续上篇…
目录
三、计算资源
AlphaGo算法论文虽然已经发表,但从商业角度复制第二个它绝对是亏钱买卖,因为它需要大量服务器和数据中心来支持算法实现。对于大多数AI应用,只要它可以联网,理论上就能使用接近无限的计算资源——把实体资源(如服务器设备、计算节点、存储节点、网络节点等)变成虚拟的资源集合,这些资源可按需使用。此过程经历了两个阶段:数据大集中和资源云化。
1、第一阶段:数据大集中
数据大集中:建设大量的数据中心基础设施,把数据集中起来使用。

数据中心:即Data Center,有时简写为DC,如提供网站发布、虚拟主机和电子商务等互联网服务的数据中心叫作IDC(Internet Data Center)、提供云计算服务的数据中心称作CDC(Cloud Data Center)、其他还有企业数据中心(EDC)、政府数据中心(GDC)等。——无统一定义,但一般来说,广义的数据中心包含三层意思:
①一种物理空间,是企业信息化建设的重要基础设施,为信息系统运行提供了必要的物理场所和配套环境。
②一种逻辑架构,是企业进行数据大集中后形成的IT应用环境,是提供数据计算、处理、存储等IT服务的枢纽。
③一种组织机构,即通过集中的运行、监控、管理等手段,负责信息系统运行和维护的一个组织或团队(负责保证系统稳定性和业务连续性)。
能源消耗:数据中心是巨大的能源消耗体,当前该行业已经达到并超过全球能源消耗的1%,其绿色节能建设方案也被提上议事日程。可利用水能、风能、太阳能等自然资源的给数据中心,以节约能耗!
2、第二阶段:资源云化
资源云化:把计算和存储等资源也集中起来,变成虚拟资源对外提供服务。
2006年,谷歌首次提出“云计算”的概念,它认为手机、电脑这些电子设备对于互联网来说,只是一个附属的设备终端,未来所有的程序和数据都可以存放到网络上,人们不用管理软件升级和安全补丁,也不用担心重要资料丢失。

云通常指两个方面,①服务,即互联网上提供的云端服务,这些服务包括云计算、云存储、云安全等;②技术,即提供云服务的技术平台,这个平台要解决大数据、虚拟化、分布式等问题。云的本质是一个超大规模的分布式系统,将海量计算和存储任务交由位于不同物理地点的大量计算机节点共同解决。
①“云”的分类
几乎所有技术的发展都分成:萌芽创意期——炒作期——幻灭期——复苏期——成熟期。云计算也不例外!
第一种按部署的方式,如私有云、公有云、混合云、社群云、行业云等,对于大多数人来说,纯粹的“云”指的就是公有云。
①私有云:企业自己建设的、供内部使用的云,集中在如金融、医疗、政务等重要服务行业。安全性高、定制化程度高。
②公有云:由云服务商建设和维护的,通过互联网为企业和个人提供服务,在游戏、视频行业用的较多。成本低、无须维护、可无限伸缩、高可靠性。
③混合云:将企业内部的基础架构、私有云与公有云相互结合的云。兼有两者特点,但也导致架构复杂、维护难度大等。
第二种按服务的内容,软件即服务(SaaS)、平台即服务(PaaS)、基础设施即服务(IaaS)。
①IaaS提供硬件设备服务,包括服务器、计算、存储、网络和配套管理工具的虚拟数据中心,通常面向的是企业基础设施运维人员。
②PaaS提供平台服务,如业务软件、中间件、数据库等,面向的是应用程序开发人员。它屏蔽了系统底层复杂的管理操作,使得开发人员可以快速开发高性能、可扩展的程序和服务。
③SaaS提供现成的软件服务,如在线邮件系统、在线存储、在线Office等,面向普通用户。②虚拟化技术
技术角度,云的底层用到的是一种虚拟化技术!
