传奇开心果博文系列
- 系列博文目录
-
- Python自动化办公库技术点案例示例系列
- 博文目录
-
- 前言
- 一、重要算法介绍
- 二、回归分析示例代码
- 三、聚类分析示例代码
- 四、决策树示例代码
- 五、关联规则挖掘示例代码
- 六、神经网络示例代码
- 七、支持向量机示例代码
- 八、聚类分析示例代码
- 九、主成分分析示例代码
- 十、时间序列分析示例代码
- 十一、集成学习示例代码
- 十二、异常检测示例代码
- 十三、自然语言处理示例代码
- 十四、归纳知识点
系列博文目录
Python自动化办公库技术点案例示例系列
博文目录
前言


在对大学生数据分析和数据挖掘时,会接触到许多重要的算法,这些算法代表了数据分析和数据挖掘领域中的一些核心技术,大学生可以通过学习和实践这些算法为代表的核心技术来提升自己的数据分析能力和数据挖掘探索分析能力。深入理解这些算法为代表的核心技术的原理和应用场景,将有助于他们在未来的学术研究或职业发展中取得成功。
一、重要算法介绍

以下是几个重要算法的概括介绍:
-
回归分析:
- 回归分析是一种用于探索变量之间关系的统计方法。在数据分析中,回归分析通常用于预测一个变量(因变量)如何受其他变量(自变量)影响。线性回归是最常见的形式,但还有其他类型的回归,如逻辑回归用于分类问题。
-
聚类分析:
- 聚类分析是一种无监督学习方法,用于将数据集中的对象分组成具有相似特征的簇。聚类分析有助于发现数据中的隐藏模式和结构,以便更好地理解数据。
-
决策树:
- 决策树是一种用于建立预测模型的监督学习方法。它通过一系列的分裂节点来构建树状模型,以便对数据进行分类或预测。决策树易于理解和解释,适用于各种领域。
-
关联规则挖掘:
- 关联规则挖掘是一种用于发现数据集中项目之间关联关系的技术。这种方法通常用于市场篮分析和推荐系统中,以发现项目之间的频繁关联规则。
-
神经网络:
- 神经网络是一种模仿人类大脑神经元网络结构的机器学习模型。它可以用于解决复杂的模式识别和预测问题。深度学习是神经网络的一种特殊形式,具有多层结构,适用于处理大规模数据和复杂任务。
-
支持向量机(SVM):
- SVM是一种用于分类和回归分析的监督学习方法。它通过在特征空间中找到最佳超平面来进行分类,适用于线性和非线性问题。SVM在处理高维数据和小样本数据时表现出色。
-
聚类分析:
- 聚类分析是一种无监督学习方法,用于将数据集中的对象分组成具有相似特征的簇。聚类分析有助于发现数据中的隐藏模式和结构,以便更好地理解数据。
-
主成分分析(PCA):
- 主成分分析是一种常用的降维技术,用于发现数据集中的主要变化方向。通过将高维数据转换为低维表示,PCA有助于减少数据集的复杂性,同时保留数据中的重要信息。
-
时间序列分析:
- 时间序列分析是一种用于处理时间序列数据的方法,旨在揭示数据随时间变化的模式和趋势。时间序列分析可用于预测未来趋势、季节性变化和周期性波动,对金融、经济等领域具有重要意义。
-
集成学习:
- 集成学习是一种结合多个模型来提高预测准确性的技术。常见的集成方法包括随机森林、梯度提升机等,通过组合多个弱分类器或回归器来构建一个更强大的模型。
-
异常检测:
- 异常检测是一种识别数据集中异常值或异常模式的技术。在数据分析中,异常检测有助于发现数据中的异常行为、错误或异常事件,对于保障数据质量和安全性非常重要。
-
自然语言处理(NLP):
- 自然语言处理是一种处理和分析人类语言的技术。在数据挖掘中,NLP可用于文本分类、情感分析、实体识别等任务,帮助理解和利用大量的文本数据。
这些算法在数据分析和数据挖掘领域中具有重要作用,掌握这些算法将有助于大学生更好地理解和应用数据,提升数据分析能力和数据挖掘探索分析能力,并为未来的学术和职业发展打下坚实基础。
二、回归分析示例代码
- 线性回归示例代码
当涉及到和大学生数据相关的线性回归示例时,我们可以考虑一个更贴近学生生活的示例,比如成绩预测。以下是一个简单的示例代码,演示如何使用线性回归模型预测学生的期末成绩:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 创建示例数据集
data = {
'hours_studied': [3, 4, 2, 5, 7, 6, 8, 5, 4, 6],
'hours_slept': [8, 7, 9, 6, 5, 7, 6, 5, 6, 4],
'final_grade': [75, 80, 65, 85, 90, 88, 92, 86, 82, 78]
}
df = pd.DataFrame(data)
# 特征和目标变量
X = df[['hours_studied', 'hours_slept']]
y = df['final_grade']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
print('Mean Squared Error:', mse)
在这个示例中,我们使用了学生的学习时间(hours_studied)和睡眠时间(hours_slept)作为特征,来预测学生的期末成绩(final_grade)。代码首先创建了示例数据集,然后将数据划分为特征和目标变量,接着将数据集划分为训练集和测试集。然后,使用线性回归模型在训练集上进行训练,并在测试集上进行成绩预测,最后评估模型性能。
这个示例更贴近大学生的实际情境,展示了如何应用线性回归模型来预测学生的期末成绩。你可以根据实际情况和数据集进行调整和扩展。
- 逻辑回归示例代码
以下是一个逻辑回归的示例代码,假设我们想要使用学生的学习时间和睡眠时间来预测他们是否通过考试(二分类问题):
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
# 创建示例数据集
data = {
'hours_studied': [3, 4, 2, 5, 7, 6, 8, 5, 4, 6],
'hours_slept': [8, 7, 9, 6, 5, 7, 6, 5, 6, 4],
'passed_exam': [0, 1, 0, 1, 1, 1, 1, 1, 1, 0] # 1表示通过考试,0表示未通过
}
df = pd.DataFrame(data)
# 特征和目标变量
X = df[['hours_studied', 'hours_slept']]
y = df['passed_exam']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
# 输出混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
在这个示例中,我们使用了学生的学习时间(hours_studied)和睡眠时间(hours_slept)作为特征,来预测学生是否通过考试(passed_exam)。代码首先创建了示例数据集,然后将数据划分为特征和目标变量,接着将数据集划分为训练集和测试集。然后,使用逻辑回归模型在训练集上进行训练,并在测试集上进行预测,最后计算模型的准确率并输出混淆矩阵。
