Abstract:
本文推出了 EVA,这是一个以视觉为中心的基础模型,旨在仅使用可公开访问的数据来探索大规模视觉表示的局限性。EVA 是一种经过预训练的普通 ViT,用于重建 以可见图像块为条件的 屏蔽掉的图像-文本对齐(image-text aligned)的视觉特征。通过这个前置任务,我们可以有效地将 EVA 扩展到 10 亿个参数,并在图像识别、视频动作识别、目标检测、实例分割和语义分割等广泛的代表性视觉下游任务上创造新记录,而无需大量监督训练。
此外,我们观察到 缩放 EVA 的量变导致迁移学习性能的质变,这在其他模型中是不存在的。例如,EVA 在具有挑战性的大词汇量实例分割任务中取得了巨大飞跃:本文的模型在具有超过一千个类别的 LVISv1.0 数据集和只有八十个类别的 COCO 数据集上实现了几乎相同的最先进性能。
除了纯粹的视觉编码器,EVA 还可以作为 以视觉为中心的多模态的支点 来连接图像和文本。我们发现从 EVA 初始化巨型 CLIP 的视觉塔可以 以更少的样本和更少的计算 极大地稳定训练 并优于从头开始的训练,为 扩大 和 加速 多模态基础模型的昂贵训练 提供了新的方向。为了方便未来的研究,本文发布了所有代码和十亿规模的模型。
(Code & Models: https://github.com/baaivision/EVA)
1. Introduction
扩大预训练语言模型 (PLM) [9,63,76] 在过去几年彻底改变了自然语言处理 (NLP)。这一成功的关键在于掩码信号预测 [31、74] 的简单且可扩展的自监督学习任务,利用该任务,Transformer 模型 [101] 可以使用几乎无限的未标记数据扩展到数十亿个参数,并且只需很少的调整就可以很好地泛化到各种下游任务。随着计算、数据和模型规模的进一步扩展,PLM 不仅带来了持续的性能改进 [51、75、76],而且令人惊讶地出现了上下文学习(in-context learning)能力 [9、25、107、108]。
受 NLP 模型扩展成功的推动,我们还可以将这种成功从语言转化为视觉,即 扩大以视觉为中心的基础模型,该模型有利于视觉和多模态下游任务。最近,掩码图像建模 (MIM) [5, 40, 116] 作为一种可行的视觉模型预训练和缩放方法得到了蓬勃发展。然而,最具竞争力的数十亿级视觉预训练模型 [33、64、71、123] 仍然 严重依赖监督或弱监督训练 以及数亿(通常是公开不可访问的)标记数据。 MIM 在某种程度上仅被用作 严格地监督预训练之前的 初始化阶段 [64],或者纯 MIM 预训练模型无法在十亿规模的模型大小下实现良好的性能 [117]。我们认为这种差距源于自然图像是原始的且信息稀疏的事实。同时,理想的视觉前置任务 不仅需要 低级几何结构信息的抽象,还需要高级语义的抽象,而像素级恢复任务 很难捕获这些信息[115]。
