一、立体匹配简介:
双目立体视觉是指使用两个摄像机从不同的角度获取同一个场景的左右视图,然后使用双目立体匹配算法来寻找左右视图中的匹配像素点对,最后利用三角测量原理来还原三维空间物理点过程。其中双目立体匹配算法是最为核心的。
立体匹配是一种根据平面图像来恢复真实场景深度信息的技术,其做法是从两个或多个相同场景的图像中找出匹配点对,然后根据三角测量原理计算点对所对应的空间物理点的深度
二、国内外研究现状
传统的立体匹配算法主要基于人为设计的特征提取算法或者优化函数进行视差的预测,在复杂环境或是不适定区域难以匹配成功。
而基于深度学习的算法,依赖于神经网络强大的特征提取和模型表达能力,能够基于海量的数据集,学习得到更加鲁棒和有效的特征,使得其精度远远超过传统算法。随着近几年可用训练数据集的增加和计算机性能的提升,基于训练学习的深度学习立体匹配方法得到迅速的发展,逐渐成为立体匹配技术研究的主流。
三、传统的立体匹配算法
传统的立体匹配算法将立体匹配分为四个步骤:
- 像素匹配代价计算
- 匹配代价聚合
- 视差计算
- 视差图后处理
同时,根据计算过程中的像素范围,可将立体匹配分为三类:局部立体匹配算法、全局立体匹配算法和半全局立体匹配算法。
3.1传统的立体匹配算法步骤
3.1 像素匹配代价计算
对左眼视图中的像素,需要计算其与右眼视图中可能的匹配像素之间的匹配代价,用来表征两个像素点的匹配程度。匹配代价越大,表示这两个像素的相似性越低,代表同一个实际空间物理点的可能性越小。
3.1.1 像素的灰度值
像素的灰度值是一个像素最基本的信息,所以最简单的方法是使用两个像素的灰度绝对值、灰度差平方值或者使用强度值采样作为两个像素的匹配代价。
但是在一副图像中会存在很多灰度值相同的像素点,仅仅使用单个像素的灰度值无法区分这些像素。此外,由于左右视图拍摄设备的参数、拍摄噪声不完全相同,拍摄时光照条件不同,一个物体在两幅图像中的成像也会显示不同的颜色,所以这类简单方法在很多情况下是无法正确衡量两个像素的不相似程度的,会导致大量的误匹配。
3.1.2 图像上的位置信息
处于图像上的不同位置,其周围的像素集合不同,它们所构成的图像区域结构也就不同。
以一个像素为中心去取一个固定大小的窗口(称为特征窗口),然后把比较两个像素的匹配程度转换为比较两个像素其特征窗口的图像块相似性,这样能更加准确地衡量两个像素在图像上表现出来的差异。这也是目前双目立体匹配中像素匹配代价计算的基本思路。
3.1.3 匹配代价的方法
归一化互相关方法(Normalized cross correlation,简记为 NCC 算法)计算两个图像块之间的互相关性来代替像素的匹配代价,它对局部的灰度值线性变化具有不变性,抗噪声干扰能力较强,但容易受局部光照变化的影响,且匹配速度较慢;
基于互信息的代价计算方法(Mutual information-based,简记为 MI 算法)利用图像灰度值概率分布的信息去计算匹配代价,可以在一定程度上应对噪声干扰和辐射畸变的影响,但是它在无纹理区域和物体边界处的匹配效果差。其它还有很多关于 NCC 和 MI 算法的后续改进工作,在一定程度上使得这类方法可以有更大的适用范围。
