1. 概述
基于ViT(Vision Transformer)自监督在最近几年取得了很大进步,目前在无监督分类任务下已经超过了之前的一些经典模型,同时在检测分割等基础任务领域也展现出了强大的泛化能力。这篇文章将主要基于DINO系列自监督算法介绍它们的算法原理,方便 大家快速了解相关算法。
2. DINO-v1
参考代码:dino
这个方法源自于一个很重要的发现,自监督的ViT在图像语义分割的显式信息表达上具有独特性,也就是说相比有监督的ViT网络或者是传统的CNN网络其具有更强的语义表达能力和分辨能力。基于此使用k-NN算法作为分类器便能在一个较小的ViT网络上实现78.3% ImageNet top-1的准确率。在该方法中构建自蒸馏的方式训练和更新教师和学生网络,同样也适用了参数类似滑动平均更新和输入图像多重裁剪训练策略。对于训练得到的网络对其中的attention map进行可视化,确实也呈现出了上述提到的物体语义区域的感知能力,见下图可视化效果:

整体上文章提出的方法pipeline见下图所示:
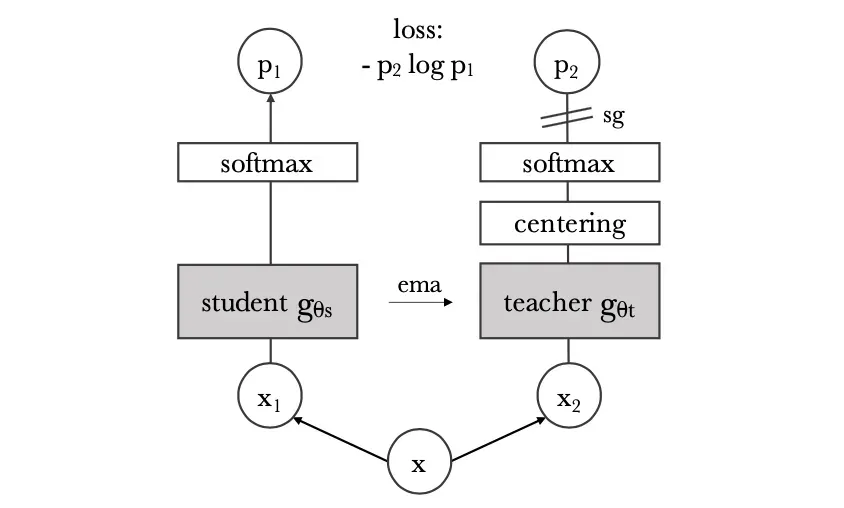
在上图中包含了两个相同结构的网络和
