今天推荐一款开源AI变声器,安装过程很友好,不用经历各种麻烦的环境问题, 作者提供了windows下的安装包,一键安装启动很方便。
目前好像对显卡有要求,nvidia显卡支持,amd显卡不支持。
功能特点
- 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
- 即便在相对较差的显卡上也能快速训练
- 使用少量数据进行训练也能得到较好结果(推荐至少收集10分钟低底噪语音数据)
- 可以通过模型融合来改变音色(借助ckpt处理选项卡中的ckpt-merge)
- 简单易用的网页界面
- 可调用UVR5模型来快速分离人声和伴奏
安装教程
1.安装包下载
直接使用最新版本,点击链接下载即可,安装包3.9G左右
## 安装包下载页面
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/releases
2.启动
解压后直接运行go-web.bat文件启动webUI
运行成功后会出现访问地址,直接访问即可。
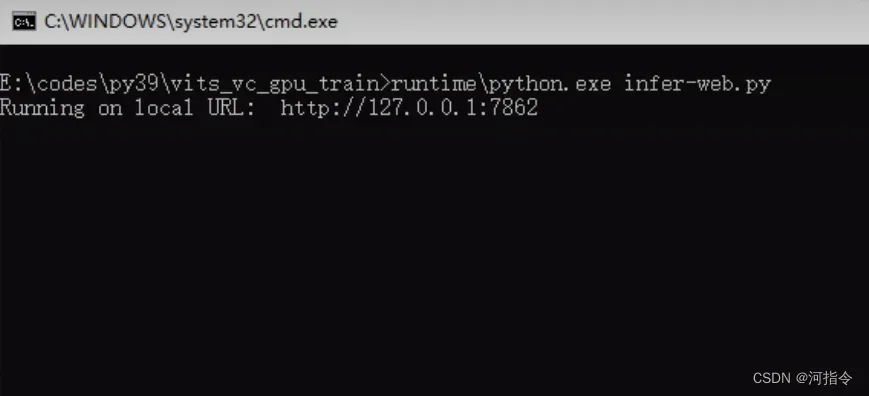
使用介绍
模型的话,可以使用其他人分享的,也可以自己训练模型。下面介绍怎么训练模型
训练模型
点击切换到训练选项卡
输入实验名:这里会存放标准训练格式的训练集,实验日志,实验配置和训练完成的模型,索引文件。
