业、有逻辑、内容真实、有价值的详细回复。' # Try this one, if you prefer longer response.
MODEL_PATH=$1
FIRST_INSTRUCTION=$2
./main -m "$MODEL_PATH" \
--color -i -c 4096 -t 8 --temp 0.5 --top_k 40 --top_p 0.9 --repeat_penalty 1.1 \
--in-prefix-bos --in-prefix ' [INST] ' --in-suffix ' [/INST]' -p \
"[INST] <<SYS>>
$SYSTEM_PROMPT
<</SYS>>
$FIRST_INSTRUCTION [/INST]"
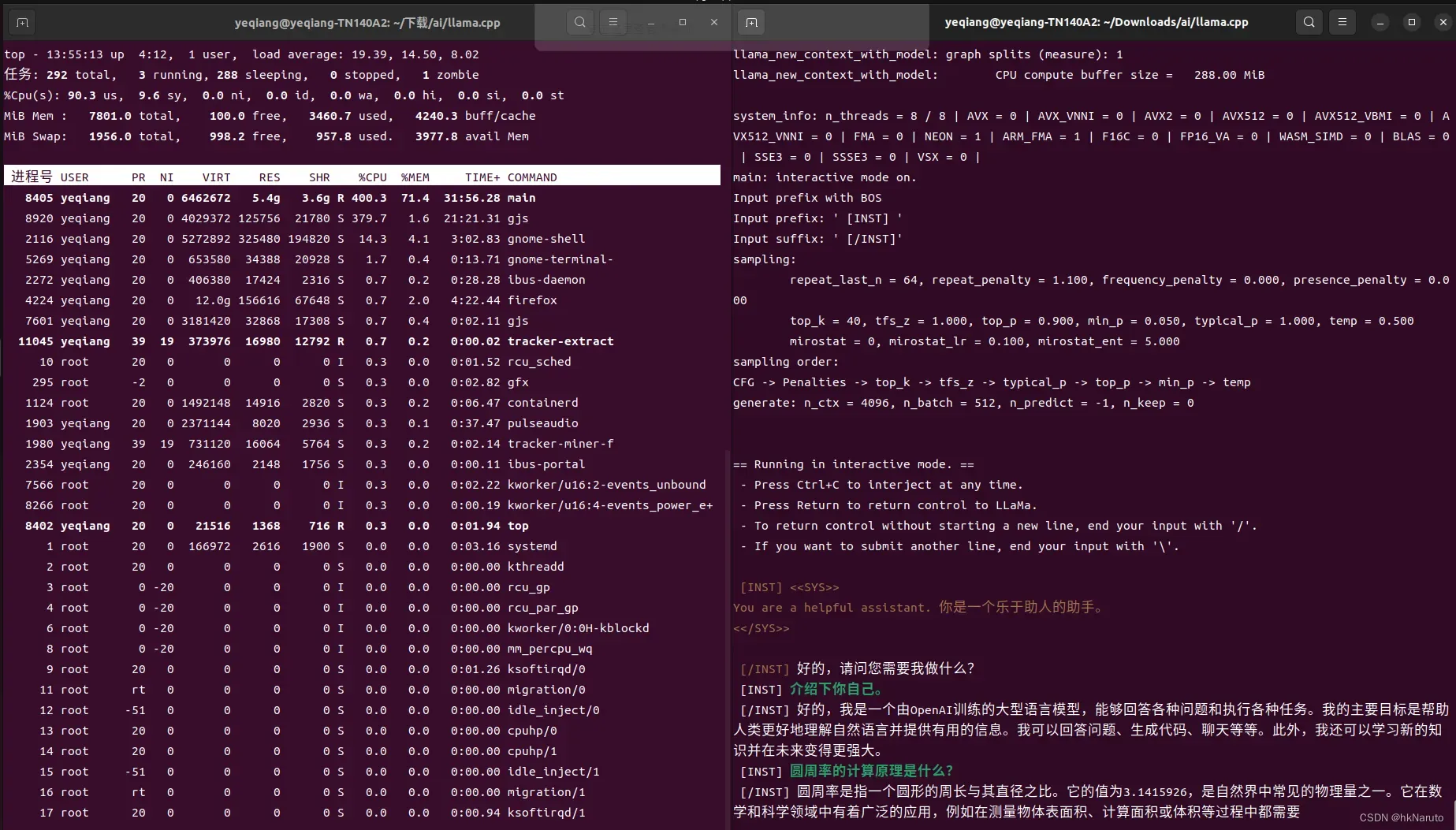
7b q4_0模型(吃力)
五分钟过去了,还没有回答完
7b q8_0模型(很吃力)
1分钟过去了,第一句话还没有输出完毕
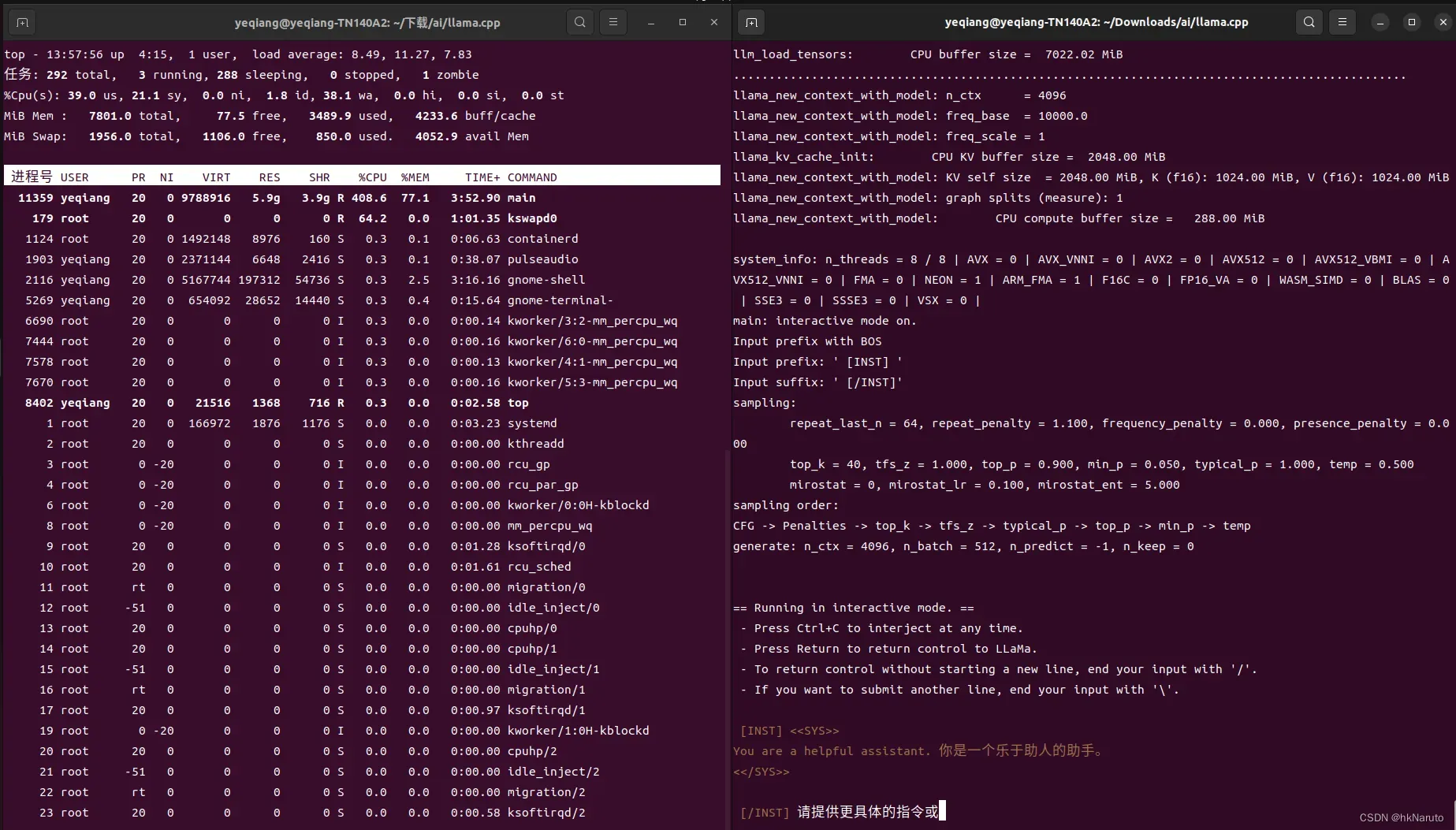
CPU温度飙升!
