智能信息检索课程设计
这是一个课程设计,具体的课设要求如下:
根据自己从网上下载的任意文档集,采用python程序设计语言,进行分词,再去掉停用词和标点符号等,生成文档的词典,接着根据词典和文档内容生成词项的倒排记录表(含位置信息),然后根据搜索关键字(多个词项),对文档集进行短语查询,符合检索条件的文档计算余弦相似度,按从大到小的顺序显示,然后进行查询扩展。
1.读取文档数据
选用的文档,是那种一小段就是一段诗歌的文档,所以使用txt.split("\n\n")就可以将每段诗歌分割开,作为一个个小的文档内容,使用字典数据类型进行存储,顺便为每一个小的文档编号。
fp=open("shakespeare.txt",'r')
txt=fp.read()
c=txt.split("\n\n")
dc={}#文本
for i in range(1,len(c)):
dc[i]=c[i-1]
2.分词,去掉停用词和标点符号
因为使用的文档是英文,所以分词操作就很容易,直接使用 字符串.split()就可以完成分词操作啦。对于去除停用词和标点符号操作可以使用字符串.replace(停用词/标点符号,'')的方法就可以完成,标点符号可以使用sring库中的string.punctuation去生成,也可以自己去定义。停用词需要我们自己去构建,比如: ‘a’,‘an’,‘of’… 这些都是可以的,具体的内容还要参考一下生成的倒排记录表,看看哪些词项是没什么意义的。当然在这个操作过程当中还涉及一些其他操作,比如将字符小写等操作,具体情况具体分析吧
import string
#punctuation="!\"#$%&’()*+,-./:;<=>?@[]^_`{|}~" #标点符号
puntion=string.punctuation
stop_word=[]#停用词
for i in dc:
start=0
line=dc[i].replace('\n',' ').lower()
for pun in puntion:
line=line.replace(pun,' ')#去除标点等符号
for stop in stop_word:
line=line.replace(stop,' ')
li=line.split()
这样对文档内容的预处理基本就结束了,可以把最终的结果重新更新存储一下哈,因为我的这里的代码是和后面的操作是连在一起的就没有这样写了。
3.生成倒排记录表
采用字典进行存储,存储结构是这样的:
{词项:{ count:数字 (表示该词项一共在多少篇文档中出现过)
文档编号(1,2,3…):[位置1,位置2] (表示该词项在该文档出现的所有位置信息)
}}
dx={}#倒排记录表
for ic in li:
st=li[start:].index(ic)
if ic in dx:
if i in dx[ic]:
dx[ic][i]+=[li[start:].index(ic)+1+start]
else:
dx[ic]["count"]+=1
dx[ic][i]=[li[start:].index(ic)+1+start]
else:
dx[ic]={"count":1,i:[li[start:].index(ic)+1+start]}
start+=1
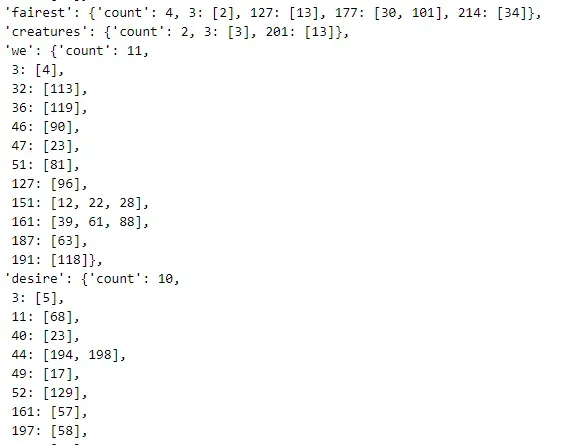 这样就生成了文档的倒排记录表啦,接下来就可以进行短语查询的操作的编写啦
这样就生成了文档的倒排记录表啦,接下来就可以进行短语查询的操作的编写啦
4.短语查询
根据短语内容和生成的倒排记录表,查询包含该短语(多关键字)的文档,具体代码如下:
def search(txt,dx):#根据位置信息查询
txts=txt.split( )
if len(txts)==1:
return list(dx[txts[0]])[1:]
result=set(list(dx[txts[0]])[1:])
i=1
while i<len(txts):
resort=[]
result=result & set(dx[txts[i]])
if result !=None:
for j in result:
for k in dx[txts[0]][j]:
if k+i in dx[txts[i]][j]:
resort.append(j)
result=set(resort)
i+=1
return list(result)
search("we desire",dx)
#[3]
还需要结合布尔查询,真正完成短语查询操作
def And(list1,list2):
print(list1)
print(list2)
li=[]
i,j=0,0
while (i<len(list1)and j<len(list2)):
if (list1[i] == list2[j]):
li.append(list1[i])
i=i+1
j+=1
elif (list1[i]<list2[j]):
i=i+1
else:
j+=1
return li
def Or(list1, list2):
print(list1)
print(list2)
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# 同时出现,只需要加入一次
if list1[i] == list2[j]:
res.append(list1[i])
i += 1
j += 1
# 指向较小数的指针后移,并加入列表
elif list1[i] < list2[j]:
res.append(list1[i])
i += 1
else:
res.append(list2[j])
j += 1