逻辑回归常用于二分类问题,可以帮助预测学生是否通过考试等情况。你可以根据实际情况和数据集进行调整和扩展,以适应不同的预测问题。
三、聚类分析示例代码
- K均值(K-means)聚类算法示例代码
以下是一个使用K均值(K-means)聚类算法进行大学生数据分析的示例代码:
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'math_score': [85, 92, 78, 88, 94, 87, 80, 75, 92, 89],
'english_score': [88, 78, 85, 80, 92, 90, 83, 79, 87, 82]
}
df = pd.DataFrame(data)
# 特征缩放
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df[['math_score', 'english_score']])
# 创建并训练K均值聚类模型
kmeans = KMeans(n_clusters=2, random_state=42)
kmeans.fit(df_scaled)
# 将聚类结果添加到数据集中
df['cluster'] = kmeans.labels_
# 可视化聚类结果
plt.scatter(df['math_score'], df['english_score'], c=df['cluster'], cmap='viridis')
plt.xlabel('Math Score')
plt.ylabel('English Score')
plt.title('K-means Clustering of Student Data')
plt.show()
在这个示例中,我们使用了学生的数学成绩(math_score)和英语成绩(english_score)作为特征进行聚类分析。首先,我们对特征进行了标准化处理,然后使用K均值聚类算法将学生分成两个簇。最后,我们将聚类结果可视化展示出来。
你可以根据实际情况和需求调整聚类的簇数、特征、数据集等,以便进行更深入和个性化的数据分析和挖掘工作。聚类分析可以帮助你发现数据中的潜在模式和群体,为进一步的数据解释和决策提供参考。
- 调整不同的参数和数据进行聚类分析示例代码
当进行聚类分析时,可以根据实际情况和需求调整不同的参数和数据,以实现更深入和个性化的数据分析和挖掘工作。以下是一个更通用的示例代码,演示如何根据不同的参数和数据进行聚类分析:
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'math_score': [85, 92, 78, 88, 94, 87, 80, 75, 92, 89],
'english_score': [88, 78, 85, 80, 92, 90, 83, 79, 87, 82],
'science_score': [90, 85, 88, 92, 78, 85, 80, 83, 89, 91]
}
df = pd.DataFrame(data)
# 选择特征并进行特征缩放
features = ['math_score', 'english_score', 'science_score']
scaler = StandardScaler()
df_scaled = scaler.fit_transform(df[features])
# 创建并训练K均值聚类模型
num_clusters = 3 # 聚类簇数
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(df_scaled)
# 将聚类结果添加到数据集中
df['cluster'] = kmeans.labels_
# 可视化聚类结果
plt.figure(figsize=(8, 6))
for cluster_num in range(num_clusters):
cluster_data = df[df['cluster'] == cluster_num]
plt.scatter(cluster_data['math_score'], cluster_data['english_score'], label=f'Cluster {cluster_num}')
plt.xlabel('Math Score')
plt.ylabel('English Score')
plt.title('K-means Clustering of Student Data')
plt.legend()
plt.show()
在这个通用示例中,我们扩展了特征,添加了科学成绩(science_score),并调整了聚类簇数为3。你可以根据具体需求选择不同的特征、聚类簇数以及数据集,以实现更加个性化和深入的数据分析和挖掘工作。这样的灵活性可以帮助你更好地理解数据中的潜在模式和群体,为进一步的数据解释和决策提供更多参考。
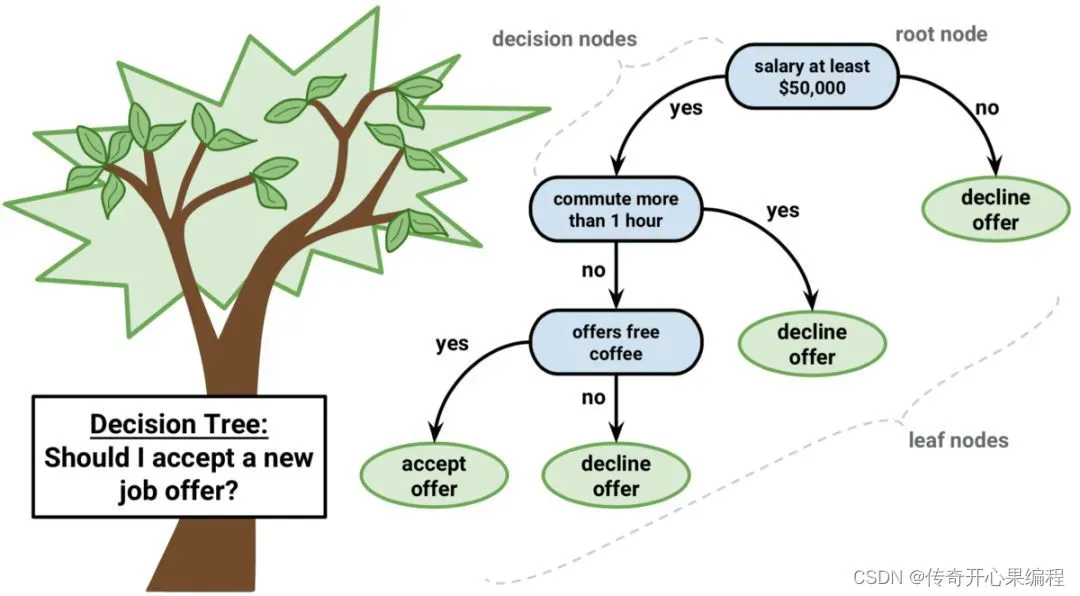
四、决策树示例代码
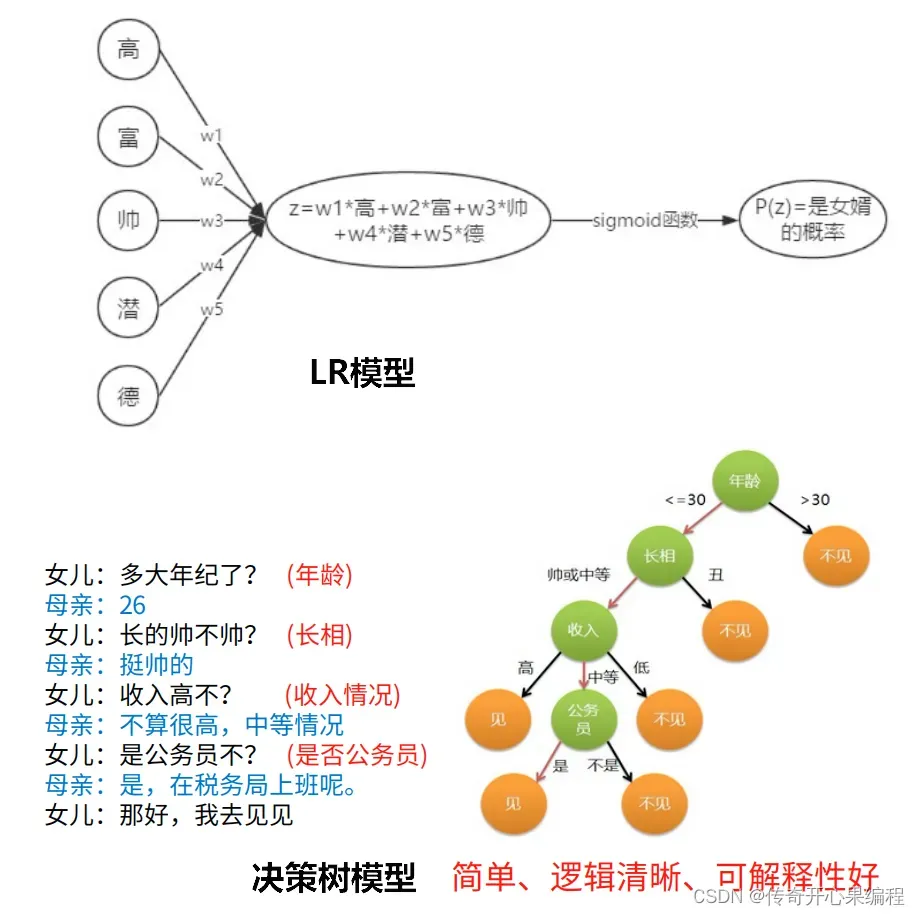
- 决策树算法示例代码
以下是一个示例代码,演示如何使用决策树算法对大学生数据进行数据分析和数据挖掘:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'math_score': [85, 92, 78, 88, 94, 87, 80, 75, 92, 89],
'english_score': [88, 78, 85, 80, 92, 90, 83, 79, 87, 82],
'pass_exam': [1, 0, 1, 0, 1, 1, 0, 0, 1, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 定义特征和目标变量
X = df[['math_score', 'english_score']]
y = df['pass_exam']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型
dt_classifier = DecisionTreeClassifier(random_state=42)
dt_classifier.fit(X_train, y_train)
# 预测测试集
y_pred = dt_classifier.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Confusion Matrix:\n{conf_matrix}')
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(dt_classifier, feature_names=X.columns, class_names=['Fail', 'Pass'], filled=True)
plt.show()
