目录
- 一、损失函数作用
- 二、选择损失函数
-
- 2.1 回归任务常见损失函数
- 2.2 分类任务常见损失函数
- 三、常见损失函数
-
- 3.1 L1 Loss
-
- 3.1.1 L1 Loss原理
- 3.1.2 L1 Loss代码
- 3.2 L2 Loss
-
- 3.2.1 L2 Loss原理
- 3.2.2 L2 Loss代码
- 3.3 MSE Loss
-
- 3.3.1 MSE Loss和L2 Loss的关系
-
- 3.3.1.1 MSE Loss和L2 Loss相同点
- 3.3.1.2 MSE Loss和L2 Loss区别点
- 3.3.2 MSE Loss原理
- 3.3.3 MSE Loss代码
- 3.4 Binary Crossentropy Loss
-
- 3.4.1 Binary Crossentropy Loss原理
- 3.4.2 Binary Crossentropy Loss代码
- 3.5 Categorical Crossentropy Loss
-
- 3.5.1 Categorical Crossentropy Loss原理
- 3.5.2 Categorical Crossentropy Loss代码
- 3.6 Charbonnier Loss
-
- 3.6.1 Charbonnier Loss原理
- 3.6.2 Charbonnier Loss代码
- 3.7 Total Variation Loss
-
- 3.7.1 Total Variation Loss原理
- 3.7.2 Total Variation Loss代码
- 3.8 Weighted TV Loss
-
- 3.8.1 Weighted TV Loss原理
- 3.8.2 Weighted TV Loss代码
- 3.9 PSNR Loss
-
- 3.9.1 PSNR Loss原理
- 3.9.2 PSNR Loss代码
- 四、总结
一、损失函数作用
在深度学习中,损失函数是一个核心组件,它度量模型的预测结果与真实值之间的差异。通过最小化损失函数的值,模型能够在训练过程中逐渐改善其性能。损失函数为神经网络提供了一个明确的优化目标,是连接数据和模型性能的重要桥梁。
二、选择损失函数
选择合适的损失函数是非常重要的,因为它会影响模型的性能和训练效率。在选择损失函数时,需要考虑模型的具体任务(回归或分类),数据的特性(例如是否存在离群点),以及模型的优化算法等因素。在实际应用中,可能需要尝试不同的损失函数,以找到最适合特定任务和数据的那一个。
选择合适的损失函数取决于许多因素,包括是否有离群点,机器学习算法的选择,运行梯度下降的时间效率,是否易于找到函数的导数,以及预测结果的置信度。损失函数可以大致分为两类:分类损失(Classification Loss)和回归损失(Regression Loss)。
2.1 回归任务常见损失函数
平均绝对误差 (MAE/L1损失)
平均平方误差 (MSE/L2损失)
Smooth L1 loss
Huber损失
Log cosh loss
Quantile loss3
2.2 分类任务常见损失函数
二元交叉熵(binary crossentropy)损失函数,适用于二分类问题4
分类交叉熵(categorical crossentropy)损失函数,适用于多分类问题
三、常见损失函数
3.1 L1 Loss
3.1.1 L1 Loss原理
L1 Loss,也称为平均绝对值误差(MAE),是指模型预测值f (x)和真实值y之间绝对差值的平均值。L1 Loss是一种常用的损失函数,主要用于回归问题和简单的模型。由于神经网络通常是解决复杂问题,所以很少使用。在数学上,它的公式如下:
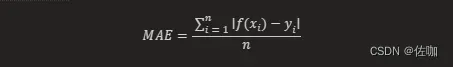
其中,f(xi) 和 yi 分别表示第 i 个样本的预测值及相应真实值,n 为样本的个数1。
3.1.2 L1 Loss代码
import torch
import torch.nn as nn
# 定义预测值和真实值
pred = torch.tensor([1.0, 2.0, 3.0, 4.0]) # 相应的真实值
target = torch.tensor([1.5, 2.5, 3.5, 4.5]) # 模型的预测值