在这项工作中,本文为大规模视觉表示学习寻找合适的 MIM 前置任务,并探索其在十亿参数规模和数千万未标记数据下的极限。最近,有一些试验 利用 图像-图像 或 图像-文本 对比学习 [13、22、73] 的语义信息进行 MIM 预训练 [44、109、130],它们在视觉下游任务中表现相当好。然而,关于 (i) 标记化语义特征 可以为视觉中的掩码建模提供更好的监督信号 [5、70、104] 以及 (ii) 良好的性能也可以通过 没有掩码预测任务的 简单后蒸馏过程 [110 ]来实现 仍然存在争论 。通过试点实证研究,本文发现简单地使用图像-文本对齐(即 CLIP [73])视觉特征作为 MIM 中的预测目标可以很好地扩展 并在广泛的下游基准测试中 取得令人满意的性能。该预训练任务受益于图像文本对比学习的高级语义抽象 以及 掩码图像建模中几何和结构的良好捕获,这通常涵盖了大多数视觉感知任务所需的信息。
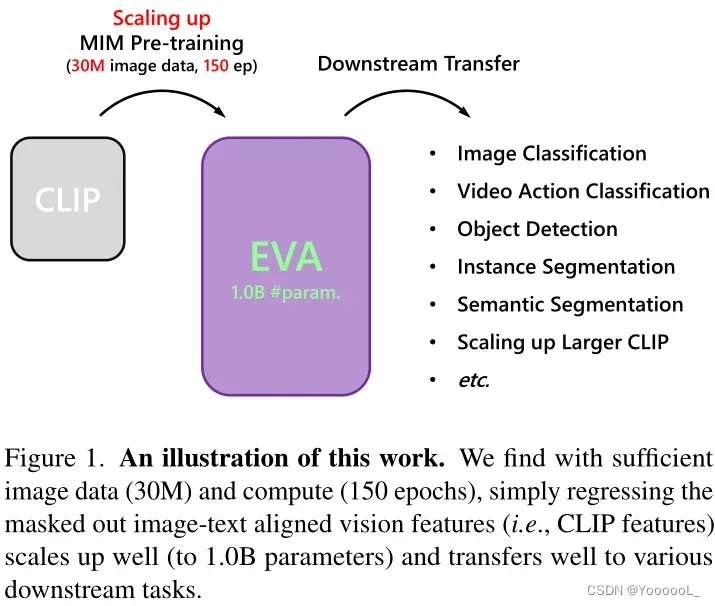
通过这个 MIM 前置任务,我们可以有效地将一个普通的 ViT 编码器 [33],称为 EVA,扩展到十亿个具有强大视觉表示的参数,可以很好地传输到广泛的下游任务(图 1)。使用 2960 万张可公开访问的未标记图像进行预训练,EVA 在几个具有代表性的视觉基准测试中创造了新记录,例如 ImageNet1K [30] 上的图像分类(89.7% top-1 准确率)、LVISv1.0 [39] (62.2 APbox & 55.0 APmask on val) 和 COCO [61] (64.5 APbox & 55.0 APmask on val, 64.7 APbox & 55.5 APmask on test-dev)上的 目标检测 和实例分割,COCO-stuff [11](53.4 mIoUss)和 ADE20K [129] (62.3 mIoUms)上的语义分割,以及 Kinetics-400 [52](89.7% top-1 准确率)、Kinetics-600 [14](89.8% top-1 准确率)、Kinetics700 [15](82.9% top-1 准确率)上的视频动作识别。值得注意的是,不同于其他 需要数千万甚至数十亿标记图像的 最先进的十亿级视觉基础模型,例如使用 ImageNet-21K-ext-70M [64] 的 SwinV2-G 和 ViT- g/G 使用 JFT-3B [123],EVA 不需要昂贵的监督训练阶段,仅利用来自开源数据集的图像来实现学术可重复性。
此外,我们观察到 扩大EVA 的量变导致迁移学习性能的质变,这在其他较小规模的模型中没有观察到,例如,EVA 在具有挑战性的大词汇量 目标级识别任务中 取得了重大突破:我们的模型在 LVISv1.0 [39] (55.0 APmask on val),一个具有超过 1,200 个类别的实例分割基准,上实现了与 COCO [61] (55.0 APmask on val),它几乎与 LVISv1.0 共享相同的图像集但仅注释了 80 个类别,几乎相同的性能(55.0 APmask on val)。这种涌现能力很好地符合模型扩展的期望[108],即模型的更大能力 不仅会 导致 标准基准的可预测性能改进,而且还会产生不可预测的现象和解决更具挑战性任务的能力。