在这个示例中,我们使用了决策树算法对大学生数据进行分析,预测学生是否通过考试。你可以根据实际情况和数据集的特点,调整特征、目标变量以及模型参数,以实现更加个性化和深入的数据分析和挖掘工作。决策树模型可以帮助你理解数据中的模式和关系,为进一步的数据解释和决策提供更多参考。
- 调整特征、目标变量以及模型参数示例代码
当涉及到个性化和深入的数据分析和挖掘工作时,你可以根据具体情况调整特征、目标变量以及模型参数。以下是一个更加灵活和通用的示例代码,演示如何根据实际情况调整特征、目标变量和模型参数,以实现个性化的数据分析和挖掘工作:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 读取数据集(这里以一个虚拟数据集为例)
data = {
'student_id': [1, 2, 3, 4, 5],
'feature1': [10, 20, 15, 25, 30],
'feature2': [3, 7, 5, 9, 11],
'target_variable': ['A', 'B', 'A', 'B', 'A'] # 例如,A和B可以是不同的类别
}
df = pd.DataFrame(data)
# 选择特征和目标变量
X = df[['feature1', 'feature2']]
y = df['target_variable']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型并调整参数
dt_classifier = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
dt_classifier.fit(X_train, y_train)
# 预测测试集
y_pred = dt_classifier.predict(X_test)
# 模型评估
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Confusion Matrix:\n{conf_matrix}')
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(dt_classifier, feature_names=X.columns, class_names=dt_classifier.classes_, filled=True)
plt.show()
这个示例代码展示了如何根据实际情况调整特征、目标变量以及模型参数,以实现更加个性化和深入的数据分析和挖掘工作。你可以根据自己的数据集和需求,灵活选择特征、目标变量以及调整决策树模型的参数,以更好地理解数据中的模式和关系,为进一步的数据解释和决策提供更多参考。
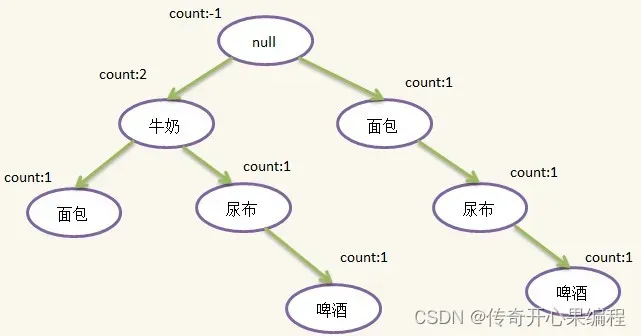
五、关联规则挖掘示例代码
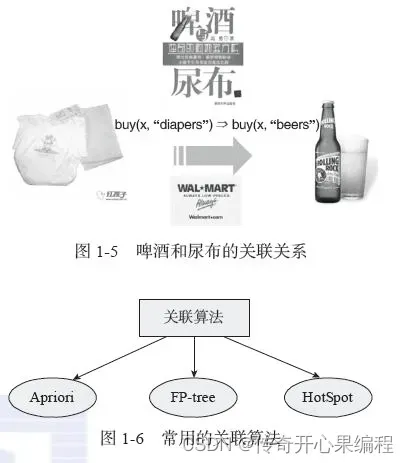
- 关联规则挖掘示例代码
以下是一个示例代码,演示如何使用关联规则挖掘算法(Apriori算法)对大学生数据进行关联规则挖掘:
# 导入必要的库
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5],
'math_score': [85, 92, 78, 88, 94],
'english_score': [88, 78, 85, 80, 92],
'pass_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 对数据进行独热编码
df_onehot = pd.get_dummies(df, columns=['math_score', 'english_score'])
# 使用Apriori算法进行频繁项集挖掘
frequent_itemsets = apriori(df_onehot, min_support=0.2, use_colnames=True)
# 根据频繁项集生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print("频繁项集:")
print(frequent_itemsets)
print("\n关联规则:")
print(rules)
在这个示例中,我们使用了Apriori算法对大学生数据进行关联规则挖掘。你可以根据实际数据集的特点和需求,调整参数如min_support和min_threshold,以获得符合实际情况的频繁项集和关联规则。关联规则挖掘可以帮助你发现数据中的潜在关联和规律,为进一步的数据分析和决策提供更多见解。
- 调整参数,并进行关联规则挖掘示例代码
当调整参数如min_support和min_threshold时,可以根据实际数据集的特点和需求,以获得符合实际情况的频繁项集和关联规则。以下是一个示例代码,演示如何根据实际情况调整参数,并进行关联规则挖掘:
# 导入必要的库
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5],
'subject_A': [1, 0, 1, 1, 0],
'subject_B': [1, 1, 0, 1, 0],
'subject_C': [0, 1, 1, 0, 1]
}
df = pd.DataFrame(data)
# 使用Apriori算法进行频繁项集挖掘
frequent_itemsets = apriori(df.drop(columns=['student_id']), min_support=0.3, use_colnames=True)
# 根据频繁项集生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.6)
print("频繁项集:")
print(frequent_itemsets)
print("\n关联规则:")
print(rules)
在这个示例中,我们根据实际数据集的特点和需求,调整了min_support参数为0.3,min_threshold参数为0.6,以获取符合实际情况的频繁项集和关联规则。你可以根据具体情况灵活调整这些参数,以发现数据中的潜在关联和规律,为进一步的数据分析和决策提供更多见解。
六、神经网络示例代码
- 神经网络示例代码
以下是一个示例代码,演示如何使用神经网络对大学生数据进行分析和预测,以预测学生是否通过考试:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5],
'math_score': [85, 92, 78, 88, 94],
'english_score': [88, 78, 85, 80, 92],
'pass_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math_score', 'english_score']]
y = df['pass_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建神经网络模型
