目录
1.VGG网络简介
一.VGG概述
VGGNet是牛津大学视觉几何组(Visual Geometry Group)提出的模型,该模型在2014ImageNet图像分类与定位挑战赛 ILSVRC-2014中取得在分类任务第二,定位任务第一的优异成绩。VGGNet突出的贡献是证明了很小的卷积,通过增加网络深度可以有效提高性能。VGG很好的继承了Alexnet的衣钵同时拥有着鲜明的特点。相比Alexnet ,VGG使用了更深的网络结构,证明了增加网络深度能够在一定程度上影响网络性能。
说得简单点,VGG就是五次卷积的卷积神经网络。
二.VGG结构简介
我们上文已经说了,VGG其实就是五层卷积。我们来看这个图:
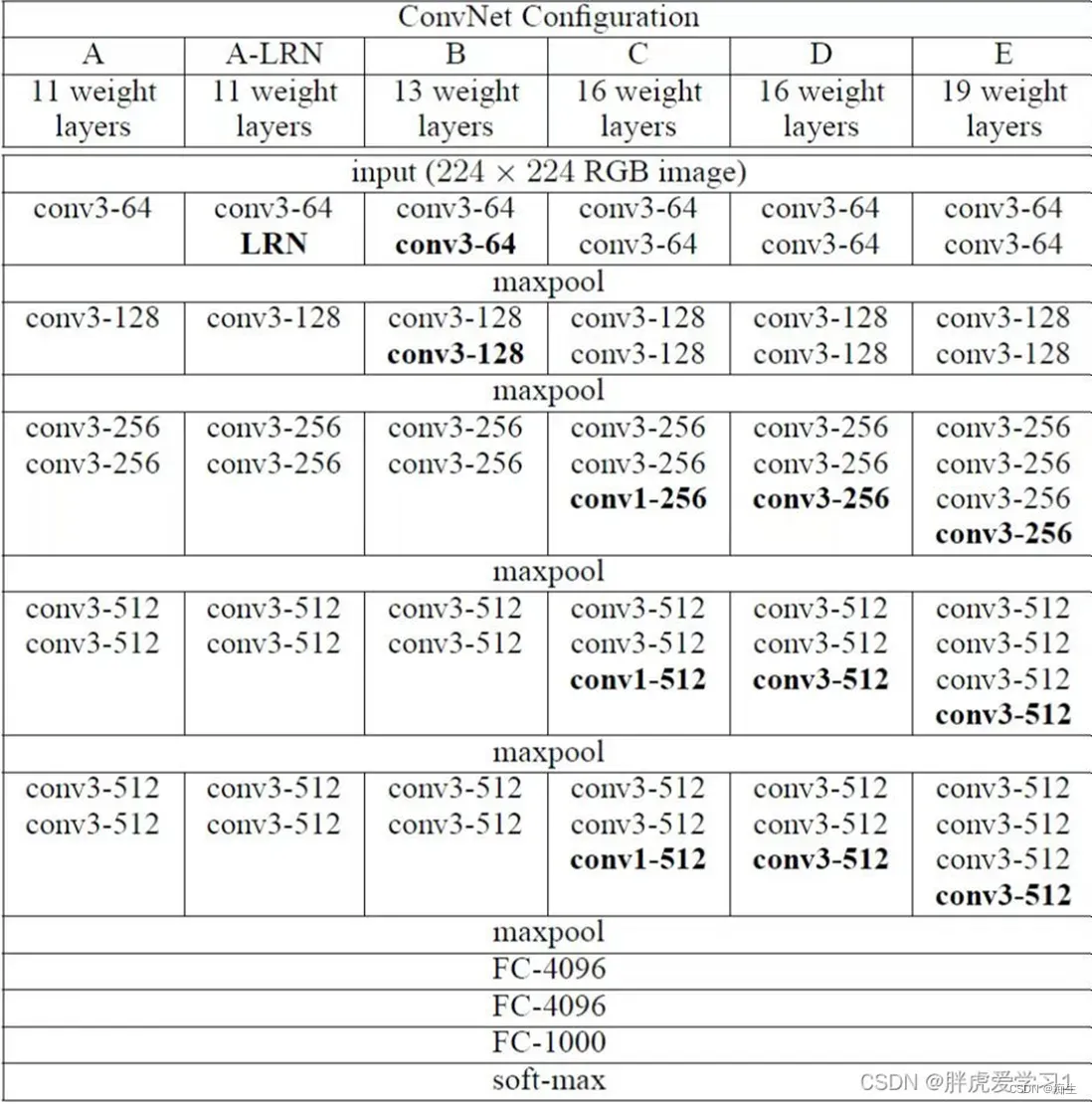
这个图是作者当时六次实验的结果图。在介绍这个图前,我先进行几个概念说明:卷积层全部为3*3的卷积核,用conv3-xxx来表示,xxx表示通道数。
在这个表格中,我们可以看到,
第一组(A)就是个简单的卷积神经网络,没有啥花里胡哨的地方。
第二组(A-LRN)在第一组的卷积神经网络的基础上加了LRN(小白们不用太过了解这个,现在已经不是主流了,LRN是Alexnet中提出的方法,在Alexnet中有不错的表现 )
第三组(B)在A的基础上加了两个conv3,即多加了两个3*3卷积核
第四组(C)在B的基础上加了三个conv1,即多加了三个1*1卷积核
第五组(D)在C的基础上把三个conv1换成了三个3*3卷积核
第六组(E)在D的基础上又加了三个conv3,即多加了三个3*3卷积核
初高中就告诉我们,实验要控制变量(单一变量),你看,用到了吧
那么,我们从这一组实验中能得到什么结果呢?
