在深度卷积神经网络中,通过构建一系列的卷积层、非线性层和下采样层使得网络能够从全局感受野上提取图像特征来描述图像,但归根结底只是建模了图像的空间特征信息而没有建模通道之间的特征信息,整个特征图的各区域均被平等对待。
在一些复杂度较高的背景中,容易造成模型的性能不佳,因此可以引入注意力机制,而注意力机制的原理是通过参考人的视觉感知能力,即人在处理视觉信息初期会集中专注于当前情景下重点区域,而其他区域将相应降低,这为更高层级的视觉感知和逻辑推理以及更加复杂的计算机视觉处理任务提供更易于处理且更相关的信息。这样利用注意力机制提高模型对目标区域的关注度,降低其他区域对目标区域的干扰,进而提高模型的性能。
通过研究近几年论文中的出现的注意力机制和用法,这里介绍几种频次比较高的且在不同语义分割和目标检测领域上均提高了模型性能的注意力机制,希望对大家有帮助。
1.坐标注意力(Coordinate Attention, CA)
CA通过精确的位置信息对通道关系和长程依赖进行编码,使网络能够以较小的计算成本关注大的重要区域,主要包括坐标信息嵌入和坐标注意力生成两个步骤,其结构如图1所示。
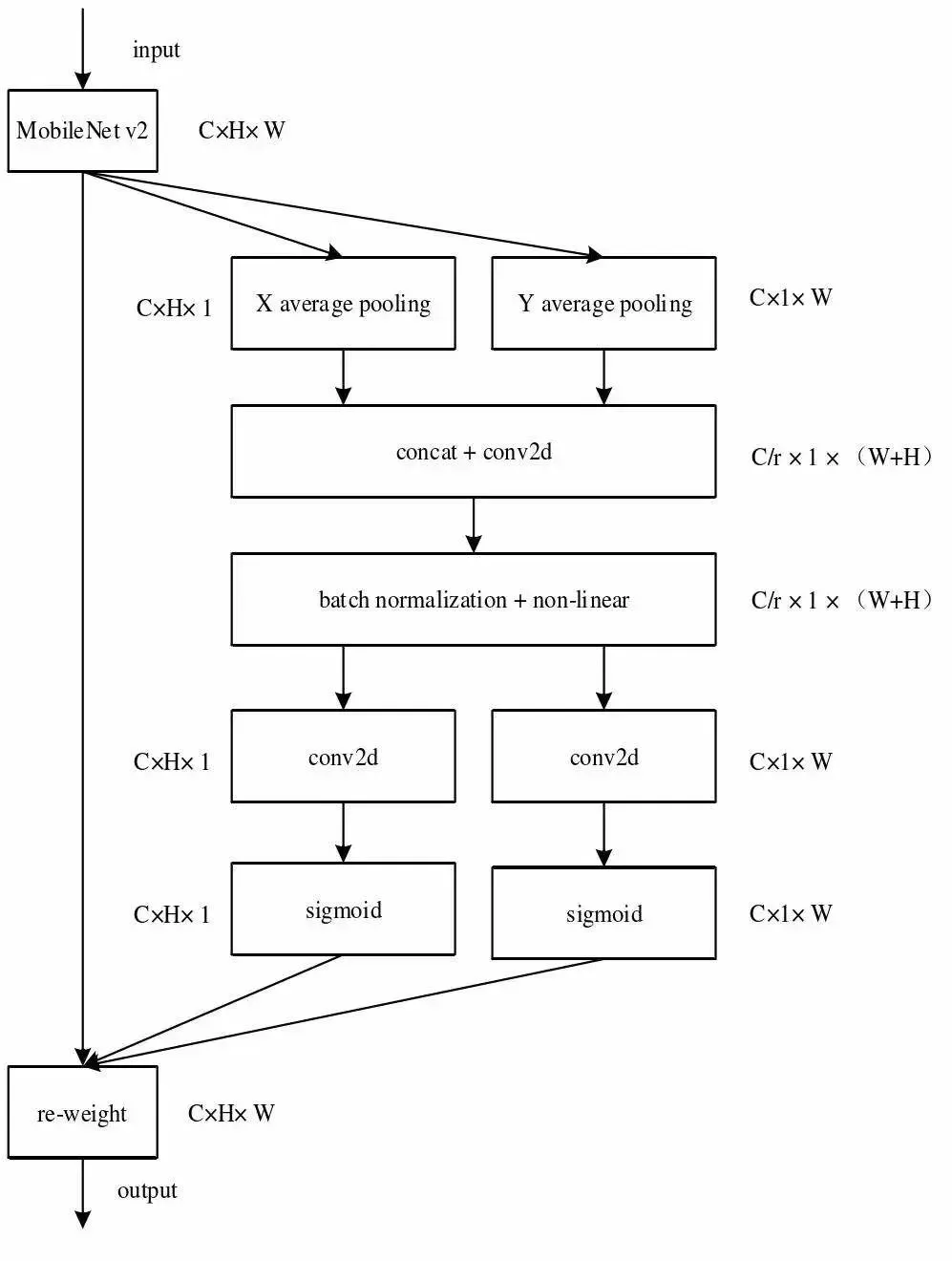
图1 坐标注意力模块
1.1 Coordinate信息嵌入
为了获取图像宽度和高度上的注意力并对精确位置信息进行编码,先将输入特征图分别按照宽度和高度两个方向分别进行全局平局池化,分别获得在宽度和高度两个方向上的特征图。具体而言,给定对于输入的特征张量X,沿水平坐标使用尺寸为(H,1)的池化核对每个通道的特征进行编码,因此,第c通道的高度为h的输出可以表示为:
(1)
其中
表示第c通道的高度为h;
表示第c通道的高度为h的宽度坐标为j的特征图的数值;W表示特征图的宽度。同理,第c通道的宽度为w的输出可以写成:
(2)
