使用python进行图片的文字识别
文章目录
- 使用python进行图片的文字识别
- 安装 Tesseract OCR
- 安装过程
- 配置系统的环境变量
- 安装python的第三方库
- Pytesseract库
- Pillow库
- 运行个demo
安装 Tesseract OCR
-
Tesseract OCR 是一款由 Google 团队开发的开源 OCR(Optical Character Recognition,光学字符识别)引擎,用于将图片、PDF 等格式中的文本转换为可编辑的文本格式。自 1985 年首次发布以来,它已经经历了多个版本和改进,并成为目前最受欢迎的 OCR 引擎之一。
Tesseract OCR 支持多种语言,包括英语、中文、日语、俄语等等,而且具有较高的准确率和稳定性,尤其在处理大量文字的场景下表现突出。同时,该引擎还支持多线程处理,可以有效地提高识别速度。
-
下载地址:Home · UB-Mannheim/tesseract Wiki (github.com)
-
Windows安装包: https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-5.3.1.20230401.exe
-
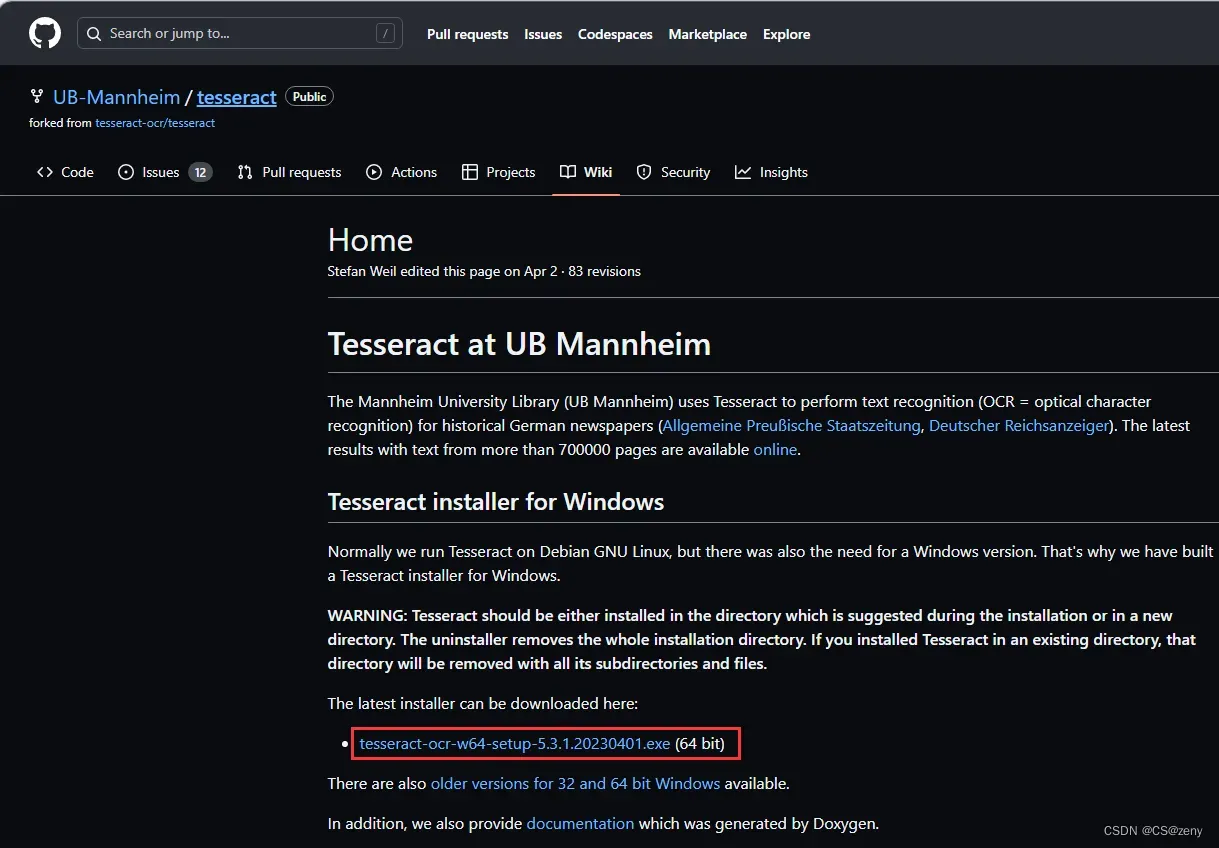
注意: 这是Windows64位系统安装包.
