论文笔记:DINO用于视觉自监督学习的知识蒸馏算法——Emerging Properties in Self-Supervised Vision Transformers
综述
论文题目:《Emerging Properties in Self-Supervised Vision Transformers》
会议时间:ICCV 2021
主要思想
Transformer由于其远距离建模的优势,最近经常用于解决视觉的各大任务,常见的策略就是在大量数据上进行有监督预训练,获得较强的语义表征能力,之后在目标数据上进行微调,用于下游任务的应用。但这种方法并没有明显的好处,在增加计算量的同时,所提取的特征并没有表现出独特的属性(unique properties),这就不免产生疑问,利用有监督式的训练策略,是否充分挖掘了模型的特征表示潜力?
在本文中,作者利用弱监督学习策略,来进一步提升了transformer在视觉应用中的能力。考虑到transformer在NLP领域中取得成功的主要因素之一是使用了自监督训练,例如BERT使用MLM(Masked Language Model)的自监督训练策略,随机抹掉部分单词,之后根据上下文来预测这个单词;GPT采用ALM(Autoregressive Language Modeling)的自监督训练策略,让模型根据前文来预测下一个可能出现的单词。这些算法均使用句子中的单词来创建假设任务(pretext task),这种操作可以提供更丰富的学习信号,可以让模型在学习过程中学到更多的语义信息,相比于监督学习中,简单地预测每个句子固定单一的标签难以让网络学到这种丰富的语义信息,模型的理解能力往往会被句子的标签所约束。同样,在图像任务中,图像级别的监督常常会降低视觉的信息量,整幅图像丰富的语义信息会被简化为从几千个对象类别的预定义集合中选择的单个概念,所学到的视觉信息量会大大降低,这也是要用自监督学习策略来取代监督学习策略的一个核心出发点。
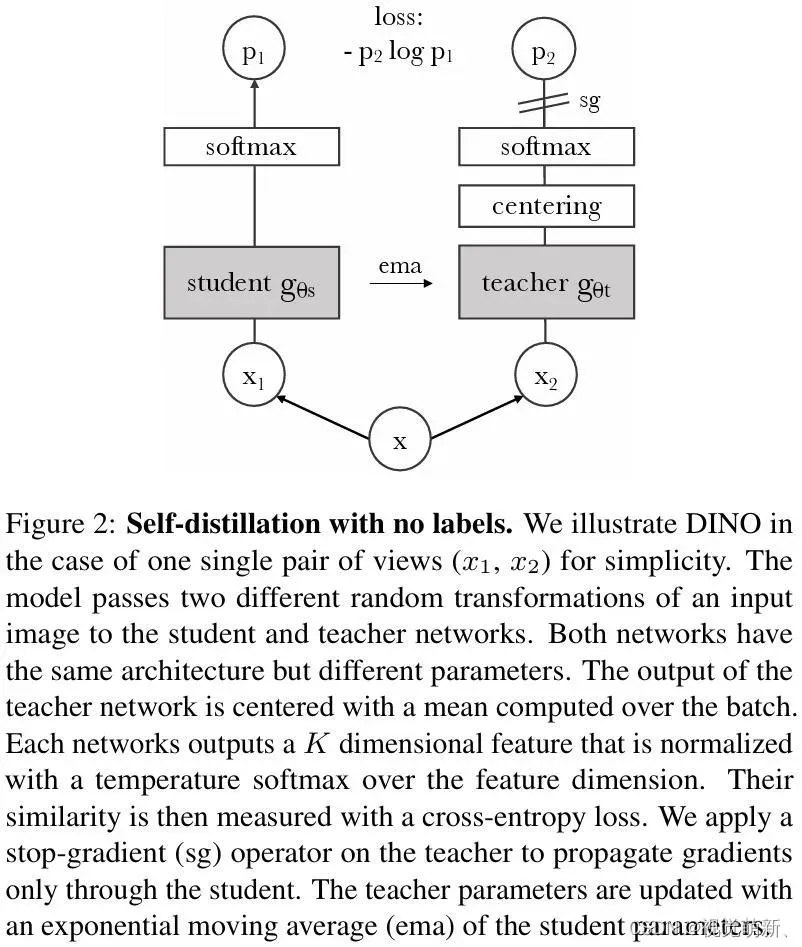
作者的自我监督学习方法可以表示为一种无标签的知识蒸馏操作(distillation with no labels, DINO),通过使用标准的交叉熵损失,让学生网络去学习教师网络的输出,同时教师网络由动量编码器(momentum encoder)构成,即教师网络的参数通过学生网络的参数来动量式地更新,最后作者使用中心化操作和锐化操作(centering and sharpening)来避免教师网络的崩溃问题(collapse)。此架构是比较灵活的,可以在CNN或者ViT上进行工作,不需要修改原始的网络架构,也不需要适应内部标准化操作(internal normalizations )。
如下图所示,利用自监督学习的ViT特征明确包含了场景布局,特别是对象边界,这些关注区域可以在最后一个自注意力关注模块中直接提取,同时,自监督ViT网络所提取的特征在基本近邻分类器k-NN下表现特别好,无需任何微调就可以在ImageNet上达到78.3%的准确率。

方法
知识蒸馏
知识蒸馏是一种学习范式,让学生网络去匹配教师网络
的输出,给定输入图像
,两个网络输出
维上的概率分布,分别表示为
和
(由网络
的输出进行softmax归一化得到):
其中表示用于控制学生网络输出分布尖锐程度的温度参数,对于教师网络的概率分布,也有同样的公式以及温度超参数
。给定一个固定的教师网络
,通过最小化交叉熵损失来匹配学生网络和教师网络的输出,从而更新学生网络的参数
:
其中,这一步用于让学生网络的输出向教师网络靠拢,此过程并不更新教师网络的参数。
自监督学习
知识蒸馏范式在设计的初衷,就是为了针对两个不同的模型,用复杂度较高、性能较好的模型去提升复杂度较低、性能较弱的模型,将强模型的能力通过蒸馏的方式蒸给弱模型,因此需要让弱模型的输出往强模型的输出上靠拢。这里教师网络输出的结果相当于伪标签,让学生网络去学习,因此如果有一个训练好的教师网络,我们就可以在没有真实标签数据的情况下,来训练学生网络,让学生网络去教师网络的能力。而在这篇文章中,作者做了进一步的改进,假设教师网络和学生网络都是随机初始化的,也就是都需要进行参数更新,用教师网络生成的伪标签去训练学生网络,从而实现完全意义上的自监督训练,现在问题的核心就在于如何动态更新教师网络的参数。在这里,作者参考动量更新的思想,利用EMA策略,让学生网络的参数去更新教师网络的参数,这样学生网络向教师网络靠拢的同时也会改变教师网络,最终两个网络会朝着同一个输出结果趋势上优化,网络主要流程图如下图所示:
版权声明:本文为博主作者:视觉萌新、原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_50001789/article/details/136208089