01
引言
随着传感器技术和互联网的迅速发展,各种不同模态的大数据正在以前所未有的发展速度迅速涌现。对于一个待描述事物(目标、场景等),通过不同的方法或视角收集到的耦合的数据样本就是多模态数据。通常把收集这些数据的每一个方法或视角称之为一个模态。狭义的多模态信息通常关注感知特性不同的模态(如图像-文本、视频-语音、视觉-触觉等),而广义的多模态融合则通常还包括同一模态信息中的多特征融合,以及多个同类型传感器的数据融合等。因此,多模态感知与学习这一问题与信号处理领域的“多源融合”、“多传感器融合”,以及机器学习领域的“多视学习”或“多视融合”等有密切的联系。多模态数据可以获得更加全面准确的信息,增强系统的可靠性和容错性。在多模态感知与学习问题中,由于不同模态之间具有完全不同的描述形式和复杂的耦合对应关系,因此需要统一地解决关于多模态的感知表示和认知融合的问题。多模态感知与融合就是要通过适当的变换或投影,使得两个看似完全无关、不同格式的数据样本,可以相互比较融合。通俗地说,就是实现不同模态之间的“关公战秦琼”(见图 1)。这种异构数据的融合往往能取得意想不到的效果。
多模态数据目前已经在互联网信息搜索、人机交互、工业环境故障诊断和机器人等领域发挥了巨大的作用。视觉与语言之间的多模态学习是目前多模态融合方面研究成果较为集中的领域。在机器人领域目前仍面临很多需要进一步探索的挑战性问题。本文将着重介绍机器人多模态信息感知与融合,特别是在视觉与触觉融合感知方面的相关工作。
02
机器人多模态感知
机器人是指挥与控制系统中实现态势感知的重要工具。但在以机器人为代表的工程系统中,不同模态的传感器通常还只能在各自感知识别完成后做融合,使得融合逻辑的设计非常困难。最典型的案例就是 2016 年在美国特斯拉汽车在自动驾驶模式下的致死车祸。虽然该车配备了精良的传感器,但由于布局的问题,未能有效地融合视觉传感器和距离传感器信息。而在工业生产现场,由于感知模态融合能力的不足,目前只能实现一些非常简单的机械操作。
机器人系统上配置的传感器复杂多样。从摄像机到激光雷达,从听觉到触觉,从味觉到嗅觉,几乎所有传感器在机器人上都有应用。但限于任务的复杂性、成本和使用效率等原因,大多数工作仍然停留在实验室阶段。在目前市场上流行的服务机器人领域,用的最多的仍然是视觉和语音传感器,这两类模态一般是独立处理(如视觉用于目标检测、听觉用于语音交互)。由于大多数机器人尚缺乏操作能力和物理人机交互能力,触觉传感器基本还没有应用。
为了解决复杂场景下的机器人精细操作问题,要求机器人能够通过视觉、距离等模态信息感知环境,还需要触觉等接触性信息感知物体。各种不同模态的传感器为机器人实现更为高效的科学决策提供了基础,为智能机器人提供了新的机遇,也为多模态信息融合方法带来了新的挑战。这一工作对于解决机器人的环境感知、目标侦察、导航控制等具有重要意义,并可直接应用于无人车、操作臂等多种不同平台,实现灾害救援、反恐防爆、应急处置等任务。
然而,对于机器人系统而言,所采集到的多模态数据具有一些明显的特点,为融合感知的研究工作带来了巨大的挑战。这些问题包括:
(1)“污染”的多模态数据:机器人的操作环境非常复杂,因此采集的数据通常具有很多噪声和野点。
(2)“动态”的多模态数据:机器人总是在动态环境下工作,采集到的多模态数据必然具有复杂的动态特性。
(3)“失配”的多模态数据:机器人携带的传感器工作频带、使用周期具有很大差异,导致各个模态之间的数据难以“配对”。
以上这些问题为机器人多模态的融合感知带来了巨大的挑战。为了实现多种不同模态信息的有机融合,需要为他们建立统一的特征表示和关联匹配关系。
03
机器人视-触模态融合技术
目前很多机器人都配备了视觉传感器。在实际操作应用中常规的视觉感知技术受到很多限制,例如光照、遮挡等。对于物体的很多内在属性,例如“软”、“硬”等,则难以通过视觉传感器感知获取。对机器人而言,触觉也是获取环境信息的一种重要感知方式。与视觉不同,触觉传感器可直接测量对象和环境的多种性质特征。同时,触觉也是人类感知外部环境的一种基本模态。早在上世纪 80 年代,就有神经科学领域的学者在实验中麻醉志愿者的皮肤,以验证触觉感知在稳定抓取操作过程中的重要性。因此,为机器人引入触觉感知模块,不仅在一定程度上模拟了人类的感知与认知机制,又符合实际操作应用的强烈需求。