除了纯粹的视觉编码器,EVA 还可以充当以视觉为中心的多模态支点,在视觉和语言之间架起一座桥梁。本文表明,在 11 亿个参数的 CLIP 模型中通过 预训练的 EVA 初始化图像编码器 可以 在广泛的零样本图像/视频分类基准测试中 胜过从头开始的训练,而且样本和计算量要少得多。此外,EVA 可以极大地稳定巨型 CLIP 的训练和优化过程。由于大型 CLIP 模型通常会遇到训练不稳定和效率低下的问题 [2, 48],本文希望我们的解决方案为 扩大和加速多模态基础模型的昂贵训练开辟新的方向。
通过使用 MIM 预训练 扩展以视觉为中心的基础模型 以在广泛的下游任务上实现强大的性能,本文希望 EVA 能够通过 掩码信号建模 弥合视觉和语言之间的差距,并为不同模式的大融合做出贡献。
2. Fly EVA to the Moon
本文首先在 §2.1 中进行了一系列试点实验 以 选择理想的视觉前置任务,然后通过在 §2.2 中选择的预训练目标 扩大了 EVA 预训练。最后,在 §2.3 中评估了各种下游任务的预训练表示。详细的实验设置和配置在附录 A 中。
2.1. The Feature Instrumentality Project 特征工具项目
在本节中,我们寻求具有令人信服的迁移性能的 MIM 视觉前置任务。基于先前关于视觉预训练的文献,本文研究了两个有前途的候选者:(i)恢复被屏蔽的标记化语义视觉特征 [5、70、104],以及(ii)从强大的预训练表示中特征蒸馏,如 [110]。它们都利用预训练的图像-文本对齐视觉特征(即 CLIP [73] 视觉特征)。通过表 2 中所示的一系列试点实验,我们发现:(i)(附加的)CLIP 特征标记化(tokenization)过程 对于 实现良好的下游性能 是不必要的(ii)特征蒸馏无法提供持续的性能增益,因为预训练变得更长。相反,我们发现 简单地重建 以可见图像块为条件的 掩码的 CLIP 视觉特征是高性能的,它被选择用于扩展 EVA。
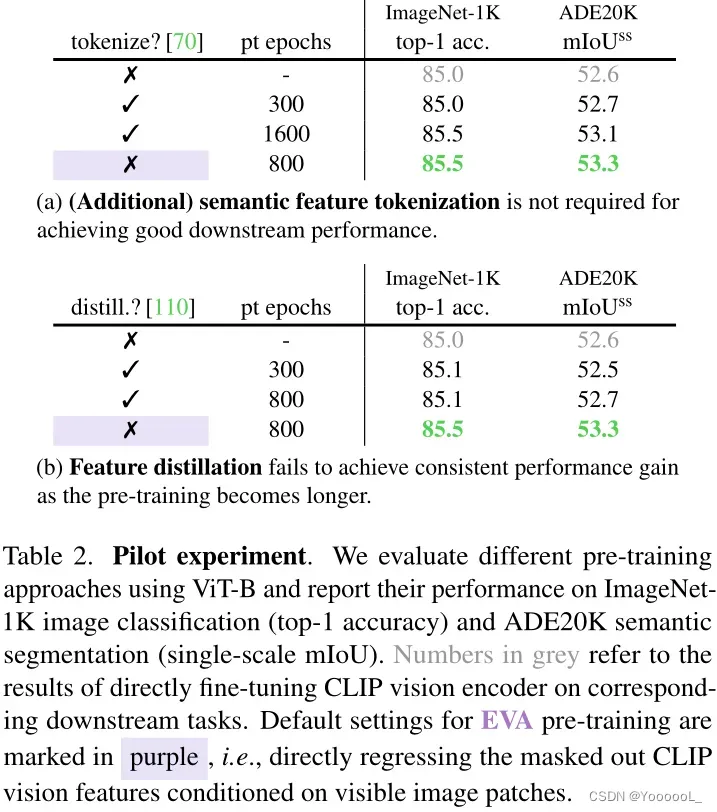
澄清一下,这个 MIM 前置任务最初并不是本文提出的。 MVP [109] 研究了 MIM 预训练的掩码图像-文本对齐视觉特征的回归,最近 MILAN [44] 重新讨论了这一问题。在这项工作中,本文表明这个前置任务可以扩展到十亿级参数和数千万个未标记图像,用于以视觉为中心的表示学习,无需 (i) 语义特征量化/标记化 [5、70],和 (ii) 明确使用图像-文本配对的预训练数据和大型语料库,如 BEiT-3 [104]。
2.2. Pre-training
架构:
EVA 的架构配置如表 3a 所示。 EVA 是具有 1.0B 参数的普通ViT [33]。她的形状遵循 ViT giant [123] 和 BEiT-3 [104] 的视觉编码器。本文在预训练期间不使用相对位置嵌入 [89] 和 layer-scale [99]。
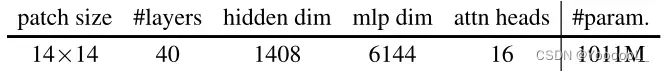
预训练目标:
EVA 经过预训练,可以重建以可见图像块为条件的屏蔽掉的图像-文本对齐视觉特征。我们用 [MASK] 标记破坏了输入patches,并且我们遵循 [5, 70, 104] 使用屏蔽率为 40% 的块级屏蔽。 MIM 预训练的目标来自公开可用的OpenAI CLIP-L/14 视觉塔,在 224×224 像素图像上训练 [73]。 EVA 的输出特征首先被归一化 [3],然后通过线性层投影到与 CLIP 特征相同的维度。我们使用负余弦相似度作为损失函数。
