《Small object detection in remote sensing images based on attention mechanism and multi-scale feature fusion》《CotYOLO-v3》
ABSTRACT
由于检测目标分布密集、背景复杂等因素的影响,遥感图像中小目标较多,难以检测。为了解决遥感图像中小物体检测的难题,本文提出了一种名为 CotYOLO-v3 的目标检测算法。首先,我们重新设计了主干 Darknet-53 中的残差块,将其替换为主干 Darknet-53 中具有上下文信息的 Contextual Transformer (Cot) 块,以提取小目标的上下文信息并增强视觉表示;其次,我们在YOLO-v3的特征融合之前引入了带有注意力机制的浅层信息,以减少背景干扰因素的影响,提高网络的表达能力。然后,我们优化了特征融合过程,将上采样方法替换为亚像素卷积,并 将预测分支的第一个卷积层 替换为残差块。最后,我们使用 K-Medians 聚类算法重新生成适合遥感图像数据集的锚点。在本文中,我们建立了 CotYOLO-v3 和 常用目标检测算法的对比实验来检测 DIOR 数据集中的小目标。实验结果表明,与其他常用的目标检测算法相比,CotYOLOv3 目标检测算法在检测遥感图像中的小目标方面具有明显优势。与原有的目标检测算法YOLO-v3相比,CotYOLO-v3的平均精度(mAP)提高了5.07%。
1. Introduction
近年来,遥感中的目标检测算法层出不穷,基于深度学习的目标检测算法在遥感图像中的应用越来越广泛。目前常用的基于深度学习的目标检测算法大致可以分为两类:基于区域生成的两阶段目标检测算法 和 基于回归的单阶段目标检测算法。 R-CNN (Girshick et al 2013; Girshick 2015; Dai et al 2016; Ren et al 2017) 系列目标检测算法是基于区域生成的两阶段目标检测算法的代表。特定模块生成候选框并提取生成的候选框的特征。并进行进一步的调整和细化以完成分类和回归任务。这类算法虽然检测精度高,但检测速度很慢。不适合实时检测,不能满足检测任务的要求。基于回归的单阶段检测算法以SSD (Liu et al 2016) 系列和YOLO (Redmon et al 2016; Redmon and Farhadi 2017, 2018)系列为代表,它们直接对原始图像生成的特征图进行分类和回归。该类算法虽然检测速度快,可用于实时检测,但检测精度有所下降。