tesseract源码的GitHub地址:tesseract-ocr/tesseract: Tesseract Open Source OCR Engine ,有能力的可以自行编译源代码
安装过程
-
双击
tesseract-ocr-w64-setup-5.3.1.20230401.exe安装包进行安装
首先是选择语言界面,默认是英文, 没有中文,有其他国家的语言可以选。
-
点
Next
-
点
I Agree
-
默认为这台电脑进行安装
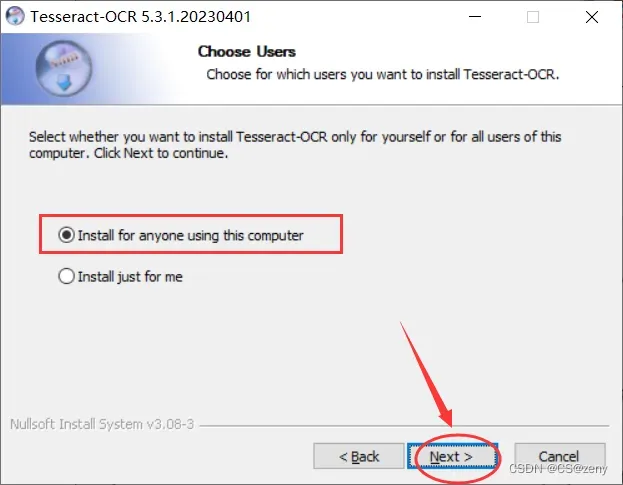
-
因为需要在 Tesseract OCR 中识别中文简体等非英语文本,所有需要安装相应的语言数据。
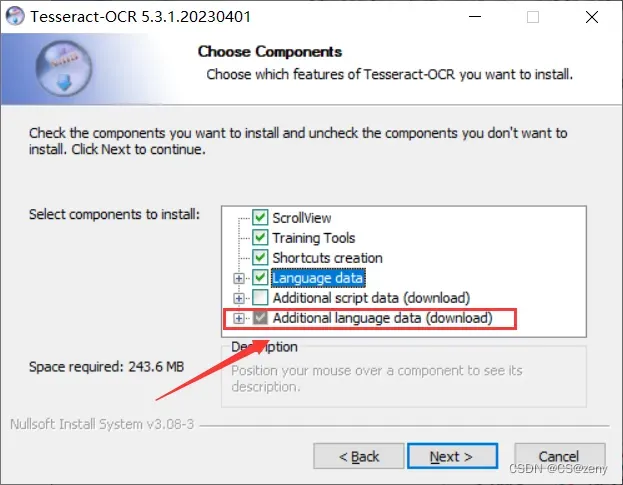
可以只安装特定语言, 比如中文简体
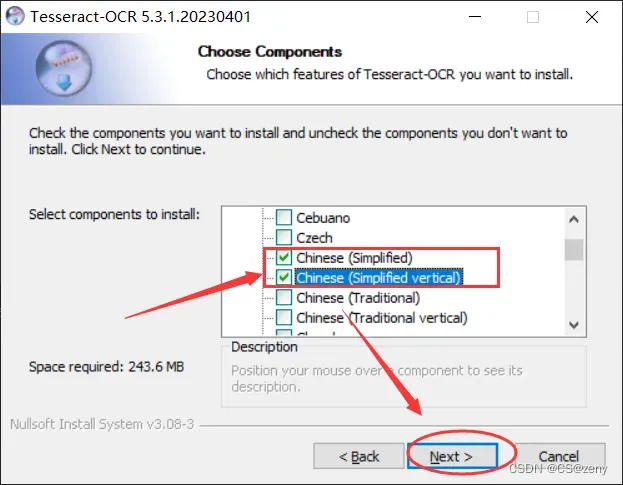
-
选择安装路径, 比如我选的是
D:\Tesseract-OCR,待会配系统环境变量可能会用到这个安装路径。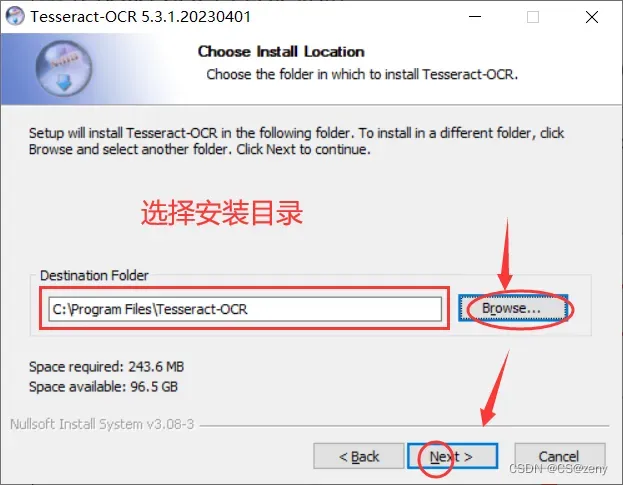
-
创建快捷图标
-
安装中
-
Next
-
Finish
-
可以在开始菜单栏中看到
Console
-
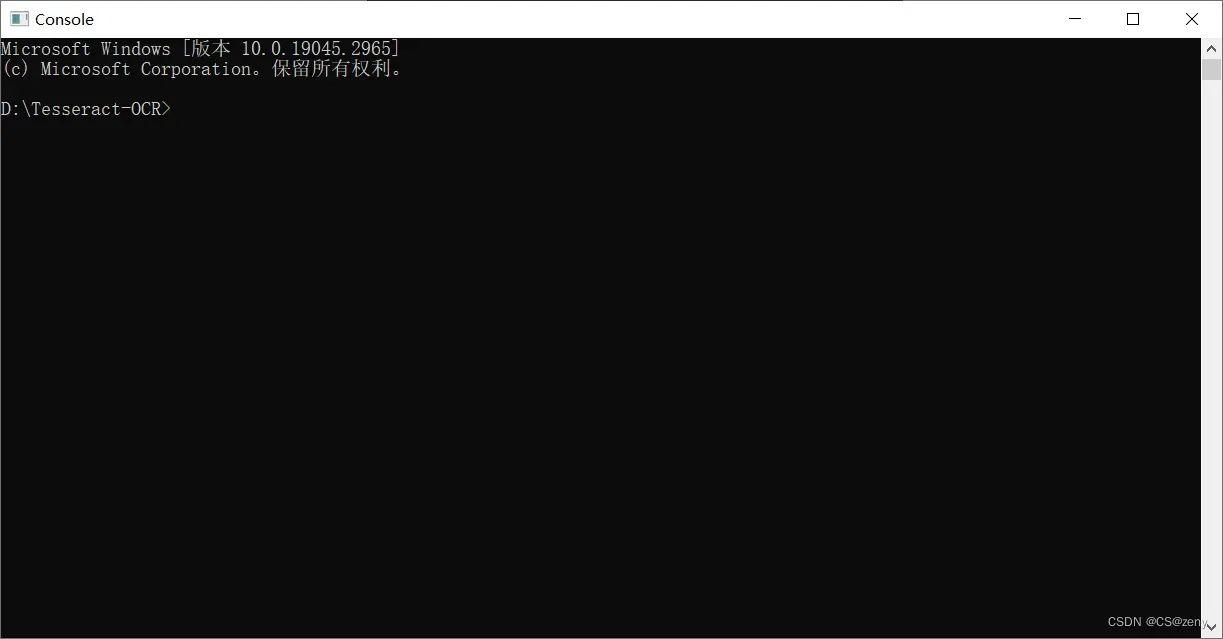
点进去就能直接进入控制台了
-
输入:
