
©PaperWeekly 原创 · 作者 | 缥缈孤鸿影

引言
ChatGPT 的横空出世,在整个自然语言处理乃至人工智能领域均掀起波澜。不同于普通的闲聊式机器人和任务型智能客服仅局限于固定场景,ChatGPT 具有相当丰富的知识储备,对于很多冷门的知识,它亦能对答如流,堪称当代“百晓生”。因此,将语言模型与知识结合具有很高的研究价值,更强的知识性也标志着模型更加智能。本文先讲述预训练语言模型与知识的关系,再阐述在对话系统中引入外部知识的原因和做法等方面,对基于知识的对话模型作简单综述。

海纳百川——大语言模型也是知识库
一个知识库通常包含结构化或半结构化数据,例如实体、属性和关系,在人工构造知识库时往往也需要繁琐的工程技术和人工标注。相比之下,语言模型是基于自然语言文本的统计模型,只需投入大量无标签文本语料就可以学习语言的规律和模式,然后利用这些规律和模式来生成文本或者回答关于文本的问题。
现在百花齐放的大语言模型如 BERT,GPT 等,都是在大量的文本数据上预训练过的,这已成为主流范式。维基百科,Reddit、知乎等论坛,推特、微博等媒体,都提供了海量的文本数据,语言模型把这些文本信息以参数化的形式存储。文章 [1] 以完形填空的形式对语言模型包含的知识进行探索,如下图所示,在实体-属性-关系形式的三元组数据集上验证,得出语言模型学习到并存储了一些事实知识。
尽管语言模型不能像知识库那样提供明确的实体、属性和关系等结构化信息,但它们可以通过学习文本信息来获取知识,比如学习单词之间的语义关系,理解句子的结构和含义,识别实体和事件等。再将这样的知识库应用于下游任务,相比传统方法得到显著提升。
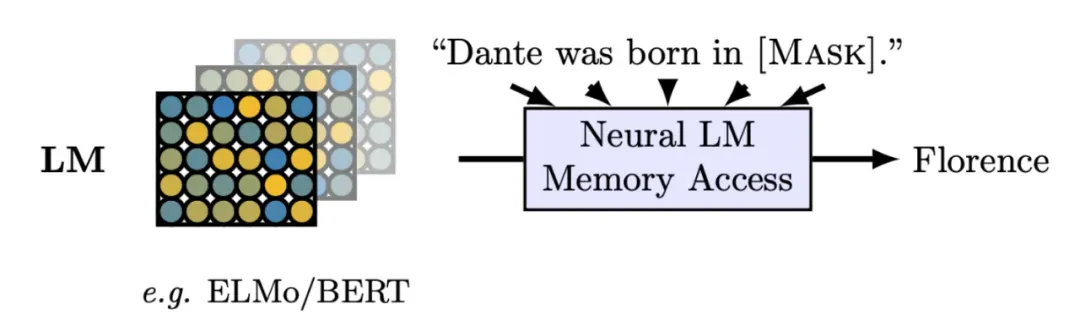
▲ Figure 1: 语言模型中的事实知识在填空任务的表现 [1]
2.1 语言模型学到了哪些知识
语言模型从海量文本语料中学习了大量知识,文章 [1] 指出语言模型除了学习到语言学知识外,还学到了大量世界性知识(或称事实知识)。
语言学知识主要包括单词之间的语义关系(比如词法、词性等),以及句子的结构和语法规则,从而理解自然语言。同图像领域中低层的神经网络通常学习轮廓等低维通用特征一样,Transformer 为基础的大语言模型也是在低层存储这些语言学知识,这也是将预训练模型在下游任务上微调时将 Adapter 等结构加到上层网络的缘故。
世界性知识就是我们通常认定的一些客观事实,比如实体和事件的识别,语言模型可以学习到如何识别文本中的人名、地名、时间、事件等实体信息;也比如一些抽象的情感特征,文本分类和主题模型等,在新闻摘要、产品评论分类、社交媒体评论分类等任务上均可胜任。
目前的大语言模型在语言学知识上的表现已相当成熟,只需要借助少量的语料数据就能生成流畅连贯,语法正确的句子 [2],但是事实知识的学习是一个动态的过程,我们只能通过增加训练语料来让模型学习更多的世界知识,并且更新起来如果涉及模型微调相当麻烦,例如 ChatGPT 只能回答截止到训练时相关知识的问题,超过这一时间点就束手无策,这也是目前 ChatGPT 待解决的问题之一。
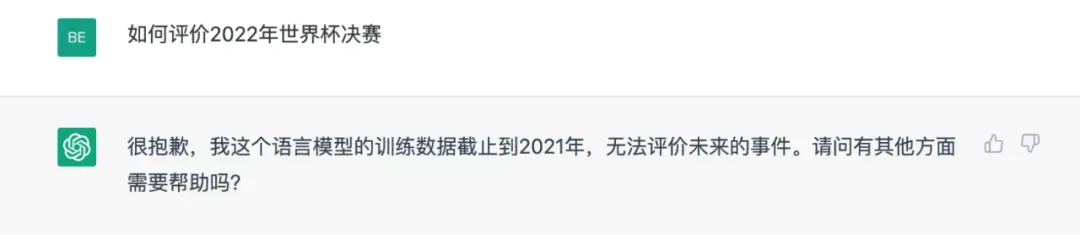
▲ Figure 2: ChatGPT 无法获取即时信息
2.2 如何将语言模型用作知识库
如前文所说,语言模型通常不能像传统的知识库一样提供结构化的实体、属性和关系等信息,但是,针对不同的子任务,只要设计良好的提示模板 Prompt,就可以提取出模型中的知识,提示学习 Prompt Learning 也是当前的主流方法。
关于将语言模型用作知识库(Language Model as Knowledge Base)这一范式,也有很多研究工作,文章 [3] 提出模型在进行预训练时使用到的无监督文本语料非常庞大,因此很难保证模型将这些知识全部存储在参数中并且之后可以准确提取,于是尝试通过加入有关的上下文信息,在实体识别等任务上均提升了模型提取知识的准确率;
而在 [4] 中通过对 prompt 重新构造进行集成和组合,在问答测试等问题取得一定提升;在 [5] 中通过在预训练时加入一个检索模块,使模型能够以更加具备解释性和模块化的来获取文本中的知识,将外部知识作为 Prompt 激发语言模型的知识能力。虽然语言模型区别于传统的知识库,但是可以通过各种方式将其应用于类似于知识库的任务中,提供类似于知识库的信息。