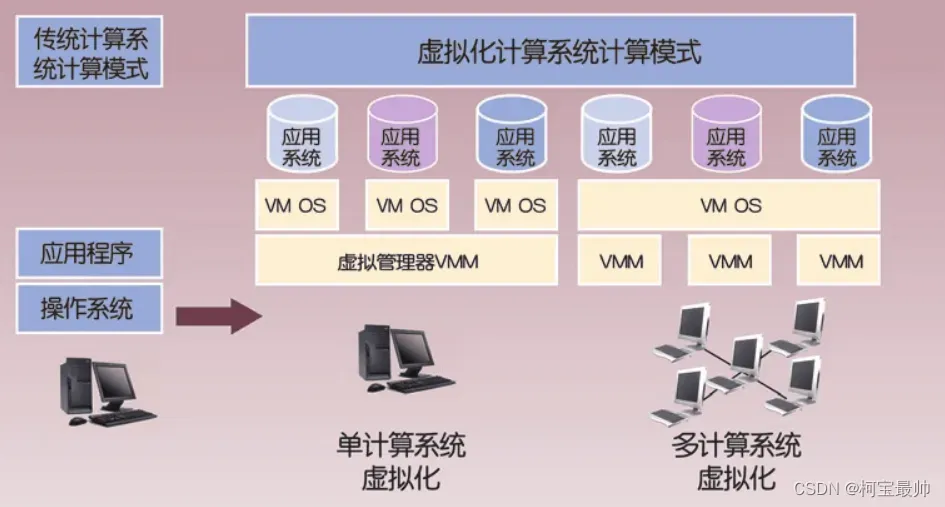
传统意义上的虚拟技术:可以在隔离环境中同时执行一个或多个操作系统,即一台物理设备或服务器上可以运行完全不同的多个操作系统(一台物理设备可分为若干个虚拟机)。后来人们使用比操作系统更小的虚拟化容器提供服务(容器相当于操作系统中运行的软件和组件的虚拟化),比起虚拟化整个操作系统,它提供的服务粒度更精细,每个组件都可单独定制和独立出来,很多AI和云服务都会用到虚拟化技术。
好处:可动态调配资源,让IT资源更好地匹配业务需求。如很多网络游戏刚上线时,很难准确估算要多少台服务器来支撑,此时可根据游戏上线后玩家人数情况,动态调整服务器数量;又比如阿里巴巴会提前增加大量的线上服务器,来保证“双十一”的在线购物、微博通过在线扩容来支撑一些意料之外的热门话题导致的用户激增和活跃度等。
③边缘计算的普及
除了云计算,另一种与AI结合使用的计算技术叫作边缘计算。近年来随着5G等网络通信技术的普及,人们要监测的设备数和要处理的数据量都在大幅增长,传感器、可穿戴设备、专属芯片等硬件开始普及,它们甚至可以植入动植物、人体中,通过这些硬件很多计算任务在本地就可完成,这种计算模式叫作边缘计算。
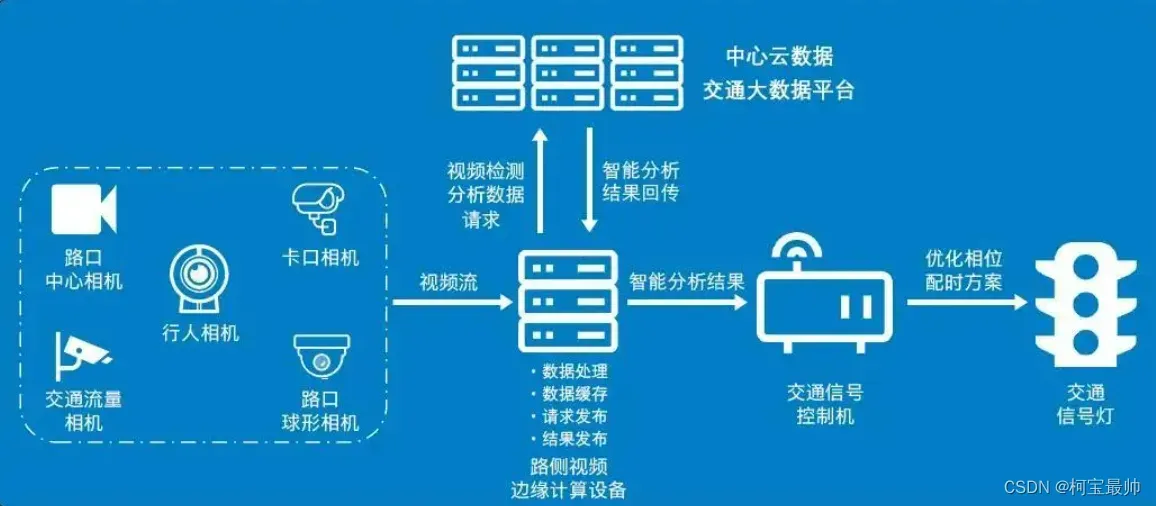
对比:与云计算的模式不同,边缘计算并不需要将数据集中上传到云端处理,而是通过本地设备或附近的基础设施完成部分计算任务,为用户提供更好、更快的服务,降低数据处理和传输的成本——例如无人驾驶汽车行驶过程中,会优先在本地完成对传感器和摄像头数据的计算任务,只有这样才能保证实时感知路况,应对各种突发情况。
边缘计算的节点可在本地筛选数据,只把有价值的数据上传到云端,这样做不仅可在网络中断的情况下持续提供本地业务,也能规避数据隐私泄露的风险。比如小区道路摄像头拍摄的视频数据,通常会现在本地完成监测和分析,再将关键视频片段上传至云端,这样即可保护用户隐私,也可大幅降低网络带宽使用成本。
四、软件代码共享
在聊AI话题时,我们总会谈到数据、算法和提供计算和存储资源的基础设施,这些属于技术上的“明线”,但有一条“暗线”——开源功不可没。它使得大规模技术协作成为可能。

说到开源就不得不提到全球最大的编程社区和代码托管网站——GitHub。GitHub在2008年成立于美国旧金山,它创建了一种全新的开发协助方式,人们可在网站上获得海量免费的代码资源。很多好的AI算法和项目都可在这里找到,如谷歌的TensorFlow、微软的CNTK(Cognitive Toolkit)、Meta的Torch、Caffe、Theano等各种开源深度学习框架。