tesseract --help试试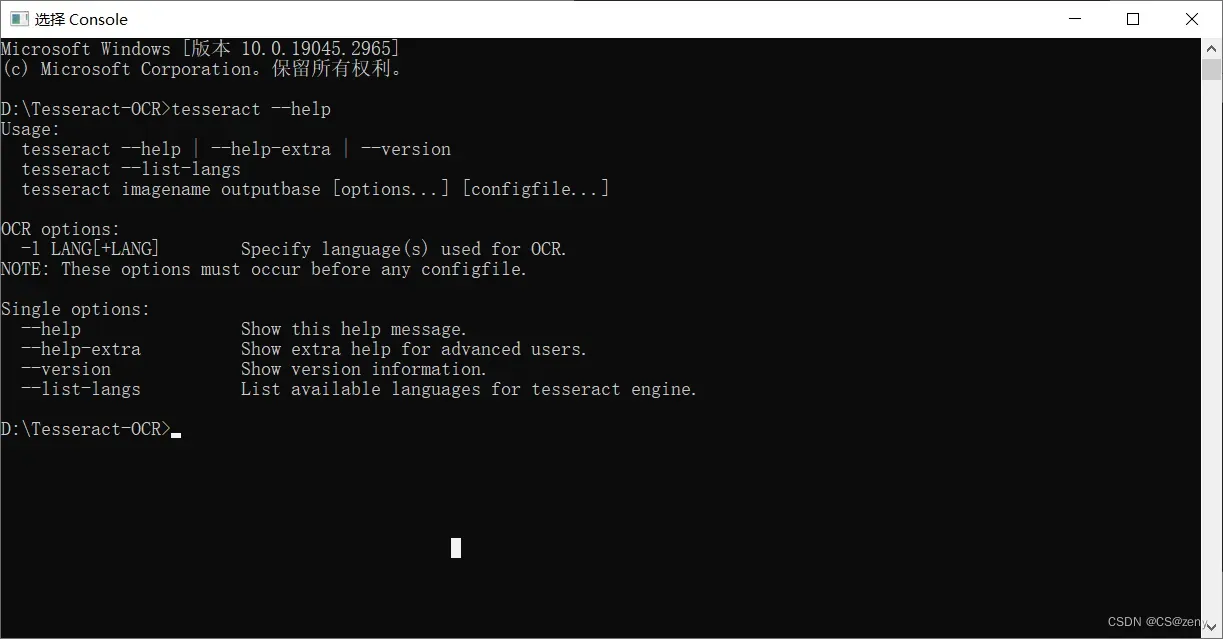
因为我们不是直接使用命令去操作这个
tesseract, 而是使用python去操作它, 因此这个命令行就不用管他, 可以关掉。接下来为了让python能直接使用它, 需要检查系统的环境变量有没有设置好。在Windows操作系统中,环境变量用于存储一些系统或用户自定义的参数和路径信息。这些参数和路径信息可以帮助操作系统找到系统中安装的软件和程序,以便正确地运行它们。
-
重新开个命令窗口
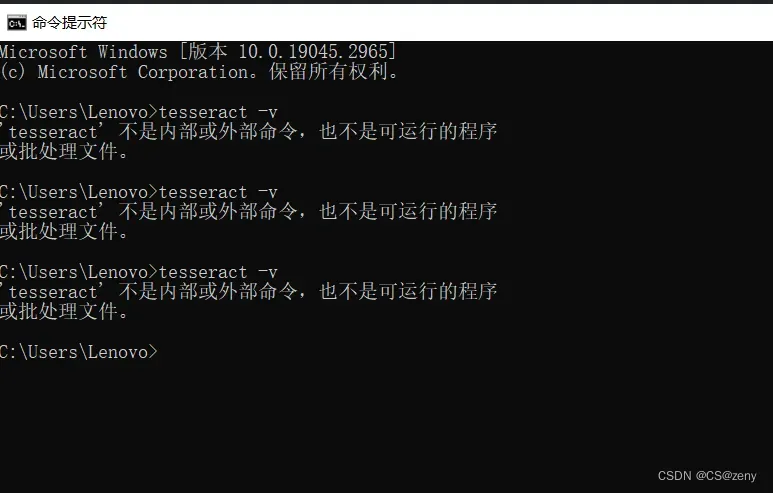
输入
tesseract -v查看版本号,你可能会出现上面的情况, 就是没有配置好系统的环境变量,那就需要配置环境变量配置系统的环境变量
-
以windows10的电脑为例, 打开电脑设置
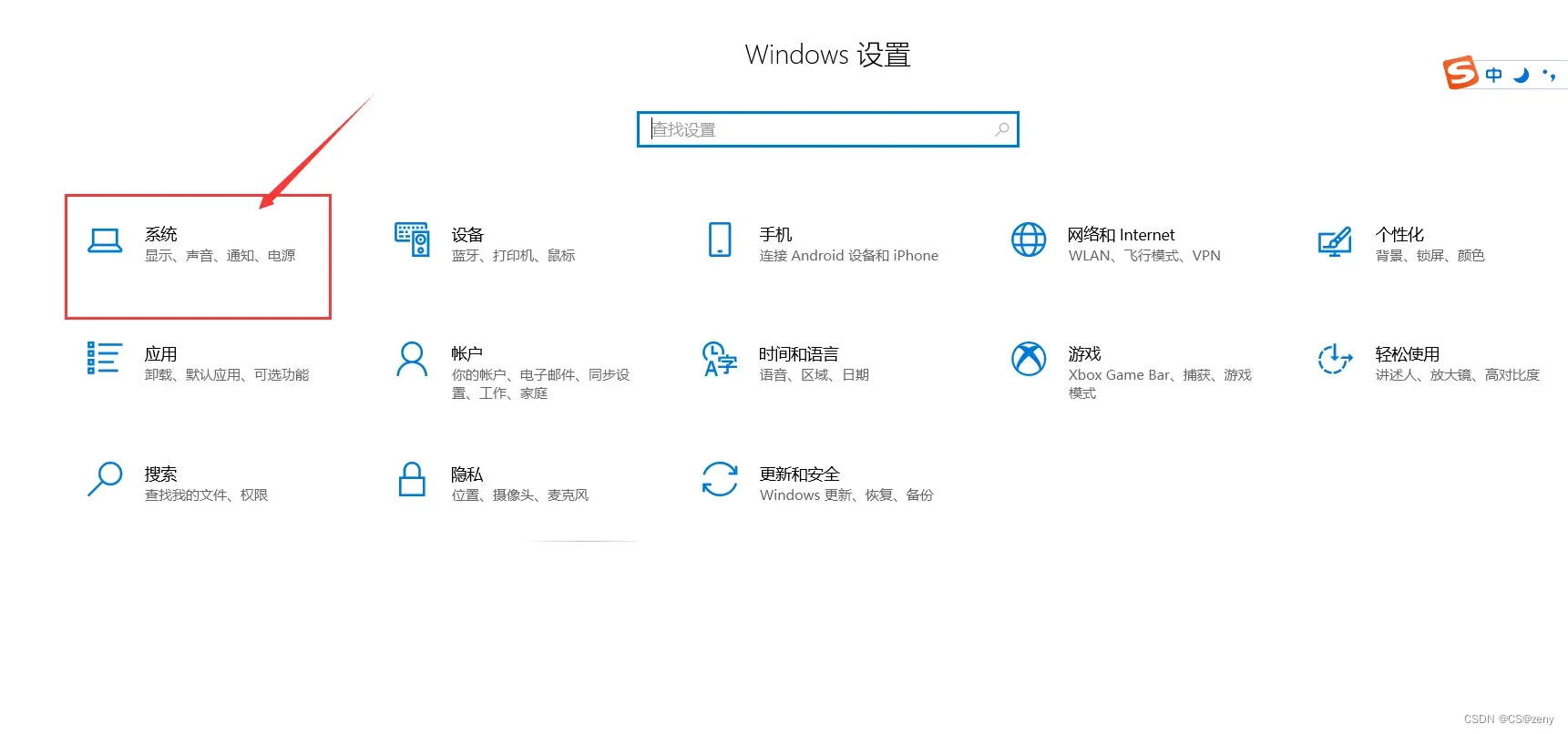
-
点击系统, 找到关于,侧边有个
高级系统设置, 点击去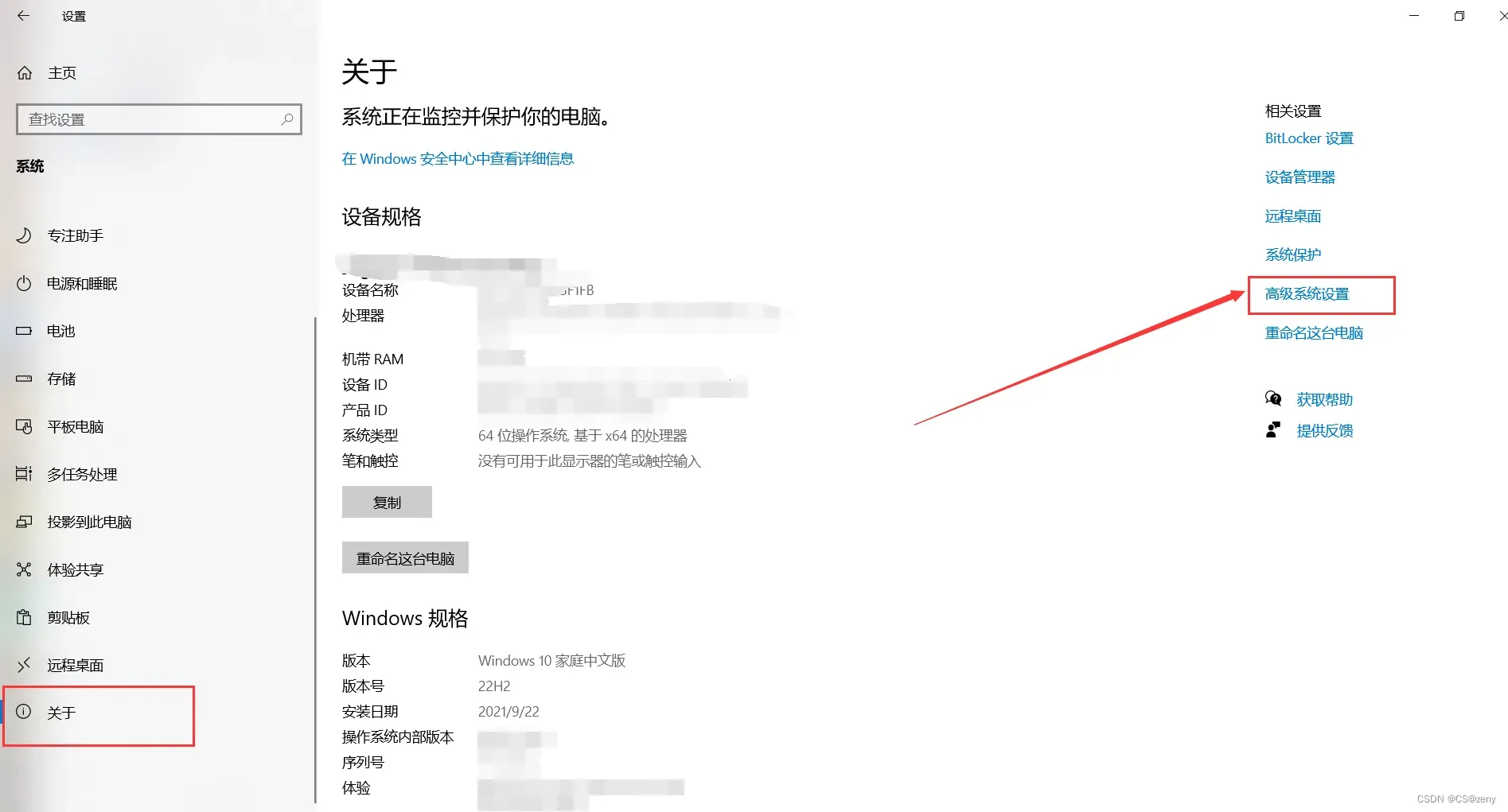
-
可以看到
环境变量, 点进去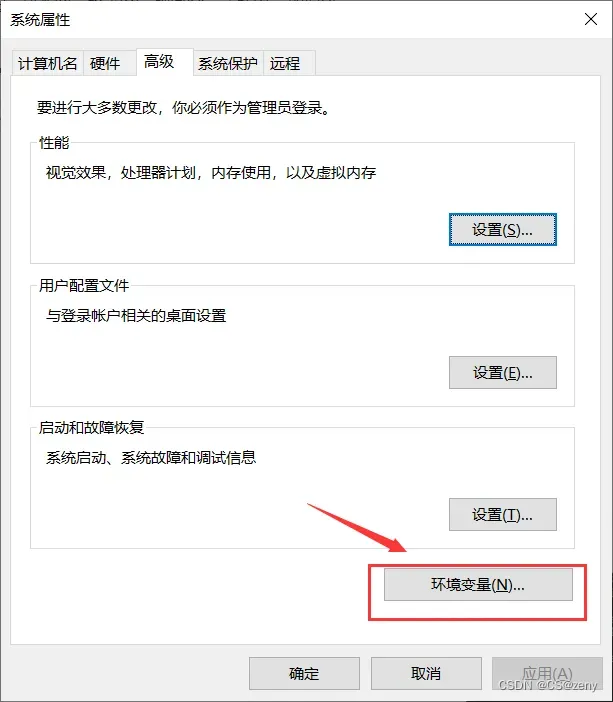
-
找到系统变量中的
Path选中, 再点击编辑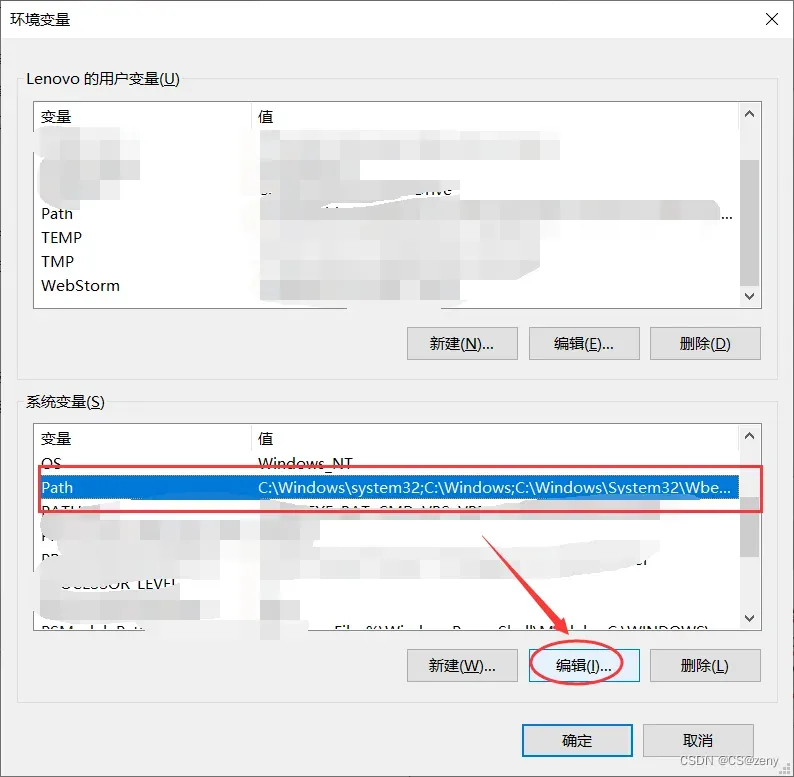
-
进入后点击