1.第一组和第二组进行对比,LRN在这里并没有很好的表现,所以LRN就让他一边去吧
2.第四组和第五组进行对比,cov3比conv1好使
3.统筹看这六组实验,会发现随着网络层数的加深,模型的表现会越来越好
据此,咱们可以简单总结一下:论文作者一共实验了6种网络结构,其中VGG16和VGG19分类效果最好(16、19层隐藏层),证明了增加网络深度能在一定程度上影响最终的性能。 两者没有本质的区别,只是网络的深度不一样。
接下来,以VGG16为例作具体讲解:
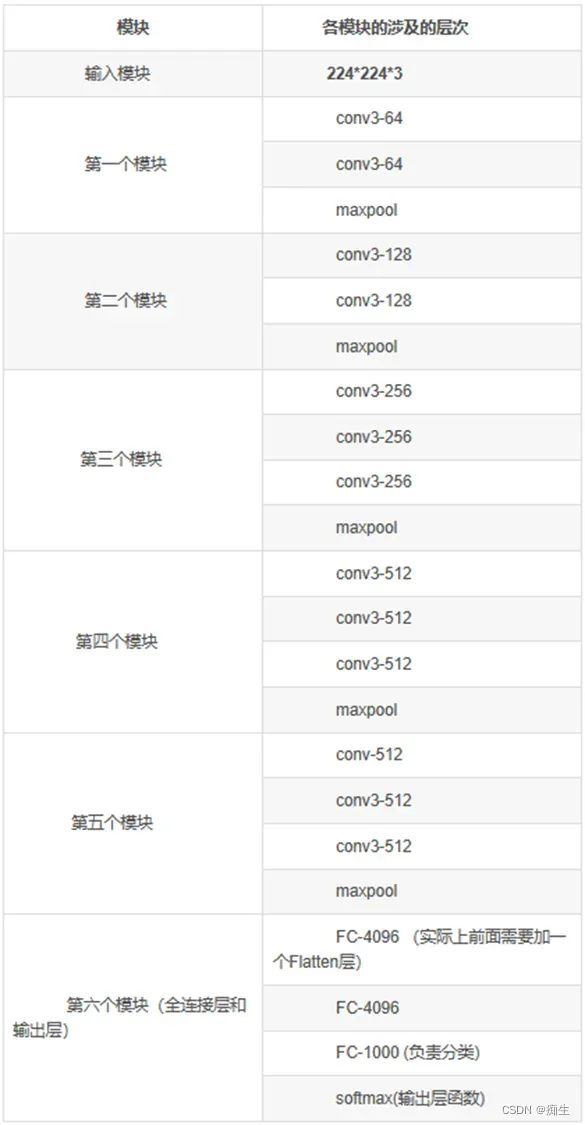
相信有小白会疑惑:组号下面那个weight layers 是啥意思?别急,看下面:
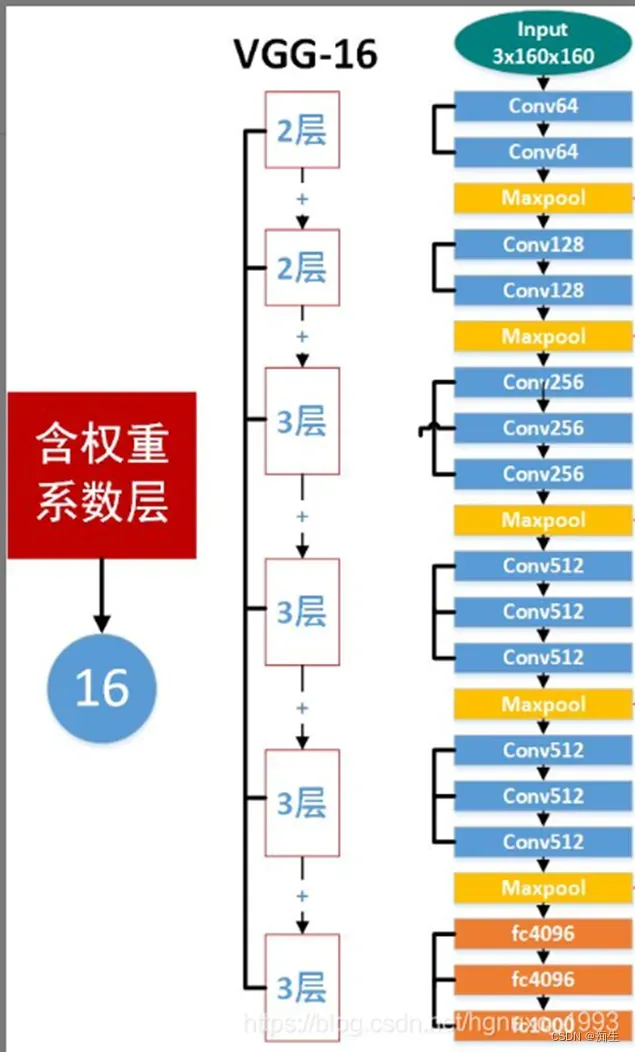
看这几个数字加起来,是不是就是16?
就像上图展示的,除了黄色的maxpool(池化层),其他所有层数的总和,就是16,同理,VGG19也一样。
那么,为什么不算池化层呢?
这是因为,池化层没有权重系数,而其他层都有,所以…..
那么,我们接下来去看VGG是如何工作的:
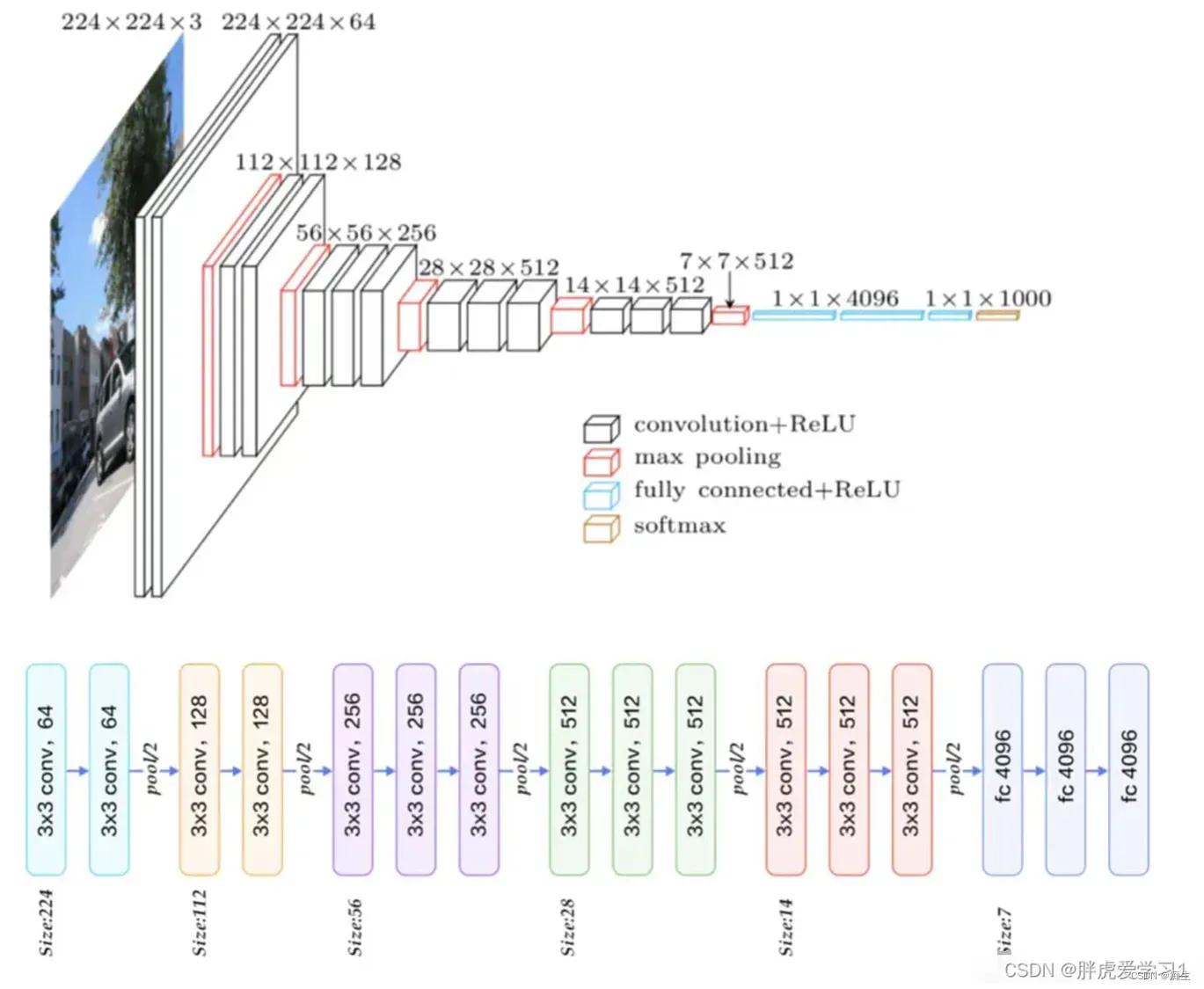
看,一个长224,宽224,通道数3的图,经过第一个模块,通道数增加到64,随后经过池化层长宽减半。然后到第二个模块,通道数增加到128,到池化层长宽再减半……
