
©Paperweekly 原创 · 作者 | Chunyuan Li
使用 GPT-4 进行视觉指令学习!Visual Instruction Tuning with GPT-4!

▲ Generated by GLIGEN (https://gligen.github.io/): A cute lava llama and glasses
我们分享了 LLaVA (Language-and-Vision Assistant),一款展示了某些近似多模态 GPT-4 水平能力的语言和视觉助手:
视觉聊天 (Visual Chat):相对得分达到了 GPT-4 的 85%
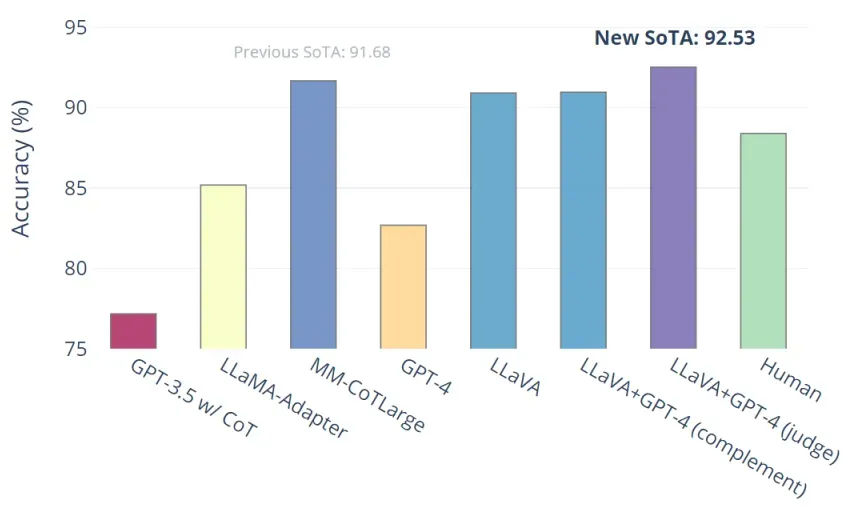
多模态推理任务的科学问答 (Science QA):达到了新的 SoTA 92.53%,超过了之前的最先进的方法:多模态思维链技术 (multimodal chain-of-thoughts)
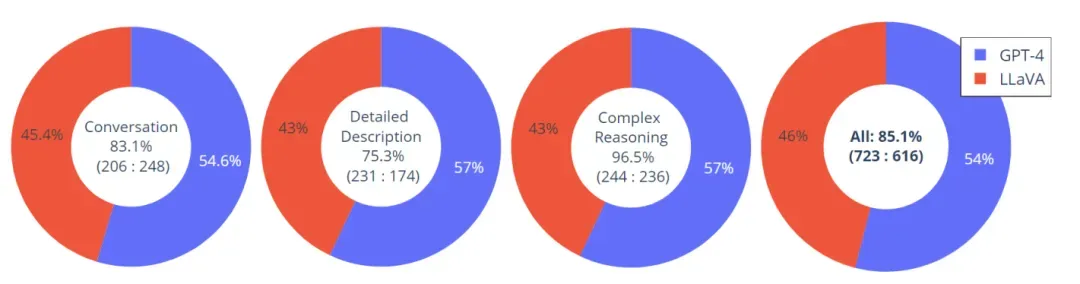
▲ 构建一个包含30张未见图像的评估数据集,其中每个图像都关联着三种类型的指令:对话、详细描述和复杂推理。这样总共有90个新的语言-图像指令,我们进行了LLaVA和GPT-4的评测,并使用GPT-4将它们的结果从1到10进行评分。每种类型的总分和相对分数都被报告。LLaVA相对于GPT-4达到了85.1%的相对分数

项目主页 Project Page:
https://llava-vl.github.io/
论文 Paper:
https://arxiv.org/abs/2304.08485
代码 GitHub:
https://github.com/haotian-liu/LLaVA
演示 Demo:
https://llava.hliu.cc/
数据 Data (158K unique language-image instruction-following samples):
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
模型 Model (LLaVA-13B):
https://huggingface.co/liuhaotian/LLaVA-13b-delta-v0

学习总结
我总结目前为止的项目主要体验:
1. 多模态指令跟踪数据(Multimodal Instruction-following Data)
毫无疑问,数据质量是这个项目的关键。我们大部分时间都在迭代新的指令数据。在这个数据为中心(Data-Centric)的项目中,需要考虑以下因素:图像的符号化表示(包括 Caption & Boxes)、ChatGPT vs GPT-4、提示工程(Prompt Engineering)等。
看到学术圈一直以来没有这类数据,我们开源了我们最新一个版本的数据,希望能启发更多人沿着这个道路去探索。
2. 视觉对话(Visual Chat)
LLaVA 在涉及面向用户应用的聊天过程中表现出非常强的泛化能力,尽管只是在不到 1M CC/COCO 数据的训练下进行的。
(a) 强大的多模态推理能力:GPT-4技术报告中的两个基于图像的推理示例,一度以为难以企及,利用LLaVA现在可以轻松复现。


