
星系动物园(galaxy zoo)是由牛津大学等研究机构组织并邀请公众协助的志愿者科学计划,目的是为超过100万个星系图像进行分类。这是天文学中一次规模浩大的公众星空普查活动,大众参与热情高涨,在近十万名志愿者的积极参与下,只用了175天就完成了第一阶段的星系动物园项目:对95万个星系进行了分类,而且平均每个星系被分类了38次。
根据星系动物园的研究结果,星系图像可以分为4大类:圆形星系、中间星系、侧向星系和旋涡星系。图1显示了随机挑选的4类星系的图像。第1行是圆形星系,即星系形状是边缘平滑的圆形。第2行是中间星系,即星系形状是椭圆,之所以称之为中间星系,是指它的形状介于第1行的圆形星系与第3行的侧向星系之间。第3行显示的侧向星系,是中心有凸起的侧向盘状星系。第4行是旋涡星系,顾名思义,这类星系形状呈旋涡状,星系中间是核球,四周有旋臂,银河系就是一个典型的旋涡星系。

■ 图1 星系图像示例
因为星系动物园的原始数据集比较大,本章只使用其中的一部分数据:在4类星系样本中各选择500张图片,所以,本章的数据样本为4×500=2000张图片。每一张图片是带分类标签的RGB图片,图片大小为424×424×3像素。类别标签为0、1、2、3,分别代表圆形星系、中间星系、侧向星系和旋涡星系。
本案例的任务是使用卷积神经网络对2000张星系图片进行分类,并评价网络模型的分类效果。
01、案例实现
本节使用Keras库中的ResNet50模型实现上述案例,即利用ResNet50模型对星系图片进行分类。实现过程如下。
1. 数据集说明
在本案例中,数据集存放在image_anli文件夹中,共有4类星系:圆形星系、中间星系、侧向星系和旋涡星系,每一类星系有500张图像,图像大小为424×424×3。按照星系图像的类别,星系图像被放到4个文件夹中,类别标签为0、1、2、3,分别代表圆形星系、中间星系、侧向星系和漩涡星系。文件夹的名称即为该星系的类别标签。数据集所在的目录结构图如图2所示。
■图2 数据集所在的目录结构图
2. 数据集划分
对星系图像进行训练和测试前,首先需要划分数据集:将2000张星系图像按照7∶2∶1的比例分成训练集(train)、验证集(validation)和测试集(test),分别用于模型的训练、验证和测试。实现思路是:首先将image_anli文件夹按照9∶1的比例分成temp文件夹和test文件夹,其中test文件夹为测试集,存放了4个子文件夹,共包括4×50=200张星系图像;temp文件夹中存放了4个子文件夹,共包括4×450=1800张星系图像,再将temp文件夹按照7∶2的比例划分成训练集和验证集。
新建一个.py程序,命名为split_dataset.py,用于完成数据集划分任务,具体实现过程如下。
(1) 导入库。导入os库和shutil库,进行文件夹和文件的相关操作,random库实现随机划分数据。代码如下。
import os
import random
import shutil(2) 定义函数split(),按照指定比例将原始数据集划分为两个数据集,并将图像复制到相应文件夹里。代码如下。
def split(initial path, save dir, split rate):
'''
划分数据集
:param initial path:字符串类型,未划分数据之前的文件路径
:param save dir:列表类型,划分数据之后的文件路径
:param split rate:浮点数,划分比例
'''
# 获取数据集数量及类别
file number list=os.listdir(initial path)
total num classes=len(file number list)
#置入随机种子,使每次划分的数据集相同
random.seed(1)
for i in range(total num classes):
class name=file number list [i]
image dir=os.path.join(initial path,class name)
# 调用函数将图像从一个文件夹复制到另一个文件夹
file copy(image dir,save list dir,class name, split rate)
print(' s 已成功划分 class name)其中,file_copy()函数的功能将图像从file_dir按照比例复制到save_dir。代码如下。
def file copy(file dir, save dir,class name,split rate):
'''
将图像从源文件夹复制到目标文件夹
:param file dir:字符串类型,未划分数据之前的文件路径
:param save dir:列表类型,划分数据之后的文件路径
:param class name:字符串类型,星系类别的名称
:param split rate:浮点数,划分比例
'''
image list=os.listdir(file dir) #获取图片的原始路径
image number=len(image list)
train number=int(image number * split rate)
#从 image list 中随机选取图像
train_sample=random.sample(image_list,train_number)
test_sample=list(set(image_list) - set(train_sample))
data_sample=[train_sample,test_sample]
# 复制图像到目标文件夹
for i in range(len(save dir)) :
if os.path.isdir(save dir i + class name) :
for data in data sample [i] :
shutil.copy(os.path.join(file dir,data),os.path.join(save)
dir [i] + class_name+'/',data))
else:
os.makedirs(save dir[i] + class_name)
for data in data sample [i] :
shutil.copy(os.path.join(file_dir,data), os.path.join(save)
dir [i] + class_name+'/', data))(3) 主函数。在主函数中第一次调用split()函数,将原始数据集按照9∶1的比例划分为temp文件夹和test文件夹,第二次调用split()函数,将temp文件夹按照7∶2的比例划分成训练集和验证集。代码如下。
if_name_== ' _main_'
# 原始数据集路径
initial path=r'./image anli'
#保存路径
save_list dir=[r'./temp/',r'./test/]
# 原始数据集按 9:1被划分为 temp 文件夹和 test 文件夹
split rate=0.9
split(initial path, save list dir, split rate)
# 继续将 temp 划分成训练集和验证集
initial path=r'./temp
#保存路径
save list dir=[r'./train/',r'./val/!]