预训练数据:
表 3b 总结了本文用于预训练 EVA 的数据。对于 CC12M [16] 和 CC3M [88] 数据集,我们只使用没有说明文字(caption)的图像数据。对于 COCO [61] 和 ADE20K [129] 数据集,我们只使用训练集数据。还使用了 ImageNet-21K [30] 和 Object365 [87] 图像数据。所有这些数据都可以公开访问。用于预训练的合并数据集共有 2960 万张图像。

我们用作 MIM 预测目标的 CLIP 特征以自监督的方式在 4 亿图像-文本数据集上进行训练。因此,在预训练期间,EVA 也在某种程度上隐式地利用了来自该数据集的知识。同时,这些 CLIP 特征也广泛用于其他最先进的表示学习和预训练工作,例如 BEiT 家族 [70、104]、AI 生成的内容 [78、83、84] 和大规模数据集过滤 [10、85、86]。
预训练设置和超参数。
如表 3c 所示,EVA 通过 Adam [53] 进行了优化,解耦权重衰减 [67] 为 0.05。峰值学习率为 1e-3 并根据余弦学习率计划衰减。本文采用随机深度 [46],正则化速率为 0.1和 RandResizeCrop (0.2, 1) 进行数据增强。不使用颜色抖动。

预训练基础设施和统计数据。
表 3d 中提供了一些基本的预训练统计数据。我们使用的 GPU 是 NVIDIA A100-SXM4-40GB。预训练代码基于用 PyTorch [69] 编写的 BEiT [5]。我们还采用带有 ZeRO stage-1 优化器 [77] 的 DeepSpeed 优化库 [80] 来节省内存。我们发现在整个预训练过程中使用具有动态损失缩放的 fp16 格式足够稳定,而无需使用 bfloat16 格式。由于我们使用 fp16 精度,EVA 也可以使用 16× NVIDIA 24GB (32GB) GPU 进行预训练,带(不带)梯度检查点 [20]。
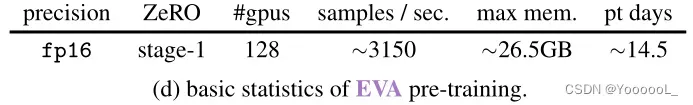
2.3.下游任务评估
在本节中,在几个代表性基准上广泛评估预训练的 EVA,例如图像分类(§2.3.1)、视频动作识别(§2.3.2)、目标检测和实例分割(§2.3.3)、语义分割(§2.3.4),以及具有零样本评估的对比图像文本预训练(§2.3.5)。 EVA 在广泛的下游任务上实现了最先进的性能。
(图像分类和视频动作识别省略)
2.3.3 目标检测&实例分割
数据集。
我们评估了 EVA 在 COCO [61] 和 LVISv1.0 [39] 基准上的目标检测和实例分割性能。 COCO 是一种广泛使用的目标级识别基准,分别由 118k train、5k val 和 20k test-dev 图像组成,具有 80 个常见目标类别。 LVISv1.0 是一个新兴的大词汇目标级识别基准,它有超过 1,200 个对象类别以及超过 200 万个高质量实例分割掩码(接近 COCO 实例掩码的 2 倍)。
