最近清华大学开源的ChatGLM-6B语言模型在国际上大出风头,仅仅62亿参数的小模型,能力却很强。很期待他们后续1300亿参数模型130B的发布。
为什么一些能力较弱的小模型,这么受追捧?因为ChatGPT、GPT-4虽好,毕竟被国外封锁,而且还要付费,更重要的是,LLM要在各行业提高生产力,很多企业接下来肯定是要自己部署语言模型的,毕竟谁也不敢泄漏自己商业数据给别人的AI去训练,为他人做嫁衣,最后砸了自己的饭碗。
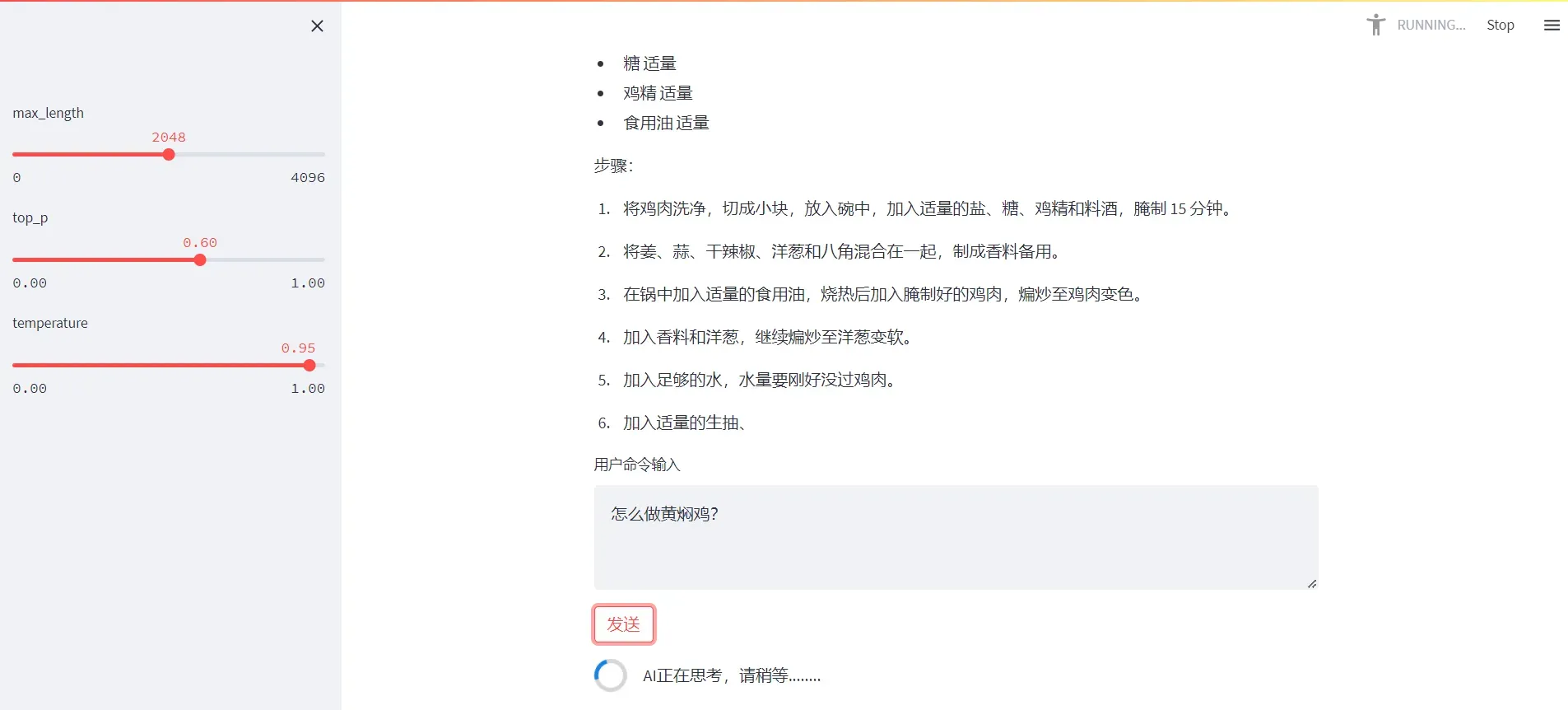
这里根据我的实操经验,分享一下如何自己搭建一个语言模型服务器。最后效果如下:
首先需要搞一台GPU较强的机器,推荐先租一台腾讯云、阿里云等AI训练的机器,T4显卡就行,一般价格是按量付费几毛钱一个小时。我是抢到了腾讯云秒杀活动的主机,60块钱半个月,白菜价。土豪可以自己去装机长期玩。
能干这个活的都是码农吧,那就不废话了,直接上sh命令(:
#我的主机环境是 Ubuntu Server 18.04 LTS 64位,预装了
# Pytorch 1.9.1 Ubuntu 18.04 GPU基础镜像(预装460驱动)
#以下命令从 /root 目录位置开始进行操作的
#更新Ubuntu软件源
apt-get update
#创建目录用于存放ChatGLM源代码
mkdir ChatGLM
cd ChatGLM/
#克隆ChatGLM-6B程序源代码
git clone https://github.com/THUDM/ChatGLM-6B.git
#创建目录用于存放ChatGLM6B-int4量化模型
mkdir model
cd model/
#安装git-lfs便于文件管理
apt install git-lfs
#当前目录初始化为git仓库、安装lfs
git init
git lfs install
#克隆ChatGLM-6B的int4量化模型
git clone https://huggingface.co/THUDM/chatglm-6b-int4
#安装python调用cuda的工具包
apt install nvidia-cuda-toolkit
cd ChatGLM-6B/
#添加三行依赖:
vim requirements.txt
chardet
streamlit
streamlit-chat
#安装所需的python依赖库
pip install -r requirements.txt
#代码中2处修改为模型绝对路径:
vim web_demo2.py
/root/ChatGLM/model/chatglm-6b-int4
#运行ChatGLM6B 的web版聊天程序,即可访问http://主机IP:8080进行聊天
python3 -m streamlit run ./web_demo2.py --server.port 8080
本文来自知识星球:ConnectGPT ,一个致力于探索AI、语言模型的应用技术的小圈子。

文章出处登录后可见!
已经登录?立即刷新