分析框架:
一、明确需求和目的
- 对一家全球超市的四年(2012-2015)销售数据进行“人、货、场”分析,并给出提升销量的针对性建议。
- 场:整体运营情况分析,包括销售额、销量、利润、客单价、市场布局等具体情况分析。
- 货:商品结构、优势/畅销商品、劣势/待优化商品等情况分析。
- 人:客户数量、新老客户、RFM模型、复购率、回购率等用户行为分析。
二、数据介绍
- 数据来源于Kaggle平台,这是一份全球大型超市五年的零售数据集,数据信息详尽。
- 数据集为”全球超市订单数据.xlsx”,共51290条数据记录,每条记录共24个特征。
三、数据预处理
3.1 导入相关库并读取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False # 设置坐标轴负数显示
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None) # 设置显示最大列
data = pd.read_excel('全球超市订单数据.xlsx')
data.sample(5)
| 行 ID | 订单 ID | 订购日期 | 装运日期 | 装运方式 | 客户 ID | 客户名称 | 细分市场 | 邮政编码 | 城市 | 省市 | 国家 | 地区 | 市场 | 产品 ID | 类别 | 子类别 | 产品名称 | 销售额 | 数量 | 折扣 | 利润 | 装运成本 | 订单优先级 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21696 | 22861 | IN-2013-BM117857-41593 | 2013-11-15 | 2013-11-17 | 二级 | BM-117857 | Bryan Mills | 消费者 | NaN | Nowra | 新南威尔士 | 澳大利亚 | 大洋洲 | 亚太地区 | OFF-AR-3453 | 办公用品 | 艺术 | BIC Highlighters, Fluorescent | 54.513 | 3 | 0.1 | 1.773 | 10.82 | 高 |
| 5749 | 12597 | ES-2015-IM1505545-42098 | 2015-04-04 | 2015-04-08 | 标准级 | IM-1505545 | Ionia McGrath | 消费者 | NaN | Tourcoing | 北部-加来海峡-庇卡底 | 法国 | 西欧 | 欧洲 | OFF-ST-5702 | 办公用品 | 存储 | Rogers Lockers, Single Width | 380.970 | 2 | 0.1 | 143.910 | 58.64 | 高 |
| 20879 | 51267 | MG-2015-DK289584-42210 | 2015-07-25 | 2015-07-28 | 一级 | DK-289584 | Dana Kaydos | 消费者 | NaN | Ulan Bator | 乌兰巴托 | 蒙古 | 东亚 | 亚太地区 | FUR-FU-3027 | 家具 | 用具 | Advantus Door Stop, Black | 45.030 | 1 | 0.0 | 9.450 | 11.58 | 高 |
| 23683 | 30075 | IN-2015-TN2104027-42136 | 2015-05-12 | 2015-05-15 | 一级 | TN-2104027 | Tanja Norvell | 家庭办公室 | NaN | Shangqiu | 河南省 | 中国 | 东亚 | 亚太地区 | OFF-AR-3502 | 办公用品 | 艺术 | Binney & Smith Sketch Pad, Water Color | 99.000 | 2 | 0.0 | 13.860 | 9.15 | 高 |
| 46704 | 12192 | ES-2014-AG10675120-41731 | 2014-04-02 | 2014-04-07 | 标准级 | AG-10675120 | Anna Gayman | 消费者 | NaN | Barcelona | 加泰罗尼亚 | 西班牙 | 南欧 | 欧洲 | OFF-BI-3290 | 办公用品 | 装订机 | Avery Hole Reinforcements, Durable | 23.640 | 4 | 0.0 | 8.400 | 1.51 | 媒介 |
# 查看数据行列数
data.shape
>(51290, 24)
# 查看数据的分布概况
data.describe()
| 行 ID | 邮政编码 | 销售额 | 数量 | 折扣 | 利润 | 装运成本 | |
|---|---|---|---|---|---|---|---|
| count | 51290.00000 | 9994.000000 | 51290.000000 | 51290.000000 | 51290.000000 | 51290.000000 | 51290.000000 |
| mean | 25645.50000 | 55190.379428 | 246.490581 | 3.476545 | 0.142908 | 28.610982 | 26.478567 |
| std | 14806.29199 | 32063.693350 | 487.565361 | 2.278766 | 0.212280 | 174.340972 | 57.251373 |
| min | 1.00000 | 1040.000000 | 0.444000 | 1.000000 | 0.000000 | -6599.978000 | 1.002000 |
| 25% | 12823.25000 | 23223.000000 | 30.758625 | 2.000000 | 0.000000 | 0.000000 | 2.610000 |
| 50% | 25645.50000 | 56430.500000 | 85.053000 | 3.000000 | 0.000000 | 9.240000 | 7.790000 |
| 75% | 38467.75000 | 90008.000000 | 251.053200 | 5.000000 | 0.200000 | 36.810000 | 24.450000 |
| max | 51290.00000 | 99301.000000 | 22638.480000 | 14.000000 | 0.850000 | 8399.976000 | 933.570000 |
3.2 对列名格式进行规范
根据上面展示的数据可以发现数据的列名不符合Python的命名规范,列名不应该包含空格,应去除或用下划线连接,这里采用去除空格对列名进行重命名。
data.rename(columns=lambda x:x.replace(' ',''),inplace=True)
data.columns
Index(['行ID', '订单ID', '订购日期', '装运日期', '装运方式', '客户ID', '客户名称', '细分市场', '邮政编码', '城市', '省市', '国家', '地区', '市场', '产品ID', '类别', '子类别', '产品名称', '销售额', '数量', '折扣', '利润', '装运成本', '订单优先级'], dtype='object')
3.3 数据类型处理
# 查看各列数据类型
# data.info()
data.dtypes
行ID int64
订单ID object
订购日期 datetime64[ns]
装运日期 datetime64[ns]
装运方式 object
客户ID object
客户名称 object
细分市场 object
邮政编码 float64
城市 object
省市 object
国家 object
地区 object
市场 object
产品ID object
类别 object
子类别 object
产品名称 object
销售额 float64
数量 int64
折扣 float64
利润 float64
装运成本 float64
订单优先级 object
dtype: object
可以看到各列数据类型与其字段数据值相符,因此不需要进行数据类型转换。
为了 方便分析每年和每月的销售情况,增加“Year”和“Month”列:
data['Year'] = data['订购日期'].dt.year
data['Month'] = data['订购日期'].values.astype('datetime64[M]')
data[['Year','Month']].head()
| Year | Month | |
|---|---|---|
| 0 | 2014 | 2014-11-01 |