其中
表示第c通道的输出高度为w;
表示第c通道的宽度为w的高度坐标为i的特征图的数值;H表示特征图的高度。
这两种变换分别从两个空间方向对特征进行聚合,得到一对方向感知特征图。且这两种变换允许注意力模块捕捉沿着一个空间方向的长期依赖关系,并保存沿着另一个空间方向的精确位置信息,有助于模型更好地定位感兴趣目标。
1.2 Coordinate信息生成
通过公式(1)和(2)可以很好的获得全局感受野对于精确位置信息的编码。为了利用产生的特征,通过信息嵌入中的变换后,将式(1)和(2)产生的聚合特征图进行拼接操作,然后使用1×1卷积变换函数F_{1}对其进行变换操作,得到水平方向和垂直方向编码空间信息的中间特征图f:
(3)
其中,[]是沿空间维度进行的拼接操作,\delta为非线性激活函数,
是在水平方向和垂直方向对空间信息进行编码的中间特征图,r是用来控制SE block大小的缩减率。沿着空间维度将f分解为2个独立的张量
和
,再利用另外两个1×1卷积变换F_{h}和F_{w}分别将f_{h}和f_{w}变换为具有相同通道数的张量到输入X,得到:
(4)
(5)
其中,\delta是Sigmoid激活函数。为了降低模型复杂性和计算开销,通常使用适当的缩减比来缩小f的通道数,然后对输出g_{h}和g_{w}进行扩展,分别作为注意力权重。最后CA模块的输出
可以写成:
(6)
2.卷积注意力模块(convolutional block attention module, CBAM)
CBAM是一个前馈卷积神经网络注意力模块,沿着通道和空间的维度顺序推断注意力图,然后将注意力图乘以输入特征图以进行自适应特征细化。其计算开销可忽略不计,且可以无缝集成到任何CNN架构中。
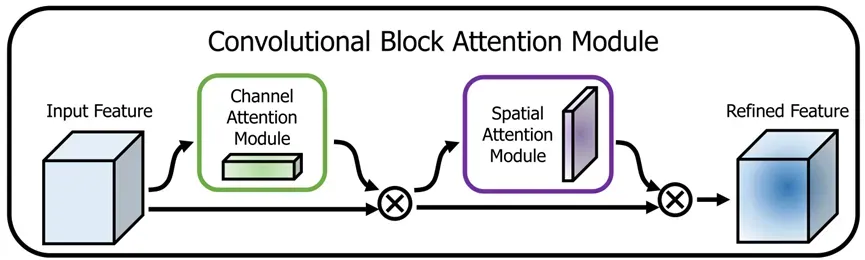
图2 卷积注意力模块