新建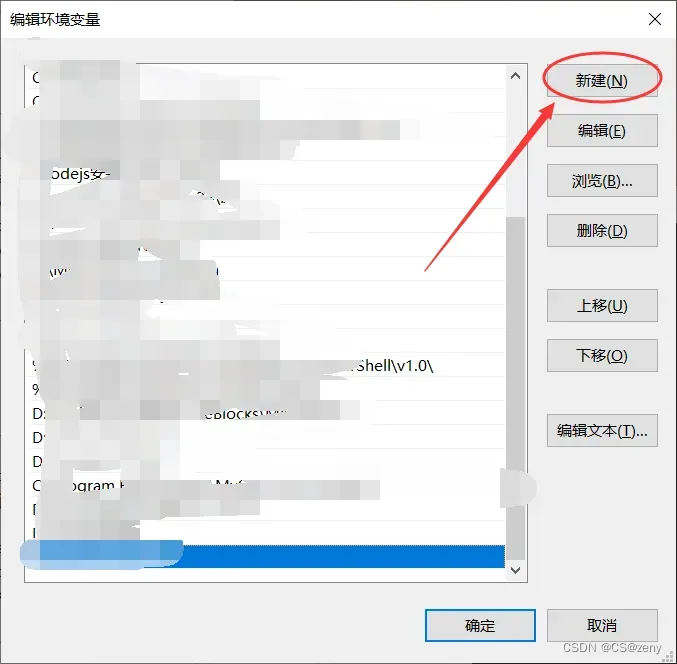
-
将安装路径复制进去,比如我安装的路径为
D:\Tesseract-OCR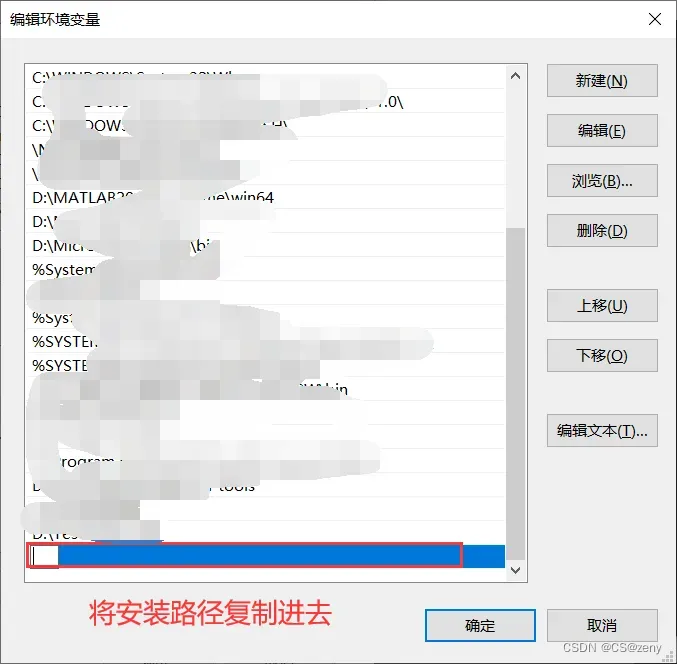
-
复制进去后点击
确认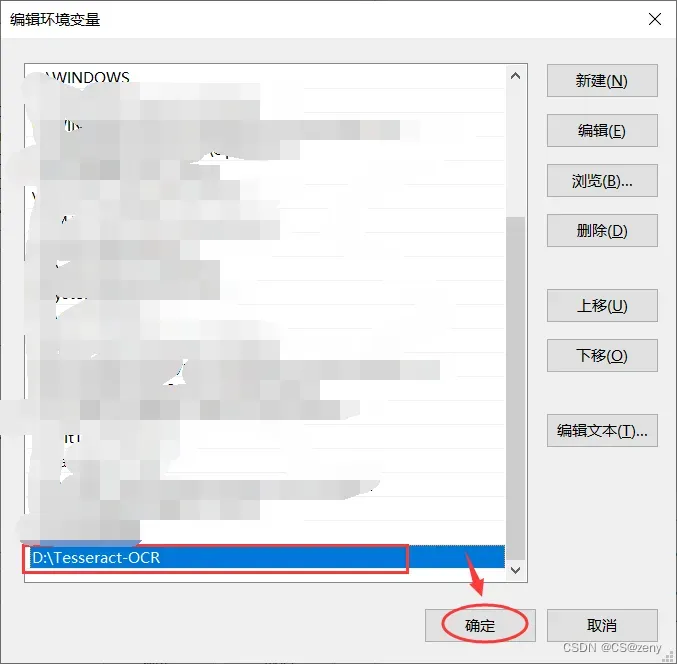
-
重新进入到命令行中
输入
tesseract -v, 若出现版本号则设置成功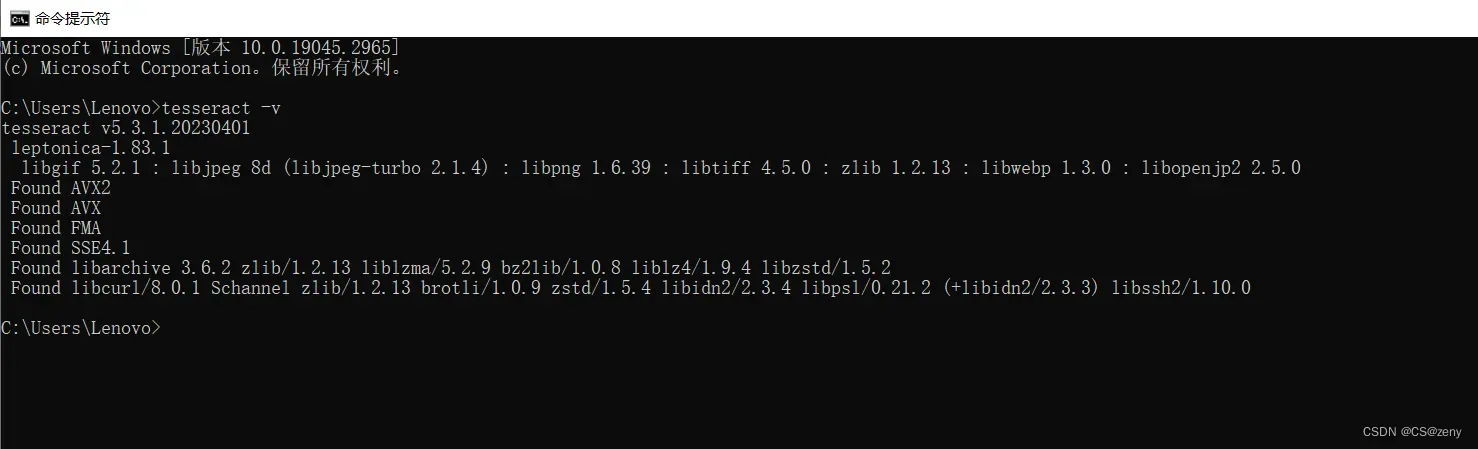
OK, tesseract算是安装完成了, 接下来使用python去操作它了!
安装python的第三方库
Pytesseract库
-
Pytesseract 是一个 Python 的 OCR(Optical Character Recognition,光学字符识别)库,可以用来将图片、PDF 等文件中的文本转换为可编辑的文本格式。它基于 Google 的 Tesseract OCR 引擎,支持多种语言,并且具有较高的准确率和稳定性。
-
安装 Pytesseract 库可以使用 pip 工具快速完成。按照以下步骤进行操作:
-
打开命令行工具(Windows: cmd,Linux/macOS: Terminal)。
-
输入以下命令来安装 Pytesseract:
pip install pytesseract -
等待安装完成即可。