# 创建 L1Loss 对象
criterion = nn.L1Loss() #nn.L1Loss() 创建了一个 L1Loss 对象,然后我们使用这个对象来计算预测值和真实值之间的 L1 损失
# 计算 L1 损失
loss = criterion(pred, target)
print(loss) # 输出结果:tensor(0.5000)
3.2 L2 Loss
3.2.1 L2 Loss原理
L2 Loss损失函数,也被称为欧氏距离,是一种常用的距离度量方法,通常用于度量数据点之间的相似度。L2损失函数是均方误差损失函数(MSE)的另一种称呼。它计算的是预测值与真实值之间差的平方的平均值。在数学上,它的公式如下:
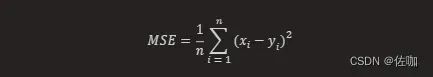
其中,xi 和 yi 分别表示第 i 个样本的预测值及相应真实值,n 为样本的个数。
3.2.2 L2 Loss代码
import torch
import torch.nn as nn
# 定义预测值和真实值
pred = torch.tensor([1.0, 2.0, 3.0, 4.0]) # 模型的预测值
target = torch.tensor([1.5, 2.5, 3.5, 4.5]) # 相应的真实值
# 创建 L2Loss 对象
criterion = nn.MSELoss() # nn.MSELoss() 创建了一个 L2Loss 对象,然后我们使用这个对象来计算预测值和真实值之间的 L2 损失
# 计算 L2 损失
loss = criterion(pred, target)
print(loss) # 输出结果:tensor(0.2500)
3.3 MSE Loss
3.3.1 MSE Loss和L2 Loss的关系
MSE Loss(均方误差损失)和L2 Loss在很多情况下是同一个概念,都是用来衡量预测值和实际值之间的平方差。在很多情况下可以互换使用,它们都是衡量模型预测性能的重要工具。在机器学习和深度学习中,它们都是常用的损失函数。
3.3.1.1 MSE Loss和L2 Loss相同点
它们都是通过计算预测值和实际值之间的平方差来衡量模型的性能。
它们都假设误差分布满足高斯分布。
3.3.1.2 MSE Loss和L2 Loss区别点
严格来说,L2 Loss是指向量各元素的平方和然后求平方根,而MSE Loss是指所有(预测值-实际值)的平方和,再除以总数。但在实际应用中,由于平方根和平方在优化过程中会抵消,所以L2 Loss常常被用来指代MSE Loss2。
3.3.2 MSE Loss原理
MSE Loss,即均方误差损失(Mean Squared Error Loss),是一种常用的损失函数,主要用于回归问题。它计算的是预测值与真实值之间差的平方的平均值。在数学上,它的公式如下:
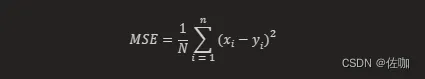
其中,xi 和 yi 分别表示第 i 个样本的预测值及相应真实值,n 为样本的个数。
3.3.3 MSE Loss代码
在 PyTorch 中,MSELoss 函数有一个 reduction 参数,用于指定如何缩减损失的维度。reduction 参数有三个选项:
‘none’:不进行缩减。
‘mean’:输出的和将被除以输出中的元素数量。
‘sum’:输出将被求和。
如果不设置 reduction 参数,其默认值为 ‘mean’。
import torch
import torch.nn as nn
a = torch.tensor([[1, 2], [3, 4]], dtype=torch.float)
b = torch.tensor([[3, 5], [8, 6]], dtype=torch.float)
loss_fn1 = torch.nn.MSELoss(reduction='none')
loss1 = loss_fn1(a, b) # loss1 是按照原始维度输出,即对应位置的元素相减然后求平方
print(loss1) # 输出结果:tensor([[4., 9.], [25., 4.]])
loss_fn2 = torch.nn.MSELoss(reduction='sum')
loss2 = loss_fn2(a, b) # loss2 是所有位置的损失求和
print(loss2) # 输出结果:tensor(42.)
