本人去年拿了湖南省省一,今年因为各种原因就没有参加这个比赛了。
但是看到了题目,我也想分享一下我的见解,希望给大家提供一些思路上的帮助,但是我也还没具体去分析,各位看官看完,有所收获就是对我最大的鼓励,不敢苟同的也就当图一乐看看吧。
废话不多说直接开始分析题目。
第一问
对这些玻璃文物的表面风化与其玻璃类型、纹饰和颜色的关系进行分析
第一问的第一个小问,我觉得不用考虑太多了,直接用相关性分析。很多现成的平台都可以直接去分析,发现 表面风化和玻璃的类型具有强相关性,这一点对我们后面解题很有帮助。结合玻璃的类型,分析文物样品表面有无风化化学成分含量的统计规律并根据风化点检测数据,预测其风化前的化学成分含量。
主要就是我们能根据风化前后的化学成分的变化来建立一个模型,从而得到风化前后的关系,从而来预测风化前的化学成分含量。 化学成分属性一共有14种,我们建立起模型就非常麻烦,那么我们首先考虑能不能删除一些不必要的属性,从而简化模型进行预测。 首先我们观察一些数据
观察一下高钾玻璃我们发现氧化钠,氧化铅,氧化钡,氧化锶……在风化之后都没有了,那我们是不是就可以最后再考虑他的变化。而氧化镁,氧化铜….这些含量并不高,而且变化并不大的化学成分,我们也考虑最后去考虑他。
那么就只剩下5个元素来让我们建模预测了,其实这个元素就是两个状态,风化前,风化后,那么我们是不是可以把风化前当x,风化后当y来建立线性回归模型,或者多元回归模型,大家自己企业试试吧,那么这些主要的几个元素的预测就出来了。(把其他属性删除时,先标准化成100%)
剩下的,我们考虑这些元素和其他元素的相关性来进行预测,比如说氧化钠的含量和氧化钾具有正比关系,那么我们就可以得到氧化纳的含量。
铅钡的也类似,大家去自己尝试一下吧。
第二问
依据附件数据分析高钾玻璃、铅钡玻璃的分类规律;对于每个类别选择合适的化学成分对其进行亚类划分,给出具体的划分方法及划分结果,并对分类结果的合理性和敏感性进行分析。
首先,我们也分析一下这些高钾玻璃为什么叫高钾玻璃,为什么叫铅钡玻璃。

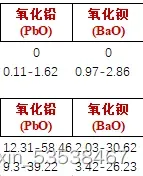
我们只考虑风化前的数据,上面是高钾玻璃,下面是铅钡玻璃。下面是未风化的数据。
我们发现,高钾玻璃的氧化钾含量是铅钡玻璃的好几倍,铅钡玻璃的铅钡的含量亦是如此。
再来了解亚种是什么意思,其实就是在一个种类里面里再来根据他的含量来进一步划分。
一般用来划分的主要有这些方法
- 1.线性判别法
- 2.距离判别法
- 3.贝叶斯分类器
- 4.决策树 decision tree
- 5. Knn算法(k近邻算法)
- 6. 人工神经网络(ANN=Artificial Neural Networks)
- 7.支持向量机 SVM
但是我们都不用,因为我们要模仿这个题目的方法来进行划分。

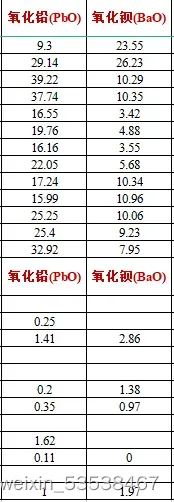
这个是分出来的数据,我们在来直观的看看,是不是其实就是含量(或者含量组合)有较大的数量差距,就能用这个属性划分命名,那么这个数量究竟是多大,怎么来定义,大家就自己想一下了。
举个例子,那么我能在铅钡玻璃分出,富磷玻璃,高钙玻璃。
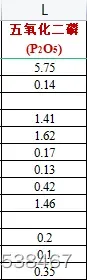
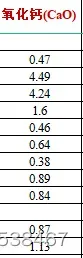
如果你现在还没开始第二问,那就要加油了,按理来说现在第二问至少有思路了。今天不建议熬大夜,明天再直接通宵,哈哈哈.
祝大家比赛顺利!加油!!!
我先睡觉了,明天有空就更新第三第四问。
文章出处登录后可见!