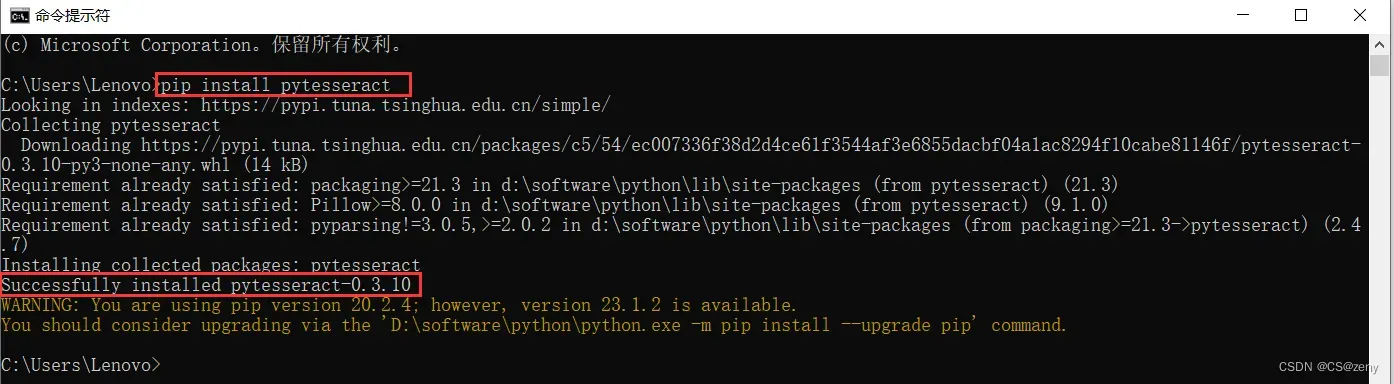
有一点需要注意的是,Pytesseract 库依赖于 Tesseract OCR 引擎,因此在安装 Pytesseract 之前请确保已安装 Tesseract OCR。如果还没有安装 Tesseract OCR,请先下载和安装它,然后再安装 Pytesseract。
-
-
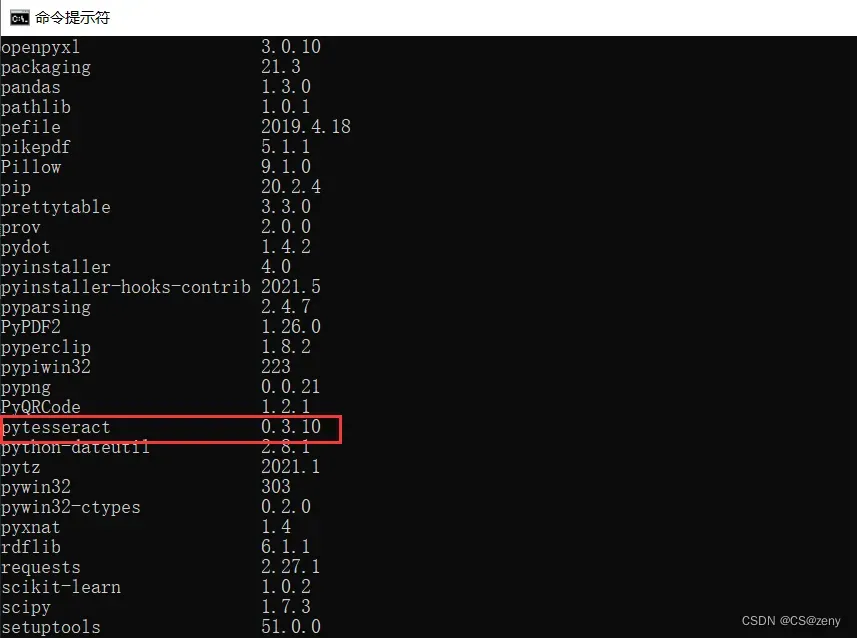
可以使用
pip list命令列出你已经安装的python库
Pillow库
- Pillow 是一个功能强大的图像处理库,可以处理多种格式的图像文件,支持图像处理、图像增强、图像转换等多种操作。
- 因为识别图片需要用到PIL(Python Imaging Library)库中的 Image 模块
使用 pip 工具来安装 Pillow 库。以下是安装 Pillow 库的命令:
pip install pillow
安装完成后,就可以在 Python 中使用 from PIL import Image 来进行图像处理和操作了。
运行个demo
比如识别这张图

import pytesseract
from PIL import Image
# 加载图片
img = Image.open('images/demo.png')
# 转换为灰度图像
img = img.convert('L')