model = MLPClassifier(hidden_layer_sizes=(50, 50), max_iter=1000, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,我们使用了多层感知器(MLP)神经网络模型对大学生数据进行分析和预测。你可以根据实际数据集的特点和需求,调整神经网络模型的参数如hidden_layer_sizes、max_iter等,以获得更好的预测效果。神经网络模型可以帮助你对数据进行深入分析和预测,为进一步的数据挖掘工作提供更多见解。

- 调整神经网络模型的参数示例代码
当调整神经网络模型的参数以获得更好的预测效果时,可以根据实际数据集的特点和需求,调整参数如hidden_layer_sizes、max_iter等。以下是一个示例代码,演示如何根据实际情况调整神经网络模型的参数:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5],
'math_score': [85, 92, 78, 88, 94],
'english_score': [88, 78, 85, 80, 92],
'pass_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math_score', 'english_score']]
y = df['pass_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建神经网络模型并调整参数
model = MLPClassifier(hidden_layer_sizes=(100, 50), max_iter=2000, random_state=42) # 调整hidden_layer_sizes和max_iter参数
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,我们根据实际数据集的特点和需求,调整了神经网络模型的参数,包括hidden_layer_sizes=(100, 50)和max_iter=2000。你可以根据具体情况灵活调整这些参数,以获得更好的预测效果。神经网络模型可以帮助你对数据进行深入分析和预测,为进一步的数据挖掘工作提供更多见解。
七、支持向量机示例代码

- 支持向量机示例代码
以下是一个示例代码,演示如何使用支持向量机(Support Vector Machine, SVM)对大学生数据进行分析和预测,以预测学生是否通过考试:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5],
'math_score': [85, 92, 78, 88, 94],
'english_score': [88, 78, 85, 80, 92],
'pass_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math_score', 'english_score']]
y = df['pass_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建SVM模型
model = SVC(kernel='linear', C=1.0, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,我们使用了支持向量机(SVM)模型对大学生数据进行分析和预测。你可以根据实际数据集的特点和需求,调整SVM模型的参数如kernel、C等,以获得更好的预测效果。支持向量机是一种强大的分类算法,在处理小样本、高维度数据和非线性数据时表现优秀,可以帮助你进行数据分析和挖掘工作,发现数据中的模式和关系。
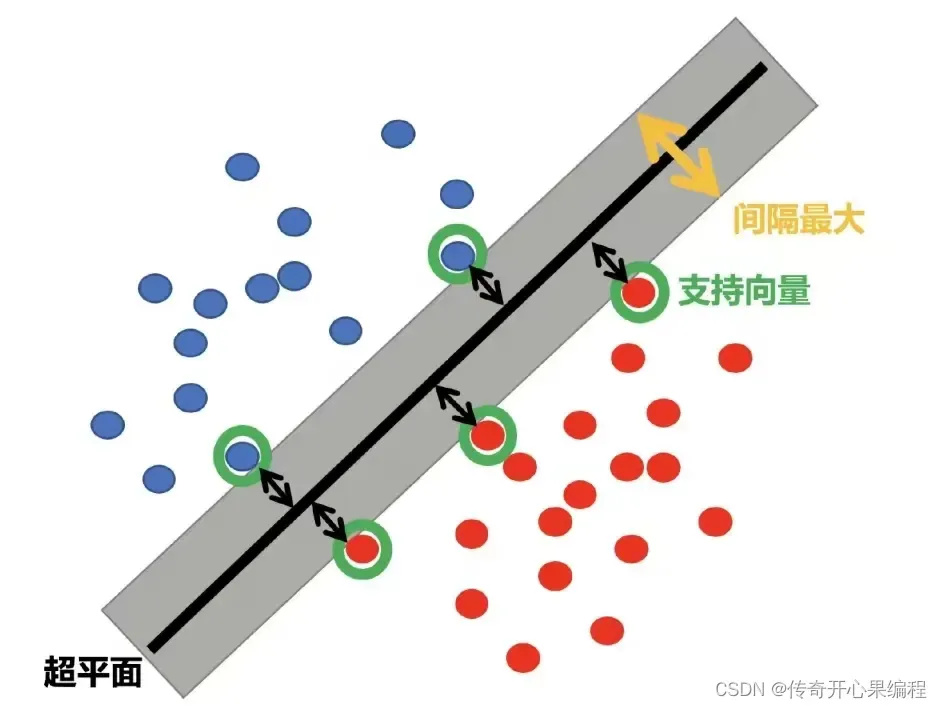
- 调整SVM模型的参数示例代码
当调整SVM模型的参数时,你可以根据实际数据集的特点和需求进行优化。以下是一个重写的示例代码,展示如何根据实际情况调整SVM模型的参数来获得更好的预测效果:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5],
'math_score': [85, 92, 78, 88, 94],
'english_score': [88, 78, 85, 80, 92],
'pass_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math_score', 'english_score']]
y = df['pass_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建SVM模型
# 你可以根据实际情况调整以下参数来优化模型
# kernel: 核函数,可以选择'linear', 'poly', 'rbf', 'sigmoid'等
# C: 惩罚参数,控制间隔的硬度,值越大表示对误分类样本的惩罚越大
model = SVC(kernel='rbf', C=1.0, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,你可以根据实际情况调整kernel和C等参数来优化SVM模型,以获得更好的预测效果。你可以尝试不同的核函数和惩罚参数,根据数据集的特点进行调整,以找到最适合的模型参数组合,从而提高预测准确性。
八、聚类分析示例代码
- 聚类分析示例代码
以下是一个示例代码,演示如何对大学生数据进行聚类分析,以发现数据中的潜在模式和群集:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 创建示例数据集
data = {
'student_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'math_score': [85, 92, 78, 88, 94, 70, 75, 89, 80, 85],
'english_score': [88, 78, 85, 80, 92, 70, 82, 79, 88, 90]
}
df = pd.DataFrame(data)
# 准备特征数据
X = df[['math_score', 'english_score']]
# 创建KMeans模型进行聚类分析
kmeans = KMeans(n_clusters=2, random_state=42) # 设置聚类簇数为2
# 训练KMeans模型
kmeans.fit(X)
# 获取每个样本的簇标签
clusters = kmeans.labels_
# 将簇标签添加到数据集中
df['cluster'] = clusters
# 可视化聚类结果
plt.figure(figsize=(8, 6))
plt.scatter(df['math_score'], df['english_score'], c=df['cluster'], cmap='viridis', s=50)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', label='Centroids')