loss_fn3 = torch.nn.MSELoss(reduction='mean')
loss3 = loss_fn3(a, b) # loss3 是所有位置的损失求和后取平均
print(loss3) # 输出结果:tensor(10.5000)
上面代码解析:loss1 是按照原始维度输出,即对应位置的元素相减然后求平方;loss2 是所有位置的损失求和;loss3 是所有位置的损失求和后取平均。
3.4 Binary Crossentropy Loss
3.4.1 Binary Crossentropy Loss原理
二元交叉熵损失函数(Binary Cross Entropy Loss Function)是深度学习中的一种常用的损失函数,它可以用来指导机器学习模型的训练过程,以便使模型的预测结果尽可能接近实际的标签值。
二元交叉熵损失函数的计算公式为:

其中,yi 表示真实标签,pi 表示模型预测出的概率值。
3.4.2 Binary Crossentropy Loss代码
import torch
import torch.nn as nn
# 定义预测值和真实值
pred = torch.tensor([[0.1, 0.9], [0.3, 0.7]], dtype=torch.float)
target = torch.tensor([1, 0], dtype=torch.long)
# 创建 CrossEntropyLoss 对象
criterion = nn.CrossEntropyLoss() # nn.CrossEntropyLoss() 创建了一个 CrossEntropyLoss 对象,然后我们使用这个对象来计算预测值和真实值之间的二元交叉熵损失
# 计算二元交叉熵损失
loss = criterion(pred, target)
print(loss) # 输出结果:tensor(0.7136)
3.5 Categorical Crossentropy Loss
3.5.1 Categorical Crossentropy Loss原理
Categorical Cross-Entropy损失函数,也称为Softmax Loss(分类损失函数),是一种常用的损失函数,主要用于多类别分类问题。它计算的是模型预测的概率分布与真实的概率分布之间的交叉熵。在数学上,它的公式如下:
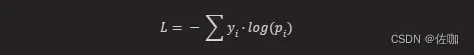
其中,yi 表示真实标签,pi 表示模型预测出的概率值。
3.5.2 Categorical Crossentropy Loss代码
import torch
import torch.nn as nn
# 定义预测值和真实值
pred = torch.tensor([[0.1, 0.2, 0.7], [0.3, 0.4, 0.3]])
target = torch.tensor([2, 1])
# 创建 CrossEntropyLoss 对象
criterion = nn.CrossEntropyLoss() # nn.CrossEntropyLoss() 创建了一个 CrossEntropyLoss 对象,然后我们使用这个对象来计算预测值和真实值之间的 Categorical Cross-Entropy 损失
# 计算二元交叉熵损失
loss = criterion(pred, target)
print(loss) # 输出结果:tensor(1.4076)
3.6 Charbonnier Loss
3.6.1 Charbonnier Loss原理
Charbonnier Loss是一种用于图像生成任务的损失函数,它是L1损失的近似,用于提高模型的性能。Charbonnier Loss的表达式如下:
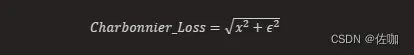
其中,x是预测值和真实值之间的差,ϵ是一个很小的常数,用于保证在x=0时函数的可微性。
3.6.2 Charbonnier Loss代码
import torch
class L1_Charbonnier_loss(torch.nn.Module):
"""L1 Charbonnierloss."""