,喂给它们同一张图不同的信息(local和global,也就是图像分辨率一个大一个小),之后对输出用交叉熵损失函数约束。但是这里需要注意的是只有student网络会存在梯度反向传播,teacher是通过类似滑动平均更新的形式更新参数。整体流程比较简洁,其自监督运算流程如下:

输入处理:
在自监督方法设计过程中,teacher网络是没有任何先验初始化的,而teacher需要正确引导student网络学习。那么要使得自监督能够进行下去,则teacher应该能获取到更多的信息,而student相应的获取较少信息,这样才有信息的梯度差异,实际中是通过给teacher和student网络不同的图像分辨率图像实现的。对应的在输入图像的过程中也会经过一些数据增广操作,如视图扭曲、裁剪等操作。
student网络蒸馏和更新:
在ViT骨干网络基础上,会连接几个fc层(中间会使用l2-norm)得到这张图的高维度表达(表达的维度为):
和
。为了避免生成的分布不够平滑这里对student和teacher的输出引入不同温度因子进行平滑:
参考上面的式子,其对teacher网络也一样适用,只不过它们的温度因子策略有所不同。而
且有一个warm-up的过程。那么对于这两个分布最后是采取在不同输入下交叉熵最小化来更新student网络的参数的:
teacher网络更新:
这里teacher网络的更新机制采用的是类似滑动平均更新的形式:
也就是使用student网络的参数去更新teacher,其中参数在训练过程中会依据cosine函数进行变化。
teacher输出中心分布的更新:
同理teacher网络参数的更新机制,这里也是采用类似滑动平均的方式在Batch维度进行统计得到的:
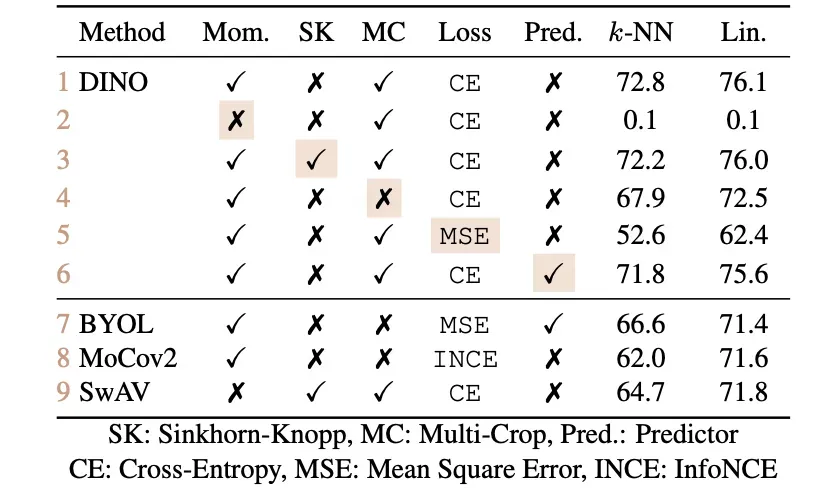
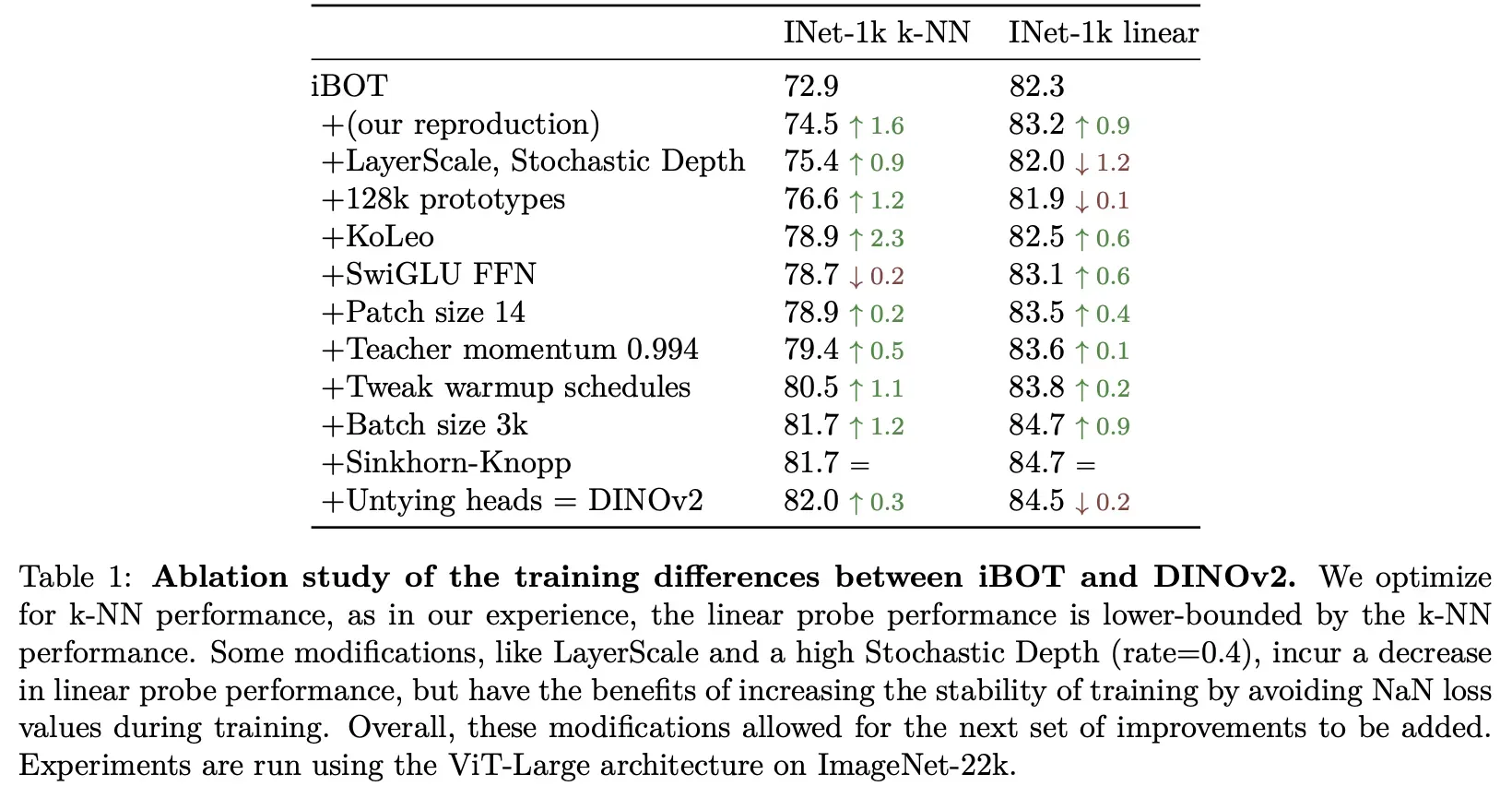
前文中一些模块对性能的影响:
3. DINO-v2
参考代码:dinov2
在V1版本中使用ViT作为backbone,而ViT在输入的时候会将图像切块,之后送入到网络编码。在切块基础上之前的一些文章,如MAE,会将其中的一些块给丢弃掉(mask掉),之后通过编解码器得到完整图像,表明了mask机制能带来较好自监督效果。则在v2版本中也借鉴了mask的操作,不过它使用的是teacher和student模型的形式,其方法借鉴自IBOT
【论文阅读】IBOT : IMAGE BERT PRE-TRAINING WITH ONLINE TOKENIZER