随着现代传感、控制和人工智能技术的发展,科研人员对包括灵巧手触觉传感器,以及使用所采集的触觉信息结合不同算法实现对于灵巧手抓取稳定性的分析以及对抓取物体的分类与识别开展了广泛的研究。触觉传感器对于灵巧手的精细操作意义重大。早在上世纪 90 年代,加州大学伯克利分校的Banks 等学者在 Nature(2002)① 和 Science(2002)② 上分别发表的两篇学术论文揭示了人类天然地具有最优融合视觉和触觉信息的能力,但如何通过计算模型为工程系统构建这样的能力还远远没有解决。
视觉信息与触觉信息采集的是物体不同部位的信息,前者是非接触式信息,而后者是接触式信息,因此他们反映的物体特性具有明显的差异,这也使得视觉信息与触觉信息具有非常复杂的内在关联关系。现阶段很难通过人工机理分析的方法得到完整的关联信息表示方法,因此数据驱动的方法是目前比较有效的解决这类问题的途径。为此,我们在结构化稀疏编码的统一框架下,建立了机器人多模态融合感知的计算模型(见图 2),开发了若干融合理解方法。以下简要介绍几个相关的研究工作。
(一)触觉阵列融合目标识别
机器人在操作过程中获取的触觉信息具有阵列化和序列化特点。已有的工作大都关注的是机械手的“指尖”建模。对于多指手,各个不同指尖获取的触觉序列可以视作为不同的传感器。常规的处理方法要么将他们视为独立的传感器,要么直接简单拼接起来。前者忽略了不同指尖之间的共性,后者则忽略了不同指尖之间的差异。我们针对触觉阵列特点开发了联合稀疏编码模型(图 3),解决了不同指尖之间的关联关系建模问题,并将其有效地应用于触觉目标识别,首次将这一领域的工作从传统的“指尖”建模推动到“指间”建模(见文献[2])。
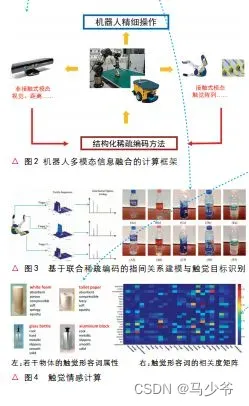
(二)触觉情感计算
如果说视觉目标识别是在确定物体的名词属性(如“石头”、“木头”),那么触觉模态则特别适合用于确定物体的形容词属性(如“坚硬”、“柔软”)。“触觉形容词”已经成为触觉情感计算模型的有利工具。值得注意的是,对于特定目标而言,通常具有多个不同的触觉形容词属性(见图 4 左),而不同的“触觉形容词”之间往往具有一定的关联关系,如“硬”和“软”一般不能同时出现,“硬”和“坚实”却具有很强的关联性。为此,我们建立了常见触觉形容词的关联频度矩阵(见图 4右),从中可以看出这些关联度与我们的直观理解高度吻合。通过将这些关联关系融入编码过程,我们建立了触觉情感计算模型。这一模型可以有效地对物体材质的触觉属性进行鉴别。特别是,当感知到“硬”、“光滑”等属性时,系统能自动分析出物体也具有“冷”的属性,从而有效地建立了接触觉与温度觉的通感。具体的算法模型和实验结果参见文献[3-4]。
(三)视-触模态融合识别
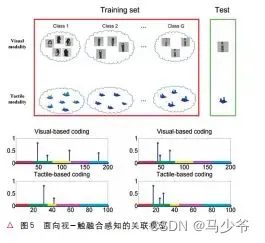
视觉与触觉模态信息具有显著的差异性。一方面,他们的获取难度不同。通常视觉模态较容易获取,而触觉模态更加困难。这往往造成两种模态的数据量相差较大。另一方面,由于“所见非所摸”,在采集过程中采集到的视觉信息和触觉信息往往不是针对同一部位的,具有很弱的“配对特性”。因此视觉与触觉信息的融合感知具有极大的挑战性。自从Banks 分析人类的视-触融合能力后,在机器人上实现高效视-触融合感知的研究进展异常缓慢。我们针对这一问题,利用开发的关联稀疏编码模型(见图5),首次解决了弱配对情形下的视-触融合目标识别问题(见文献[5])。
04
展望
机器人是一个复杂的工程系统,开展机器人多模态融合感知需要综合考虑任务特性、环境特性和传感器特性。尽管大家已经充分认识到触觉模态在机器人系统上的应用,国内很多相关机构,如东南大学[6]、北京航空航天大学[8]等都在这方面开展了多年的研究工作,但目前机器人触觉感知方面的进展远远落后于视觉感知的进展。另一方面,如何融合视觉模态与触觉模态的研究工作尽管在上世纪 80 年代就开始有相关研究,但进展一直缓慢。近年来,围绕机器人操作任务,美国的宾夕法尼亚大学和加州大学伯克利分校[1]、德国的慕尼黑工业大学[7]都在开展这方面的研究工作。未来需要在视触融合的认知机理、计算模型、数据集和应用系统上开展突破,综合解决融合表示、融合感知、融合学习的融合计算问题。