# temp 数据集按 7:2 被划分成训练集和验证集
split rate=7/9
split(initial path,save list dir,split rate)
3. 利用ResNet50模型对图像进行分类
划分数据集后,新建一个classify_resnet50.py程序,实现图像的读取与处理、模型的训练与评价等功能。具体实现过程如下。
(1) 导入库。导入Keras已封装的ResNet50模型,对图像进行分类,导入sklearn.metrics模块的相关方法评估模型的分类准确率、召回率、精确率和F1度量。代码如下。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
from sklearn.metrics import accuracy score
from sklearn.metrics import precision score
from sklearn.metricsimport recall score
from sklearn.metrics import f score(2) 读取数据集的图像。从本地读取训练集、验证集和测试集的图像,分别放入对象train、val、test中。代码如下。
# 从训练集、验证集和测试集所在文件夹里读取图像
train dir=r'. train'
test dir=r'. test!
val dir=r'. val
height=224width=224
# resnet 50 的处理的图像大小
# resnet 50 的处理的图像大小
batch size=24
train=tf.keras.preprocessing.image dataset from directory(
train dir
seed=123
image size=(height, width),
batch size=batch size)
test=tf.keras.preprocessing.image dataset from directory(test dir,
shuffle=False
image size=(height,width)batch size=batch size)
val=tf.keras.preprocessing.image dataset from directory(val dir,
seed=123
image size=(height, width)
batch size=batch size)读取测试集图像时,设置shuffle参数的值为False,这样做的目的是不会打乱读取的测试集图像的顺序,便于后续评估模型的分类效果。
(3) 图像增强。大型数据集是深度神经网络成功的先决条件。如果训练数据集比较小,可以使用图像增强来提高训练集的多样性。图像增强是指在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,神经网络在每一轮迭代训练时用到的图片不完全一样,以增强模型的健壮性。此外,随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。例如,随机缩放或移动图像,使目标对象出现在不同的位置,减少模型对于对象出现位置的依赖。在本案例中,训练集的星系图像的数量有限,所以使用tensorflow.keras的预处理层对训练集进行如下的图像增强操作。
① 随机翻转tf.keras.layers.experimental.preprocessing.RandomFlip(mode):将输入的图片进行随机翻转。一般mode=“horizontal”表示水平翻转,mode=“vertical”表示上下翻转。
② 随机旋转tf.keras.layers.experimental.preprocessing.RandomRotation(factor):按照旋转角度(factor×2π)将输入的图片进行随机旋转。参数factor可以是2个元素的元组,也可以是单个浮点数:正值表示逆时针旋转,负值表示顺时针旋转。例如,factor=(-0.2,0.3)表示旋转范围为[-20%×2π,30%×2π]中的随机量。factor=0.1表示旋转范围为[-10%×2π,10%×2π]内的随机量。由于星系图片有着旋转不变性,旋转后星系图片的类别不会发生改变,可以在一定程度上提高数据量。
③ 随机缩放layers.experimental.preprocessing.RandomZoom(factor):将星系图像进行随机的缩小或放大。参数factor表示缩放比例,取值可以是2个元素的元组,也可以是单个浮点数。factor=(0.2,0.3)表示输出缩小范围为[+20%,+30%]的随机量,factor=(-0.3,-0.2)表示输出放大范围为[+20%,+30%]的随机量。
④ 随机高度layers.experimental.preprocessing.RandomHeight (factor):随机改变图像的高度。参数factor表示比例,取值与随机缩放的factor参数相似。
⑤ 随机宽度layers.experimental.preprocessing.RandomWidth(factor):将图像随机移动一段宽度。