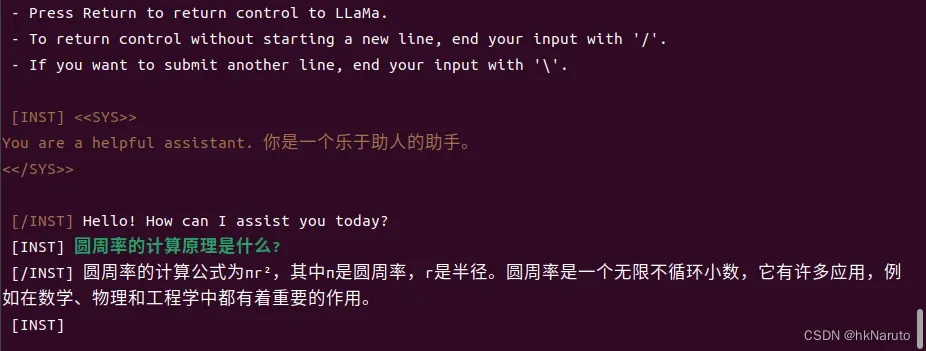
1.3b q_40模型(速度很快)
下载地址
hfl/chinese-alpaca-2-1.3b at main

速度很快,达到通义千问的响应速度,但是回答的内容很简单
D2000 aarch64比 i5-9600k x86_64速度还快!(前面的模型也是)
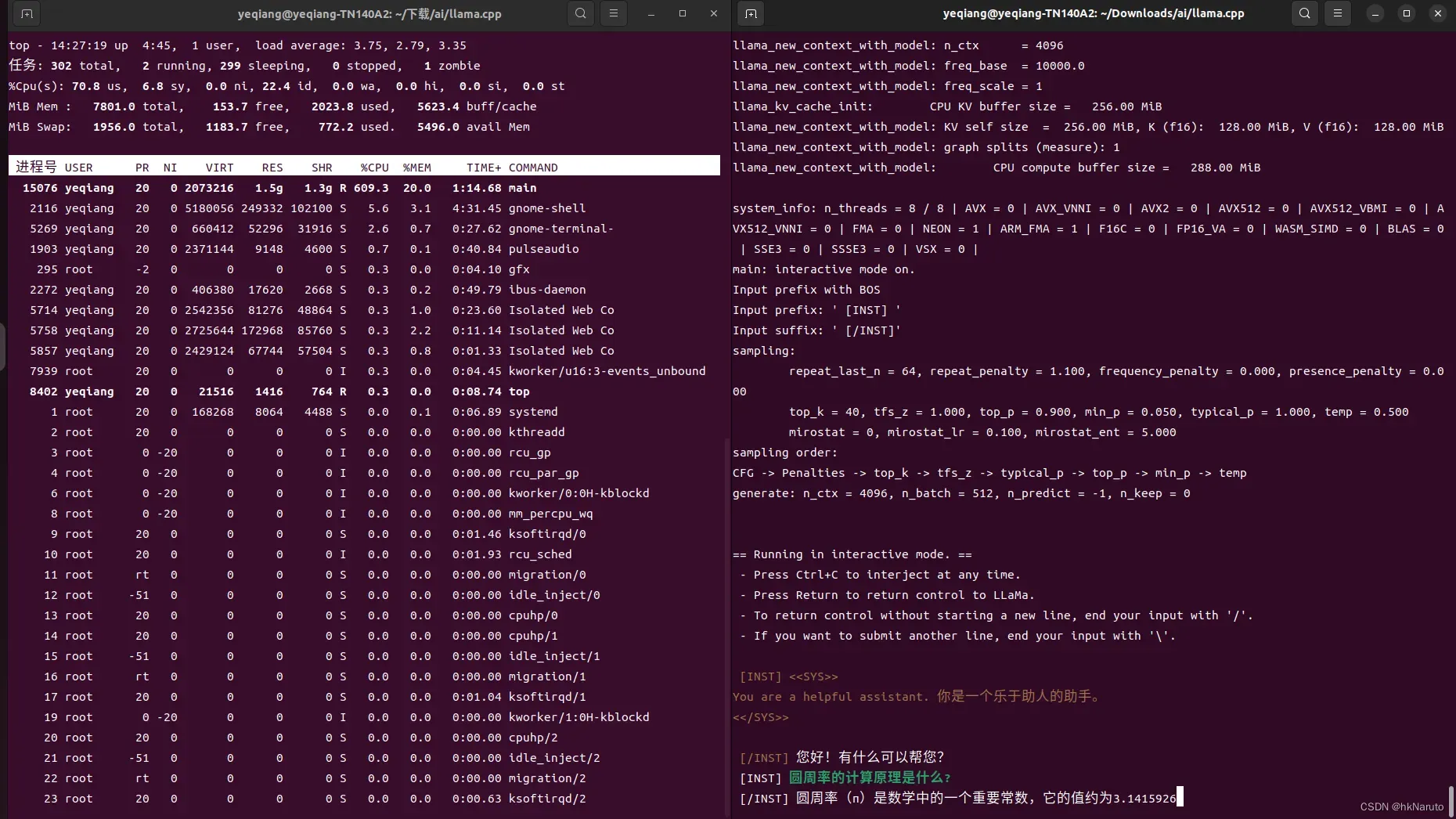
1.3b q_80模型(速度很快)
速度与q_40相比没有明显差异,输出内容更详细。

参考:
https://hknaruto.blog.csdn.net/article/details/135643928?spm=1001.2014.3001.5502
版权声明:本文为博主作者:hkNaruto原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/hknaruto/article/details/135764853