plt.xlabel('Math Score')
plt.ylabel('English Score')
plt.title('Clustering of Student Data')
plt.legend()
plt.show()
这段代码将完成KMeans聚类分析,并将每个学生数据点根据所属簇进行可视化展示。簇中心点用红色标记。通过这种方式,你可以观察数据中的模式和群集,从而更好地理解大学生数据集的结构和关系。

- 扩展示例代码
当然,我可以帮你扩展示例代码,让它更加完整和有趣。以下是一个扩展示例,包括数据预处理、选择最佳聚类数、以及展示不同聚类数下的聚类效果:
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
# 数据预处理:标准化特征数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 选择最佳的聚类数
silhouette_scores = []
for n_clusters in range(2, 6):
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(X_scaled)
silhouette_avg = silhouette_score(X_scaled, cluster_labels)
silhouette_scores.append(silhouette_avg)
best_n_clusters = silhouette_scores.index(max(silhouette_scores)) + 2 # 获得最佳聚类数
# 重新训练KMeans模型
best_kmeans = KMeans(n_clusters=best_n_clusters, random_state=42)
best_kmeans.fit(X_scaled)
best_clusters = best_kmeans.labels_
df['best_cluster'] = best_clusters
# 可视化不同聚类数下的聚类效果
plt.figure(figsize=(16, 6))
for i, n_clusters in enumerate([2, 3, 4]):
plt.subplot(1, 3, i+1)
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
clusters = kmeans.fit_predict(X_scaled)
plt.scatter(X['math_score'], X['english_score'], c=clusters, cmap='viridis', s=50)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', label='Centroids')
plt.xlabel('Math Score')
plt.ylabel('English Score')
plt.title(f'Clustering with {n_clusters} clusters')
plt.legend()
plt.tight_layout()
plt.show()
这段代码扩展了示例,添加了数据预处理步骤、选择最佳聚类数的过程,并展示了不同聚类数下的聚类效果。通过这个扩展示例,你可以更全面地了解如何进行数据预处理、选择最佳聚类数,并比较不同聚类数对聚类效果的影响。
九、主成分分析示例代码
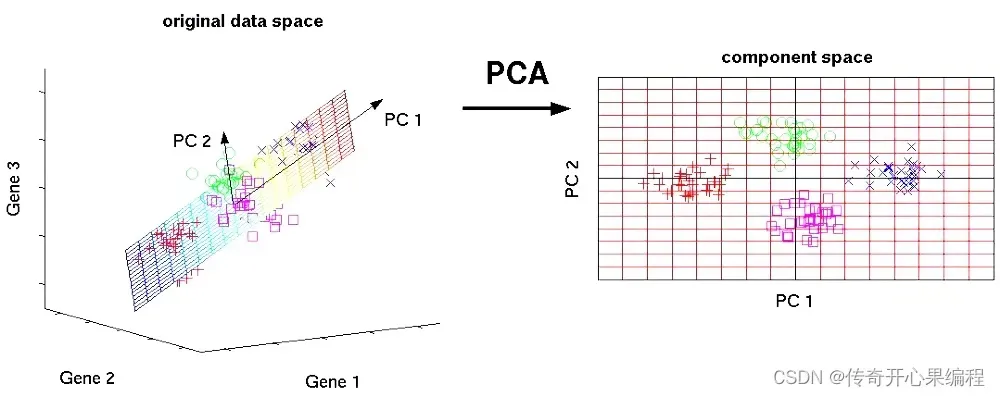
- 主成分分析示例代码
当涉及到大学生数据分析和数据挖掘时,主成分分析(PCA)是一个常用的技术,用于降维和发现数据中的模式。以下是一个示例代码,展示如何使用PCA对大学生数据进行降维处理:
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 假设X是包含大学生数据的特征矩阵
# 实例化PCA模型,选择要保留的主成分数量
n_components = 2 # 选择保留的主成分数量
pca = PCA(n_components=n_components)
# 对数据进行PCA降维处理
X_pca = pca.fit_transform(X)
# 可视化PCA降维后的数据
plt.figure(figsize=(8, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], s=50)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Student Data')
plt.show()
# 查看各主成分的解释方差比例
explained_variance_ratio = pca.explained_variance_ratio_
print("Explained Variance Ratio:")
for i, ratio in enumerate(explained_variance_ratio):
print(f"Principal Component {i+1}: {ratio}")
在这个示例中,我们使用PCA对大学生数据进行降维处理,并将数据可视化在二维空间中。通过查看各主成分的解释方差比例,我们可以了解每个主成分对数据方差的贡献程度。这有助于我们理解数据的结构并选择合适的主成分数量来保留最重要的信息。
- 扩展示例代码
当涉及到主成分分析(PCA)的示例代码时,我们可以进一步扩展代码,包括更详细的解释方差比例、可视化主成分和原始特征之间的关系,以及如何利用PCA降维后的数据进行后续分析。以下是一个扩展示例代码:
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟的大学生数据
X, _ = make_classification(n_samples=100, n_features=5, n_informative=3, n_redundant=1, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 实例化PCA模型,选择要保留的主成分数量
pca = PCA(n_components=2)
# 对数据进行PCA降维处理
X_pca = pca.fit_transform(X_scaled)
# 查看各主成分的解释方差比例
explained_variance_ratio = pca.explained_variance_ratio_
print("Explained Variance Ratio:")
for i, ratio in enumerate(explained_variance_ratio):
print(f"Principal Component {i+1}: {ratio}")