输入训练文件夹路径:这里存放的是你需要用于训练的所有干声,最好是干净,清晰,无杂音的,不然训练出来的声音效果会很差。
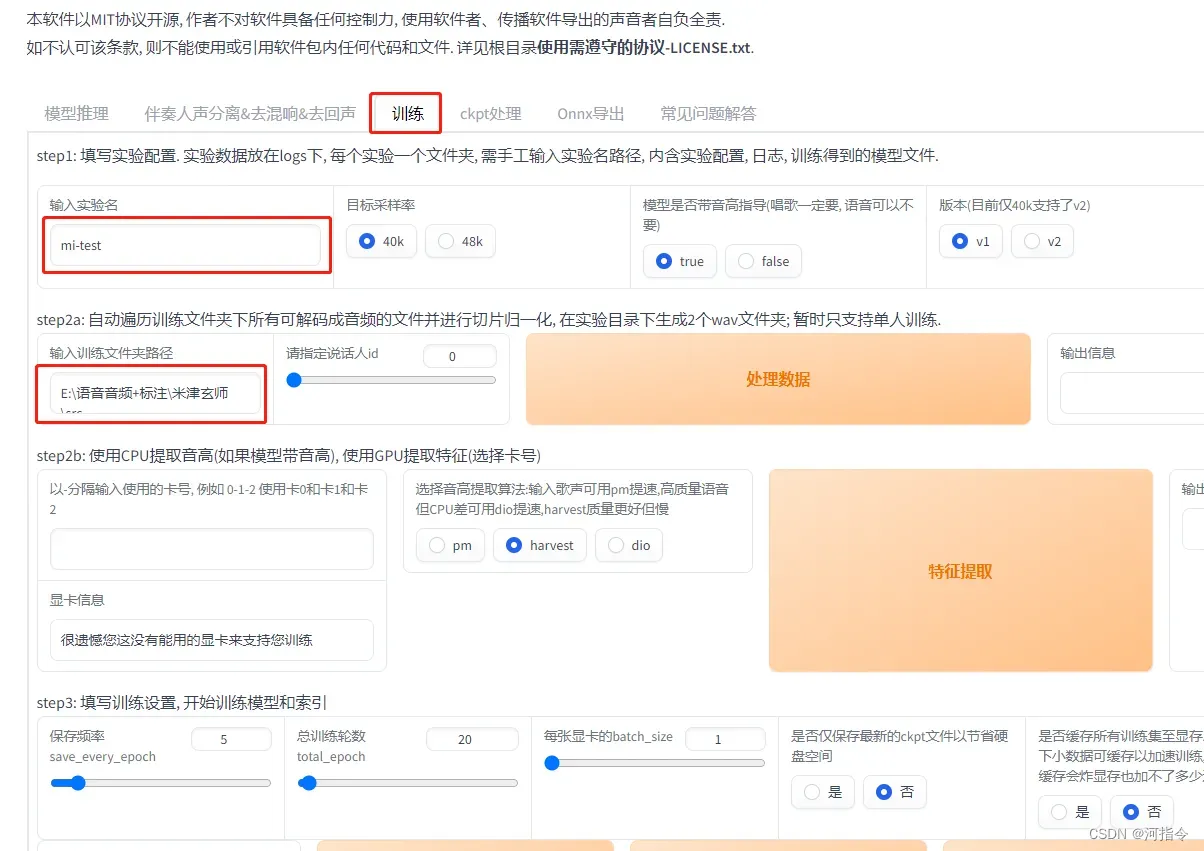
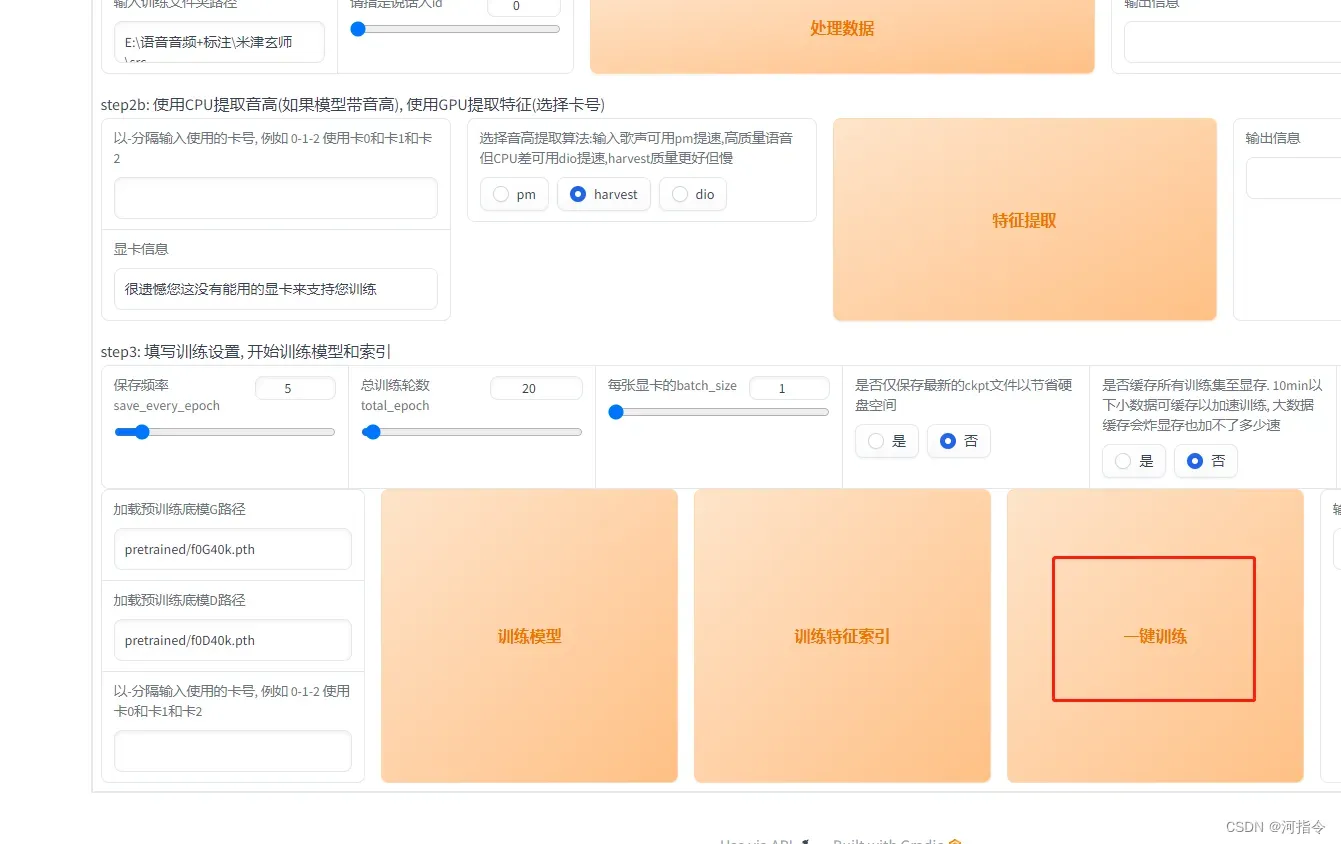
设置好配置项后,下拉点击一键训练即可。
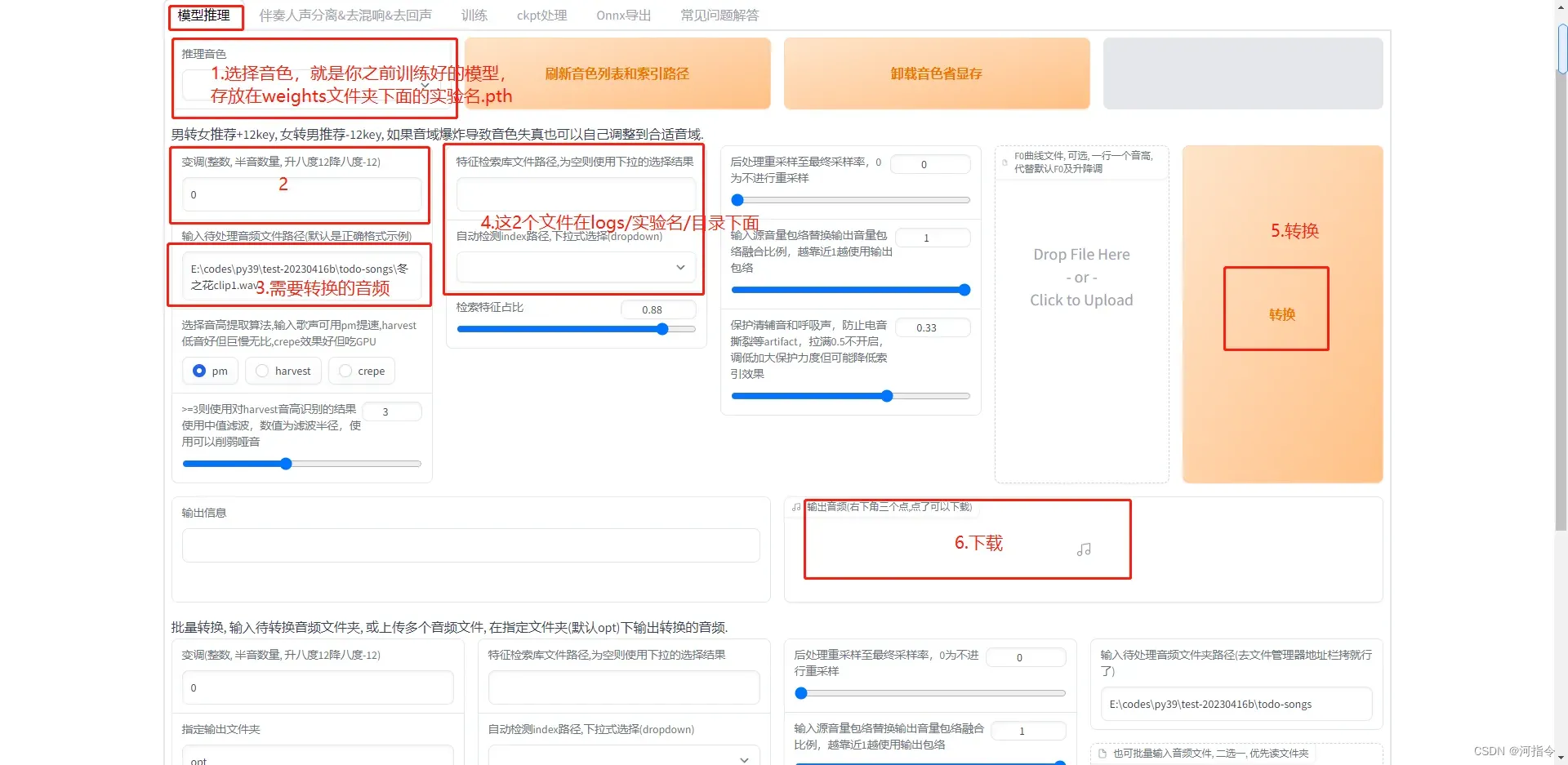
模型推理,使用模型
使用我们训练好模型,进行音频转换
好了, 文章到此结束,感谢您的阅读!
如果你想了解更多AI相关知识,和一些好玩的工具,那就关注一下我吧!
文章出处登录后可见!
已经登录?立即刷新