# 加入未遍历到的index
res.extend(list1[i:]) if j == len(list2) else res.extend(list2[j:])
return res
def AndNot(list1, list2):
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# index相等时,同时后移
if list1[i] == list2[j]:
i += 1
j += 1
# 指向list1的index较小时,加入结果列表
elif list1[i] < list2[j]:
res.append(list1[i])
i += 1
else:
j += 1
# list1 未遍历完,加入剩余index
if i != len(list1):
res.extend(list1[i:])
return res
def find_words(list1,list2,ap):#短语查询
#print(list1)#第一个子查询返回的文档集
#print(list2)#第二个子查询返回的文档集
#print(ap)#连接词
if ap==" AND ":
return And(list1,list2)
elif ap==' OR ':
return Or(list1,list2)
elif ap==' ANDNOT ':
return AndNot(list1,list2)
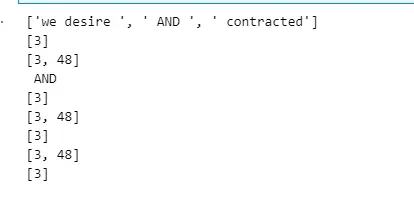
m="we desire AND contracted"#输入查询
n=m.split()
i=1
while i<len(n):
if n[i] in ["AND","OR","ANDNOT"]:
n.insert(i,"#")
n.insert(i+2,"#")
i+=1
i+=1
n=' '.join(n)
sear=n.split('#')
print(sear)
c=1
list1=search(sear[c-1],dx)
while c<len(sear):
list2=search(sear[c+1],dx)
list1=find_words(list1,list2,sear[c])
c+=2
print(list1)
这是最终运行结果:
5.计算余弦相似度
采用nnc.ltn权重计算机制计算短语与每篇文档的相关性。对于查询,采用wf=1+math.log(tf)的计算方法计算wf,idf权重因子,使用math.log(N/df)方法计算。对于文档,wf采用tf本身,没有采用idf因子,但是采用了余弦归一化方法计算出所占权值w。最后根据计算内积得出的余弦相似度,对满足查询语句的文档进行排序。
def cos_sore(doc,n):#计算余弦相似度
#doc表示符合短语查询的文档所组成的列表
#n表示查询语句中的所有词汇的列表,例如查询语句we desire OR contracted,n表示['we', 'desire','contracted']
N=len(ds)#文档集总数
score={}#每篇文档的最终得分
q=[]
for t in n:#查询
tf=1
df=len(dx[t])
idf=math.log(N/df)
wf=1+math.log(tf)
q.append(wf*df)
for d in doc:#文档
wf=[]
di=[]
for t in n:
if t in ds[d]:
tf=ds[d][t]
wf.append(1+math.log(tf))
else:
tf=0
wf.append(tf)
g_wf=np.array(wf)
for i in wf:
di.append(i/np.linalg.norm(wf))
score[d]=round(sum(np.multiply(wf,di)),3)#内积
return score
score=cos_sore(lis_1,sas)#计算余弦相似度,即文档的得分
score=list(score.items())
score.sort(key=lambda x:x[1],reverse=True)#根据相似度进行排序
6.扩展查询
利用nltk库中的corpus.wordnet模块对t进行同义词查找,将查找出的同义词进行查询,这样就实现了扩展查询。
def expansion(n):#扩展查询
doclist=[]
n_sys={}
sys_doc={}
for i in n:#n表示查询语句中的所有词汇的列表,例如查询语句we desire OR contracted,n表示['we', 'desire','contracted']
doclistt=[]
print('原词:',i)
synonyms = []#同义词
for syn in wn.synsets(i):
for lm in syn.lemmas():
synonyms.append(lm.name())
synonyms=list(set(synonyms))
print("同义词:",synonyms)
#查找同义词所在文档
n_sys[i]=synonyms
for w in synonyms:
if w in dx and w!=i:
doclistt+=search(w,dx)
sys_doc[i]=list(set(doclistt))
doclist+=doclistt
doclist=list(set(doclist))#对列表进行去重,并返回列表形式
return n_sys,sys_doc,doclist#返回含有同义词的所有文档
这样基本就完成啦,之后可以写个页面展示一下,可以参考链接:
https://download.csdn.net/download/clown0004/87625976
文章出处登录后可见!