同时,数据这块文章指出精心设计过的数据能带来更好的性能,所以不是说自监督直接喂给图片就能拿到最好效果。
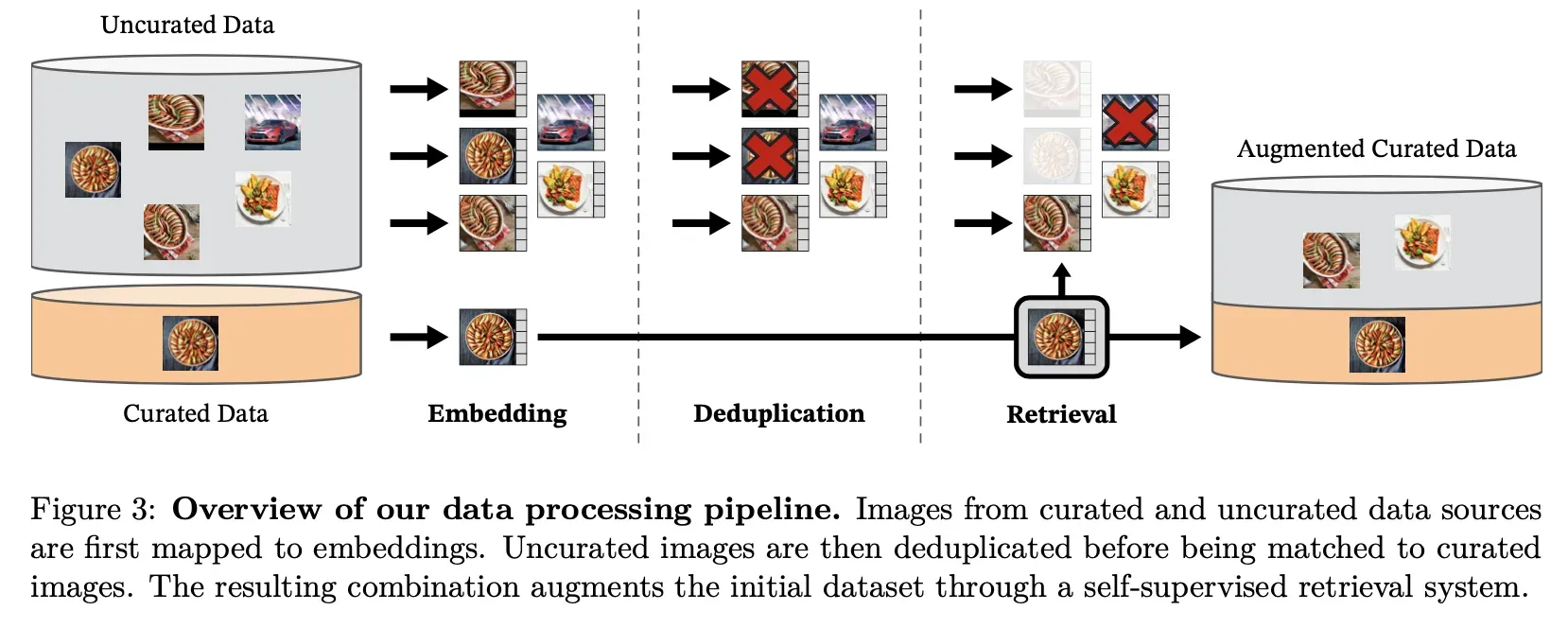
数据处理:
这里从ImageNet-22k、ImageNet-1k的train部分、Google Landmarks和其它一些数据中使用数据清洗手段筛选更具表达能力的数据,新得到的数据集被命名为LVD-142M。具体的,数据清洗过程见下图:
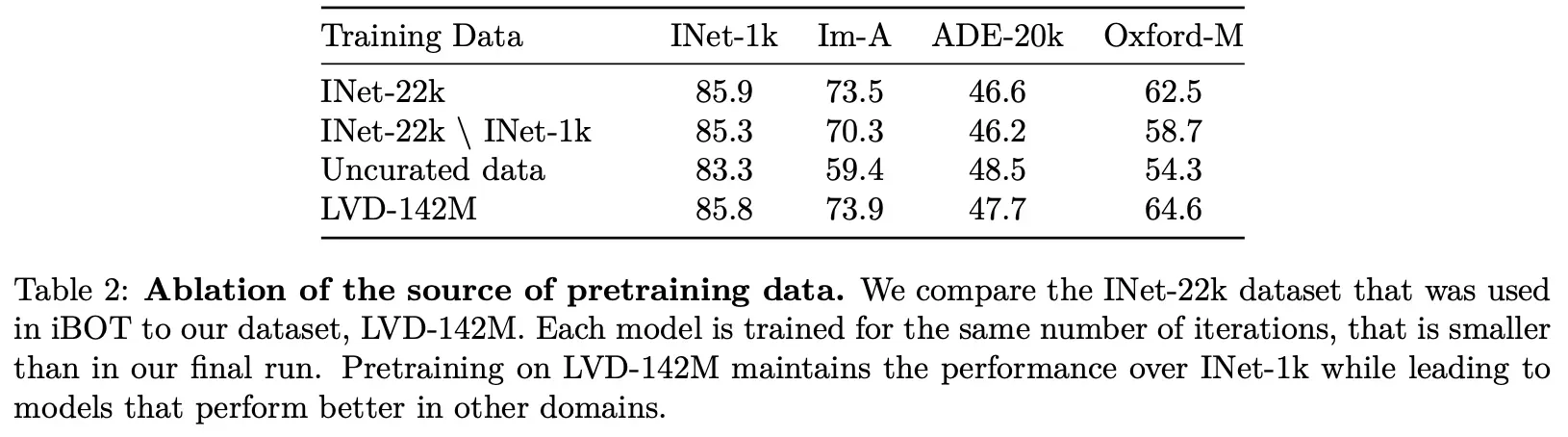
对比是否对数据进行清洗,其差异见下表:
V2相比V1显著区别:
- V2中借鉴iBot方法引入mask机制,从而引导teacher和student网络在mask掉的区域上表达一致
- teacher网络将之前的softmax-centering方法替换为Sinkhorn-Knopp (SK) batch normalization,用以避免collapse。而student网络还是使用softmax归一化
- 为了使得一个batch中分布更加均匀使用了KoLeo regularizer
- 为了适应下游任务中增大分辨率的需求,在训练快结束阶段会将分辨率调整到
一些改动对性的影响:
文章出处登录后可见!