一直到最后一次池化,得到7×7×512的结果,然后通过三个全连接层,变成最后的1×1×1000的分类结果(也不一定是一千,这里的1000是当时的比赛结果)
2.VGG的优点
1.小卷积核组:作者通过堆叠多个3*3的卷积核(少数使用1*1)来替代大的卷积核,以减少所需参数;
2.小池化核:相比较于AlexNet使用的3*3的池化核,VGG全部为2*2的池化核;
3.网络更深特征图更宽:卷积核专注于扩大通道数,池化专注于缩小高和宽,使得模型更深更宽的同时,计算量的增加不断放缓;
4.将卷积核替代全连接:作者在测试阶段将三个全连接层替换为三个卷积,使得测试得到的模型结构可以接收任意高度或宽度的输入。
5.多尺度:作者从多尺度训练可以提升性能受到启发,训练和测试时使用整张图片的不同尺度的图像,以提高模型的性能。
6.去掉了LRN层:作者发现深度网络中LRN(Local Response Normalization,局部响应归一化)层作用不明显。
3.VGG亮点所在
在AlexNet中,作者使用了11×11和5×5的大卷积,但大多数还是3×3卷积,对于stride=4的11×11的大卷积核,理由在于一开始原图的尺寸很大因而冗余,最为原始的纹理细节的特征变化可以用大卷积核尽早捕捉到,后面更深的层数害怕会丢失掉较大局部范围内的特征相关性,后面转而使用更多3×3的小卷积核和一个5×5卷积去捕捉细节变化。