| 1 | 2014 | 2014-02-01 |
| 2 | 2014 | 2014-10-01 |
| 3 | 2014 | 2014-01-01 |
| 4 | 2014 | 2014-11-01 |
3.4 缺失值处理
# 查看各字段的数据是否存在缺失
data.isnull().any()
行ID False
订单ID False
订购日期 False
装运日期 False
装运方式 False
客户ID False
客户名称 False
细分市场 False
邮政编码 True
城市 False
省市 False
国家 False
地区 False
市场 False
产品ID False
类别 False
子类别 False
产品名称 False
销售额 False
数量 False
折扣 False
利润 False
装运成本 False
订单优先级 False
Year False
Month False
dtype: bool
# 发现只有邮政编码存在缺失值,统计查看一下存在多少缺失值(行数是51290)
data['邮政编码'].isnull().sum()
41296
发现邮政编码列几乎80%都是缺失值,显然该列已经对我们的分析没有太大作用,因此进行删除。
data.drop('邮政编码', axis=1, inplace=True)
3.5 异常值处理
data.describe()
| 行ID | 销售额 | 数量 | 折扣 | 利润 | 装运成本 | Year | |
|---|---|---|---|---|---|---|---|
| count | 51290.00000 | 51290.000000 | 51290.000000 | 51290.000000 | 51290.000000 | 51290.000000 | 51290.000000 |
| mean | 25645.50000 | 246.490581 | 3.476545 | 0.142908 | 28.610982 | 26.478567 | 2013.777208 |
| std | 14806.29199 | 487.565361 | 2.278766 | 0.212280 | 174.340972 | 57.251373 | 1.098931 |
| min | 1.00000 | 0.444000 | 1.000000 | 0.000000 | -6599.978000 | 1.002000 | 2012.000000 |
| 25% | 12823.25000 | 30.758625 | 2.000000 | 0.000000 | 0.000000 | 2.610000 | 2013.000000 |
| 50% | 25645.50000 | 85.053000 | 3.000000 | 0.000000 | 9.240000 | 7.790000 | 2014.000000 |
| 75% | 38467.75000 | 251.053200 | 5.000000 | 0.200000 | 36.810000 | 24.450000 | 2015.000000 |
| max | 51290.00000 | 22638.480000 | 14.000000 | 0.850000 | 8399.976000 | 933.570000 | 2015.000000 |
从上面展示的结果可以确定没有明显的异常值,因此不需要进行处理。
3.6 重复值处理
# 查看是否存在完全重复的行:
data.duplicated().sum()
0
0说明没有完全重复的记录,因此不需要进行处理
四、数据分析
4.1 整体销售情况分析
首先构造整体销售情况的数据子集:
- 包含:订购日期、年份、月份、销售额、销量、利润
sales_data = data[['订购日期','Year','Month','销售额','数量','利润']]
sales_data.head()
| 订购日期 | Year | Month | 销售额 | 数量 | 利润 | |
|---|---|---|---|---|---|---|
| 0 | 2014-11-11 | 2014 | 2014-11-01 | 221.980 | 2 | 62.1544 |
| 1 | 2014-02-05 | 2014 | 2014-02-01 | 3709.395 | 9 | -288.7650 |
| 2 | 2014-10-17 | 2014 | 2014-10-01 | 5175.171 | 9 | 919.9710 |
| 3 | 2014-01-28 | 2014 | 2014-01-01 | 2892.510 | 5 | -96.5400 |
| 4 | 2014-11-05 | 2014 | 2014-11-01 | 2832.960 | 8 | 311.5200 |
按照年、月对销售数据子集进行分组求和统计:
sales_year_grouped = sales_data.groupby(by=['Month']).agg('sum')
sales_year_grouped.sample(5)
| Year | 销售额 | 数量 | 利润 | |
|---|---|---|---|---|
| Month | ||||
| 2014-10-01 | 2215400 | 293406.64288 | 3883 | 42433.22258 |
| 2012-01-01 | 871196 | 98898.48886 | 1463 | 8321.80096 |
| 2014-04-01 | 1580990 | 177821.31684 | 2688 | 19462.03844 |
| 2012-08-01 | 1740380 | 208063.28372 | 3020 | 26452.99742 |
| 2014-12-01 | 3226428 | 405454.37802 | 5694 | 50202.87112 |
对上面进行分组求和后的数据进行拆分,将每一年的数据分配一张独立的表:
year_2012 = sales_year_grouped['2012':'2012'].reset_index()
year_2013 = sales_year_grouped['2013':'2013'].reset_index()
year_2014 = sales_year_grouped['2014':'2014'].reset_index()
year_2015 = sales_year_grouped['2015':'2015'].reset_index()
year_2015
| Month | Year | 销售额 | 数量 | 利润 | |
|---|---|---|---|---|---|
| 0 | 2015-01-01 | 1849770 | 241268.55566 | 3122 | 28001.38626 |
| 1 | 2015-02-01 | 1523340 | 184837.35556 | 2482 | 19751.69996 |
| 2 | 2015-03-01 | 2152020 | 263100.77262 | 3722 | 37357.26052 |
| 3 | 2015-04-01 | 2117765 | 242771.86130 | 3594 | 23782.30120 |
| 4 | 2015-05-01 | 2587260 | 288401.04614 | 4300 | 33953.55774 |
| 5 | 2015-06-01 | 3522220 | 401814.06310 | 6009 | 43778.60280 |
| 6 | 2015-07-01 | 2190305 | 258705.68048 | 3637 | 28035.87258 |
| 7 | 2015-08-01 | 3375125 | 456619.94236 | 5824 | 53542.89496 |
| 8 | 2015-09-01 | 4066270 | 481157.24370 | 6837 | 67979.45110 |
| 9 | 2015-10-01 | 3276390 | 422766.62916 | 5876 | 58209.83476 |
| 10 | 2015-11-01 | 4326205 | 555279.02700 | 7706 | 62856.58790 |
| 11 | 2015-12-01 | 4338295 | 503143.69348 | 7513 | 46916.52068 |
4.1.1 销售额分析(按月)
# 构建销售额表
sales = pd.concat([year_2012['销售额'],year_2013['销售额'],
