文章目录
- ChatGLM-Med
- 推理过程
- 微调过程
- HuaTuo
- 配置环境
- 模型下载
- 推理过程
- 微调过程
如何基于领域知识对类ChatGPT模型进行微调,以提升类ChatGPT模型在领域的问答效果?
有下面两个模型,一起来看看微调后的效果如何。
ChatGLM-Med: 基于中文医学知识的ChatGLM模型微调
HuaTuo:基于中文医学知识的LLaMA微调模型
ChatGLM-Med
使用模型:ChatGLM-6B
所用微调数据集:医学知识图谱和GPT3.5 API构建的中文医学指令数据集。
环境准备:因为该项目使用的是ChatGLM-6B模型,因此环境也与ChatGLM-6B模型的环境一致,我这里之前微调过,所以直接使用chatglm-6b的conda环境。可以参考此文。
文件准备:将项目和模型文件下载下来
git clone https://github.com/SCIR-HI/Med-ChatGLM.git
模型文件下载:
该项目已经提供了训练微调好的模型参数,直接通过百度云盘链接或Google云盘链接下载即可。
我这里将模型文件下载到 /data/sim_chatgpt/ChatGLM-Med/ 下。
修改 infer.py 文件中的文件加载路径,如下:
import torch
from transformers import AutoTokenizer, AutoModel
from modeling_chatglm import ChatGLMForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained(
"/data/sim_chatgpt/ChatGLM-Med/", trust_remote_code=True)
model = ChatGLMForConditionalGeneration.from_pretrained(
"/data/sim_chatgpt/ChatGLM-Med").half().cuda()
while True:
a = input("请输入您的问题:(输入q以退出)")
if a.strip() == 'q':
exit()
response, history = model.chat(tokenizer, "问题:" + a.strip() + '\n答案:', max_length=256, history=[])
print("回答:", response)
运行报错
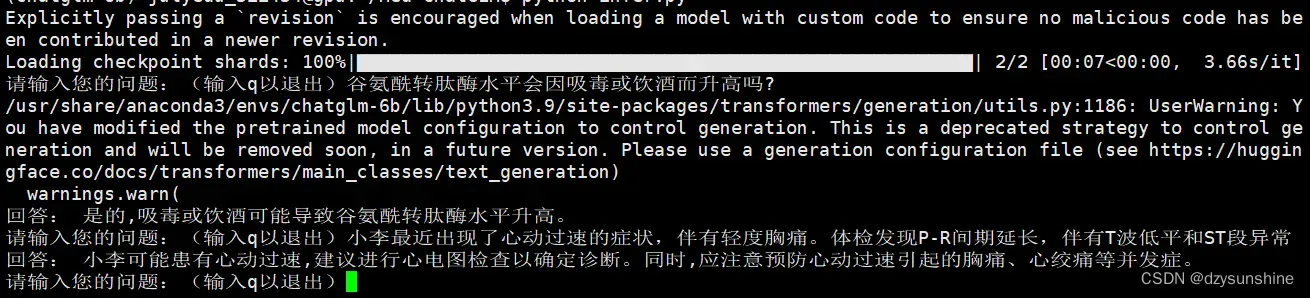
推理过程
python infer.py

解决办法
修改 modeling_chatglm.py 文件的831行,975行,如下:
MASK, gMASK = 150000, 150001
修改后成功运行
微调过程
安装evaluate包
pip install evaluate
pip install wandb
修改要运行文件中的model_name_or_path,修改为 /data/sim_chatgpt/chatglm-6b,如下:
vi scripts/sft_medchat.sh
wandb online
exp_tag="chatglm_tuning"
python run_clm.py \
--model_name_or_path /data/sim_chatgpt/chatglm-6b \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--train_file ./data/train.txt \
--max_seq_length 256 \
--output_dir ./output/ \
--do_train \
--logging_steps 30 \
--log_file ./log/$exp_tag \
--gradient_accumulation_steps 2 \
--learning_rate 5e-5 \
--group_by_length False \
--num_train_epochs 3 \
--lr_scheduler_type linear \
--warmup_ratio 0.1 \
--logging_dir ./log \
--logging_steps 10 \
--save_strategy epoch \
--seed 2023 \
--remove_unused_columns False \
--torch_dtype auto \
--adam_epsilon 1e-3 \
--report_to wandb \
--run_name $exp_tag
执行命令
sh scripts/sft_medchat.sh

尝试调小batch_size,将per_device_train_batch_size改为1试下,仍然cuda of memory,放弃。
官方是在一张A100-SXM-80GB显卡上进行了微调训练,根据经验,训练显存建议选择32G及以上。
HuaTuo
使用模型:LLaMA-7B
所用微调数据集:医学知识图谱和GPT3.5 API构建的中文医学指令数据集
配置环境
创建新的 conda 环境:huatuo,并安装所需的包
conda create -n huatuo python==3.9
pip install -r requirements.txt
模型下载
LoRA权重可以通过百度网盘或Huggingface下载:
1、对LLaMA进行指令微调的LoRA权重文件
2、对Alpaca进行指令微调的LoRA权重文件。
我这里将文件下载的文件都放在:/data/sim_chatgpt/huatuo 下。
![]()
#1.对LLaMA进行指令微调的LoRA权重文件
#基于医学知识库
lora-llama-med/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
#基于医学文献
lora-llama-med-literature/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
#2. 对Alpaca进行指令微调的LoRA权重文件
#基于医学知识库
lora-alpaca-med-alpaca/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
#基于医学知识库和医学文献
lora-alpaca-med-alpaca-alldata/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
##
推理过程
以基于医学知识库为例,修改 ./scripts/infer.sh 中的路径如下:

运行基于医学知识库的命令即可
bash ./scripts/infer.sh

其他几个类似:
#基于医学知识库
bash ./scripts/infer.sh
#基于医学文献
#单轮
bash ./scripts/infer-literature-single.sh
#多轮
bash ./scripts/infer-literature-multi.sh
微调过程
llama模型文件路径:/data/sim_chatgpt/llama-7b-hf/models–decapoda-research–llama-7b-hf/snapshots/5f98eefcc80e437ef68d457ad7bf167c2c6a1348
修改要运行文件中模型文件路径
vi scripts/finetune.sh
exp_tag="e1"
python finetune.py \
--base_model '/data/sim_chatgpt/llama-7b-hf/models--decapoda-research--llama-7b-hf/snapshots/5f98eefcc80e437ef68d457ad7bf167c2c6a1348' \
--data_path './data/llama_data.json' \
--output_dir './lora-llama-med-'$exp_tag \
--prompt_template_name 'med_template' \
--micro_batch_size 128 \
--batch_size 128 \
--wandb_run_name $exp_tag
运行文件
sh scripts/finetune.sh
报错:显存不足

官方在一张A100-SXM-80GB显卡上进行了训练,训练总轮次10轮,耗时约2h17m。batch_size=128的情况下显存占用在40G左右。预计3090/4090显卡(24GB显存)以上显卡可以较好支持,根据显存大小来调整batch_size。
文章出处登录后可见!