为了解决遥感图像中小物体检测精度低的问题,有很多创新。近年来,随着深度学习技术的不断发展,提高遥感图像中 小目标检测精度的方法越来越多。 (Kisantal et al 2019) 提出了一种用于 复制粘贴小目标 的数据增强算法。 (Peng, Hong, and Deng 2018) 使用 递归卷积神经网络 (RCNN) 从整个源图像中提取全局深度特征和上下文信息。 (Li et al 2017) 使用生成对抗网络 (GAN) (Goodfellow et al 2014) 生成高分辨率特征。它使用低分辨率特征作为 GAN 的输入,通过缩小小目标和大目标之间的表示差异来改进小目标检测。 (Deng et al 2020) 提出了 扩展特征金字塔网络 (EFPN),它 具有专用于小目标检测的超高分辨率金字塔层级。 (Fu et al 2017) 使用反卷积代替传统的双线性插值进行上采样。在预测阶段,它引入了 残差块 和 候选框的优化回归以及分类任务的输入特征图。与SSD相比,大大提高了小目标的检测精度。
YOLO-v3 是一种常用的单阶段目标检测算法。它集成了残差网络和特征金字塔网络 (FPN) (Lin et al 2017),并使用大量残差块构建主干网 Darknet-53。同时,在下采样过程中,使用stride = 2的卷积对尺寸为416×416的输入图像进行下采样。最后,YOLO-v3输出三个预测层(13×13,26×26,52× 52) 通过使用 FPN 融合深浅特征来检测不同大小的物体。
YOLO-v3目标检测算法虽然较之前的目标检测算法有一定的改进和提升,但在遥感图像的小目标检测领域仍然无法获得非常准确的检测结果。主要原因是 遥感图像中的小物体分辨率低,通常只有几十个像素或更少。低分辨率增加了目标检测算法的特征提取难度,导致小目标检测漏检率和误检率高。针对遥感图像中的小目标检测问题,我们提出了 一种 基于CotYOLO-v3的小目标检测算法。它 通过 挖掘小目标的上下文信息,融合更多的浅层特征信息,提高了小目标的检测能力。此外,我们还做了其他尝试来提高小目标检测的准确性。
2. 我们的方法