year_2014['销售额'],year_2015['销售额']],axis=1)
# 重构行列名
sales.index = [str(i+1)+'月' for i in range(12)]
sales.columns = ['sales_2012','sales_2013','sales_2014','sales_2015']
# 绘制热力图,颜色越深表示销售额越高
plt.figure(figsize=(8,6))
sns.heatmap(sales,cmap='RdPu',annot=True,fmt='.2f',linewidths=0.5)
# plt.yticks(rotation=90)
plt.show()
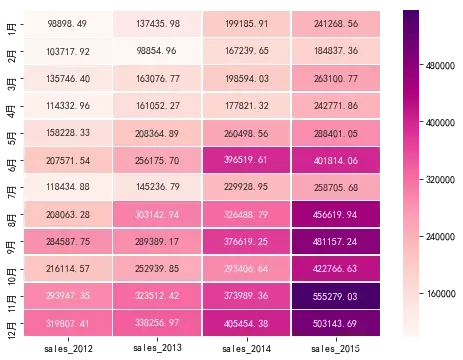
从上图可以看出,基本每年的下半年的销售额都比上半年要高,而且随着年份的增长,销售额也在逐年增加,可以说明该超市的发展还是比较好的。
肉眼可以看见每一年的销售额都比前一年要好,那么现在来实际计算一下每年的销售总额和具体的增长率:
# 每年的总销售额
sales_sum = sales.sum()
# 计算销售额增长率
rise_rates = [0]
for i in range(len(sales_sum)-1):
rise_rate = round((sales_sum[i+1]-sales_sum[i])/sales_sum[i],4)
rise_rates.append(rise_rate)
rise_rates
[0, 0.185, 0.272, 0.2625]
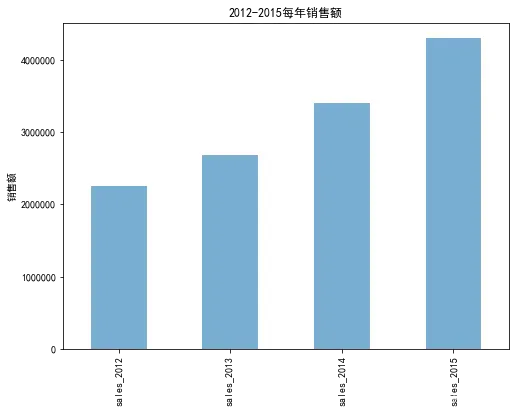
# 可视化每年销售额
sales_sum.plot(kind='bar', alpha=0.6, figsize=(8,6))
plt.ylabel('销售额')
plt.title('2012-2015每年销售额')
plt.show()
# 可视化销售额增长率
rise_rates = pd.Series(rise_rates)
rise_rates.index = sales_sum.index
rise_rates.plot(color = 'r', figsize=(8,6))
plt.title('2012-2015每年销售额增长率变化趋势')
plt.ylim(0,0.5)
plt.show()
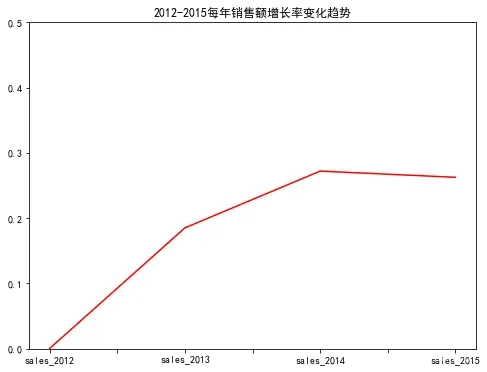
从上面可以看出,后两年销售额增长率达到26%,2015年销售额相比2012年,将近翻了一番,发展势头良好,经营在逐步稳定。结合年度销售额和增长率进行战略规划,可以规划或制定下一年度总销售额业绩指标。
了解了超市整体销售额后,在对每年每月的销售额进行分析。了解不同月份的销售情况,探究是否有淡旺季之分,找出重点销售月份,以便制定经营策略与业绩月度及季度指标拆分。
首先来看一下每年每月销售额的面积堆积图:
sales.plot.area(stacked=False,figsize=(8,6))
plt.title('每年每月的销售额变化')
plt.show()
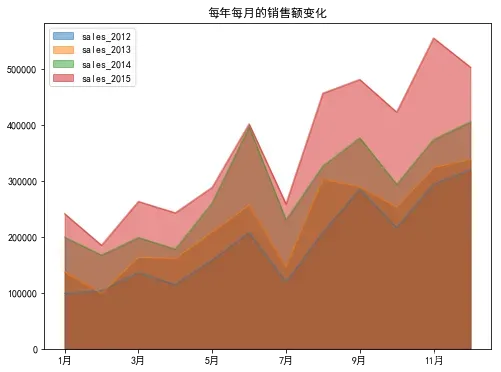
从面积图可以大致看出该超市的销售存在季节性差异,总体情况是上半年为淡季,下半年为旺季。其中上半年6月份的销售额比较高,下半年的7月份销售额偏低。对此可采取的措施:
- 1、对于旺季的月份,运营推广的策略要继续维持,也可以加大投入,提高整体销售额。
- 2、对于淡季的月份,可以适当减少库存,也可以结合产品特点拓展新品,同时举办一些促销活动等来吸引用户。
4.1.2 销量分析(按月)
# 构建销量表
quantity = pd.concat([year_2012['数量'],year_2013['数量'],
year_2014['数量'],year_2015['数量']],axis=1)
# 重构行列名
quantity.index = [str(i+1)+'月' for i in range(12)]
quantity.columns = ['Quantity_2012','Quantity_2013','Quantity_2014','Quantity_2015']
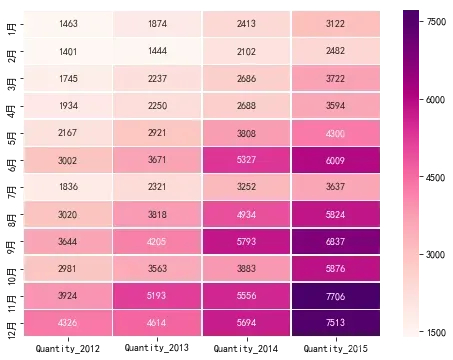
# 绘制热力图,颜色越深表示销量越高
plt.figure(figsize=(8,6))
sns.heatmap(quantity, cmap='RdPu', annot=True,fmt='d', linewidths=0.5)
plt.show()
# 计算每年销量
quantity_sum = quantity.sum()
# 计算销量增长率
rise_rates_quantity = [0]
for i in range(len(quantity_sum)-1):
rise_rate = round((quantity_sum[i+1]-quantity_sum[i])/quantity_sum[i],4)
rise_rates_quantity.append(rise_rate)
rise_rates_quantity
[0, 0.2121, 0.263, 0.2594]
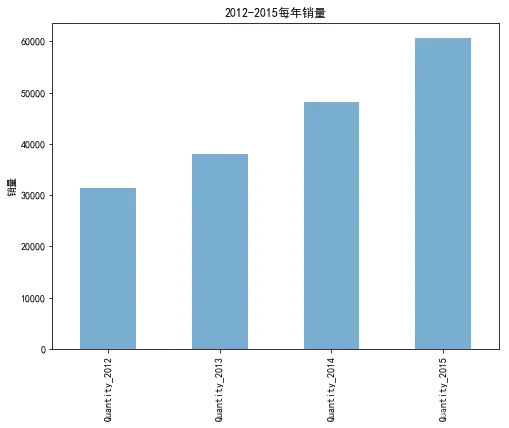
# 可视化每年销量
quantity_sum.plot(kind='bar', alpha=0.6, figsize=(8,6))
plt.ylabel('销量')
plt.title('2012-2015每年销量')
plt.show()
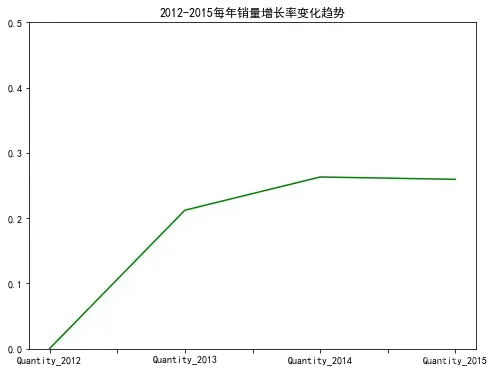
# 可视化销量增长率
rise_rates_quantity = pd.Series(rise_rates_quantity)
rise_rates_quantity.index = quantity_sum.index
rise_rates_quantity.plot(color = 'g', figsize=(8,6))
plt.title('2012-2015每年销量增长率变化趋势')
plt.ylim(0,0.5)
plt.show()
quantity.plot.area(stacked=False,figsize=(8,6))
plt.title('每年每月的销量变化')
plt.show()
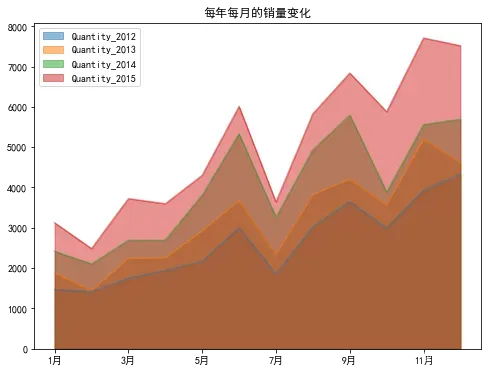
可以看出2012-2014年销量的变化趋势和销售额是一样的,下半年销量整体高于上半年,同时销量同比上一年均是在不断提升。
4.1.3 利润分析
# 构建利润表
profit = pd.concat([year_2012['利润'],year_2013['利润'],
year_2014['利润'],year_2015['利润']],axis=1)
# 重构行列名
profit.index = [str(i+1)+'月' for i in range(12)]
profit.columns = ['profit_2012','profit_2013','profit_2014','profit_2015']
# 绘制热力图,颜色越深表示利润越高
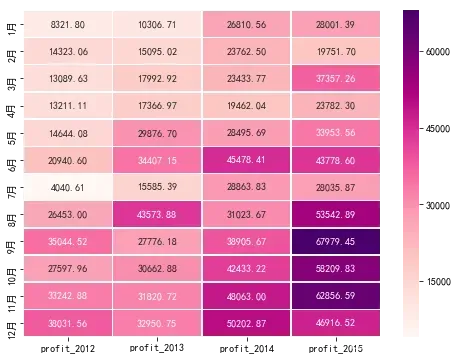
plt.figure(figsize=(8,6))
sns.heatmap(profit, cmap='RdPu', annot=True,fmt='.2f', linewidths=0.5)
plt.show()
# 计算每年利润
profit_sum = profit.sum()
# 计算利润率
profit_sum = pd.DataFrame({'profit_sum':profit_sum})
profit_sum['sales_sum'] = sales.sum().values
profit_sum['profit_rate'] = profit_sum['profit_sum']/profit_sum['sales_sum']
profit_sum
| profit_sum | sales_sum | profit_rate | |
|---|---|---|---|
| profit_2012 | 248940.81154 | 2.259451e+06 | 0.110178 |
| profit_2013 | 307415.27910 | 2.677439e+06 | 0.114817 |
| profit_2014 | 406935.23018 | 3.405746e+06 | 0.119485 |
| profit_2015 | 504165.97046 | 4.299866e+06 | 0.117252 |