值得注意的是,COCO 和 LVISv1.0 几乎使用同一组图像,LVISv1.0 的 train 和 val split 与 COCO train 和 val split 有很大的重叠。同时,COCO 的对象类别比 L VISv1.0 少得多(即 80 对 1,200+)。因此,评估模型在 COCO 和 LVIS 上的性能是有趣且有意义的。
指标。
对于 COCO,本文在 val 和 test-dev split上报告了标准框 AP (APbox) 和掩码 AP (APmask)。对于 LVISv1.0,我们使用 [39] 中定义的 APbox、APmask 和 APmaskrare 在 v1.0 验证集上评估 EVA。我们还报告了 LVIS 2021 challenge3 中使用的实验性“边界,固定 AP”(表 8a 中的 APboundary)以供参考。
训练和评估设置。
EVA 使用 Cascade Mask R-CNN [12] 作为检测器,并采用 ViTDet [59] 的训练设置(例如,大规模抖动数据增强 [37])和架构配置(例如,交错窗口和全局注意力)。按照惯例 [64, 104, 126],我们首先使用分辨率为 1024*1024 的 Objects365 [87] 数据集对整个检测器进行中间微调,然后我们分别用1280*1280的输入在 COCO 和 LVISv1.0 train split上微调检测器。
我们报告了 EVA 的单尺度评估和多尺度评估/测试时间增强 (tta) 结果以供比较。对于 COCO,还应用了 Soft-NMS [8]。例如分割任务,分类分数是通过掩码 [105] 校准的 [47]。
模型架构以及 COCO 和 LVISv1.0 的超参数几乎相同(即,超参数几乎是从 COCO 到 LVISv1.0 的“零样本”转移),期望我们使用联合损失 [131] 和在 LVISv1.0 上遵循 ViTDet 重复因子采样 [39]。
COCO结果。
或许COCO才是最猛的视觉标杆。表 7 将 EVA 与 COCO 上的一些先前领先方法进行了比较。本文的模型在目标检测和实例分割任务上创造了新的最先进的结果。
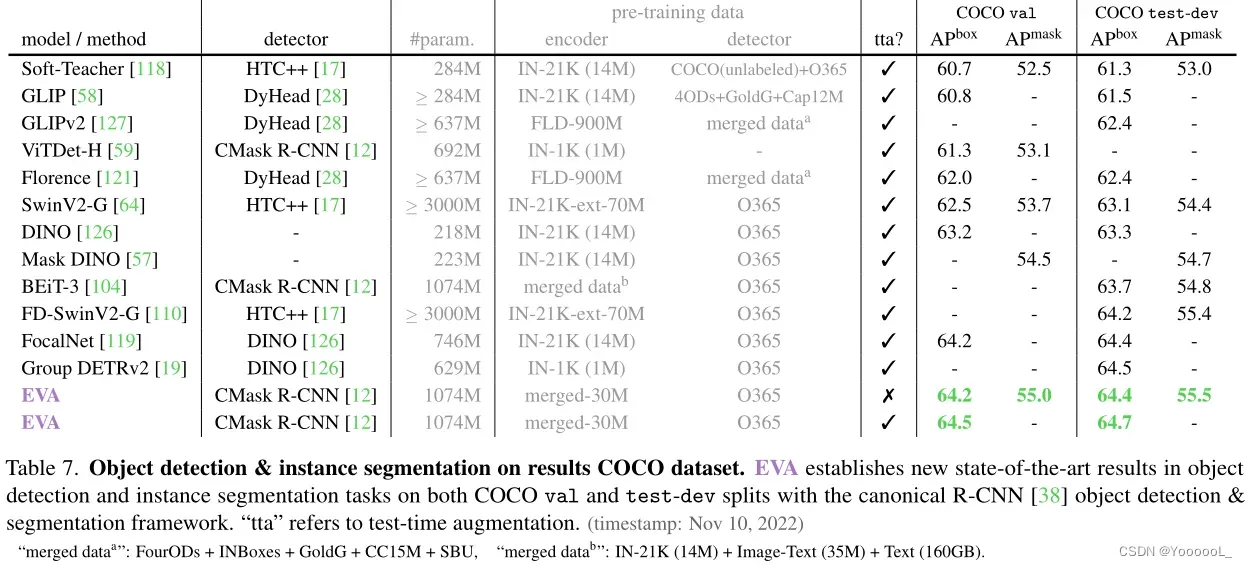
与同样使用 Cascade Mask R-CNN [12] 的 ViTDet-H [59] 相比,EVA 表明,使用更大的模型和更好的编码器&检测器预训练,在使用相同的检测器时可以大大提高性能。
与选择更成熟和高度优化的 DINO 检测器 [126] 的 FocalNet [119] 和 Group DETRv2 [19] 相比,EVA 表明,如果有足够的模型大小、数据和预训练,也可以通过经典的 R-CNN 框架 [38] 实现更好的性能。另一方面,由于使用 DINO,FocalNet 和 Group DETRv2 无法进行实例分割。
与 SwinV2-Giant [64] 和 FD-SwinV2Giant [110] 相比,它们也采用了来自 R-CNN 家族的(更强的 HTC++ [17])检测器,但具有 ~3× 模型大小的 EVA,本文的方法简化了预训练过程并通过更好的表示来完成“Giant-killing”行为。