本节将详细介绍本文提出的基于CotYOLO-v3的小目标检测算法。网络结构如图 1 所示。首先,我们通过 引入更注重上下文信息的 Cot (Yehao et al 2021) 模块构建主干 CotDarknet-53。其次,为了充分利用浅层特征信息,我们加入了backbone 4倍下采样的特征进行特征融合。最后,我们在backbone的16次下采样、8次下采样和4次下采样之后 引入注意力机制模块SE。他们可以去掉背景等分散注意力的特征。此外,我们使用改进的 K-Medians 聚类算法重新生成适用于遥感图像数据集小目标的锚框。我们将特征金字塔网络中的上采样方法 替换为 亚像素卷积 而不是最近邻插值,并 将预测层中的第一个卷积块替换为残差块。这些改进 提高了遥感图像中小目标的检测精度。与YOLO-v3相比,CotYOLO-v3的mAP提升了5.07%。
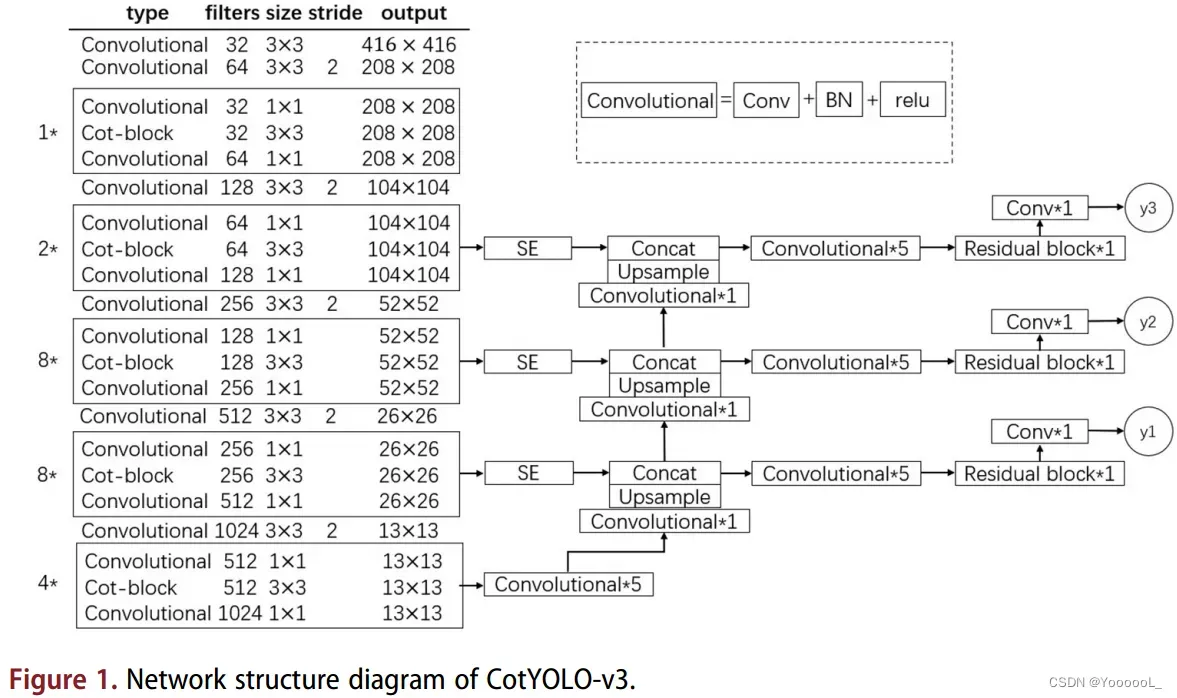
2.1. Backbone CotDarknet-53
遥感图像中的小目标具有分辨率低、分布密集的特点,这使得遥感图像中的小目标检测变得非常困难。目前流行的小目标检测方法是 提取小目标附近的上下文信息 来帮助检测小目标。在本文中,我们通过将 Transformer 风格的 cot 模块引入 YOLO-v3 的主干 Darknet-53 来构建 CotDarknet-53。我们 使用主干 CotDarknet-53 提取小目标附近的上下文信息,以帮助检测小目标。 Cot模块充分利用 输入keys之间的上下文信息 来指导动态注意力矩阵的学习。关键点之间的特征图的上下文挖掘 和 自注意力学习 统一在具有良好参数预算的体系结构中。因此,Cot 模块增强了视觉表示能力。 Cot 模块如图 2 所示。
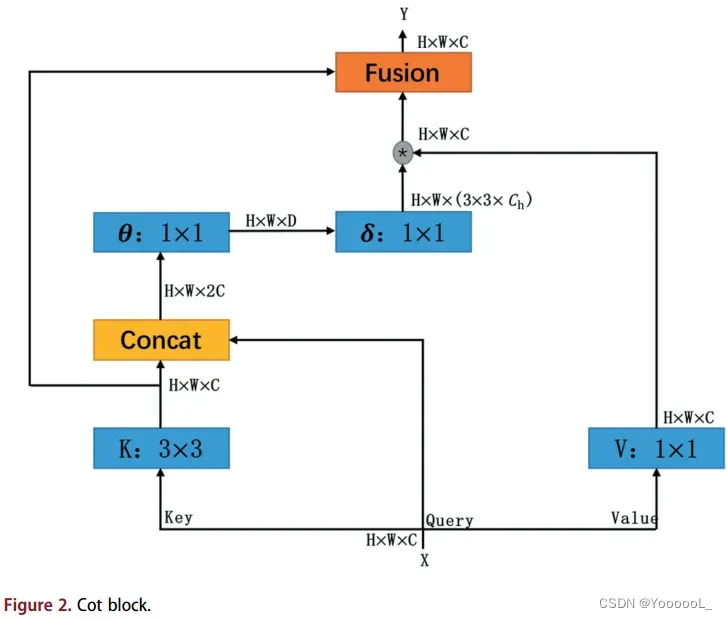
我们 将大小为 H×W×C 的输入 X 分别转换为 Query (Q)、Key (K) 和 Value (V)。首先,cot 模块通过 3×3 卷积对 输入key 进行上下文编码,生成输入的静态上下文 K1。其次,基于输入Query 和 经过上下文处理的输入Key,我们在静态上下文的引导下,使用两个连续的1×1卷积来学习注意力矩阵A。最后,将学习到的注意力矩阵乘以输入Value,实现输入的动态上下文K2。对应的计算公式如下:
![]()
![]()
上式中,☉表示局部矩阵乘法。 Wθ; Wδ分别表示 带sigmoid激活函数的 1×1卷积 和 不带激活函数的1×1卷积。我们 将静态和动态上下文融合在一起作为 Cot 模块的输出 Y。通过获取输入key的静态和动态上下文,增强了目标检测算法检测小目标的能力。
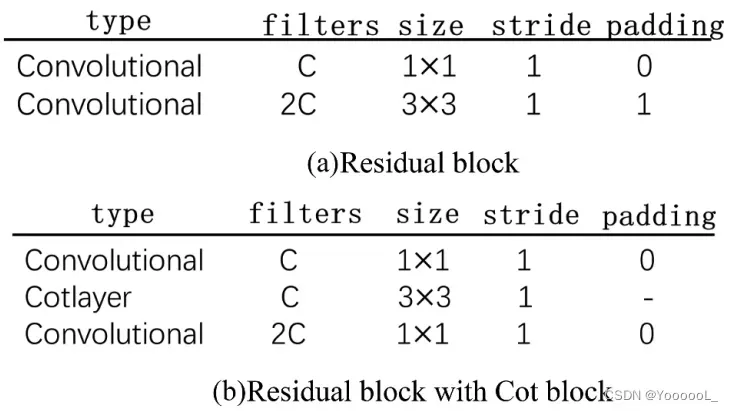