参考文献
[1] V. Chu, I. McMahon, L. Riano, C. McDonalda, Q. Hea,J. Perez-Tejada, M. Arrigo, T. Darrell, K.Kuchenbeckera, Robotic learning of haptic adjectivesthrough physical interaction, Robotics and AutonomousSystem s, vol. 63, no. 3, pp. 279-292, 2015.
[2] H. Liu, D. Guo, F. Sun, Object recognition using tactile measurements: Kernel sparse coding methods, IEEE Transactions on Instrumentation and Measurement, vol.65, no.3, pp.656-665, 2016.
[3] H. Liu, F. Sun, D. Guo, B. Fang, Structured outputassociated dictionary learning for haptic understanding,IEEE Transactions on System s, Man and Cybernetics:System s, In press
[4] H. Liu, J. Qin, F. Sun, D. Guo, Extreme kernel sparse learning for tactile object recognition, IEEE Transactions on Cybernetics, In press
[5] H. Liu, Y. Yu, F. Sun, J. Gu, Visual-tactile fusion for object recognition, IEEE Transactions on Automation Science and Engineering, In press
[6] A.Song, Y.Han, H.Hu, J.Li, A novel texture sensor for fabric texture measurement and classification, IEEE Transactions on Instrumentation and Measurement, vol.63, no.7, pp.1739-1747, 2014.
[7] M. Strese, C. Schuwerk, A. Iepure, E. Steinbach, Multimodal feature-based surface material classification, IEEE Transactions on Haptics, In press
[8]D.Wang,X.Zhang, Y. Zhang, J. Xiao, Configurationbased optimization for six degree-of-freedom haptic rendering for fine manipulation, IEEE Transactions on Haptics, vol.6, no.2, pp.167-180, 2013
本文作者:刘华平 清华大学计算机科学与技术系
清华大学计算机科学与技术系副教授、博士生导师,中国指挥与控制学会青年工作委员会委员,IEEE 高级会员。主要从事智能机器人的多模态感知、学习与控制技术研究。曾被评为国家高技术研究发展计划“十二五”科技攻关“青年创新之星”,2016年获中国指挥与控制学会创新二等奖。
“中国指挥与控制学会”微信公众号发布
多模态解释
多模态系统(multimodalsystem)是指两个或更多的具有不同特性的感知器(通常被称为模态传感器),它们被集成到同一个硬件平台上。模态传感器是可以选择使用的,包括多光谱图像传感器、摄像机、视频传感器、激光扫描仪等。 7种模态(7CI)与媒体的选择无关,用户可以从许多感知器中任意选择。
文章出处登录后可见!