# 可视化每年总利润
profit_sum['profit_sum'].plot(kind='bar',alpha=0.6)
plt.title('2012-2015年每年总利润')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-avBhIgA8-1666229503178)(output_54_0.png)]](https://aitechtogether.com/wp-content/uploads/2023/06/3f9c9734-39ed-4644-aed1-9ef3c276ea38.webp)
# 可视化利润率
profit_sum['profit_rate'].plot(color = 'b',figsize=(8,6))
plt.title('2012-2015年利润变化趋势')
plt.ylim(0,0.5)
plt.show()
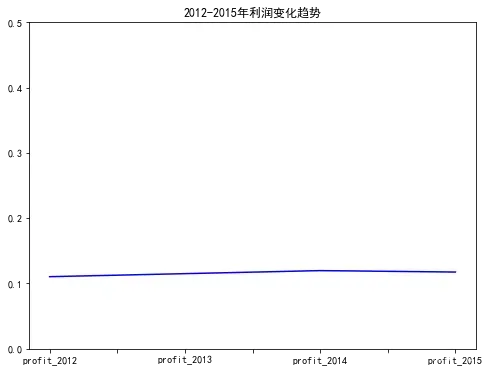
从上面的结果可以看出,每年的利润变化趋势跟销售额一样,都是在逐年增加,说明企业经营情况良好。但是利润率总体平稳,稳定在11%-12%之间,总体还是不错的。
4.1.4 客单价分析(按年)
客单价是指超市每一位客户平均购买商品的金额,即平均交易金额。
从某种程度上反映了企业的消费群体的许多特点以及企业的销售类目的盈利状态是否健康。
其中,需要注意的有:
- 计算总消费次数要将同一天内同一个客户发生的所有消费算作一次消费;
- 客单价 = 总消费金额 ÷ 总消费次数
data.head()
| 行ID | 订单ID | 订购日期 | 装运日期 | 装运方式 | 客户ID | 客户名称 | 细分市场 | 城市 | 省市 | 国家 | 地区 | 市场 | 产品ID | 类别 | 子类别 | 产品名称 | 销售额 | 数量 | 折扣 | 利润 | 装运成本 | 订单优先级 | Year | Month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 40098 | CA-2014-AB10015140-41954 | 2014-11-11 | 2014-11-13 | 一级 | AB-100151402 | Aaron Bergman | 消费者 | Oklahoma City | 俄克拉何马州 | 美国 | 美国中部 | 美国 | TEC-PH-5816 | 技术 | 电话 | Samsung Convoy 3 | 221.980 | 2 | 0.0 | 62.1544 | 40.77 | 高 | 2014 | 2014-11-01 |
| 1 | 26341 | IN-2014-JR162107-41675 | 2014-02-05 | 2014-02-07 | 二级 | JR-162107 | Justin Ritter | 公司 | Wollongong | 新南威尔士 | 澳大利亚 | 大洋洲 | 亚太地区 | FUR-CH-5379 | 家具 | 椅子 | Novimex Executive Leather Armchair, Black | 3709.395 | 9 | 0.1 | -288.7650 | 923.63 | 紧急 | 2014 | 2014-02-01 |
| 2 | 25330 | IN-2014-CR127307-41929 | 2014-10-17 | 2014-10-18 | 一级 | CR-127307 | Craig Reiter | 消费者 | Brisbane | 昆士兰州 | 澳大利亚 | 大洋洲 | 亚太地区 | TEC-PH-5356 | 技术 | 电话 | Nokia Smart Phone, with Caller ID | 5175.171 | 9 | 0.1 | 919.9710 | 915.49 | 媒介 | 2014 | 2014-10-01 |
| 3 | 13524 | ES-2014-KM1637548-41667 | 2014-01-28 | 2014-01-30 | 一级 | KM-1637548 | Katherine Murray | 家庭办公室 | 柏林 | 柏林 | 德国 | 西欧 | 欧洲 | TEC-PH-5267 | 技术 | 电话 | Motorola Smart Phone, Cordless | 2892.510 | 5 | 0.1 | -96.5400 | 910.16 | 媒介 | 2014 | 2014-01-01 |
| 4 | 47221 | SG-2014-RH9495111-41948 | 2014-11-05 | 2014-11-06 | 当日 | RH-9495111 | Rick Hansen | 消费者 | 达喀尔 | 达喀尔 | 塞内加尔 | 西非 | 非洲 | TEC-CO-6011 | 技术 | 复印机 | Sharp Wireless Fax, High-Speed | 2832.960 | 8 | 0.0 | 311.5200 | 903.04 | 紧急 | 2014 | 2014-11-01 |
total_num_list = []
unit_price_list = []
for i in range(2012,2016):
df = data[data['Year']==i]
price = df[['订购日期','客户ID','销售额']]
# 计算每年总消费次数
price_dr = price.drop_duplicates(['订购日期','客户ID'])
# 总消费次数统计
total_num_list.append(price_dr.shape[0])
# 客单价
unit_price_list.append(round(price['销售额'].sum()/price_dr.shape[0],3))
unit_price = pd.DataFrame({'total_num':total_num_list,
'unit_price':unit_price_list})
unit_price.index = [str(i) for i in range(2012,2016)]
unit_price
| total_num | unit_price | |
|---|---|---|
| 2012 | 4512 | 500.765 |
| 2013 | 5473 | 489.209 |
| 2014 | 6883 | 494.806 |
| 2015 | 8851 | 485.806 |
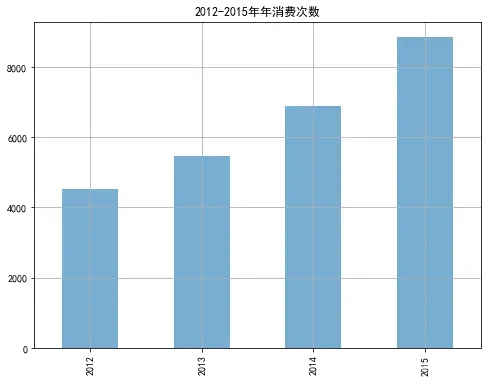
# 可视化每年消费次数
unit_price['total_num'].plot(kind='bar',alpha=0.6,figsize=(8,6))
plt.grid() # 设置网格线
plt.title('2012-2015年年消费次数')
plt.show()
# 可视化每年客单价
unit_price['unit_price'].plot(figsize=(8,6))
plt.ylim(400,550)
plt.grid()
plt.title('2012-2015年客单价变化趋势')
plt.show()
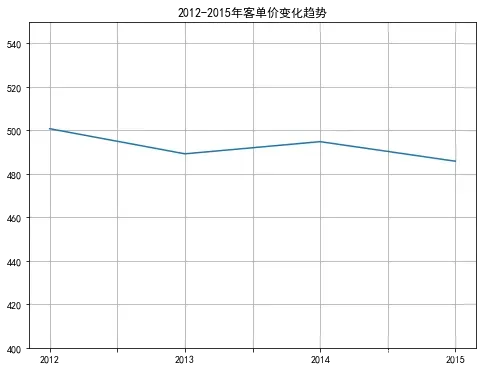
从上面图表来看,每年的消费次数呈不断上升趋势,但是客单价总体波动不大,基本稳定在500左右。
4.1.5 市场布局分析
因为这是宜家全球超市,在不同地区都有市场,因此来看一下不同地区之间的销售情况:
Market_year_sales = data.groupby(['市场','Year']).agg({'销售额':'sum'}).reset_index()
Market_year_sales
| 市场 | Year | 销售额 | |
|---|---|---|---|
| 0 | 亚太地区 | 2012 | 7.136582e+05 |
| 1 | 亚太地区 | 2013 | 8.639840e+05 |
| 2 | 亚太地区 | 2014 | 1.092232e+06 |
| 3 | 亚太地区 | 2015 | 1.372784e+06 |
| 4 | 拉丁美洲 | 2012 | 3.850982e+05 |
| 5 | 拉丁美洲 | 2013 | 4.647333e+05 |
| 6 | 拉丁美洲 | 2014 | 6.081408e+05 |
| 7 | 拉丁美洲 | 2015 | 7.066329e+05 |
| 8 | 欧洲 | 2012 | 5.407506e+05 |
| 9 | 欧洲 | 2013 | 7.176114e+05 |
| 10 | 欧洲 | 2014 | 8.486702e+05 |
| 11 | 欧洲 | 2015 | 1.180304e+06 |