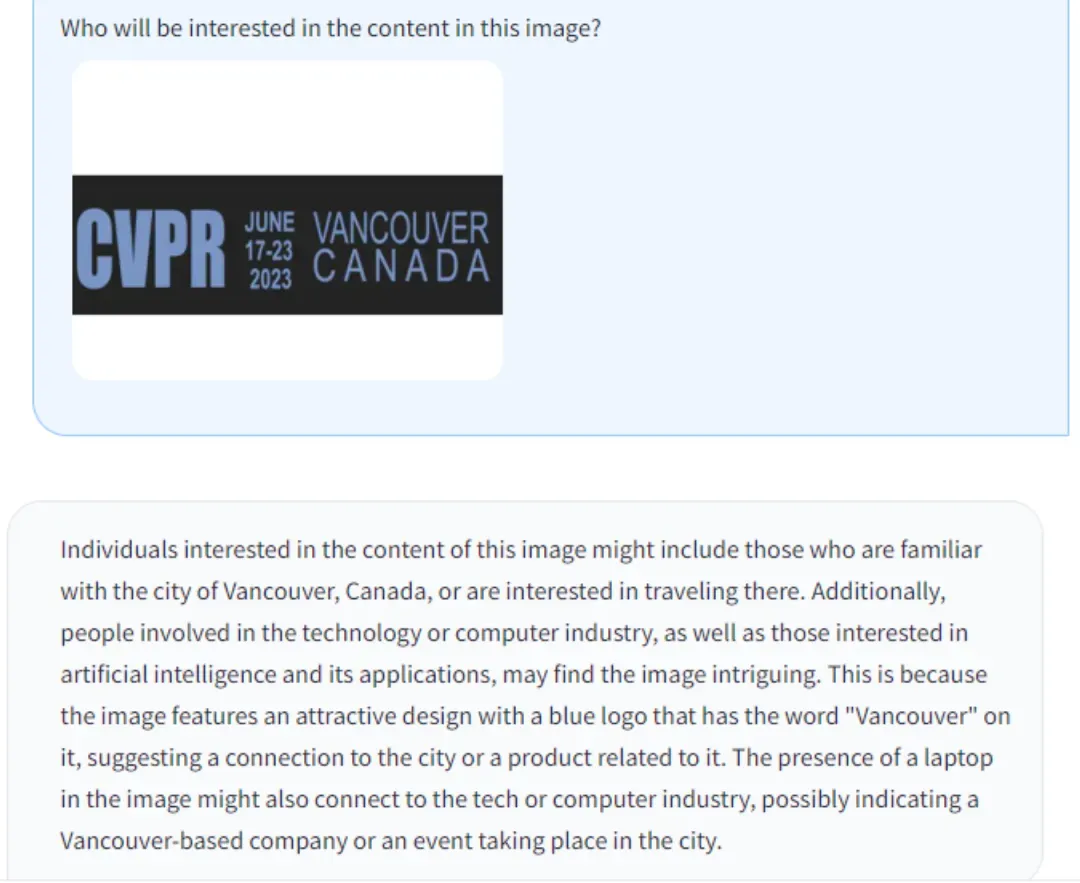
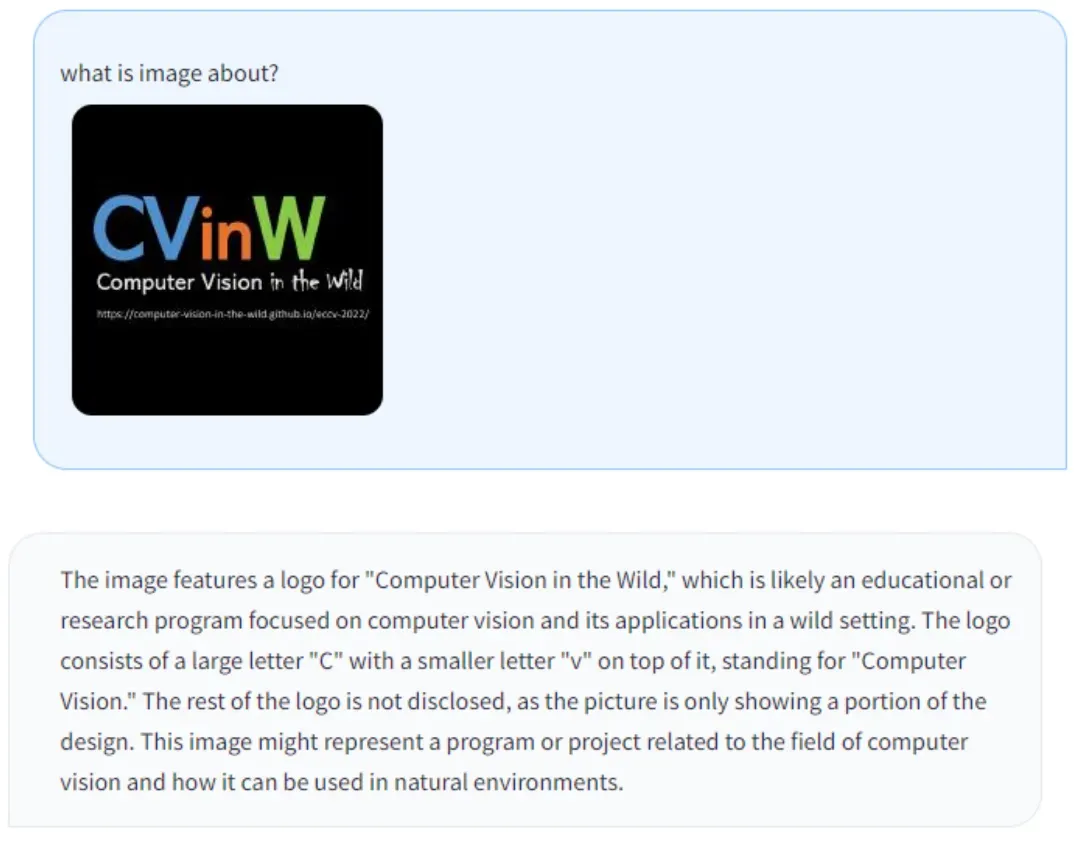
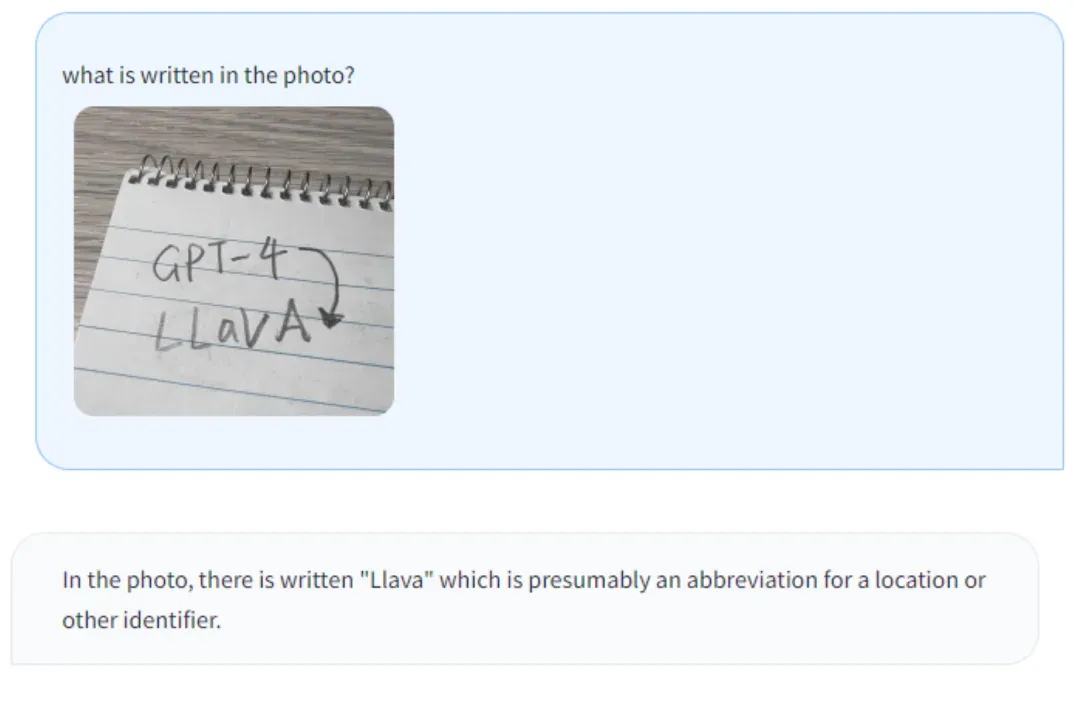
(b) 强大的 OCR 文字识别能力:请看我刚刚制作的一些示例。它能识别 CVPR、我们的举办的 Computer Vision in the Wild (CVinW) Workshop 的标志的图片,和 LLaVA 本身相关的照片。
CVinW Workshop:
https://github.com/Computer-Vision-in-the-Wild
3. 科学问答(Science QA)
单独使用 LLaVA 实现了 90.92% 的准确率。我们使用仅文本的 GPT-4 作为评判者,根据其自身先前的答案和 LLaVA 的答案预测最终答案。这种“GPT-4 作为评判者”的方案产生了新的 SOTA 92.53%。令人惊讶的是,GPT-4 可以作为一种有效的模型集成方法!这些结果希望启发大家以后刷榜的时候,可以利用 GPT-4 这个神奇来集成不同方法。
总的来说,LLaVA 展示了一种非常有前途的方法,启发大家复现且超越 GPT-4 的多模态能力。
更多阅读



🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·

文章出处登录后可见!