与 BEiT-3 相比,EVA 表明可以在 在预训练期间 不利用 (i) 语义特征量化/标记化 [5、70] 和 (ii) 图文配对预训练数据和大型语料库的情况下 构建最先进的目标级识别系统。
LVIS 结果。
表 8a 总结了 LVISv1.0 验证集的结果。 EVA 通过单尺度评估在所有指标下实现了最先进的性能,大大优于以前的最佳方法。

分析LVIS-COCO差距:more is different。
在 COCO 和 LVISv1.0 基准上评估和分析模型是有趣且有价值的,因为它们共享几乎相同的图像集,但具有不同数量的带标记的目标类别。与只有 80 个标注类别的 COCO 相比,LVIS 标注了 1200 多个对象类别,因此自然具有长尾分布,更接近具有挑战性的现实世界场景 [39]。一般来说,LVIS 被认为是目标级识别中比 COCO 更难的基准,与 COCO 相比,传统方法在 LVIS 上的性能通常会大幅下降。
在表 8b 中,本文分析了 EVA 的 LVISv1.0 和 COCO 基准与其他最先进方法之间的性能差距。对于之前领先的方法,如 ViTDet,APbox 之间的性能差距在 8 左右,APmask 之间的差距在 5 左右。但是,使用相同的检测器(Cascade Mask R-CNN)和与 ViTDet 预训练的几乎相同的设置MAE-Huge (ViTDet-H),EVA 不仅在 LVIS 和 COCO 基准测试上同时取得了最先进的结果,而且在很大程度上缩小了它们之间的性能差距,特别是对于实例分割任务,EVA通过单尺度评估在 LVIS 和 COCO 上实现相同的性能。与 ViTDet-H 相比,本文展示了一个更大的模型和更强的表示可以在具有挑战性的大词汇量实例分割基准测试中取得巨大飞跃——下面将描述一个警告。
请注意,说 EVA 基于“零 APmask 间隙”“解决”LVIS 大词汇量实例分割任务是不准确的,并且有可能在 LVIS 上实现比 COCO 更高的 APmask(例如,LVIS 具有更高质量的掩码注释训练和评估)。尽管 LVIS 上 EVA 的 APmaskrare 比以前的方法好得多,但稀有类别和常见/频繁类别之间仍然存在很大差距(即 APmaskrare = 48.3 vs APmaskcomm = 55.5 / APmaskfreq = 57.4)。从另一个角度来看,LVIS 和 COCO 之间的 APbox 差距(EVA 为 1.9)可能更好地反映了大词汇和普通词汇对象级识别之间的整体差距,因为该指标消除了实例掩码注释质量的混杂因素。
尽管如此,EVA 在具有挑战性的大词汇量对象级识别任务中取得了重大突破。我们相信其他大型视觉基础模型,如 SwinV2-G 和 BEiT-3 在 COCO 和 LVISv1.0 基准测试中也具有类似的特性。我们希望我们的努力可以鼓励社区在扩展模型和在每个任务中追求最先进的同时更多地关注不同任务之间的关系。
2.3.5 具有零样本分类评估的对比语言-图像预训练
CLIP(对比语言-图像预训练)[48、50、72、73] 是一种多模态基础模型,通过对比图像-文本预训练连接视觉和语言。 CLIP 可以应用于任何图像分类基准,只需提供要识别的视觉类别的名称 [1]。因此,CLIP 的引入实质上重塑了视觉识别的格局。同时,CLIP 特征还在表示学习 [70、104]、AI 生成的内容 [78、83、84] 和大数据集过滤 [10、85、86] 等方面发挥着核心作用。