def __init__(self):
super(L1_Charbonnier_loss, self).__init__()
self.eps = 1e-6
def forward(self, X, Y):
diff = torch.add(X, -Y)
error = torch.sqrt(diff * diff + self.eps)
loss = torch.mean(error)
return loss
上面代码解析:L1_Charbonnier_loss是一个自定义的损失函数类,它继承了torch.nn.Module。在forward方法中,首先计算预测值X和真实值Y之间的差,然后计算这个差的平方和ϵ2的平方根,最后返回这个值的平均值。
3.7 Total Variation Loss
3.7.1 Total Variation Loss原理
Total Variation Loss(TV Loss),全名为总变分损失函数,源自于图像处理中的全变分去噪。TV Loss作为一种正则项配合损失函数去调节网络学习。即求每一个像素与其下方像素和右方像素的差的平方相加再开根号的和。
在图像复原过程中,图像上的一点点噪声可能就会对复原的结果产生非常大的影响,因为很多复原算法都会放大噪声。这时候我们就需要在最优化问题的模型中添加一些正则项来保持图像的光滑性,TV Loss是常用的一种正则项。TV Loss的作用就是保持图像的光滑性,消除图像复原可能带来的伪影。缺陷在于会使得复原的图像过于光滑,在一些细节比较多的图像中会使得复原后的图像丢失细节。
3.7.2 Total Variation Loss代码
import torch
import torch.nn as nn
class TVLoss(nn.Module):
def __init__(self, weight: float=1) -> None:
"""Total Variation Loss
Args:
weight (float): weight of TV loss
"""
super().__init__()
self.weight = weight
def forward(self, x):
batch_size, c, h, w = x.size()
tv_h = torch.abs(x[:,:,1:,:] - x[:,:,:h-1,:]).sum()
tv_w = torch.abs(x[:,:,:,1:] - x[:,:,:,:w-1]).sum()
return self.weight * (tv_h + tv_w) / (batch_size * c * h * w)
def main():
tv_loss = TVLoss()
x = torch.rand([1, 3, 3, 3])
print(f'Input:\\n{x}')
print(f'The TV Loss is {tv_loss(x).item()}')
if __name__ == "__main__":
main()
上面代码解析:TVLoss 是一个自定义的损失函数类,它继承了 torch.nn.Module。在 forward 方法中,首先计算输入图像 x 在水平和垂直方向上的差异,然后将这些差异的绝对值求和,最后返回加权的 TV Loss。
3.8 Weighted TV Loss
3.8.1 Weighted TV Loss原理
WeightedTVLoss是一种损失函数,它是Total Variation Loss(TV Loss)的加权版本。TV Loss是一种常用于图像生成任务的损失函数,它可以鼓励生成的图像在空间上具有平滑性。WeightedTVLoss通过对每个像素的TV Loss应用不同的权重,可以让模型在某些区域更加关注细节,而在其他区域更加关注平滑性。
3.8.2 Weighted TV Loss代码
import torch
import torch.nn.functional as F
class WeightedTVLoss(nn.Module):
def __init__(self):
super(WeightedTVLoss, self).__init__()
def forward(self, input, weight):
diff_i = torch.sum(torch.abs(input[:, :, :, 1:] - input[:, :, :, :-1]))
diff_j = torch.sum(torch.abs(input[:, :, 1:, :] - input[:, :, :-1, :]))
tv_loss = diff_i * weight[:, :, :, 1:] + diff_j * weight[:, :, 1:, :]
return torch.mean(tv_loss)
上面代码解析:WeightedTVLoss是一个自定义的损失函数类,它继承了torch.nn.Module。在forward方法中,首先计算输入图像在水平和垂直方向上的差异,然后将这些差异与权重相乘,最后返回加权TV Loss的平均值。
3.9 PSNR Loss
3.9.1 PSNR Loss原理
PSNRLoss,即峰值信噪比损失(Peak Signal to Noise Ratio Loss),是一种常用的损失函数,主要用于图像生成任务。它计算的是预测值与真实值之间的峰值信噪比的差异。在数学上,它的公式如下:
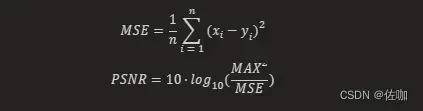
其中,xi 和 yi 分别表示第 i 个样本的预测值及相应真实值,n 为样本的个数,MAX 是可能的最大像素值。
3.9.2 PSNR Loss代码
import torch
import torch.nn as nn
class PSNRLoss(nn.Module):
def __init__(self):
super(PSNRLoss, self).__init__()
self.mse = nn.MSELoss()
def forward(self, img1, img2):
mse = self.mse(img1, img2)
psnr = 10 * torch.log10(1 / mse)
return psnr
上面代码解析:PSNRLoss 是一个自定义的损失函数类,它继承了 torch.nn.Module。在 forward 方法中,首先计算输入图像 img1 和 img2 之间的均方误差(MSE),然后计算这个均方误差的倒数的对数,最后返回 PSNR。
四、总结
还会持续更新其它损失函数,欢迎留言讨论。
总结不易,三连支持,谢谢。
版权声明:本文为博主作者:佐咖原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_40280673/article/details/134293907