自监督表征学习方法——DINO方法
参考文献:《Emerging Properties in Self-Supervised Vision Transformers》
DINO全称——a form of knowledge distillation with no labels.(一种没有标签的知识蒸馏的形式)

如上图所示:来自没有监督训练的8×8补丁的视觉变压器的自我注意。我们观察最后一层头部的[CLS]令牌的自我关注。此令牌不附属于任何标签或监管机构。这些地图显示,该模型自动学习类特定的特征,从而实现无监督的对象分割。
1.摘要
在本文中,我们质疑自监督学习是否为Vision Transformer (ViT)提供了新的特性,与卷积网络相比脱颖而出。除了将自我监督方法适应这种架构特别有效之外,我们还做了以下观察:首先,自我监督ViT特征包含关于图像语义分割的显式信息,这在监督ViT和卷积网络中都不明显。其次,这些特征也是优秀的k-NN分类器,在ImageNet上达到了78.3%的前1名。我们的研究还强调了动量编码器、多作物训练和使用带有vit的小贴片的重要性。我们将我们的发现实现到一个简单的自我监督的方法中,称为DINO,我们将其解释为一种没有标签的自蒸馏形式。
个人总结:
①提出了新的自监督学习方法DINO;
②自监督学习相比于有监督学习,可以获取更加有用的信息。这里主要针对图像分割吧。
③Vision Transformer比卷积网络获得更多有用的语义信息。
2.DINO方法介绍
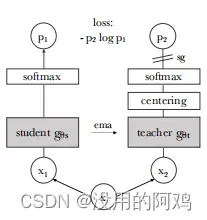
如上图所示, 无标签的自蒸馏。
为了简单起见,我们在一对视图(,
)的情况下说明DINO。
①该模型将输入图像的两种不同的随机变换传递给学生和教师网络。这两种网络具有相同的架构,但参数不同。教师网络的输出以批量计算的平均值为中心。
②每个网络输出一个K维特征,该特征在特征维度上用一个温度softmax进行归一化。
③然后用交叉熵损失来测量它们的相似性。
④我们在教师上应用一个停止梯度(sg)算子,只通过学生传播梯度。教师参数用学生参数的指数移动平均数(ema)进行更新。
DINO算法伪代码