学海无涯——对话系话为何引入外部知识
对话系统引入外部知识可以生成信息更丰富的回复,利用外部知识库中的术语来生成更专业的表达式。外部知识对于消除模型幻觉”Hallucination” 一直都具备重要意义,语言模型受限于训练语料本身存储的知识有限,对于很多场景的任务均需要外部知识辅助,不然本身容易生成具有事实性错误的内容,如下图所示。
此外,一些事实性知识在训练语料中出现频率较少,在生成回复时并不能很好利用,这时引入外部知识就可以作为一种提示,激发语言模型本身的知识用于回复生成。

▲ Figure 3: 引入外部知识的对话模型

学以致用——对话模型如何利用外部知识?
许多研究人员致力于构建以知识为基础的对话系统。对话系统可以利用外部知识来增强其对话能力,使得其可以回答更加复杂和多样化的用户问题,如下图所示。其中的关键问题就在于如何把外部知识引入到对话模型中,一般来讲,包括将知识库以某种形式存储供模型调用,或者使用外部检索从海量文本中查找需要的知识。
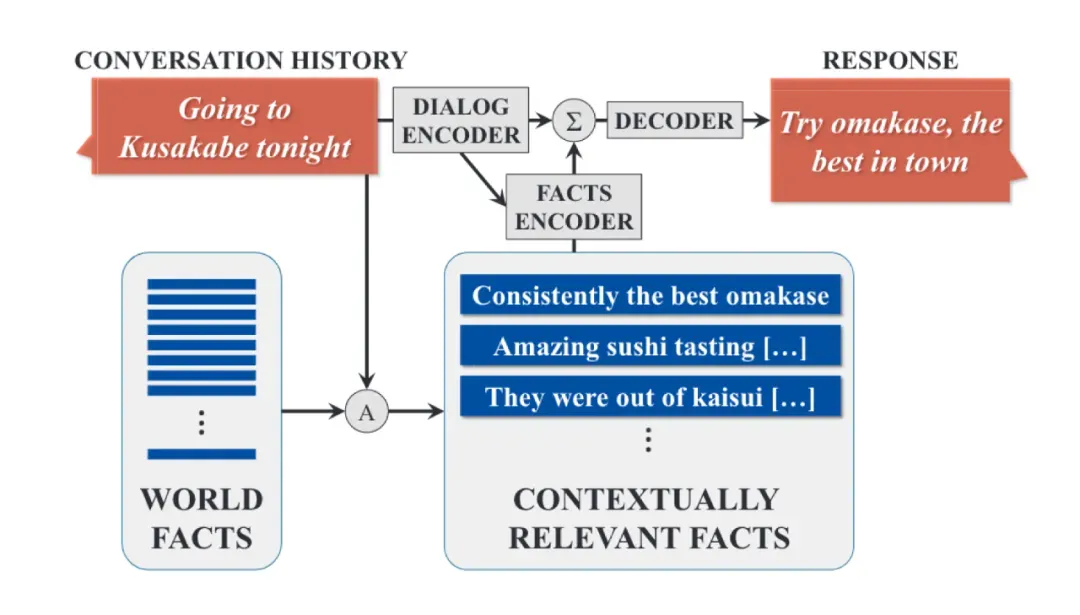
▲ Figure 4: 基于知识的对话模型 [6]
4.1 记忆网络
记忆网络是一种常用于对话模型中的网络结构,它可以用来增强对话模型记忆历史对话内容以及其他外部知识。知识为基础的系统使用记忆网络存储外部知识,生成器在生成阶段从中检索相关知识事实 [6]。
对话模型可以使用记忆网络来检索外部知识库中的信息,从而使回复更具知识性,能够解决用户需求,也可以使用记忆网络来记录对话历史,以便更好地理解用户的意图和回答用户的问题,同时也避免在长对话历史场景中发生上下文不一致的问题,在特定话题以及人设对话场景中都非常重要,以更好地理解用户意图并生成自然回复。
4.2 文本知识检索
对话模型也可以直接检索外部知识文档来辅助生成回复,外部知识文档可以是类似于 Wikipedia 这样的知识库,文档包含大量知识事实,但它们有一个缺点,即它们通常太长而无法从中检索有用的信息 [7,8]。
对话系统使用检索算法在外部知识库中寻找与用户输入相关的信息,检索算法可以使用基于文本相似度的方法,如词袋模型、tf-idf 模型、文本向量化模型等;通常将对话上下文作为查询语句进行检索,也有工作进行一种后验选择,先将对话上下文作为输入并生成回复,再利用回复和上下文一块来检索文档 [7]。这也意味着需要对生成的多个回复进行过滤和排序,返回最相关和准确的信息。
由于文本知识检索不需要改变模型参数就可以结合最新知识,这也是非常有前景的研究方向;区别于传统的文本检索。
4.3 知识图谱
知识图是外部信息的另一个来源,由于其实体-属性-关系的结构化特性,它在以知识为基础的系统中越来越受欢迎。随着图神经网络的发展,很多研究都侧重从知识图谱中获取更强的信息表征然后应用到对话任务 [9]。知识图谱为模型提供了全面、丰富的实体特征和关系,模型在存储知识时也更倾向于这种实体关系的映射,所以知识图谱往往更容易增强了模型的知识性和鲁棒性,而对话任务由于经常有多轮交互,涉及通过上下文在知识图谱上转移到更有意义的节点。

