网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
一)HTTP协议
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,HTTP的端口号为80。
1. HTTP的请求与响应
HTTP通信由两部分组成:客户端请求消息 与 服务器响应消息。
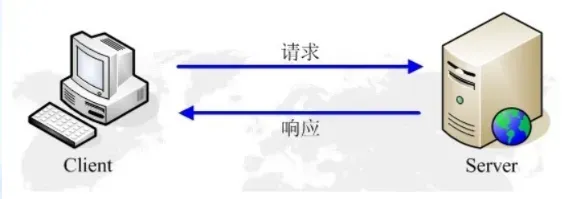
浏览器发送HTTP请求的过程:
- 当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
- 当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
- 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。在运行窗口输入“CMD”进入仿DOS窗口,然后输入Mysql –u root –proot 命令进入MYSQL数据库环境。其中–u后面是用户名,-p后面是密码。
2. URL
URL(Uniform / Universal Resource Locator的缩写):统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。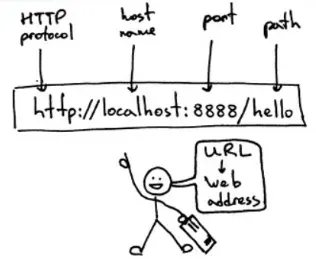
3.客户端HTTP请求
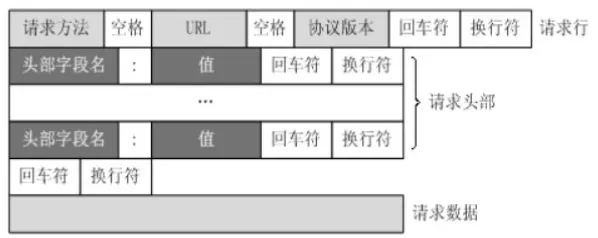
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括格式:请求行、请求头部、空行、请求数据等四个部分组成,下图给出了请求报文的一般格式。
4.服务端HTTP响应
HTTP响应也由四个部分组成,分别是: 状态行、消息报头、空行、响应正文。响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。 常见状态码:
- 100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
- 300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
- 400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。
- 500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
5.项目依赖包
requests模块用来获取目标网页文本,BeautifulSoup模块用来获取html中特定标签内容,fake_useragent.UserAgent类提供random方法可以随机生成合法的User-Agent,作为请求头一部分请求网页,以避免网页请求失败。myMysql是当前目录的一个文件,其中定义一个类。用来二次封装pymysql开放的操作mysql数据库的接口,实现对数据库的读写。
二)爬取和解析网站数据
1.爬取网页
定义函数request_douban(),目标url作为参数,headers作为请求头,将自动生成的user_agent添加到headers作为反爬机制。调用requests类get方法获取请求url返回的响应内容,通过response.status_code获取响应代码,若为200,表示成功响应,通过response.status_code获取响应的html正文,作为函数返回值。
2.目标网页分析
这次以豆瓣主页为实例,首先打开我们的目标链接https://movie.douban.com/top250可以看到如图所示的网页
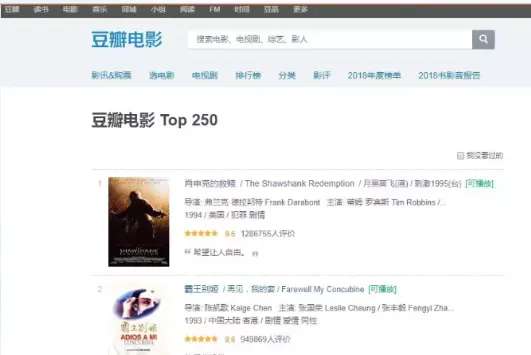
每一页显示了 25 条数据,当我们点击下一页的时候链接请求参数变了,https://movie.douban.com/top250?start=25&filter=,。我们可以明确下一页就是从第 25 条数据开始加载的。所以,我们可以使用这个 start=25 来做变量,实现翻页获取信息。接下来我们来看下我们要的主要信息:电影名称、电影排名、电影评分、电影作者、电影简介。我们可以使用 BeautifulSoup 超简单获取对应我们想要获取的电影信息。主要思路,请求豆瓣的链接获取网页源代码,然后使用 BeatifulSoup 拿到我们要的内容,最后就把数据存储到MySQL中。
3. BeautifulSoup解析html提取目标数据
BeautifulSoup 是一个能从 HTML 或 XML 文件中提取数据的 Python 库。它能通过自己定义的解析器来提供导航、搜索,甚至改变解析树。它的出现,会大大节省开发者的时间。 定义函数getResult(),BeautifulSoup对象作为参数,首先获取所有类选择器为“grid_view”的li标签,每个电影对应的Tag对象作为列表的元素保存到html变量,定义空列表result用来存储希望得到的电影信息,包括排名、电影名、评分、简介等。遍历html变量,使用BeautifulSoup相关方法,结合html分析获取前述电影信息,即item_index, item_name, item_score, item_intr,将四个包含电影信息的字符串存储在元组item中,最后将item插入列表result暂时存储,result最终作为函数返回值。
4.获取全部页面数据并存储到数据库