基于转换的方法; 这类方法从局部像素灰度值的相对顺序不变的假设出发,认为即使是在光照变化强烈的情况下,单个像素的灰度值会发生变化,但该像素与周围像素的灰度值的大小关系是不变的。所以可以比较图像块内 各个像素灰度值的大小关系,把比较结果作为代表该图像块结构信息的特征,然后把比较两个像素的匹配程度转换为比较两个像素特征的相似性。
这类方法的代表算法有 CENSUS 算法、LBP 算法(Local binary pattern)、SLBP 算法(Support local binary pattern)、FEP算法(Fuzzy encoding pattern)、RSRT 算法(Robust soft rank transformations)、ADCENSUS 算法(Absolute difference and CENSUS),等等。长期的实践证明,这类算法在立体匹配中表现出的匹配效果优异,稳定性高。
3.2 匹配代价聚合
图像上的像素通常与其周围的像素形成一个整体,如都是表示同一个物体,或者表示同一个物体的某部分,这个联系(匹配代价聚合 )使得一个像素会和周围的部分像素有着接近的匹配情况。从另外一个方面讲,一个像素的匹配需要受周围其它像素匹配情况的约束,不能孤立地考虑单个像素的匹配情况。
局部立体匹配方法在考虑一个像素的匹配情况时,只考虑“该像素”周围一个小区域内其它像素的匹配情况。
对于左右视图中两个像素,通常会分别以这两个像素为中心取相同大小的窗口(称为聚合窗口),然后逐个计算两个窗口内处于相同位置的像素之间的匹配代价,并把这些匹配代价值累加起来作为最终的聚合匹配代价。如果聚合代价越小,则两个像素越有可能是匹配的。
左右视图中的两个像素取形状大小相同的聚合窗口,这种做法默认假设了处于聚合窗口内的像素具有相同的视差值,即它们在实际空间中距离相机的距离相同。但是,实际情况中小窗口内的像素不一定具有相同的视差,所以关于代价聚合步骤,研究的主要工作在于如何选择合适的窗口进行聚合。
有一部分论文致力于找到与中心像素具有相同视差的像素:离中心像素较近的区域内,如果一个像素的灰度值与中心像素的灰度值相近,便认为该像素与中心像素的视差相同,在聚合时也只累加上这部分具有相同视差的像素的匹配代价;
另外一部分论文无论对待什么情况,都选取一个固定大小的矩形聚合窗口,只是在对窗口内各个像素的匹配代价进行累加时都附加上一个权重,该权重表示该像素与中心像素具有相同视差的可能性大小。如对聚合窗口施加一个高斯滤波权重后进行聚合、对聚合窗口进行引导滤波聚合、把聚合窗口拓展到整幅图像后加权聚合;还有一部分论文认为左边视图中的区域映射到右边视图时,需要先找到该区域所在真实三维空间中的平面法向量,再根据平面法向量进行映射。
3.3 视差计算
视差计算是在计算出聚合匹配代价之后,寻找到各个像素最优匹配点,完成匹配任务。局部立体匹配算法中的视差计算一般比较简单,采用 WTA 胜者为王理论(Winner-Take-All)直接进行视差寻找。
具体方法为:对于左边图中的一个像素,它在右图中有多个可能的匹配像素,逐个比较这些可能匹配像素与当前待匹配像素的聚合代价,其中有着最小匹配代价的像素即为寻找到的匹配像素。
这一步骤的相关研究不多,比较出名的是 Patch Match 算法针对视差搜索效率进行的方法改进,其根据图像的连续性原理,用随机搜索的方法大大缩小了可能匹配像素的集合,极大提高了视差计算的效率。
3.4 视差图后处理
视差图后处理是在初步得到视差图之后,对视差图的结果进行判断,发现可能的匹配错误情况并进行改正。
