层次分析法(The analytic hierarachy process,简称AHP)是一种常用的决策分析方法,其基本思路是将复杂问题分解为多个组成部分,然后对这些部分进行逐一评估和比较,最后得出最优解决方案。(例如:选择哪种方案最好、哪位运动员或员工表现得更优秀)
要解决评价类问题,要解决以下三个问题:
1、我们评价的目标是什么?
2、我们为了达到这个目标有哪几种可选方案?
3、评价的准则或者说指标是什么?
一般来说,前两个问题的答案是显而易见的,第三个问题的答案需要我们根据题目中的背景材料、常识或者网上搜集到的参考资料进行结合,从中筛选最合适的指标。
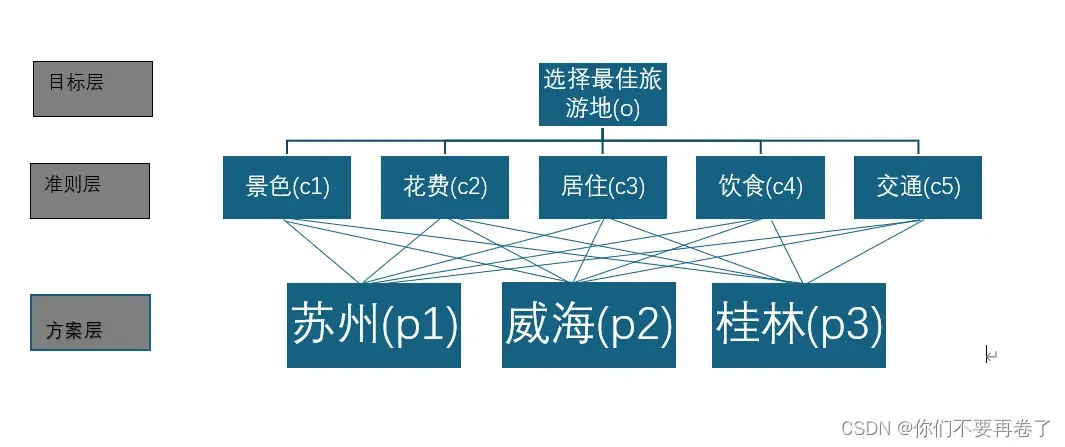
案例:请选择合适的指标,为小明选取一个最适合他的城市。
本题需要我们选择最优的旅游城市,首先上网搜索几个比较重要的指标:景点景色、旅游花费、居住环境、饮食情况、交通便利程度。选取想去的城市分别为:苏州、威海、桂林。我们先来绘制一张权重表。
指标权重 |
苏州 |
威海 |
桂林 |
|
|
景色 |
||||
花费 |
||||
居住 |
||||
饮食 |
||||
交通 |
现在的关键就是求出这张权重表。
确定影响某因素的诸因子在该因素中所占的比重时,遇到的主要困难是这些比重常常不易定量化。此外,当影响某因素的因子较多时,直接考虑各因子对该因素有多大程度的影响时,常常会因考虑不周全、顾此失彼而使决策者提出与他实际认为的重要性程度不相一致的数据,甚至有可能提出一组隐含矛盾的数据。
–选自司守奎[kuil老师的《数学建模算法与应用教材》
一次性去考虑五个指标的关系,往往考虑不周;而两个两个指标进行比较,最终根据两两比较的结果来推算出权重。
|
标度 |
含义 |
|
1 |
表示两个因素相比,具有相同重要性 |
|
3 |
表示两个因素相比,一个因素比另一个因素稍微重要 |
|
5 |
表示两个因素相比,一个因素比另一个因素明显重要 |
|
7 |
表示两个因素相比,一个因素比另一个因素强烈重要 |
|
9 |
表示两个因素相比,一个因素另一个因素极端重要 |
|
2,4,6,8 |
上述两相邻判断的中值 |
|
倒数 |
A和B相比如果标度3,那么B和A相比就是1/3 |
重要性可以理解为满意程度
景色 |
花费 |
居住 |
饮食 |
交通 |
|
|
景色 |
1 |
1/2 |
4 |
3 |
3 |
|
花费 |
2 |
1 |
7 |
5 |
5 |
|
居住 |
1/4 |
1/7 |
1 |
1/2 |
1/3 |
|
饮食 |
1/3 |
1/5 |
2 |
1 |
1 |
|
交通 |
1/3 |
1/5 |
3 |
1 |
1 |
我们知道景色与景色属于同一元素,满意程度为1,其他亦是如此(根据自己对这几个指标的判断确定权重)。
总结:上面这个表是一个5*5的方阵,我们记为A,对应的元素为aij,这个方针有如下特征:
(1)aij表示的意义是,与指标j相比,i的重要程度。
(2)当i=j时,两个指标相同,因此同等重要记为1,这就解释了主对角元素为1.