| 12 | 美国 | 2012 | 4.927566e+05 |
| 13 | 美国 | 2013 | 4.866293e+05 |
| 14 | 美国 | 2014 | 6.276350e+05 |
| 15 | 美国 | 2015 | 7.571081e+05 |
| 16 | 非洲 | 2012 | 1.271873e+05 |
| 17 | 非洲 | 2013 | 1.444807e+05 |
| 18 | 非洲 | 2014 | 2.290688e+05 |
| 19 | 非洲 | 2015 | 2.830364e+05 |
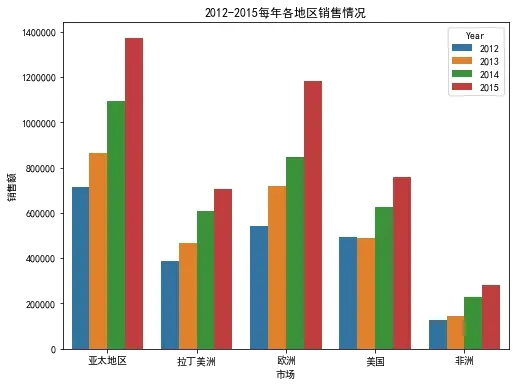
# 可视化各地区销售额
plt.figure(figsize=(8,6))
sns.barplot(data=Market_year_sales,x='市场',y='销售额',hue='Year')
plt.title('2012-2015每年各地区销售情况')
plt.show()
再来看看这四年各地区销售额占总销售额的百分比:
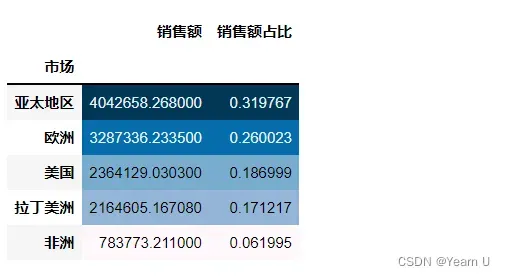
Market_sales = data.groupby(['市场']).agg({'销售额':'sum'})
Market_sales['销售额占比'] = Market_sales['销售额']/data['销售额'].sum()
Market_sales.sort_values(by='销售额占比',ascending=False,inplace=True)
# 颜色越深,说明销售额和占比越大
Market_sales.style.background_gradient()
Market_sales['销售额占比'].plot.pie(autopct='%.2f%%', explode=[0.015 for i in range(len(Market_sales))],figsize=(8,6))
plt.axis('equal')
plt.title('2012-2015年各地区销售额占总销售额的百分比')
plt.show()
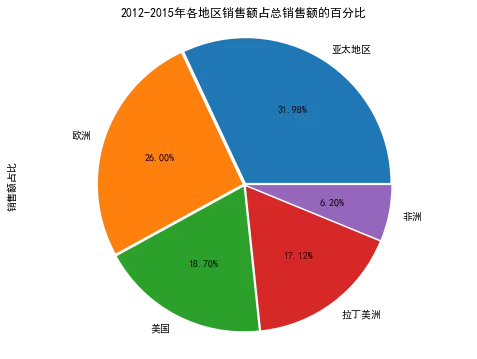
从以上图表可以看出,每个地区每年销售额总体处于上升趋势,其中亚太地区、欧洲、美国、拉丁美洲的销售额就超过了总销售额的90%,总体也与地区的经济发展相匹配。其中,非洲的销售额占比相比其它市场比较低,可以结合公司的整体战略布局进行调整。
4.2 商品情况分析
首先统计销量前10的商品:
product_count = data.groupby('产品ID').agg({'数量':'sum'}).sort_values(by='数量',ascending=False).reset_index()
product_count.head(10)
| 产品ID | 数量 | |
|---|---|---|
| 0 | OFF-FA-6129 | 876 |
| 1 | OFF-BI-3737 | 337 |
| 2 | OFF-ST-4057 | 321 |
| 3 | OFF-ST-5693 | 262 |
| 4 | OFF-AR-5923 | 259 |
| 5 | OFF-FA-6189 | 253 |
| 6 | OFF-BI-3293 | 252 |
| 7 | OFF-BI-4828 | 251 |
| 8 | OFF-ST-6033 | 250 |
| 9 | OFF-AR-6120 | 242 |
统计销售额前10的商品:
product_amount = data.groupby('产品ID').agg({'销售额':'sum'}).sort_values(by='销售额',ascending=False).reset_index()
product_amount.head(10)
| 产品ID | 销售额 | |
|---|---|---|
| 0 | TEC-PH-3148 | 86935.7786 |
| 1 | TEC-PH-3806 | 76441.5306 |
| 2 | TEC-PH-5268 | 73156.3030 |
| 3 | TEC-PH-5355 | 71904.5555 |
| 4 | TEC-CO-3691 | 61599.8240 |
| 5 | FUR-CH-4654 | 58193.4841 |
| 6 | FUR-CH-5441 | 50661.6840 |
| 7 | FUR-CH-4530 | 50121.5160 |
| 8 | TEC-PH-5839 | 48653.4600 |
| 9 | TEC-PH-5356 | 47877.7857 |
统计利润前10的商品:
product_profit = data.groupby(by='产品ID').sum()['利润'].sort_values(ascending=False)
product_profit.head(10)
产品ID
TEC-CO-3691 25199.9280
TEC-PH-3806 17238.5206
TEC-PH-5268 17027.1130
OFF-AP-4743 11807.9690
FUR-BO-5951 10672.0730
FUR-CH-4530 10427.3260
TEC-PH-5355 9938.1955
TEC-PH-3807 9786.6408
TEC-PH-5356 9465.3257
TEC-AC-3405 8955.0180
Name: 利润, dtype: float64
从上面结果可以看出,销量靠前的大部分是(OFFICE)办公用品;销售额靠前的大部分是电子产品,还有一些是家具商品;利润靠前的也绝大部分是电子产品。因此,可以重点提升电子类产品的销量,从而来增加整体利润。
下面来看一下具体商品种类的销售情况:
# 按照种类和子类进行分组,统计销售额和利润
df_category_sub_category = data.groupby(['类别','子类别']).agg({'销售额':'sum','利润':'sum'})
# 按照销售额倒序排序
df_category_sub_category.sort_values(by='销售额',ascending=False,inplace=True)
# 计算每个类别商品的销售额累计占比
df_category_sub_category['cum_percent'] = df_category_sub_category['销售额'].cumsum()/df_category_sub_category['销售额'].sum()
df_category_sub_category.reset_index(inplace=True)
df_category_sub_category
| 类别 | 子类别 | 销售额 | 利润 | cum_percent | |
|---|---|---|---|---|---|
| 0 | 技术 | 电话 | 1.706824e+06 | 216717.00580 | 0.135007 |
| 1 | 技术 | 复印机 | 1.509436e+06 | 258567.54818 | 0.254401 |
| 2 | 家具 | 椅子 | 1.501682e+06 | 140396.26750 | 0.373181 |
| 3 | 家具 | 书架 | 1.466572e+06 | 161924.41950 | 0.489184 |
| 4 | 办公用品 | 存储 | 1.126813e+06 | 108416.68060 | 0.578313 |
| 5 | 办公用品 | 电器 | 1.010536e+06 | 141562.58770 | 0.658245 |
| 6 | 技术 | 设备 | 7.790601e+05 | 58867.87300 | 0.719867 |
| 7 | 家具 | 桌子 | 7.570419e+05 | -64083.38870 | 0.779748 |
| 8 | 技术 | 附件 | 7.492370e+05 | 129626.30620 | 0.839011 |
| 9 | 办公用品 | 装订机 | 4.618694e+05 | 72433.15160 | 0.875544 |
| 10 | 家具 | 用具 | 3.851560e+05 | 46845.43190 | 0.906010 |
| 11 | 办公用品 | 艺术 | 3.716132e+05 | 57829.85930 | 0.935403 |
| 12 | 办公用品 | 用品 | 2.428111e+05 | 22559.19530 | 0.954609 |
| 13 | 办公用品 | 纸张 | 2.417875e+05 | 58111.65350 | 0.973734 |