大道行思——知识对话模型的未来展望
随着 ChatGPT 的大获成功,知识对话模型也受到越来越多的关注,在很多方向上都具备很高的研究价值:可以将图像、视频等多模态信息融入对话模型中,可以进一步提高对话的自然度和实用性;未来的知识对话模型将更加注重对用户个性化需求的满足,包括对用户的历史对话记录、兴趣爱好等信息的建模和利用,以实现更自适应和个性化的对话服务;
此外,微软最近将 ChatGPT 与 Bing 结合一改搜索引擎的范式,通过对话查询的形式返回最新的网页链接,这又是对传统文档检索的一次突破;未来对话模型也会更注重对话策略和生成算法的智能优化,以提高对话的质量和效率,包括如何更好地利用对话历史和上下文信息,以及如何更好地生成自然、连贯的对话文本。
参考文献
[1] F.Petroni,T.Rocktäschel,S.Riedel,P.Lewis,A.Bakhtin,Y.Wu,andA.Miller,“Language models as knowledge bases?” in Proceedings of the 2019 Conference on Empirical Meth- ods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 2463–2473.
[2] Y. Zhang, A. Warstadt, X. Li, and S. Bowman, “When do you need billions of words of pretraining data?” in Proceedings of the 59th Annual Meeting of the Association for Com-
putational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 1112–1125.
[3] F. Petroni, P. Lewis, A. Piktus, T. Rocktäschel, Y. Wu, A. H. Miller, and S. Riedel, “How context affects language models’ factual predictions,” in Automated Knowledge Base Con- struction.
[4] Z.Jiang,F.F.Xu,J.Araki,andG.Neubig,“Howcanweknowwhatlanguagemodelsknow?”Transactions of the Association for Computational Linguistics, vol. 8, 2020.
[5] K. Guu, K. Lee, Z. Tung, P. Pasupat, and M.-w. Chang, “Realm: Retrieval-augmented lan- guage model pre,” Training, 2020.
[6] M. Ghazvininejad, C. Brockett, M.-W. Chang, B. Dolan, J. Gao, W.-t. Yih, and M. Galley, “A knowledge-grounded neural conversation model,” in Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, 2018, pp. 5110–5117.
[7] Z. Li, C. Niu, F. Meng, Y. Feng, Q. Li, and J. Zhou, “Incremental transformer with delib- eration decoder for document grounded conversations,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 12–21.
[8] K. Shuster, S. Poff, M. Chen, D. Kiela, and J. Weston, “Retrieval augmentation reduces hallucination in conversation,” in Findings of the Association for Computational Linguistics: EMNLP 2021, 2021, pp. 3784–3803.
[9] J. Jung, B. Son, and S. Lyu, “Attnio: Knowledge graph exploration with in-and-out attention flow for knowledge-grounded dialogue,” in Proceedings of the 2020 Conference on Empiri- cal Methods in Natural Language Processing (EMNLP), 2020, pp. 3484–3497.

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·

文章出处登录后可见!