DINO详细介绍:
知识蒸馏是一种学习范式,我们训练学生网络匹配给定教师网络
的输出,分别由
和
参数化。给定一个输入图像
,两个网络在
维上的概率分布,用
和
表示。概率P是通过用softmax函数将网络
的输出归一化得到的。更准确地说,
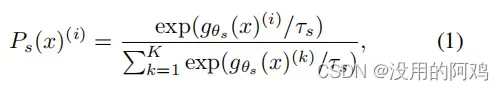
其中,是温度参数。
给定一个固定的教师网络,我们学习通过最小化交叉熵损失w.r.t.来匹配这些分布学生网络
的参数:
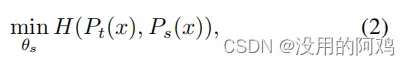
其中。
在下面,我们将详细介绍我们如何在等式中适应这个问题(2)来进行自我监督学习。首先,我们用多棒策略构建一个图像的不同扭曲视图或作物。更准确地说,从给定的图像,我们生成一个集合V,这个集合包含两个全局视图,和
,以及几个分辨率较小的局部视图。所有的作物都通过学生传递,而只有全球的观点通过老师传递,因此鼓励“本地到全球”的通信。我们最大限度地减少损失:
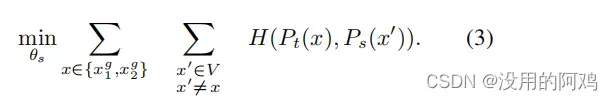
这两个网络共享相同的架构,具有不同的参数集
和
。我们通过最小化等式(3)来学习参数
具有随机梯度下降的方法。
特别有趣的是,在学生权重上使用指数移动平均线(EMA),即动量编码器,特别适合我们的框架。更新规则是,在训练期间,λ遵循从0.996到1的余弦时间表。
防止崩溃。居中防止了一个维度的主导地位,但鼓励崩溃到均匀分布,而锐化则有相反的效果。应用这两种操作可以平衡它们的效果,这足以避免在动量老师面前的崩溃。选择这种方法以避免崩溃,可以交换稳定性来减少对批次的依赖:定心操作只依赖于一阶批统计,可以解释为向老师添加一个偏差项:
。中心
以指数移动平均线进行更新,这允许该方法在不同的批处理大小中很好地工作,如下所示:
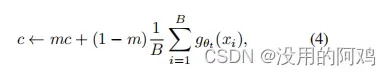
其中,m > 0是一个速率参数,B是批处理大小。输出锐化是通过在教师软最大归一化中使用温度的低值来获得的。
3.实验结果
表1:在ImageNet上的线性和k-NN分类。我们报告了对于不同的自监督方法,在ImageNet验证集上的线性和k-NN评估的前1个精度。我们关注ResNet-50和vit-小型架构,但也报告了跨架构获得的最佳结果。∗是由我们经营的。我们对具有官方发布权重的模型进行了k-NN评估。吞吐量(im/s)是在NVIDIA V100 GPU上计算的,每个前进128个样本。参数(M)为特征提取器。
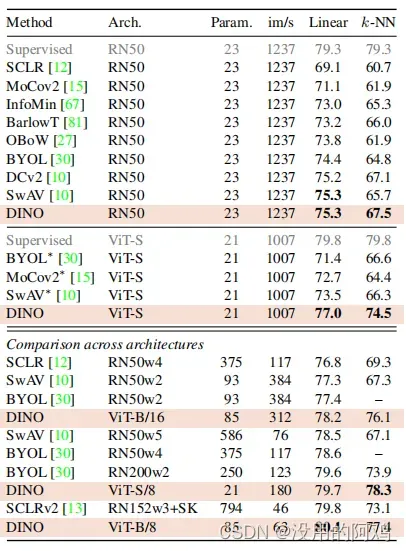
表2:图像检索。我们比较了在ImageNet和谷歌地标v2(GLDv2)数据集上使用监督或DINO预训练的现成特征的检索性能。我们报道了关于牛津和巴黎的地图。在地标数据集上使用DINO进行预训练表现得特别好。作为参考,我们还报告了具有现成的功能[57]的最佳检索方法。
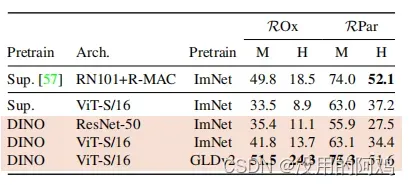
表3:拷贝检测。我们报告了在复制日“强”子集[21]上的复制检测中的mAP性能。作为参考,我们还报告了多层模型[5]的性能,专门为特定的对象检索进行训练。
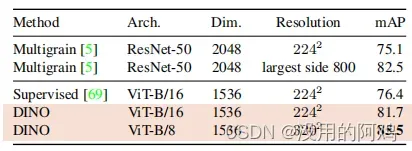
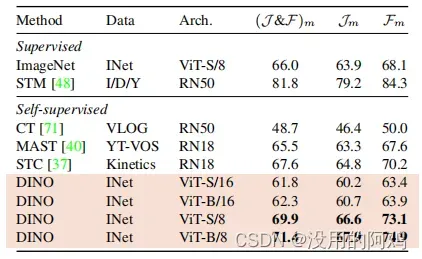
表4: DAVIS 2017视频对象分割。我们在视频实例跟踪中评估了冻结特征的质量。我们报告了平均区域相似度Jm和基于轮廓的精度Fm。我们比较了现有的自监督方法和在ImageNet上训练的监督ViT-S/8。图像分辨率为480p。

上图:从监督和DINO的分割。我们可视化了通过阈值化自注意图获得的面具,以保持60%的质量。在上面,我们展示了经过监督和DINO训练的ViT-S/8的结果口罩。我们展示了两种模型最好的头部。底部的表格比较了在PASCAL VOC12数据集的验证图像上的地面真相和这些掩模之间的Jaccard相似性。
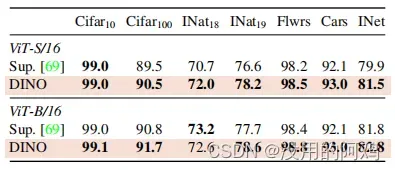
表5:通过微调不同数据集上的预训练模型进行迁移学习。我们报告了前1的准确性。DINO的自我监督预训练比监督预训练更好。
4.结论
在这项工作中,我们展示了自监督预训练一个标准ViT模型的潜力,实现的性能是与为此设置设计的最佳凸网相媲美的。我们还看到了两个可以在未来应用中利用的特性:k-NN分类中特征的质量具有图像检索的潜力,其中ViT已经显示出了有希望的结果。特征中场景布局信息的存在也有利于弱监督图像分割。然而,本文的主要结果是,我们有证据表明,自我监督学习可能是开发一个基于的bert样模型的关键ViT。在未来,我们计划探索在随机未管理的图像上使用DINO对大型ViT模型进行预训练是否能够突破视觉特征的极限。
个人疑问:
①会不会训练太久了
②配置好像好太高了,两台8GPU电脑
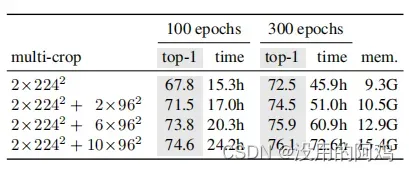
表8:时间和内存要求。我们显示了每个GPU的总运行时间和峰值内存(“mem.”)。当在两台8-GPU机器上运行ViT-S/16 DINO型号时。我们报告了前1ImageNetvalacc对多作物的线性评估,每个都有不同的计算需求。
文章出处登录后可见!