| 14 | 办公用品 | 信封 | 1.692175e+05 | 28849.48730 | 0.987119 |
| 15 | 办公用品 | 系固件 | 8.949505e+04 | 13844.28890 | 0.994198 |
| 16 | 办公用品 | 标签 | 7.335028e+04 | 14988.92370 | 1.000000 |
# !pip install waterfallcharts # 安装第三方瀑布图库
import waterfall_chart
waterfall_chart.plot(df_category_sub_category['子类别'],
df_category_sub_category['cum_percent'],
rotation_value=90,
formatting='{:,.2f}',
net_label = '销售额总计')
plt.ylim(0,15)
plt.show()
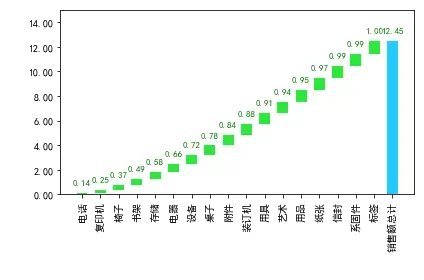
- 从以上图表可以清晰的看到不同种类商品的销售额贡献对比,差不多一半种类的商品的总销售额占比就达到了84%,这部分商品应是自家的优势主营产品,后续经营过程中应继续保持,可结合整体战略发展适当加大投入,逐渐形成自己的品牌。
- 同时也发现,末尾销售额累计占比16%的产品中大部分属于办公类产品的小物件,可以考虑与其它主营产品结合,连带销售来提升销量,或者考虑对这些产品进行优化。
- 最值得关注的是,家具品类的桌子的利润是负数,表面这个产品目前词语亏损状态,原因可能是促销让利太多。因为通过查看原数据,发现桌子大部分都在打折,打折的销量高达76%。如果是在清理库存,那属于正常现象,但如果不是,说明这个产品在市场推广中遇到了瓶颈或者是遇到了竞争对手,需要结合实际业务进行分析,适当改善经营策略。
4.3 用户情况分析
4.3.1 不同类型的客户占比分析
首先统计四年所有不同类型的客户占比:
plt.figure(figsize=(8,6))
data['细分市场'].value_counts().plot(kind='pie',autopct='%.2f%%',
explode=[0.015 for i in range(len(data['细分市场'].value_counts()))])
plt.axis('equal')
plt.title('四年所有不同类型的客户占比')
plt.show()
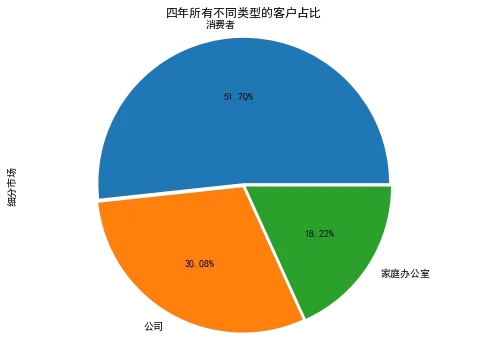
从饼图可以看出,这四年中,普通消费者的客户占比最多,达到了51.7%。
接下来看一下每一年不同类别的客户数情况:
segment_year = data.groupby(['Year','细分市场']).agg({'客户ID':'count'}).reset_index()
plt.figure(figsize=(8,6))
sns.lineplot(data=segment_year,x='Year',y='客户ID',hue='细分市场')
plt.xticks(segment_year['Year'])
plt.title('2012-2015年不同类型的客户数量')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PXuPK43k-1666229503186)(output_86_0.png)]](https://aitechtogether.com/wp-content/uploads/2023/06/9940622b-0ebb-48e1-a146-c06121acbdf3.webp)
从上图可以看出,各类客户每年都呈增长趋势,说明客户结构非常好。
再来看一下每一年不同类别的客户贡献销售额:
segment_amount = data.groupby(['Year','细分市场']).agg({'销售额':'sum'}).reset_index()
plt.figure(figsize=(8,6))
sns.lineplot(data=segment_amount,x='Year',y='销售额',hue='细分市场')
plt.xticks(segment_amount['Year'])
plt.title('2012-2015年不同类型客户的销售额贡献')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VmDWp9Nw-1666229503187)(output_89_0.png)]](https://aitechtogether.com/wp-content/uploads/2023/06/540c6d5e-2ea0-455d-b26f-3cdbdeafc157.webp)
从上图可以看到,各类客户每年贡献的销售额都在稳步上升,普通消费者贡献的销售额最多,当然这与客户群体大小有一定关系。
4.3.2 客户下单行为分析
截取客户ID、订购日期、数量、销售额、Month作为新的数据子集,并对订购日期进行排序,方便后续分析。
customer_df = data[['客户ID','订购日期','数量','销售额','Month']].sort_values(by='订购日期')
customer_grouped = customer_df.groupby('客户ID')
首先,查看一下用户的首购日期分布和最后一次购买日期分布:
customer_grouped.min()['订购日期'].value_counts().plot(figsize=(8,6))
plt.title('用户首购日期分布')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1pgxRZb1-1666229503188)(output_94_0.png)]](https://aitechtogether.com/wp-content/uploads/2023/06/a051ebd1-a0d1-4f6a-9bf6-e3d0022e971d.webp)
customer_grouped.max()['订购日期'].value_counts().plot(figsize=(8,6))
plt.title('用户最后一次购买日期分布')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kTHVexLI-1666229503188)(output_95_0.png)]](https://aitechtogether.com/wp-content/uploads/2023/06/e2057d82-3a27-4793-bf21-f6459a130fbb.webp)
- 从上面可以看出日新增用户的增长速度平稳,稳定在15人左右,说明超市在拉新方面维持的比较好。通过观察最后一次购买日期分布,(最后一次消费距离数据的最大时间两年视为流失,即2013年以前最后消费的用户都是流失用户),可以看到用户的流失保持在10人左右,整体用户数量呈现一个上涨趋势,也验证了超市每年销售额的增长趋势。
接下来看一下只消费过一次的客户数量:
# 查看客户的第一次消费和最后一次消费时间
custom_life = customer_grouped['订购日期'].agg(['max','min'])
# 统计第一次消费时间和最后一次消费时间相同的客户。
(custom_life['max']==custom_life['min']).value_counts()
True 11985
False 5430
dtype: int64
从结果来看,只购买一次的用户是购买多次的用户的两倍多,可以看出超市的用户流失严重,并没有采取很好的用户留存措施,导致很多用户只消费了一次就不再消费了,因此,超市可以采取一些会员制、促销活动等策略增加客户粘性,提高用户留存。
4.3.3 用户分层:RFM模型
RFM的含义:
- R(Recency):客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
- F(Frequency):客户最近一段时间交易的次数。F越大,交易越频繁,反之,说明客户交易不够活跃。
- M(Monetary):客户在最近一段时间内交易的金额。M值越大,说明客户价值越高,反之,客户价值越低。
RFM模型分析就是根据客户活跃长度和交易金额贡献,进行客户价值细分的一种方法。
首先构建RFM表:
rfm = data.groupby('客户ID').agg({'订购日期':'max','订单ID':'count','销售额':'sum'})
# 以所有用户中最大的交易日期为准,求每个用户最近一次交易的时间间隔R
rfm['R'] = -(rfm.订购日期.max()-rfm.订购日期)/np.timedelta64(1,'D') # 去除days的单位