定义onePage()函数,整形page作为参数,当变量page=0,url代表首页,包含top25电影信息,当page=1,url代表排名第26到50的电影信息页面,以此类推。调用request_douban(url)获取对应页面html正文,然后html作为参数,实例化BeautifulSoup类生成对象soup,调用getResult(soup)函数,将一个页面中包含的25个电影分别对应的四个电影信息作为返回值保存到列表result。循环10次,i取0到9,10个整数,作为变量传递到onePage()函数。最终空列表result存储了10个页面共250个电影的电影信息。
定义saveToMysql()函数,列表result作为参数,该函数实现了250条电影信息保存到数据表douban.movie中,DBHelper()是在myMysql文件中自定义的数据库操作类,pyMySQL开放接口execute实现sql语句,开放executemany接口实现多条数据插入数据表。 最终项目主函数,调用allPage()函数,返回所有电影信息暂存到result列表,调用saveToMysql()函数实现电影信息存储到数据库。
5.具体代码
此代码借鉴于:https://blog.csdn.net/weixin_48964486/article/details/122563126?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168242521916800226515391%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168242521916800226515391&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-1-122563126-null-null.142v86control_2,239v2insert_chatgpt&utm_term=python%E7%88%AC%E8%99%AB%E7%88%AC%E5%8F%96%E5%95%86%E5%93%81%E4%BF%A1%E6%81%AF%E4%BD%BF%E7%94%A8xpath&spm=1018.2226.3001.4187
# 1.导包
from lxml import etree
import requests
import csv
# 2.拿到目标url
doubanUrl = 'https://movie.douban.com/top250?start={}&filter='
# 3.获取网页源码
def getSource(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
return response.text
# 4.解析数据
def getEveryItem(source):
html_element = etree.HTML(source)
# class = 'info' 电影的名字,评分,引言,详情页的
movieItemList = html_element.xpath("//div[@class='info']")
# 定义一个空列表,添加字典数据
movieList = []
for eachMovie in movieItemList:
# 定义一个字典保存每部电影的数据
movieDict = {}
# 标题
title = eachMovie.xpath("div[@class='hd']/a/span[@class='title']/text()")
# 副标题
otherTitle = eachMovie.xpath("div[@class='hd']/a/span[@class='other']/text()")
# 详情页url
star = eachMovie.xpath("div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()")[0]
link = eachMovie.xpath('div[@class="hd"]/a/@href')[0]
quote = eachMovie.xpath("div[@class='bd']/p[@class='quote']/span/text()")
# 非空判断
if quote:
quote = quote[0]
else:
quote = ''
# 保存数据,标题是主标题+副标题
movieDict['title'] = ''.join(title+otherTitle)
movieDict['url'] = link
movieDict['star'] = star
movieDict['quote'] = quote
#print(movieDict)
movieList.append(movieDict)
return movieList
# 5.保存数据
def writeData(movieList):
with open('douban.csv', 'w', encoding='utf-8' , newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'star', 'quote', 'url'])
writer.writeheader()
for each in movieList:
writer.writerow(each)
if __name__ == '__main__':
movieList = []
for i in range(10):
pageLink = doubanUrl.format(i * 25)
source = getSource(pageLink)
MovieList += getEveryItem(source)
writeData(movieList)
文章出处登录后可见!