在本节和表 10 中,本文展示了 EVA 不仅是广泛的视觉下游任务的强大编码器,而且还是在视觉和语言之间架起桥梁的多模式支点。为了证明这一点,我们在各种零样本图像/视频分类基准中将 EVA 作为十亿级 CLIP 的视觉塔进行训练和评估。
CLIP 模型放大的基线和主要挑战。
本文将本文的 CLIP(称为 EVA CLIP)与其他仅利用可公开访问的数据/学术资源的开源 CLIP 竞争对手进行比较。模型配置和统计数据详见表 10a。
CLIP 模型训练和扩展有两个众所周知的主要挑战:(i) 大规模 Open CLIP 模型(例如,Open CLIP-H 和 Open CLIP-g [2, 48])通常会遇到严重的训练不稳定问题 [ 2] 并且必须使用 bfloat16 格式进行优化。 (ii) 训练效率低,这可能会阻碍模型扩大和下游性能。例如,Open CLIP-g 由于其大量的计算需求而严重缺乏训练,其性能甚至比模型尺寸较小的充分训练的 Open CLIP-H 更差。
与本文的 CLIP 模型相比,Open CLIP-H & -g 是从头开始训练的,使用更多的图像-文本对(本文的~2.9× 和~1.1×)在∼3 倍的 GPU上 从更大的数据集(我们的~5×)中采样。通过利用 EVA,可以通过改进的零样本分类性能加速十亿级 CLIP 模型训练,如下所述。
训练设置。
对于本文的 CLIP 模型,本文通过 预训练的 EVA 初始化视觉编码器 和 来自 OpenAI CLIP-L 的语言编码器。预训练实现基于 Open CLIP [48]。本文还采用带有 ZeRO stage-1 优化器 [77] 的 DeepSpeed 优化库 [80] 来节省内存。我们发现在整个训练过程中使用具有动态损失缩放的 fp16 格式足够稳定,而无需使用 bfloat16 格式。这些修改使我们能够在 256× NVIDIA A100 40GB GPU 上训练批处理大小为 41k 的 1.1B CLIP。
评估设置。
本文在 12 个基准上评估每个 CLIP 模型的零样本图像/视频分类性能,并报告 top-1 准确性以进行比较。
对于零样本图像分类任务,本文选择了 8 个基准,即 ImageNet-1K [30]、ImageNet-V2 [81]、ImageNet-Adversarial (ImageNet-Adv.) [43]、ImageNetRendition (ImageNet-Adv.) [ 42]、ImageNet-Sketch (ImageNetSke.) [102]、ObjectNet [6]、CIFAR-10 和 CIFAR-100 [54]。我们还对 CLIP 模型的鲁棒性感兴趣,通过具有自然分布变化的 ImageNet-{1K, V2, Adv., Ren., Ske.} 和 ObjectNet 的平均性能与原始 ImageNet-1K 之间的性能差距来评估验证准确性。
对于零样本视频分类任务,我们选择了 4 个基准,即 UCF-101 [92]、Kinetics-400 [52]、Kinetics600 [14] 和 Kinetics-700 [15]。