⑥ 归一化layers.experimental.preprocessing.Rescaling(scale):将数据进行归一化处理。scale=1./255表示将取值范围为[0,255]的输入归一化到[0,1]范围内。
本案例中图像增强的具体代码如下。
# 图像增强,包括随机水平翻转,随机旋转,随机缩放
data augmentation=keras.Seguential(
[
layers.experimental.preprocessing.RandomFlip("horizontal",
input shape=(height, width,3)),
layers.experimental.preprocessing.RandomRotation(0.1),
layers.experimental.preprocessing.RandomZoom(0.1),
layers.experimental.preprocessing.Randomwidth(0.1),
layers.experimental.preprocessing.RandomHeight(0.1),
layers.experimental.preprocessing.Rescaling(1./255)
]
)为了展现图像增强的效果,在数据集中随机选取的一张图片,对其进行水平翻转和随机旋转,效果如图3所示。
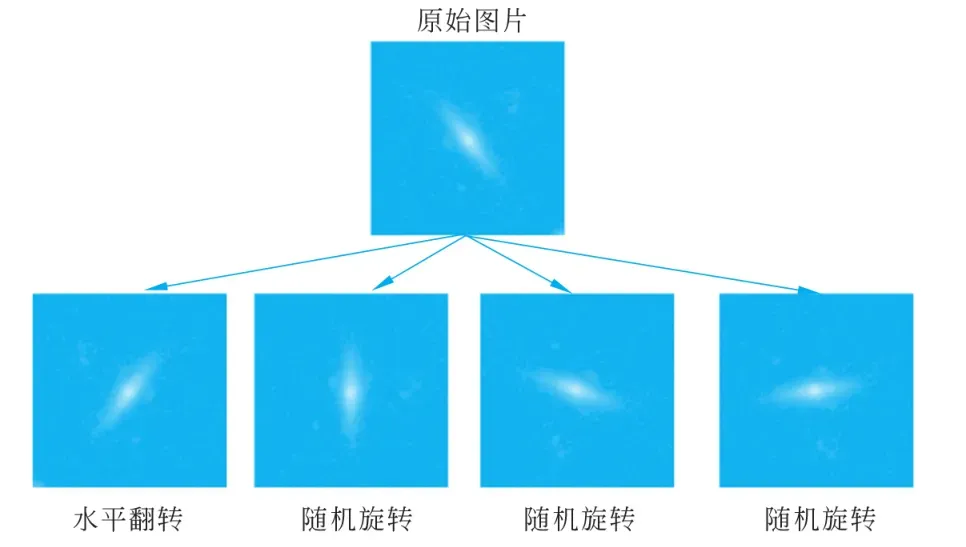
■ 图3 图像增强示例
(4) 模型构建及训练。本案例选用的网络模型是Keras自带的ResNet50模型,使用的优化器(optimizer)为Adam,选用的loss为sparse_categorical_crossentropy,衡量标准(metrics)使用的是accuracy,设置的epochs的值为100,batch_size的值为32。当然,超参数的选择并不唯一,大家可以自行尝试其他超参数,并观察其训练效果。代码如下。
#构建模型
model=Sequential(Ldata augmentation,
ResNet50(weights=None,classes= 4)])
#配置模型参数
model.compile(optimizer="Adam"loss='sparse categorical crossentropy'rmetrics='accuracy' )
#训练模型
epochs=100
history=model.fit(train,epochs=epochs,batch size=32
validation data=val)
# 保存模型
model.save("resnet img.h5")程序运行完成后,程序所在目录下生成了名为resnet_img.h5的文件,即训练所得的模型。
(5) 测试模型。模型训练完成后,使用测试集对模型进行测试,查看模型的分类效果。评价模型时,使用Scikit-learn库中的准确率、召回率、精确率和F1度量评价指标。本案例将以上指标写入一个自定义函数test_score()中,然后将模型预测的类别和真实标签值送入该函数,得到该模型的分类效率在85%以上。代码如下。
deftest score(x,y):
'''
自定义函数对分类效果进行评估
:param x:预测类别
:param y:真实标签
'''
print("准确率:.4f" accuracy score(x,y))
print("精确率:4f" precision score(x,Y,average='macro'))
print("召回率:.4f"号recall score(x,y,average='macro'))
print("F1度量:.4f" fl score(x,y,average='macro'))
#加载模型
model=tf.keras .models.load model("resnet img.h5")
# 使用模型对测试集进行预测
predict y=model.predict(test)
predict class=np.argmax(predict y, axis=1) #选出最大概率对应的下标#生成标签值
labels=[07 * 50+[1 * 50+27 * 50+/3 * 50 # 评估预测结果
test score(predict class,labels)输出结果为:
准确率:0.8550
精确率:0.8550
召回率:0.8791
E1度量:0.8571通过上文可知,测试集test中含有200张星系图像,分为4类,每1类有50张图像。通过model.predict(test)对测试集进行预测,返回的data里面的值为200个array数组,每个array数组里面存放着4个概率值,对应这一星系图像被分为这0、1、2、3类的概率值。然后通过np.argmax()得到了每一个array数组中的最大值对应的下标,该下标的值就是这一图像的类别。
读取测试集图片的时候,并没有将测试集图片的顺序打乱,所以测试集的标签也没有被打乱。测试集里的200张星系图像对应的标签顺序是50个标签值为0、50个标签值为1、50个标签值为2、50个标签值为3,而labels变量是一个含有50个0、50个1、50个2、50个3的列表,所以使用labels变量表示测试集的200张图像的真实类别。
文章出处登录后可见!