2.1 通道注意力
通道注意力结构如图2所示,首先通过平均池化和最大池化操作来聚合特征图的空间信息,生成两个不同的空间上下文描述符:
和
,它们分别表示平均池特征和最大池特征。然后将这两个特征描述符送到共享网络(由具有一个隐藏层的多层感知器组成)来生成通道注意力图 ,随后再将共享网络应用于每个描述符之后,进行逐元素求和合并输出特征向量。通道注意力计算如下:
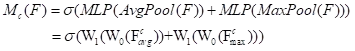
(7)
其中\sigma表示Sigmoid函数,
和
分别为两个输入共享MLP的权重。
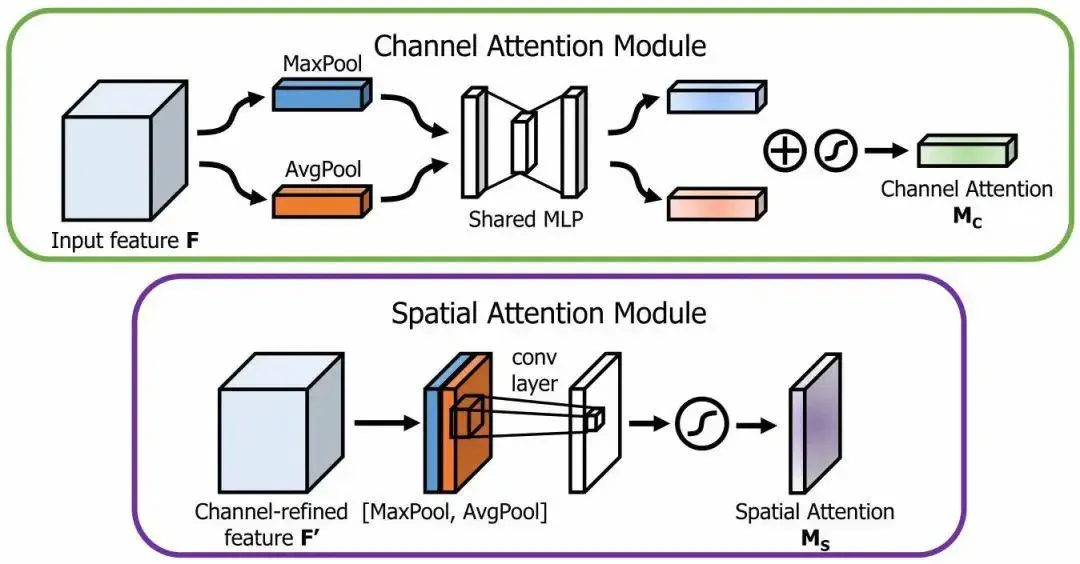
图2 通道注意力
2.2 空间注意力模块
空间注意力模块如图3所示。之前沿着通道方向应用平均池化和最大池化操作来聚合特征图信息,得到两个2D图:
和
,然后通过标准卷积层将它们连接起来并卷积,生成我们的2D空间注意力图,空间注意力计算如下
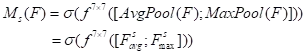
(8)
其中\sigma表示Sigmoid函数,f^{7×7}表示卷积核大小为7×7的卷积运算。
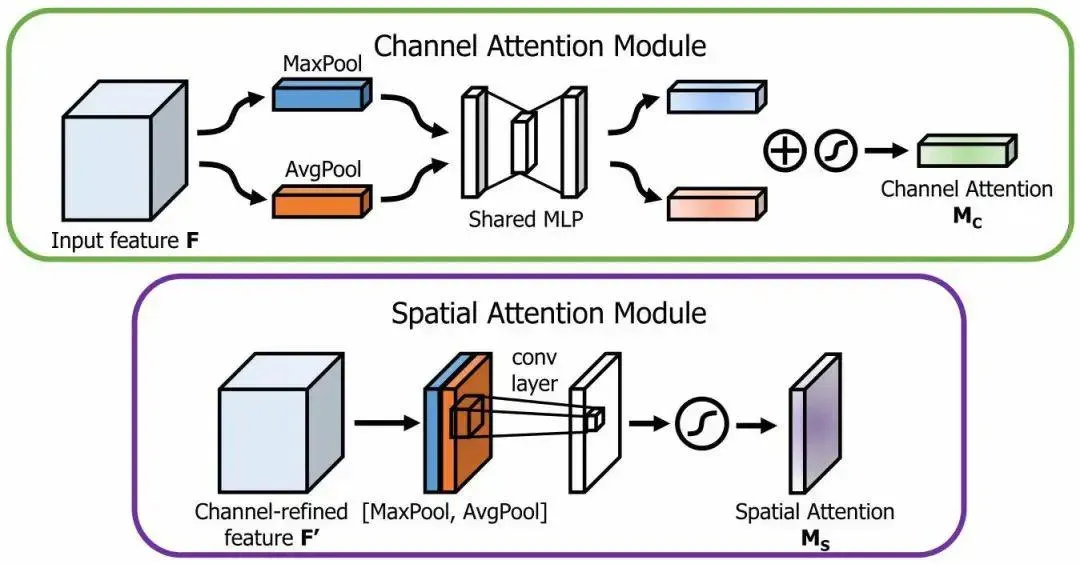
图3 空间注意力
3.挤压和激励注意力(Squeeze-and-Excitation attention, SE)
SE结构通过显式地建模信道之间的相互依赖性,自适应地重新校准信道特征响应,在略微增加计算成本的情况下显著提高了现有最先进的CNN的性能。其结构主要分为挤压和激励两部分,如图4所示。
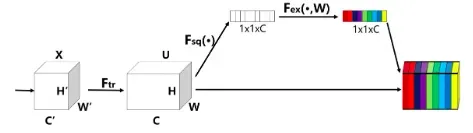
图4 挤压和激励注意力结构
3.1 挤压:全局信息嵌入