常用的后处理方法:左右一致性检测、遮挡填补、加权中值滤波。
左右一致性检测
用于发现错误匹配情况,它的原理是:左边视图中的某个像素p ,其找到的匹配像素为右边视图中的像素 q ,则反过来像素 q 找到的匹配像素也应该为 p ,如果不是则视为错误匹配。
遮挡填补
认为错误的匹配点是该像素在另外一个视图中被遮挡住的原因,所以该像素应该与邻近的背景像素具有相同的视差值。
中值滤波
是为了解决遮挡填补后产生的横向条纹问题,对填补像素的视差进行中值滤波。
3.2传统匹配算法分类
3.2.1局部匹配算法
局部算法通常仅关注局部区域,大多具有较低的计算复杂度和较快的运行速度。与全局算法相比,局部算法准确性较差,尤其是在重复纹理、视差不连续或遮挡等区域。
该方法假设两幅图像中匹配像素点的强度相似,并且相邻像素点的视差类似。对于左图中的一个像素点,找到右图中候选视差为d的像素,分别构造以这两点为中心的窗口,并计算两个窗口内的匹配成本。之后对于成本进行聚合,采用WTA获得预测的视差值。这些方法实现简单,但是缺乏鲁棒性。后续研究者又提出了census变换[47]或采用不同尺度的匹配特征I48]来增强特征的表达能力。
3.2.2全局匹配算法
全局匹配算法主要采用全局优化的理论,通过构建包括数据项和平滑项的全局能量函数来估计视差[49],可以更好地解决在重复纹理、遮挡情况下的匹配问题。
动态规划方法(Dynamic Programming, DP)在左右图像的对应扫描线中搜索最小匹配代价路径,可以快速地实现全局最优,如图1.4(a)所示。图割法(Graph Cuts,GC)通过最大流最小割的方式求解全局能量函数。置信传播算法(Belief Propagation,BP)构造消息传递的迭代网络,将像素作为传输节点,在四邻域上进行搜索。全局匹配算法具有较高的精度,但是由于是对整个图像进行搜索,耗时较长。
3.3.3半全局匹配算法
半全局匹配算法(Semi-Global Matching, SGM)平衡了准确性和时间复杂度之间的关系,精度比局部算法高,速度比全局算法更快。Hirschmuller首先提出了半全局匹配算法,采用互信息计算像素的匹配代价,并按照动态规划的思想,在多个不同方向的一维路径上寻找局部最优,最后聚合所有方向的能量函数得到最优的结果,如图1.4(b)所示。
传统的算法虽然在实际的复杂场景中无法获得高精度的视差结果,但是该类算法相比深度学习下的算法,不依赖于真值和大量的计算资源,并且整个算法流程具备可解释性,在实际的应用中仍然具有一定的优势。
四、深度学习立体匹配算法
4.1半传统半深度学习的立体匹配算法
由于卷积神经网络在计算机视觉领域强大的特征提取和学习能力,研究者们逐渐使用CNN来解决立体匹配问题。在引入深度学习的早期阶段,大部分算法使用CNN替代1.2.1所述四个步骤中的部分步骤,并且大多仅关注匹配成本计算过程,使用网络学习的方式替代人工设计的特征表达。相比传统算法,该类方式在精度上获得了较大提升,也为后续完全采用CNN的端到端立体匹配网络奠定了基础。