# 每个客户的订单ID数即为F,销售额为M
rfm.rename(columns={'订单ID':'F','销售额':'M'}, inplace=True)
rfm = rfm[['R','F','M']]
rfm.head()
| R | F | M | |
|---|---|---|---|
| 客户ID | |||
| AA-10315102 | -358.0 | 6 | 544.656 |
| AA-10315120 | -959.0 | 1 | 2713.410 |
| AA-10315139 | -149.0 | 13 | 2955.798 |
| AA-103151402 | -184.0 | 6 | 4780.552 |
| AA-103151404 | -818.0 | 3 | 753.508 |
接下来对客户价值进行标注,将客户划分为8个等级。
客户价值判断标准:以R、F、M各自的均值作为判别标准,超过均值则为1,反之则为0。
def rfm_func(x):
level = x.apply(lambda x:'1' if x>0 else '0')
level = level.R + level.F + level.M
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户'}
return d[level]
rfm['Label'] = rfm.apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
rfm.head()
| R | F | M | Label | |
|---|---|---|---|---|
| 客户ID | ||||
| AA-10315102 | -358.0 | 6 | 544.656 | 一般价值客户 |
| AA-10315120 | -959.0 | 1 | 2713.410 | 重要发展客户 |
| AA-10315139 | -149.0 | 13 | 2955.798 | 重要价值客户 |
| AA-103151402 | -184.0 | 6 | 4780.552 | 重要价值客户 |
| AA-103151404 | -818.0 | 3 | 753.508 | 重要保持客户 |
接着对重要价值客户和非重要价值客户进行可视化展示:
rfm['Label'].value_counts().plot(kind = 'pie',autopct='%.2f%%',
shadow=True,center=(0.2,0.2))
plt.axis('equal')
plt.title('各类价值客户占比',fontsize=16)
plt.ylabel('') # 去掉y坐标轴标题
plt.show()
![可能有0)(output_108_0.png)]](https://aitechtogether.com/wp-content/uploads/2023/06/f1f7037d-4755-49ed-9db2-44bba6796d97.webp)
通过RFM模型可以识别不同的客户群体,能够衡量客户价值和客户利润创收能力,可以制定个性化的沟通和服务,为更多的营销决策提供有力支持,为企业创造更大的收益。
4.3.4 新用户、活跃用户、不活跃用户和回归用户分析
- 将用户按照每一个月份分成:
- unreg:观望用户,前两个月没买,第三个月才第一次购买,则用户前两个月为观望用户
- unactive:首月购买后,后续月份没有购买则在没有购买的月份中该用户为非活跃用户
- new:当前月就进行首次购买的用户在当前月为新用户
- active:连续月份购买的用户在这些月中为活跃用户
- return:购买之后间隔n个月后再次购买的第一个月份为该月份的回头客。
创建透视表,统计每一个月每个用户的购买次数:
pivoted_counts = data.pivot_table(index='客户ID',columns='Month',values='订购日期',aggfunc='count').fillna(0)
# 统计每个用户每个月是否消费,消费了设为1,没有消费设为0
df_purchase = pivoted_counts.applymap(lambda x : 1 if x>0 else 0)
df_purchase.head()
| Month | 2012-01-01 | 2012-02-01 | 2012-03-01 | 2012-04-01 | 2012-05-01 | 2012-06-01 | 2012-07-01 | 2012-08-01 | 2012-09-01 | 2012-10-01 | 2012-11-01 | 2012-12-01 | 2013-01-01 | 2013-02-01 | 2013-03-01 | 2013-04-01 | 2013-05-01 | 2013-06-01 | 2013-07-01 | 2013-08-01 | 2013-09-01 | 2013-10-01 | 2013-11-01 | 2013-12-01 | 2014-01-01 | 2014-02-01 | 2014-03-01 | 2014-04-01 | 2014-05-01 | 2014-06-01 | 2014-07-01 | 2014-08-01 | 2014-09-01 | 2014-10-01 | 2014-11-01 | 2014-12-01 | 2015-01-01 | 2015-02-01 | 2015-03-01 | 2015-04-01 | 2015-05-01 | 2015-06-01 | 2015-07-01 | 2015-08-01 | 2015-09-01 | 2015-10-01 | 2015-11-01 | 2015-12-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 客户ID | ||||||||||||||||||||||||||||||||||||||||||||||||
| AA-10315102 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AA-10315120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AA-10315139 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| AA-103151402 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| AA-103151404 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
# 定义函数将df_purchase中的数据0和1转换为new、unactive、active、unreg、return状态。
def active_status(data):
status = []
for i in range(len(df_purchase.columns)):
# 本月未消费
if data[i] == 0:
if len(status) > 0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 本月消费量
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unreg':
status.append('new')
elif status[i-1] == 'unactive':
status.append('return')
else:
status.append('active')
return status
purchase_status = df_purchase.apply(active_status,axis=1)
purchase_status.head()
客户ID
AA-10315102 [unreg, unreg, unreg, unreg, unreg, unreg, new...
AA-10315120 [unreg, unreg, unreg, unreg, unreg, unreg, unr...
AA-10315139 [unreg, unreg, unreg, unreg, unreg, unreg, unr...
AA-103151402 [unreg, unreg, unreg, unreg, unreg, unreg, unr...
AA-103151404 [unreg, unreg, new, unactive, unactive, unacti...