结果。
表 10b 显示了比较。本文的 EVA CLIP 实现了最高的平均精度,并且在 12 个零样本分类基准中的 10 个中表现最好。值得注意的是,在不使用任何训练集标签的情况下,ImageNet-1K 验证零样本 top-1 的准确率为 78.2%,与原始 ResNet-101 [41] 相匹配。此外,本文的模型非常稳健,并且在面对 ImageNet 中的自然分布变化时性能下降最小。
最后,在表 11 中,本文提供了 EVA-CLIP 在 ImageNet-1K 验证集上的零样本、线性探测和端到端微调 top-1 精度,以供参考。本文的方法在所有现有的自监督学习方法中创造了新的最先进的结果。
请注意,EVA CLIP 的视觉分支从 OpenAI CLIP-L 学习,而语言分支从相同的 CLIP-L 模型初始化。因此,从只有 430M 参数的 CLIP-L 开始,本文逐步扩展到 1.1B EVA CLIP-g,性能有了很大改进。
这意味着 交错的 MIM 和图像文本对比预训练 可能是一种高效且可扩展的 CLIP 训练方法。据我们所知,EVA CLIP-g 是通过可公开访问的数据和资源训练的最大的高性能 CLIP 模型。本文希望本文在扩展和改进 CLIP 方面的实践也能启发和转移到其他大规模多模态基础模型的研究。
3. Related Work
掩码图像建模 (MIM)
通过预测以可见上下文为条件的掩码视觉内容来学习丰富的视觉表示。 ViT [33] 和 iGPT [18] 报告了第一个有意义的 MIM 预训练结果。 BEiT 家族 [5, 70, 104] 通过掩码视觉标记预测极大地提高了 MIM 的性能。最近的工作 [4、21、32、34、40、106、116、130](重新)探索 MIM 中的像素/特征回归,但仅限于相对较小的模型和数据规模。在这项工作中,本文通过掩码图像-文本对齐特征预测 [44、109] 探索了大规模 MIM 预训练的局限性。
视觉基础模型。
ConvNets [56] 长期以来一直是事实上的标准视觉架构。自 AlexNet [55] 以来,ConvNets 迅速发展并变得更深、更广、更大 [41,45,65,91,93,96,114]。然而,在足够大的模型和数据规模下,由于缺乏可扩展的预训练任务和内置的归纳偏差,ConvNets 落后于 ViTs [33]。进入 2020 年代,大型预训练 ViT [33,123],例如具有分层架构的 SwinV2-G [64] 以及具有多模态表示的 BEiT-3 [104] 开始展示各种视觉基准。在这项工作中,本文展示了通过利用未标记的图像,普通的ViT 可以有效地扩展到十亿级参数,并在各种下游任务中脱颖而出。
4. 结论
在这项工作中,本文推出了 EVA,这是一个十亿参数的普通的 ViT 编码器,用于探索掩码视觉表示学习的极限。本文展示了 简单的掩蔽特征建模 作为视觉学习前置任务 在具有最小视觉先验的体系结构上很好地扩展,并在具有代表性和多样化的下游任务集中取得了优异的结果。
本文希望 EVA 能够通过掩码建模弥合视觉和语言研究之间的差距,并为视觉研究的霓虹灯起源做出贡献。
文章出处登录后可见!