(3)aij>0且满足aij*aji=1(我们称满足这一条件的矩阵为正互反矩阵)
实际上,上面这个矩阵就是层次分析法中的判断矩阵。
接下来我们则需要填写5个判断矩阵(我们可以通过与小明一问一答的形式,来填写,当然在论文中我们直接给出即可)
| 景色 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 2 | 5 |
| 威海 | 1/2 | 1 | 2 |
| 桂林 | 1/5 | 1/2 | 1 |
| 花费 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 1/3 | 1/8 |
| 威海 | 3 | 1 | 1/3 |
| 桂林 | 8 | 3 | 1 |
| 居住 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 1 | 3 |
| 威海 | 1 | 1 | 3 |
| 桂林 | 1/3 | 1/3 | 1 |
| 饮食 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 3 | 4 |
| 威海 | 1/3 | 1 | 1 |
| 桂林 | 1/4 | 1 | 1 |
| 交通 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 1 | 1/4 |
| 威海 | 1 | 1 | 1/4 |
| 桂林 | 4 | 4 | 1 |
需要注意的是:在这里我们应该把表格里的数字理解为可接受度(即满意程度)。
我们在书写时也有可能会有bug。比如说:苏州=A 威海=B 桂林=C 苏州比威海景色好则A>B 苏州和桂林景色一样好则A=C 威海比桂林景色号则B>C如此便出现了矛盾
什么是一致矩阵呢?
| 景色 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 2 | 4 |
| 威海 | 1/2 | 1 | 2 |
| 桂林 | 1/4 | 1/2 | 1 |

也就说只要各行各列满足成倍数的关系即为一致矩阵
一致矩阵:若矩阵中每个元素 aij>0且满足 aij*aji=1,则我们称该矩阵为正互反矩阵。在层次分析法中,我们构造的判断矩阵均是正互反矩阵。若正互反矩阵满足aij*ajk=aik,则我们称其为一致矩阵。
注意:在使用判断矩阵求权重之前,必须对其进行一致性检验。

引理:n阶正互反矩阵A为一致矩阵时当且仅当最大特征值ℷmax=n且当正互反矩阵A非一致时,一定满足
ℷmax>n.
| 景色 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 2 | a |
| 威海 | 1/2 | 1 | 2 |
| 桂林 | 1/a | 1/2 | 1 |
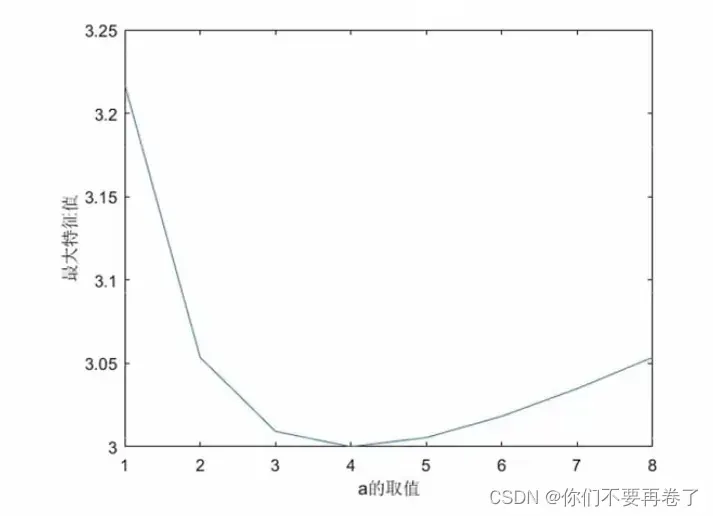
判断矩阵越不一致,最大特征值与n就相差越大
第一步:计算一致性指标
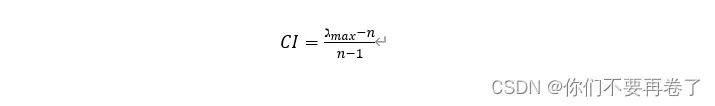
第二步:查找对应的平均随机一致性指标RI
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| RI | 0 | 0 | 0.52 | 0.89 | 1.12 | 1.26 | 1.36 | 1.41 | 1.46 | 1.49 | 1.52 | 1.54 | 1.56 | 1.58 | 1.59 |
注:在实际运用中,n很少超过10,如果指标的个数大于10,可以考虑建立二级指标体系
第三步:计算一致性比例CR