为了缓解变换输出U的每个单元不能利用该区域之外上下文信息的问题,通过使用全局平均池来生成通道统计信息来实现将全局空间信息压缩到信道描述符中。通过U的空间维度H×W收缩U来生成统计量z∈RC,从而z的第c个元素计算为:
(9)
注:这里作者使用最简单的全局平均池化,可以试试更复杂的方法进行改进,以提高更多的性能。
3.2 激励:自适应调整
为了利用在挤压操作中聚集的信息,但为了完全捕获通道相关性就必须满足两个标准:①必须灵活,即能够学习通道之间的非线性相互作用;②必须学习非互斥关系,因为希望确保允许增强多个通道。这里选择满足这些标准S形激活门控机制:
(10)
其中,\delta表示ReLU激活函数,
,
。为了限制模型的复杂性,在非线性周围形成两个全连接(FC)层的瓶颈,即具有缩减比率r的维度缩减层,经ReLU后维度增加层到变换输出U的通道维度。通过用激活s重新缩放U来获得块的最终输出:
(11)
其中
和
是标量s_{c}和特征映射
之间的通道乘法操作。
参考文献
[1] Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design[C]. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.2021:13713-13722
[2] Woo S, Park J, Lee JY, et al. CBAM Convolutional block attention module. Proceedings of the 15th European Conference on Computer Vision.2018,3-19.
[3] Jie H, Li S, Gang S, et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
文章出处登录后可见!