Zbontar和 LeCun[4-55]采用权值共享的孪生网络来学习左右图像块的特征描述,然后将这两个特征级联后输入全连接网络中计算相似性分数,如图1.5所示。后续则采用传统的交叉代价聚合[56]、半全局匹配[53]、左右一致性校验等方法得到视差结果。Chen等人[57]设计不同尺度的卷积层提取特征,以此来构建多种尺度信息融合的匹配代价。Shaked和 Wolf58]提出了由多级残差网络和全局视差网络构成的立体匹配算法,前者用于在每个候选视差上计算匹配成本,后者用于从匹配成本体中获得视差,以此来替代赢者通吃策略。
该类算法作为传统算法与深度学习算法的过渡,目前使用较少。它相比传统算法能提升部分精度,但是由于网络无法进行统一训练,整体性能仍有较大的改善空间。除此之外,该类算法仍然可能保有传统算法的优势,比如计算资源要求低、可解释性较强等。
4.2端到端的深度学习立体匹配
半传统半深度学习的算法,大多仅利用神经网络在特征提取方面的优势,导致其改进性能有限。相比之下,端到端训练的深度学习方法能够直接生成最终的视差,减少了人工干预,更好地利用了网络强大的学习能力。该类方法可以大致分为五个步骤:
特征提取、成本体构建、成本聚合、视差估计和损失计算。
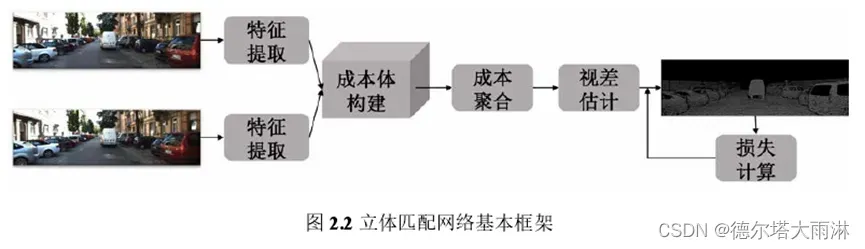
2.2.1 特征提取
立体匹配网络主要基于权值共享的孪生网络来获得左右图像的特征。孪生网络一般可采用现有的经典全卷积结构,比如 VGG]、ResNet7]等。在此基础之上,为了获得更健壮、更加丰富的上下文信息,可以采用空洞卷积(Dilated Convolution)21.66]、特征金字塔网络(Feature Pyramid Network,FPN)15]、空间金字塔池化(Spatial Pyramid Pooling,SPP)[65,98]等结构,如图2.3所示。对于轻量级的网络,可以采用深度可分离卷积P9-100]、构建低分辨率的特征进行后续操作[66]等。
2.2.2成本体构建
提取了左右图像的特征之后,需要构建成本体。它的基本思路是,在设定好的候选视差范围内,计算左右图像中对应点的相似度。后续基于相似度的大小,可以确定左右图像中正确的像素匹配关系。
成本体构建主要有三种方式,基于相关层[59]和基于3D成本体的方法[64],或者两者的结合[67]。
基于相关层的方法,直接计算左特征和在某个候选视差d下的右特征的相似度,最终可以得到HxWxD的成本体,其中H、W、D分别代表长、宽和最大的候选视差,如式(2-5)所示:
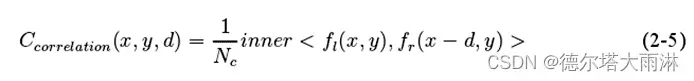
(2-5)
其中inner 代表点积操作,f和f是左右图像的特征,N。是特征通道数,(z, y)和d是像素坐标及对应的视差值。
该方法占用内存小、速度快,但是它直接保存了点积结果,丢失了太多信息,导致最终的性能并不理想。
基于3D成本体的方法,直接级联不同候选视差下的左右特征,构建了大小为HxWxDxC的成本体,如式(2-6)所示:
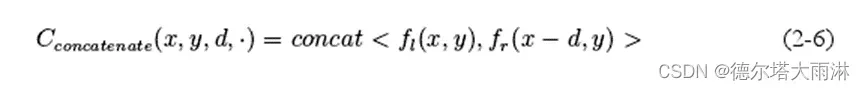
(2-6)
其中 concat表示级联操作。
该方法要求更大的内存,速度相对较慢,但是它保留了完整的信息,性能更为优异。GwcNetl67将上述两种成本体进行结合,它包含两个部分,一个是基于级联的3D成本体,采用两个卷积将其压缩为12个通道,另一个通过分组相关层(Group-Wise Cor-relation, GWC)进行构建。分组相关的方式是将特征按照通道分成N,个组,每个组的通道数为N。/Ng,然后计算左右图像每组特征的相关性,如式(2-7)所示:
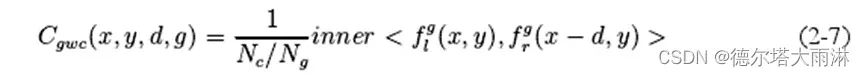
(2-7)
与基于3D成本体的方式相比,该方法在减少参数的同时,不会损失过多的信息。
2.2.3成本聚合
在成本聚合阶段,主要针对初始的成本体在不同的维度上进行成本的优化,以增加成本体的可靠性。深度学习下的算法,主要根据成本体构建方式的不同,相应地采用2D或是3D卷积的方式。
基于相关层的方法,后续采用2D卷积在空间维度上对邻域范围内的信息进行聚合,速度较快。
基于3D成本体的方法,后续采用3D卷积在空间和视差维度上聚合信息,且可以保留每个候选视差明确的成本值,但速度较慢。PSMNet[6习中使用堆叠的沙漏结构对成本体进行聚合,该结构对特征进行重复的下采样和上采样操作,以学习更多的上下文。为了提高速度,也可以对3D成本体进行特征压缩94],或者采用低分辨率成本体计算初始视差,然后在高分辨率特征上计算残差85-8刀等方式。
2.2.4视差估计
图2.4中展示了两种视差预测的方法,分别是argmin和soft argmin操作。
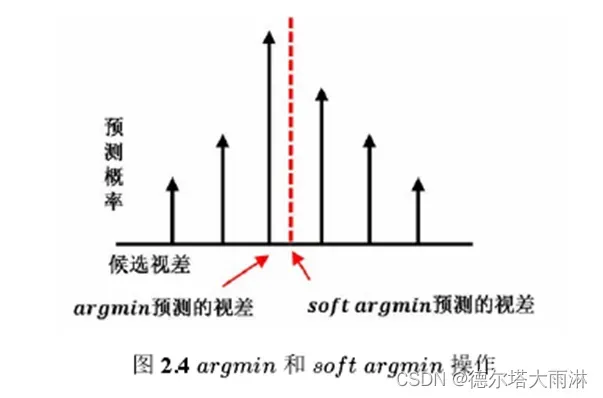
传统的方法采用嬴者通吃的策略,即 argmin操作,在所有候选视差中选择成本值最小,或概率值最大的候选视差作为最终的视差值,如式(2-8)所示。

(2-8)
其中à是预测视差,C(z, y, d)是最终的成本体,d是候选视差。
但是这种argmin的方式,在深度学习中无法有效计算梯度,也不能获得亚像素的精度。
所以,主流的方式采用sof t argmin算法[6],首先对于成本体应用softmar操作,获得O~1范围内的概率值。然后,计算所有候选视差与其对应概率的加权求和结果,作为最终的视差值,如式(2-9)和式(2-10)所示。
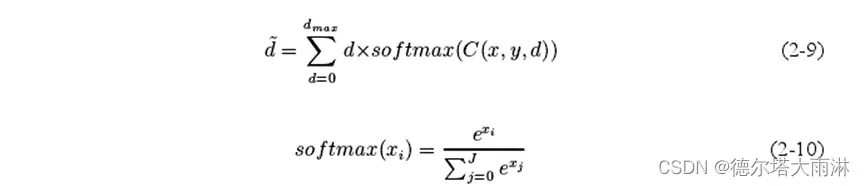
(2-10)
其中 dmax是设定好的最大搜索视差值。
该种方式能够进行梯度传播,而且可以获得亚像素的精度。但是只有当该视差概率分布满足单峰分布时,soft argmin的结果才会与argmin类似。否则,当概率分布为多峰等情况时,最终结果会远离所有峰值,并导致较大的误差,这在边界处尤为明显。
2.2.5损失计算
对于有监督的立体匹配算法来说,损失阶段主要采用基于视差的smooth L损失55],它结合了L和Ln损失的优点。在误差小于1的时候采用L2损失,使得原点处损失可微;在误差大于1的时候采用L损失,它能够处理异常值,并对外点不敏感。公式如下:
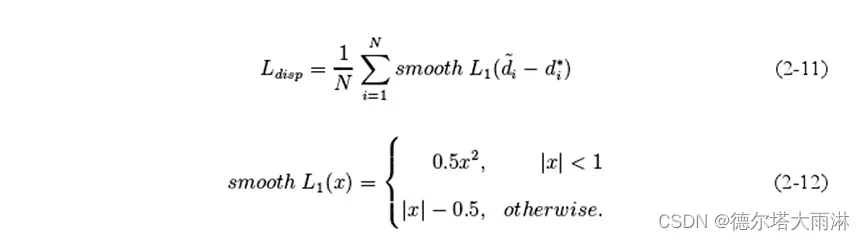
(2-12)
其中N表示有效像素的数量,i和分别代表像素点i的预测视差和真值视差,|·|是取绝对值操作。
在某些特定场景中,如果有足够的数据集进行训练学习得到一个可用模型,则深度学习立体匹配方法后续在相似场景中进行立体匹配工作时,通常可以取得优于传统立体匹配方法的效果,这是因为神经网络可以从数据中学习到更为细致的匹配规则,一些人为指引所不能体现的规则。
但是训练好的模型用于一个新场景时,如果没有足够多关于新场景的数据让其进行参数调整,则该网络匹配正确率将大大下降。这是目前众多深度学习立体匹配方法表现出来的通病,对训练数据有极大的依赖性,泛化性差。
文章出处登录后可见!