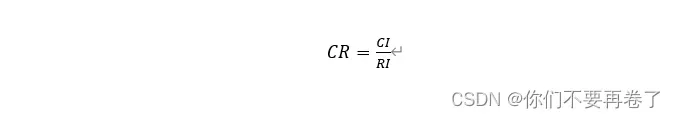
如果CR<0.1,则可认为判断矩阵的一致性可以接受;否则需对判断矩阵进行修正。
求指标权重及城市在各个指标上的得分
1、算数平均法
先对景色指标进行对第一列归一化处理,得出权重
苏州=1/(1+0.5+0.2)=0.5882
威海=0.5/(1+0.5+0.2)=0.2941
桂林=0.2/(1+0.5+0.2)=0.1177
使用第二列的数据,计算出来的权重
苏州=2/(2+1+0.5)=0.5714
威海=1/(2+1+0.5)=0.2857
桂林=0.5/(2+1+0.5)=0.1429
使用第三列数据,计算出来的权重
苏州=5/(5+2+1)=0.625
威海=2/(5+2+1)=0.25
桂林=1/(5+2+1)=0.125
综合上述三列,算术平均求权重:
苏州=(0.5882+0.5714+0.625)/3=0.5949
威海=(0.2941+0.2857+0.25)/3=0.2766
桂林=(0.1177+0.1429+0.125)/3=0.1285
基本步骤:将判断矩阵按照列归一化,将归一化的各列相加,最后将相加后得到的向量中每个元素除以n即可得到权重向量
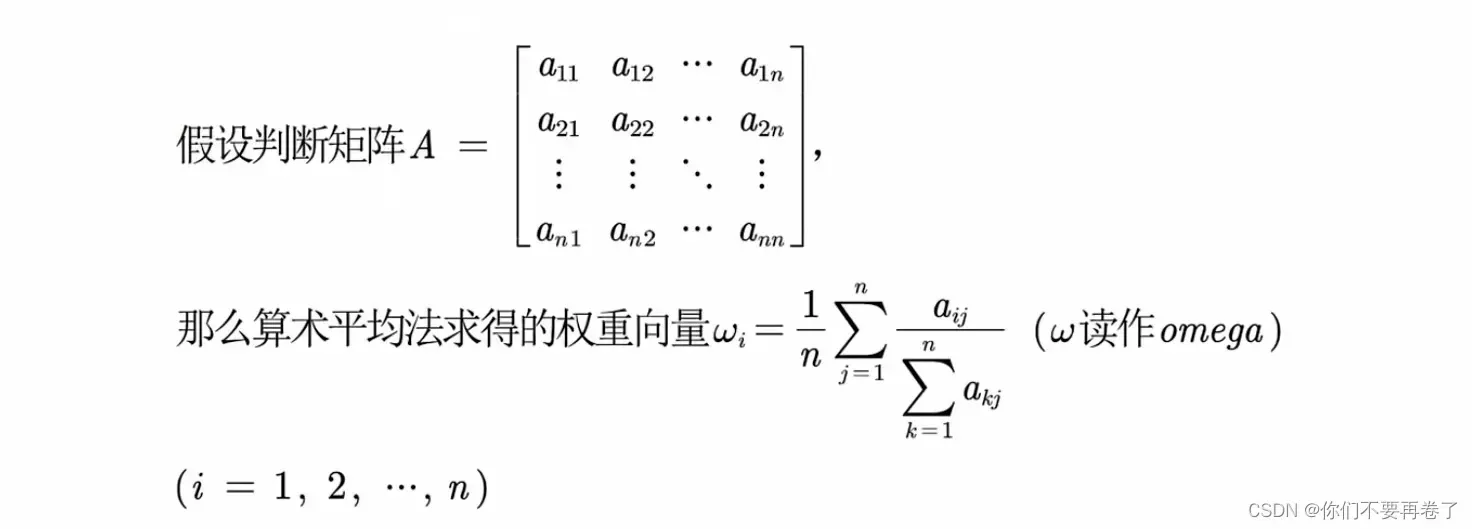
2、几何平均法
第一步:将A的元素按照行相乘得到一个新的列向量
第二步:将新的向量的每个分量开n次方
第三步:对该列向量进行归一化即可得到权重向量

| 算数平均法权重 | 几何平均法权重 | |
| 苏州 | 0.5949 | 0.5954 |
| 威海 | 0.2766 | 0.2764 |
| 桂林 | 0.1285 | 0.1283 |
注意:权重和应为1,这里由于四舍五入所以会有可以忽略的差距。
3、特征值法求权重

假若我们的判断矩阵一致性可以接受,那么我们可以仿照一致矩阵求权重的方法。
第一步:求出矩阵A的最大特征值以及其对应的特征向量
第二步:对求出的特征向量进行归一化即可得到我们的权重
| 景色 | 苏州 | 威海 | 桂林 |
| 苏州 | 1 | 2 | 5 |
| 威海 | 1/2 | 1 | 2 |
| 桂林 | 1/5 | 1/2 | 1 |
最大特征值为3.0055,一致性比例CR=0.0053对应的特征向量:[-0.8902,-0.4132,-0.1918]对其归一化:[0.5954,0.2764,0.1283]
| 算术平均法 | 几何平均法 | 特征值法 | |
| 苏州 | 0.5949 | 0.5954 | 0.5954 |
| 威海 | 0.2766 | 0.2764 | 0.2764 |
| 桂林 | 0.1285 | 0.1283 | 0.1283 |
以特征值法为例(我们可以借助MATLAB来求权重,下面我们会介绍到):
| 指标权重 | 苏州 | 威海 | 桂林 | |
| 景色 | 0.2636 | 0.5954 | 0.2764 | 0.1283 |
| 花费 | 0.4758 | 0.0819 | 0.2363 | 0.6817 |
| 居住 | 0.0538 | 0.4286 | 0.4286 | 0.1429 |
| 饮食 | 0.0981 | 0.6337 | 0.1919 | 0.1744 |
| 交通 | 0.1087 | 0.1667 | 0.1667 | 0.6667 |
此时我们便可以求出每一个城市的得分情况:
苏州=0.5954*0.2636+0.0819*0.4758+0.4286*0.0538+0.6337*0.0981+0.1667*0.1087=0.299
同理我们也可以得出剩下两个城市的得分情况为威海0.245,桂林0.455