# 可视化主成分和原始特征之间的关系
plt.figure(figsize=(12, 6))
# 绘制原始特征与第一个主成分的关系
plt.subplot(1, 2, 1)
for feature in range(X.shape[1]):
plt.scatter(X_scaled[:, feature], X_pca[:, 0], label=f'Feature {feature + 1}')
plt.xlabel('Original Features')
plt.ylabel('Principal Component 1')
plt.title('Relationship between Original Features and PC1')
plt.legend()
# 绘制原始特征与第二个主成分的关系
plt.subplot(1, 2, 2)
for feature in range(X.shape[1]):
plt.scatter(X_scaled[:, feature], X_pca[:, 1], label=f'Feature {feature + 1}')
plt.xlabel('Original Features')
plt.ylabel('Principal Component 2')
plt.title('Relationship between Original Features and PC2')
plt.legend()
plt.tight_layout()
plt.show()
这段代码扩展了示例,包括生成模拟的大学生数据、数据标准化、查看各主成分的解释方差比例、可视化主成分和原始特征之间的关系等步骤。通过这个扩展示例,你可以更深入地了解主成分分析的应用和效果。
十、时间序列分析示例代码

- 时间序列分析示例代码
在进行大学生数据分析和数据挖掘时,时间序列分析是一个常用的技术,用于揭示数据随时间变化的模式和趋势。以下是一个简单的时间序列分析示例代码,展示如何使用Python中的Pandas和Matplotlib库对大学生数据进行时间序列分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建模拟的大学生数据
np.random.seed(42)
dates = pd.date_range(start='2024-01-01', periods=100, freq='D')
scores = np.random.randint(60, 100, size=100)
# 创建时间序列DataFrame
data = pd.DataFrame({'Date': dates, 'Score': scores})
data.set_index('Date', inplace=True)
# 可视化时间序列数据
plt.figure(figsize=(12, 6))
plt.plot(data.index, data['Score'], marker='o')
plt.xlabel('Date')
plt.ylabel('Score')
plt.title('Student Scores Over Time')
plt.grid(True)
plt.show()
在这个示例中,我们生成了一个模拟的大学生数据集,其中包含了日期和分数。然后,我们使用Pandas库创建了一个时间序列DataFrame,并利用Matplotlib库将学生分数随时间变化的趋势可视化出来。
这只是一个简单的时间序列分析示例,你可以根据实际情况进一步扩展分析,比如季节性分析、趋势分析、周期性分析等。

- 扩展示例代码
当涉及到时间序列分析时,我们可以进一步扩展示例代码,包括趋势分析、季节性分析、移动平均线等。以下是一个扩展示例代码,展示了如何进行简单的移动平均线计算和季节性分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建模拟的大学生数据
np.random.seed(42)
dates = pd.date_range(start='2024-01-01', periods=100, freq='D')
scores = np.random.randint(60, 100, size=100)
# 创建时间序列DataFrame
data = pd.DataFrame({'Date': dates, 'Score': scores})
data.set_index('Date', inplace=True)
# 计算并绘制移动平均线
data['MA_7'] = data['Score'].rolling(window=7).mean()
# 季节性分析
data['Month'] = data.index.month
seasonal_data = data.groupby('Month')['Score'].mean()
# 可视化时间序列数据、移动平均线和季节性趋势
plt.figure(figsize=(12, 8))
# 时间序列数据和移动平均线
plt.subplot(2, 1, 1)
plt.plot(data.index, data['Score'], label='Original Data', marker='o')
plt.plot(data.index, data['MA_7'], label='7-Day Moving Average', color='red')
plt.xlabel('Date')
plt.ylabel('Score')
plt.title('Student Scores Over Time with 7-Day Moving Average')
plt.legend()
# 季节性分析
plt.subplot(2, 1, 2)
plt.bar(seasonal_data.index, seasonal_data.values, color='skyblue')
plt.xlabel('Month')
plt.ylabel('Average Score')
plt.title('Seasonal Analysis of Student Scores')
plt.xticks(np.arange(1, 13), ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])
plt.tight_layout()
plt.show()
这段代码扩展了示例,包括计算和绘制移动平均线,以及进行季节性分析。通过这个扩展示例,你可以更全面地了解时间序列分析中的一些常见技术和方法。
十一、集成学习示例代码

- 集成学习随机森林算法示例代码
集成学习是一种强大的机器学习技术,可以通过结合多个模型的预测结果来提高整体预测性能。以下是一个示例代码,展示如何在大学生数据分析中应用集成学习技术(以随机森林为例):
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取大学生数据集,假设包含特征和目标变量
data = pd.read_csv('student_data.csv')
