OpenAI——CLIPs(打通NLP与CV)
Open AI在2021年1月份发布Contrastive Language-Image Pre-training(CLIP),基于对比文本-图像对对比学习的多模态模型,通过图像和它对应的文本描述对比学习,模型能够学习到文本-图像对的匹配关系。它开源、多模态、zero-shot、few-shot、监督训练均可。
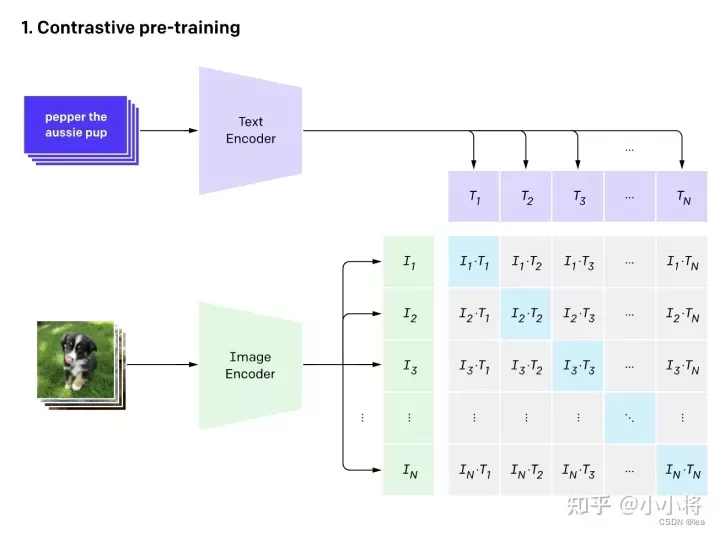
原文原理图:
原文算法思想伪代码:

OpenAI CLIP 原项目:
https://github.com/openai/CLIP
使用
(一)原版
安装:
$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
$ pip install ftfy regex tqdm
$ pip install git+https://github.com/openai/CLIP.git
当然没有GPU和cuda,直接CPU也可以
源码:
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("cat.png")).unsqueeze(0).to(device) # CLIP.png为本文中图一,即CLIP的流程图
text = clip.tokenize( ["cat in basket", "python", "a cute cat","pytorch","code of CLIP","code of pytorch ","code"]).to(device) # 将这三句话向量化
with torch.no_grad():
image_features = model.encode_image(image) # 将图片进行编码
text_features = model.encode_text(text) # 将文本进行编码
# print("image_features shape:",image_features.shape,image_features.size(),image_features.ndim)
# print("text_features shape:", text_features.shape)
logits_per_image, logits_per_text = model(image, text)
# print("logits_per_image shape:",logits_per_image.shape)
# print("logits_per_text shape:", logits_per_text.shape)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]] # 图片"CLIP.png",text["a diagram", "a dog", "a cat"] 对应"a diagram"的概率为0.9927937
####(2)接前:矩阵相乘分类
import pandas as pd
with torch.no_grad():
score = []
image_features = model.encode_image(image) # 将图片进行编码
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features = model.encode_text(text) # 将文本进行编码
text_features /= text_features.norm(dim=-1, keepdim=True)
# texts = ["cat in basket", "python", "a cute cat","pytorch","code of CLIP","code of pytorch ","code"]
texts = ["cat in basket", "python", "a cat","pytorch","code","pytorch code"]
for text in texts:
textp = clip.tokenize(text)
# 问题文本编码
textp_embeddings = model.encode_text(textp)
textp_embeddings /= textp_embeddings.norm(dim=-1, keepdim=True)
# 计算图片和问题之间的匹配分数(矩阵相乘)
sc = float((image_features @ textp_embeddings.T).cpu().numpy())
score.append(sc)
print(pd.DataFrame({'texts': texts, 'score': score}).sort_values('score', ascending=False))
print('')
print('-------------------------')
print('')
(二)transformer库版本
Transformers 库的基本使用:
https://blog.csdn.net/benzhujie1245com/article/details/125279229
安装:
pip install transformers
CLIP源码:
####基本用法二:利用transformer库
from PIL import Image
from transformers import CLIPProcessor,CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
#这里加入自己图片的地址就行
image = Image.open('cat.png')
#这里加入类别的标签类别
text = ["cat in basket", "python", "a cute cat","pytorch","code of CLIP","code of pytorch ","code"]
inputs = processor(text=text,images = image,return_tensors="pt",padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
for i in range(len(text)):
print(text[i],":",probs[0][i])
输入图片:

结果:

但是CLIP对于有些比较抽象的图片或任务效果并不一定好,例如:
图片code.png:

PLUS:
贴几个其他的使用示例链接:
https://zhuanlan.zhihu.com/p/493489688?utm_id=0
https://zhuanlan.zhihu.com/p/472448018
https://zhuanlan.zhihu.com/p/511460120
https://www.kaggle.com/code/moeinshariatnia/openai-clip-simple-implementation/notebook
https://distill.pub/2021/multimodal-neurons/
CLIP feature改进版:https://github.com/jianjieluo/OpenAI-CLIP-Feature
但是CLIP仍是一项AI重要突破,尤其是当它应用到CV相关任务时,例如风格换装,CLIPBERT,CLIP4Clip,CLIP2Video,CLIPTV、image caption等等。
文章出处登录后可见!