因此我们就可以认为最佳旅游城市是桂林(可以用EXCELL简化运算)
以往的论文利用层次分析法解决实际问题时,都是采用其中某一种方法求权重,而不同的计算方法可能会导致结果有所偏差。为了保证结果的稳健性本文采用了三种方法分别求出了权重,再根据得到的权重矩阵计算各个方案的得分,并进行排序和综合分析,这样避免了采用单一方法所产生的偏差,得出的结论将更全面、更有效。
层次分析法的局限性:
(1)评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异可能会很大。(一般n最多不能超过15)
(2)如果决策层中的指标的数据是已知的,应该如何利用数据使得评价更准确?
因此层次分析法存在很大局限性。
下面我们来看代码部分内容:
disp('请输入判断矩阵A')
A=input('A=');
[n,n] = size(A);
% % % % % % % % % % % % %方法1: 算术平均法求权重% % % % % % % % % % % % %
Sum_A = sum(A);
SUM_A = repmat(Sum_A,n,1);
Stand_A = A ./ SUM_A;
disp('算术平均法求权重的结果为:');
disp(sum(Stand_A,2)./n)
% % % % % % % % % % % % %方法2: 几何平均法求权重% % % % % % % % % % % % %
Prduct_A = prod(A,2);
Prduct_n_A = Prduct_A .^ (1/n);
disp('几何平均法求权重的结果为:');
disp(Prduct_n_A ./ sum(Prduct_n_A))
% % % % % % % % % % % % %方法3: 特征值法求权重% % % % % % % % % % % % %
[V,D] = eig(A);
Max_eig = max(max(D));
[r,c]=find(D == Max_eig , 1);
disp('特征值法求权重的结果为:');
disp( V(:,c) ./ sum(V(:,c)) )
% % % % % % % % % % % % %下面是计算一致性比例CR的环节% % % % % % % % % % % % %
CI = (Max_eig - n) / (n-1);
RI=[0 0.0001 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; %注意哦,这里的RI最多支持 n = 15
% 这里n=2时,一定是一致矩阵,所以CI = 0,我们为了避免分母为0,将这里的第二个元素改为了很接近0的正数
CR=CI/RI(n);
disp('一致性指标CI=');disp(CI);
disp('一致性比例CR=');disp(CR);
if CR<0.10
disp('因为CR<0.10,所以该判断矩阵A的一致性可以接受!');
else
disp('注意:CR >= 0.10,因此该判断矩阵A需要进行修改!');
end层次分析法在实际应用中有局限性,比如判断矩阵的主观性较强,可能导致结果的不稳定性。因此,在使用层次分析法时,应尽可能确保判断矩阵的客观性和准确性,并结合实际情况进行考虑。
本次分析就到这里,欢迎大家在评论区补充更正,相信大家一定会有所收获。感谢大家的关注及观看!
版权声明:本文为博主作者:你们不要再卷了原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2401_83283514/article/details/137757093