# 假设数据集包含特征列 X 和目标列 y
X = data.drop('Target', axis=1)
y = data['Target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_classifier.fit(X_train, y_train)
# 预测
y_pred = rf_classifier.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 可以根据需要进一步优化参数、尝试其他集成学习算法等
在这个示例中,我们使用了随机森林分类器作为集成学习模型,对大学生数据集进行分类任务。你可以根据实际情况调整代码中的数据读取部分,确保数据集的特征和目标变量正确加载。此外,你还可以根据需要对模型进行参数调优、尝试其他集成学习算法(如梯度提升树、AdaBoost等)来进一步提高预测性能。

- 集成学习梯度提升树算法示例代码
以下是一个示例代码,展示了如何在大学生数据分析中使用梯度提升树(Gradient Boosting)作为集成学习算法:
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取大学生数据集,假设包含特征和目标变量
data = pd.read_csv('student_data.csv')
# 假设数据集包含特征列 X 和目标列 y
X = data.drop('Target', axis=1)
y = data['Target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化梯度提升树分类器
gb_classifier = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
# 训练模型
gb_classifier.fit(X_train, y_train)
# 预测
y_pred = gb_classifier.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 可以根据需要调整学习率、树的数量等参数,进一步优化模型
在这个示例中,我们使用了梯度提升树作为集成学习算法,对大学生数据集进行分类任务。你可以根据实际情况调整代码中的数据读取部分,确保数据集的特征和目标变量正确加载。此外,你还可以根据需要调整学习率、树的数量等参数来优化模型的性能。
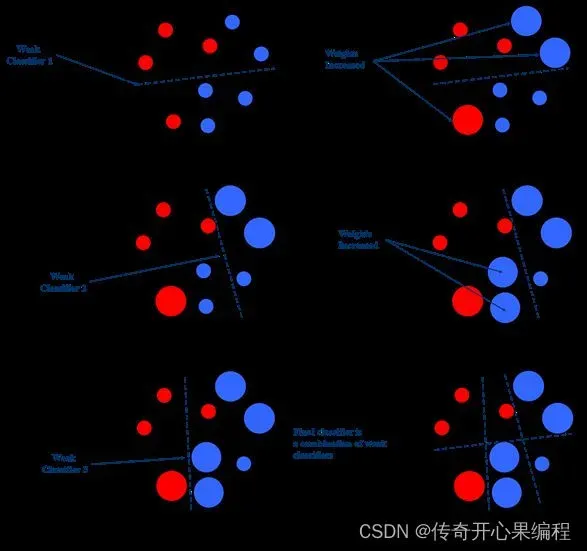
- 集成学习AdaBoost算法示例代码
以下是一个示例代码,展示了如何在大学生数据分析中使用AdaBoost算法作为集成学习算法:
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取大学生数据集,假设包含特征和目标变量
data = pd.read_csv('student_data.csv')
# 假设数据集包含特征列 X 和目标列 y
X = data.drop('Target', axis=1)
y = data['Target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化AdaBoost分类器
adaboost_classifier = AdaBoostClassifier(n_estimators=50, learning_rate=1.0, random_state=42)
# 训练模型
adaboost_classifier.fit(X_train, y_train)
# 预测
y_pred = adaboost_classifier.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 可以根据需要调整学习率、基本分类器数量等参数,进一步优化模型
在这个示例中,我们使用了AdaBoost算法作为集成学习算法,对大学生数据集进行分类任务。你可以根据实际情况调整代码中的数据读取部分,确保数据集的特征和目标变量正确加载。此外,你还可以根据需要调整学习率、基本分类器数量等参数来优化模型的性能。
十二、异常检测示例代码
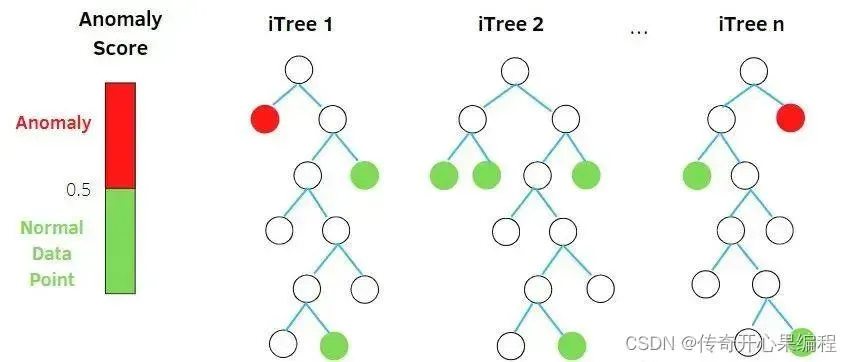
- 异常检测的孤立森林算法示例代码
以下是一个简单的示例代码,演示了如何在大学生数据集中使用孤立森林(Isolation Forest)算法进行异常检测:
import pandas as pd
from sklearn.ensemble import IsolationForest
# 读取大学生数据集,假设包含特征
data = pd.read_csv('student_data.csv')
# 假设数据集包含特征列 X
X = data.drop('Target', axis=1)
# 初始化孤立森林模型
isolation_forest = IsolationForest(contamination=0.05, random_state=42)
# 训练模型
isolation_forest.fit(X)
# 预测样本是否为异常值
predictions = isolation_forest.predict(X)
# 将预测结果转换为正常值(1)和异常值(-1)
predictions[predictions == 1] = 0 # 正常值
predictions[predictions == -1] = 1 # 异常值
# 将预测结果添加到原始数据集中
data['Anomaly'] = predictions
# 打印异常检测结果
print(data[data['Anomaly'] == 1])
# 可以根据实际情况调整异常检测的参数和阈值,进一步优化模型
在这个示例中,我们使用了孤立森林算法对大学生数据集中的异常值进行检测。你可以根据实际情况调整代码中的数据读取部分,确保数据集的特征正确加载。此外,你还可以根据需要调整孤立森林模型的参数(如contamination)来优化异常检测的性能。
- 调整数据读取部分调整模型参数示例代码
以下是调整过的示例代码,包括了数据读取部分和孤立森林模型参数的调整:
import pandas as pd
from sklearn.ensemble import IsolationForest
# 读取包含大学生数据的CSV文件,确保文件路径正确
data = pd.read_csv('your_student_data.csv')
# 假设数据集包含特征列 X 和目标列 Target
X = data.drop('Target', axis=1)
# 初始化孤立森林模型
# 调整contamination参数来控制异常值的比例,可以根据实际情况进行调整
isolation_forest = IsolationForest(contamination=0.1, random_state=42)
# 训练模型
isolation_forest.fit(X)