而VGGNet则全部使用3×3卷积。因为卷积不仅涉及到计算量,还影响到感受野。前者关系到是否方便部署到移动端、是否能满足实时处理、是否易于训练等,后者关系到参数更新、特征图的大小、特征是否提取的足够多、模型的复杂度和参数量等。
计算量
VGG16相比AlexNet的一个改进是采用连续的几个3×3的卷积核代替AlexNet中的较大卷积核(11×11,7×7,5×5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层的非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
在VGG中,使用了3个3×3卷积核来代替7×7卷积核,使用了2个3×3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升网络的深度,在一定程度上提升神经网络的效果。
比如,3个3×3连续卷积相当于1个7×7卷积:3个3*3卷积的参数总量为 3x(3×3×C2) =27C2,1个7×7卷积核参数总量为1×7×7×C2 ,这里 C 指的是输入和输出的通道数。很明显,27<49,即最终减少了参数,而且3×3卷积核有利于更好地保持图像性质,多个小卷积核的堆叠也带来了精度的提升。
感受野
简单理解就是输出feature map上的一个对应输入层上的区域大小。
计算公式:(从深层推向浅层)
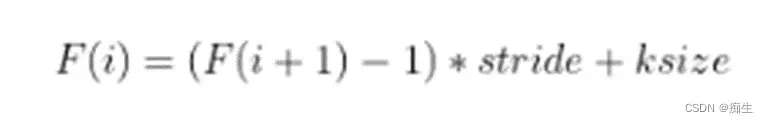