dtype: object
purchase_status_ct = purchase_status.apply(lambda x:pd.Series(x))
# 将标注状态的列名修改回月份
purchase_status_ct.columns = df_purchase.columns
# 在实际场景中,任何没注册的人都可以是unreg,所以没有意义,用NaN替换“unreg”或后面进行删除
# 统计每个月各状态的客户数量
purchase_status_ct = purchase_status_ct.apply(lambda x:pd.value_counts(x)).head()
purchase_status_ct.head()
| Month | 2012-01-01 | 2012-02-01 | 2012-03-01 | 2012-04-01 | 2012-05-01 | 2012-06-01 | 2012-07-01 | 2012-08-01 | 2012-09-01 | 2012-10-01 | 2012-11-01 | 2012-12-01 | 2013-01-01 | 2013-02-01 | 2013-03-01 | 2013-04-01 | 2013-05-01 | 2013-06-01 | 2013-07-01 | 2013-08-01 | 2013-09-01 | 2013-10-01 | 2013-11-01 | 2013-12-01 | 2014-01-01 | 2014-02-01 | 2014-03-01 | 2014-04-01 | 2014-05-01 | 2014-06-01 | 2014-07-01 | 2014-08-01 | 2014-09-01 | 2014-10-01 | 2014-11-01 | 2014-12-01 | 2015-01-01 | 2015-02-01 | 2015-03-01 | 2015-04-01 | 2015-05-01 | 2015-06-01 | 2015-07-01 | 2015-08-01 | 2015-09-01 | 2015-10-01 | 2015-11-01 | 2015-12-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| active | NaN | NaN | 1 | 5 | 2 | 4 | 5 | 4 | 13 | 14 | 8 | 8 | 7 | 3 | 2 | 7 | 2 | 9 | 9 | 3 | 10 | 15 | 17 | 16 | 11 | 2 | 7 | 4 | 4 | 14 | 13 | 12 | 19 | 15 | 18 | 20 | 15 | 3 | 4 | 2 | 12 | 19 | 15 | 12 | 38 | 28 | 29 | 38.0 |
| new | 215.0 | 202.0 | 264 | 245 | 306 | 430 | 242 | 410 | 464 | 383 | 484 | 519 | 228 | 180 | 267 | 260 | 330 | 483 | 255 | 404 | 494 | 354 | 505 | 437 | 252 | 214 | 290 | 258 | 352 | 517 | 292 | 442 | 518 | 355 | 470 | 459 | 264 | 227 | 292 | 288 | 366 | 499 | 297 | 437 | 526 | 406 | 509 | 524.0 |
| return | NaN | NaN | 1 | 5 | 6 | 15 | 14 | 27 | 36 | 25 | 60 | 65 | 32 | 38 | 69 | 55 | 76 | 75 | 57 | 113 | 131 | 123 | 185 | 167 | 80 | 89 | 114 | 127 | 164 | 188 | 139 | 235 | 286 | 201 | 296 | 340 | 168 | 154 | 232 | 230 | 284 | 371 | 223 | 388 | 438 | 362 | 519 | 514.0 |
| unactive | NaN | 215.0 | 415 | 671 | 918 | 1213 | 1643 | 1873 | 2265 | 2739 | 3093 | 3572 | 4125 | 4351 | 4501 | 4777 | 5021 | 5345 | 5846 | 6051 | 6430 | 6927 | 7217 | 7741 | 8270 | 8522 | 8706 | 8986 | 9207 | 9525 | 10092 | 10289 | 10673 | 11280 | 11537 | 11961 | 12597 | 12887 | 13035 | 13331 | 13555 | 13827 | 14478 | 14613 | 14974 | 15586 | 15834 | 16339.0 |
| unreg | 17200.0 | 16998.0 | 16734 | 16489 | 16183 | 15753 | 15511 | 15101 | 14637 | 14254 | 13770 | 13251 | 13023 | 12843 | 12576 | 12316 | 11986 | 11503 | 11248 | 10844 | 10350 | 9996 | 9491 | 9054 | 8802 | 8588 | 8298 | 8040 | 7688 | 7171 | 6879 | 6437 | 5919 | 5564 | 5094 | 4635 | 4371 | 4144 | 3852 | 3564 | 3198 | 2699 | 2402 | 1965 | 1439 | 1033 | 524 | NaN |
# 用0填充NaN
purchase_status_ct.iloc[:-2,:].fillna(0).T.plot.area(stacked=False,figsize=(8,6))
plt.title('每月各正向状态的用户数量')
plt.show()
purchase_status_ct.iloc[-2,:].fillna(0).T.plot.area(stacked=False,figsize=(8,6))
plt.title('每月不活跃的用户数量')
plt.show()
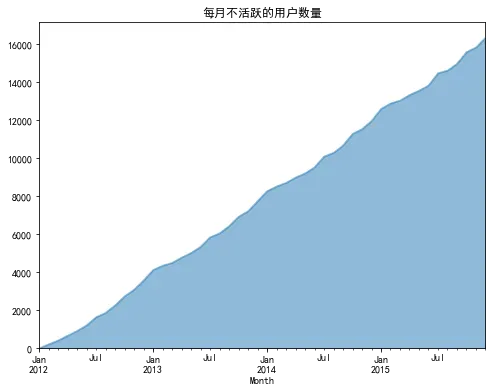
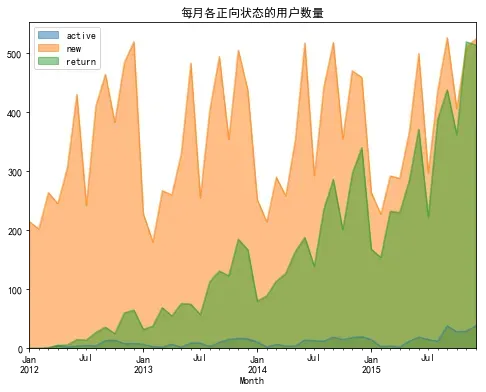
从以上结果可以发现活跃用户、新用户和回归用户,每年呈一定的规律波动,这可能跟年终年末大促销有关,需要更多的数据进行佐证。同时发现不活跃用户数量每月都在不断增加,再次证明了该超市没有实施用户留存相关的策略,导致用户流失严重,如果能在用户留存方面取得突破,会给商家带来很大的增长空间。
4.3.5 复购率和回购率分析
复购计算指标:用户在本月内购买超过一次以上算作一次复购
复购率 = 本月复购次数/本月消费人数
purchase_r = pivoted_counts.applymap(lambda x:1 if x>1 else np.NaN if x==0 else 0)
purchase_r.head()
| Month | 2012-01-01 | 2012-02-01 | 2012-03-01 | 2012-04-01 | 2012-05-01 | 2012-06-01 | 2012-07-01 | 2012-08-01 | 2012-09-01 | 2012-10-01 | 2012-11-01 | 2012-12-01 | 2013-01-01 | 2013-02-01 | 2013-03-01 | 2013-04-01 | 2013-05-01 | 2013-06-01 | 2013-07-01 | 2013-08-01 | 2013-09-01 | 2013-10-01 | 2013-11-01 | 2013-12-01 | 2014-01-01 | 2014-02-01 | 2014-03-01 | 2014-04-01 | 2014-05-01 | 2014-06-01 | 2014-07-01 | 2014-08-01 | 2014-09-01 | 2014-10-01 | 2014-11-01 | 2014-12-01 | 2015-01-01 | 2015-02-01 | 2015-03-01 | 2015-04-01 | 2015-05-01 | 2015-06-01 | 2015-07-01 | 2015-08-01 | 2015-09-01 | 2015-10-01 | 2015-11-01 | 2015-12-01 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 客户ID | ||||||||||||||||||||||||||||||||||||||||||||||||
| AA-10315102 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| AA-10315120 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| AA-10315139 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | 1.0 | NaN | NaN | NaN | NaN |
| AA-103151402 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| AA-103151404 | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
# count是统计本月消费的人数
(purchase_r.sum()/purchase_r.count()).plot(figsize=(8,6))
plt.title('复购率变化趋势')
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4XTklmrn-1666229503193)(output_121_0.png)]](https://aitechtogether.com/wp-content/uploads/2023/06/d351ec22-3992-4bab-8fee-2d0e9208ad39.webp)
回购:在本月购买过,且在相邻下月也购买时计入回购
回购率 = 回购次数/消费人数
def purchase_back(data):
status = []
for i in range(len(data)-1):
# 如果本月购买过
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
# 如果本月未购买
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status)
purchase_b = df_purchase.apply(purchase_back, axis=1)
purchase_b.columns = purchase_r.columns
(purchase_b.sum()/purchase_b.count()).plot(figsize=(8,6))
# plt.xticks(purchase_r.columns)
plt.title('回购率变化趋势')
plt.show()
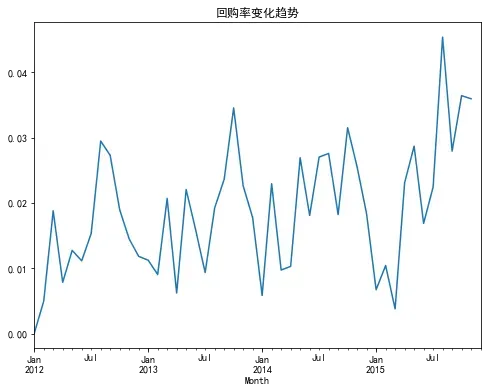
从上面可以发现复购率基本在50%左右,总体波动幅度不大,说明客户忠诚度比较高,回购率在年终年末呈峰形态,可能跟商家促销活动或节日有关。
五、总结
本项目分别通过“场、货、人”三个不同的角度去分析了一家全球超市的销售、商品、用户情况,并根据分析结果给出一些利于拓展用户、提高销量和利润的方法建议。当然,这份数据集包含信息很多,还可以继续进行其它一些方面的分析,来给出更好的建议和业务决策支持。
文章出处登录后可见!