# 识别文本, 使用pytesseract库进行OCR识别
text = pytesseract.image_to_string(img)
# 输出识别结果
print(text)
注意: 默认识别英文和数字
识别效果:

因为都是中文, 识别不出来
- 若要识别中文, 得进行配置 (前提是安装tesseract时要选择下载好中文简体数据包才能进行使用)
import pytesseract
from PIL import Image
# 加载图片
img = Image.open('images/demo.png')
# 转换为灰度图像
img = img.convert('L')
# 识别文本, 使用pytesseract库进行OCR识别, 将语言设置成中文
text = pytesseract.image_to_string(img, lang='chi_sim')
# 输出识别结果
print(text)

这个识别的正确率还可以, 这取决于图片的质量和文字的清晰规整程度
OK, 上述只是简单的小例子,更多用法可以自行探索, 还可以设置其他参数来提高文字的识别正确率!
- 使用说明文档https://github.com/madmaze/pytesseract/blob/master/README.rst
比如下面是官方的说明例子:
from PIL import Image
import pytesseract
# 如果您的PATH中没有tesseract可执行文件,请包括以下内容:
pytesseract.pytesseract.tesseract_cmd = r'<full_path_to_your_tesseract_executable>'
# 示例 tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract'
# 简单的图像转字符串
print(pytesseract.image_to_string(Image.open('test.png')))
# 为了绕过pytesseract的图像转换,只需使用相对或绝对图像路径
# 注意:在这种情况下,您应该提供tesseract支持的图像,否则tesseract将返回错误
print(pytesseract.image_to_string('test.png'))
# 可用语言列表
print(pytesseract.get_languages(config=''))
# 将法语文本图像转换为字符串
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra'))
# 使用包含多个图像文件路径列表的单个文件进行批处理
print(pytesseract.image_to_string('images.txt'))
# 在一段时间后超时/终止tesseract作业
try:
print(pytesseract.image_to_string('test.jpg', timeout=2)) # 在2秒后超时
print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # 半秒后超时
except RuntimeError as timeout_error:
# tesseract处理已终止
pass
# 获取边界框估计
print(pytesseract.image_to_boxes(Image.open('test.png')))
# 获取详细数据,包括框、置信度、行和页码
print(pytesseract.image_to_data(Image.open('test.png')))
# 获取有关方向和脚本检测的信息
print(pytesseract.image_to_osd(Image.open('test.png')))
# 获取可搜索的PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f:
f.write(pdf) # pdf类型默认为bytes
# 获取HOCR输出
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr')
# 获取ALTO XML输出
xml = pytesseract.image_to_alto_xml('test.png')
文章出处登录后可见!