GitHub核心使用了Git技术,以前的版本控制系统都是运行在集中的版本控制服务器上,
而Git创新地把它变成了分布式。通过GitHub网站,我们只需要从任何公开的代码仓库中
克隆代码到自己账号下,就可以进行开发和编辑。我们也可将修改的代码给原作者发送
一个推送请求,原作者觉得代码改动没问题,就可直接把修改的代码合并到自己的原代码中,
这样实现了集体编程。开源主导了技术生态,例如很多人喜欢使用Python来研究AI算法,这是因为很多实用的深度学习框架和机器学习软件都能基于Python运行,像TensorFlow、Scikit-learn、Keras、Theano、Caffe等,这些开源软件提供了良好的学习环境!
但是也有副作用——有些人喜欢拿来主义,编程不再是从零开始,而是直接从网上整段的复制代码,软件公司开始靠对源码的封装和微调,对外宣称自主研发。
虽然软件开源但是却不是企业的最佳选择,因为开源软件无法保证高可用性和安全性,用于商业风险很大。另外AI有别于其他普通程序,并非只要有了软件代码就能很好运行,还需要依靠海量数据、高性能算力、很多轮的模型训练——因此一些较为成熟的AI不见得会走开源之路,如前段时间很火的自然语言处理模型GPT,GPT-2发布时,OpenAI没有选择公开全部代码,只公开了一部分,它认为GPT-2功能过于强大,完全开源可能存在安全隐患;GPT-3模型发布时,OpenAI选择以API接口的形式邀请测试,也没直接公开代码,目的是防止这一技术的滥用。
总结
虽然计算机每秒已经可执行数十亿次运算,但是仍无法很好满足人类计算的需要!
我们虽能模拟超过千亿级的模型参数,但这与人脑中的神经元相比可能连万分之一都不到!
直到今天,我们还远没具备达到通用AI水平的计算能力,追求高性能的计算能力,认识人类需要努力的方向!

往期精彩:
【AI底层逻辑】——篇章5(下):机器学习算法之聚类&降维&时间序列
【AI底层逻辑】——篇章3(下):信息交换&信息加密解密&信息中的噪声
【AI底层逻辑】——篇章3(上):数据、信息与知识&香农信息论&信息熵
【机器学习】——续上:卷积神经网络(CNN)与参数训练
【AI底层逻辑】——篇章1&2:统计学与概率论&数据“陷阱”
【AI底层逻辑】——篇章5(上):机器学习算法之回归&分类
文章出处登录后可见!