# 预测样本是否为异常值
predictions = isolation_forest.predict(X)
# 将预测结果转换为正常值(1)和异常值(-1)
predictions[predictions == 1] = 0 # 正常值
predictions[predictions == -1] = 1 # 异常值
# 将预测结果添加到原始数据集中
data['Anomaly'] = predictions
# 打印异常检测结果
print(data[data['Anomaly'] == 1])
# 可以根据实际情况进一步调整数据读取和孤立森林模型的参数,以优化异常检测的性能
在这个示例中,你需要将your_student_data.csv替换为你实际使用的大学生数据集文件名,并确保文件路径正确。同时,你可以根据实际情况调整contamination参数来控制异常值的比例,以及根据需要进一步调整其他模型参数来优化异常检测的性能。
十三、自然语言处理示例代码

- 支持向量机分类器自然语言处理示例代码
以下是一个简单的示例代码,演示了如何在大学生数据集上使用自然语言处理(Natural Language Processing)技术,具体是文本分类任务:
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 读取包含大学生数据的CSV文件,确保文件路径正确
data = pd.read_csv('your_student_text_data.csv')
# 假设数据集包含文本数据和对应的标签
X = data['Text']
y = data['Label']
# 将文本数据转换为TF-IDF特征向量
vectorizer = TfidfVectorizer()
X_tfidf = vectorizer.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.2, random_state=42)
# 初始化支持向量机分类器
svm = SVC()
# 训练模型
svm.fit(X_train, y_train)
# 预测测试集
predictions = svm.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print("准确率:", accuracy)
# 可以根据需要尝试其他NLP技术、调整模型参数或尝试不同的分类器来优化文本分类性能
在这个示例中,你需要将your_student_text_data.csv替换为你实际使用的包含文本数据的大学生数据集文件名,并确保文件路径正确。代码使用TF-IDF特征向量化文本数据,并训练一个支持向量机分类器进行文本分类。你可以根据需要尝试其他NLP技术、调整模型参数或尝试不同的分类器来优化文本分类性能。
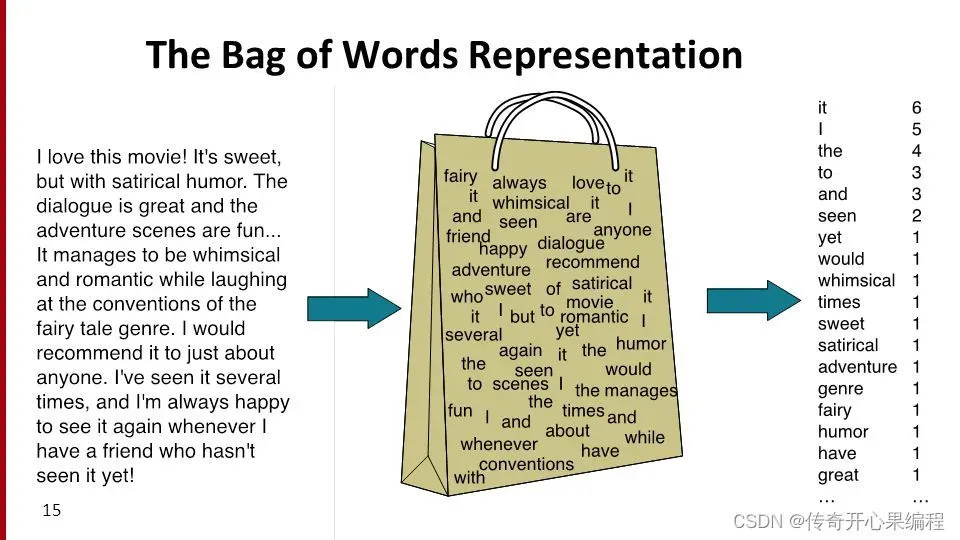
- 词袋模型和随机森林分类器自然语言处理示例代码
以下是一个示例代码,展示如何使用词袋模型(Bag of Words)和随机森林分类器来进行文本分类。你可以根据需要尝试不同的NLP技术、调整模型参数或尝试其他分类器来优化文本分类性能:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取包含大学生数据的CSV文件,确保文件路径正确
data = pd.read_csv('your_student_text_data.csv')
# 假设数据集包含文本数据和对应的标签
X = data['Text']
y = data['Label']
# 将文本数据转换为词袋模型特征向量
vectorizer = CountVectorizer()
X_bow = vectorizer.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_bow, y, test_size=0.2, random_state=42)
# 初始化随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_classifier.fit(X_train, y_train)
# 预测测试集
predictions = rf_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print("准确率:", accuracy)
# 可以尝试调整词袋模型参数、随机森林分类器参数或尝试其他NLP技术和分类器来优化文本分类性能
在这个示例中,我们使用词袋模型和随机森林分类器进行文本分类。你可以尝试调整词袋模型的参数、随机森林分类器的参数,或者尝试其他NLP技术(如TF-IDF、Word2Vec等)和分类器(如支持向量机、朴素贝叶斯等)来优化文本分类性能。
十四、归纳知识点

数据分析和数据挖掘领域涉及多种核心技术,以下是几个重要方法的总结:
-
数据预处理:
-缺失值处理:填充缺失值、删除包含缺失值的样本或特征。
-数据清洗:处理异常值、重复值、噪声数据。
-特征工程:特征选择、特征提取、特征转换、特征组合。 -
机器学习算法:
-监督学习:包括回归、分类任务,常见算法有线性回归、逻辑回归、决策树、随机森林、支持向量机等。
-无监督学习:包括聚类、降维任务,常见算法有K均值聚类、层次聚类、主成分分析(PCA)、t-SNE等。
-强化学习:Agent与环境交互学习,通过奖励机制优化决策策略。 -
文本挖掘(文本数据分析):
-词袋模型(Bag of Words):将文本转换为词频向量。
-TF-IDF(Term Frequency-Inverse Document Frequency):衡量词语在文档中的重要性。
-Word2Vec:将单词映射到高维度的稠密向量空间。
-文本分类:将文本文档分为不同类别,常用算法有朴素贝叶斯、支持向量机、深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)等。 -
图像处理与计算机视觉:
-特征提取:使用卷积神经网络(CNN)进行特征提取。
-目标检测:常见算法有YOLO(You Only Look Once)、Faster R-CNN等。
-图像分类:使用CNN等模型进行图像分类任务。 -
时间序列分析:
-预测与建模:使用ARIMA(自回归积分移动平均模型)、LSTM(长短期记忆网络)等模型进行时间序列预测。
-季节性分析:分析时间序列数据中的季节性变化。 -
异常检测:
-基于统计方法:如箱线图、Z分数等。
-机器学习方法:使用聚类、孤立森林(Isolation Forest)等算法进行异常检测。
以上是数据分析和数据挖掘中的一些核心技术知识点和方法,这些方法可以帮助处理和分析不同类型的数据,从而提取有用的信息和知识。如有任何问题或需要进一步了解,请随时告诉我!
版权声明:本文为博主作者:传奇开心果编程原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/jackchuanqi/article/details/136752032