F(i)为第i层感受野
strider为第i步的步距
ksize为卷积核或池化核尺寸
说白了,感受野其实就是结果层一个神经元节点发生变动能影响多少个输入层神经元节点。
以下图为例: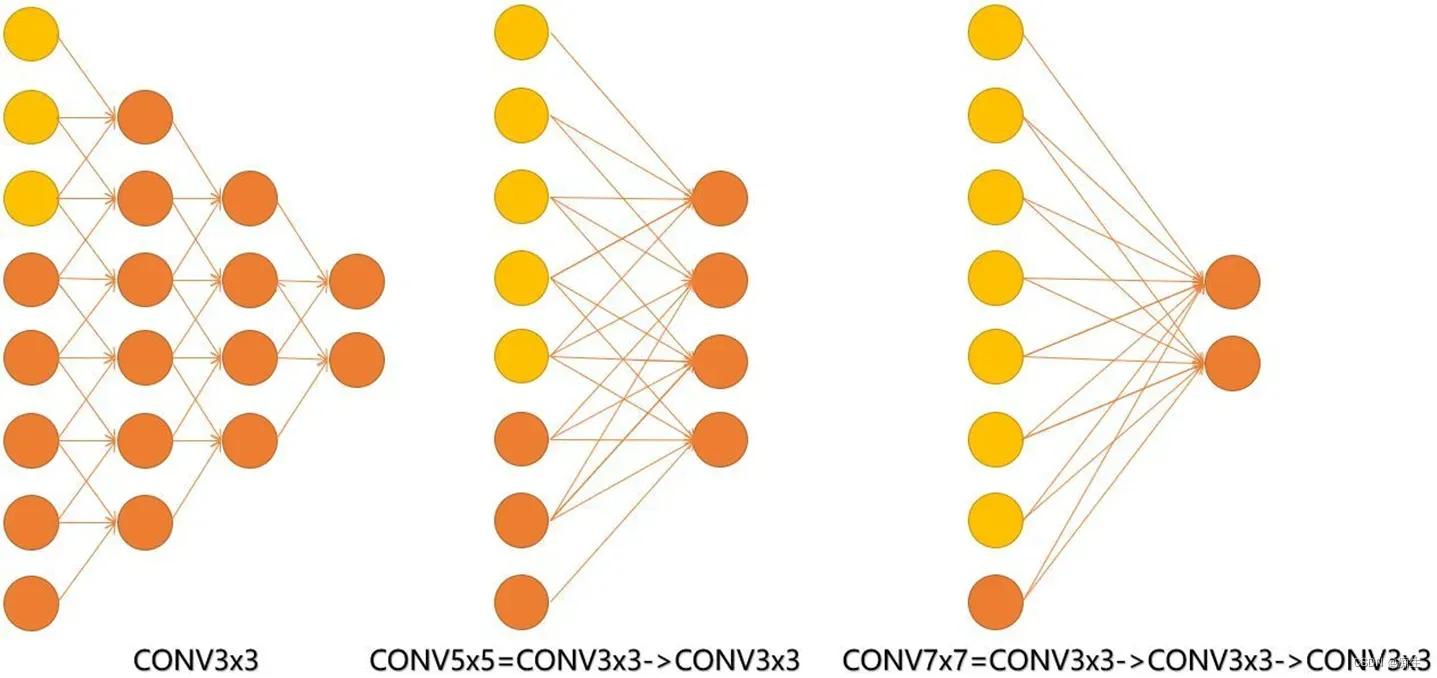
第一幅图大家可以看到,1个神经元连接了上一层3个神经元,第二幅图连接5个,第三幅图连接7个。并且大家发现没有,一次5*5卷积下来和两次3*3卷积得到的神经元相同, 一次7*7卷积下来和三次3*3卷积得到的神经元相同。
并且,大家也可以在最左边的图推一推,更改最后一层的一个节点将会影响第一层的7个节点,再看看最右边的图,改最后一层的一个节点将会影响第一层的7个节点。这就代表了3个conv3与一个conv7最终所得到的结果的感受野相同。
于是,在相同感受野的情况下:
堆叠小卷积核相比使用大卷积核具有更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,可使决策函数更加具有辨别能力;此外,3×3比7×7就足以捕获细节特征的变化:3×3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化;3个3×3堆叠近似一个7×7,网络深了两层且多出了两个非线性ReLU函数,网络容量更大,对于不同类别的区分能力更强
文章出处登录后可见!