YOLO-v3 使用主干网 Darknet-53 从输入图像中提取特征。 YOLO-v3对尺寸为416×416的输入图像进行下采样,压缩图像的宽高,增加通道数,得到一系列特征层来表示输入图像的特征。 Darknet-53 由一系列卷积层和残差块组成 (Guo Zhichao et al 2021)。卷积层的卷积核为3×3,每个残差块由一个1×1的卷积核和一个3×3的卷积核组成,用于提取图像特征。为了提高小目标检测的性能,我们改进了Darknet-53中的所有残差块,将残差块中的3×3卷积核的卷积替换为Cot模块。并在Cot模块后加入一个1×1的卷积来改变通道数。主干网Darknet-53和改进后的主干网CotDarknet-53中残差块的比较如图3所示。
2.2. SE模块引入浅层信息
Backbone Darknet-53进行五次下采样,网络层数由浅到深。深层网络 具有很强的语义特征,浅层网络 具有更高的分辨率。 YOLO-v3以FPN为参考,结合了 深层网络的强语义特征 和 浅层网络的高分辨率,充分利用了从backbone中提取的浅层和深层特征。并且可以大大提高检测效果(Fang and Zhaokui 2019)。在小目标检测任务中,下采样是致命的。它失去了目标的特征,并且在多次采样时很难重建小目标(Kun and Wei 2022)。因此,下采样倍数小的浅层特征感受野小,分辨率高,适合处理小目标。 YOLO-v3 对 32倍下采样、16倍下采样 和 8倍下采样的特征进行特征融合。为了充分利用浅层网络更高分辨率和更小的特征感受野,我们在特征融合中加入了4倍下采样的特征。并且可以实现对小目标更准确的检测。
为了关注小目标,我们尽早使用注意力机制,这有助于减少背景中不必要的浅层特征信息(Lim et al 2019)。在本文中,我们在四次下采样得到的特征后,将 注意力机制SE模块 引入到特征提取网络中。它可以确保 在特征融合之前 过滤掉背景等不必要特征信息的干扰。同时,我们还将经过 16次下采样 和 8次下采样 特征后的 SE模块引入到特征提取网络中。通过这种方式,网络可以自动学习不同通道特征的重要性,更加关注通道之间的关系。 SE 模块如图 4 所示。
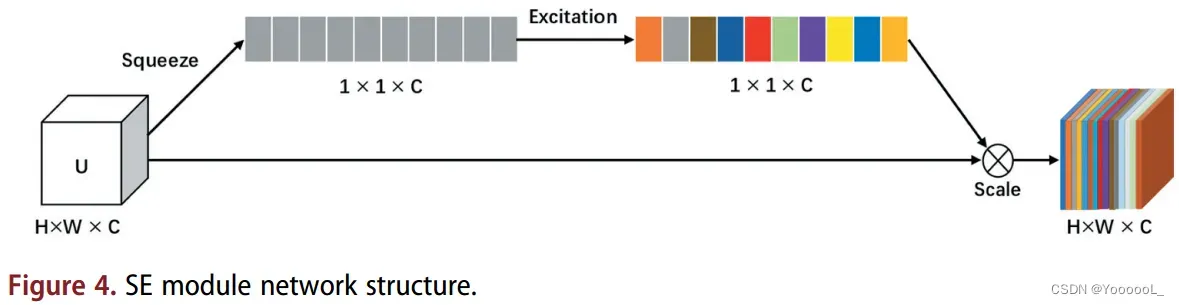
SE 模块 包括 Squeeze 操作 和 Excitation 操作,它们通过对通道的卷积特征之间的相互依赖性进行显式建模来提高网络的表现力 (Jie et al 2017)。首先,SE 模块从输入 U 中压缩特征,该操作使用空间维度 H×W 生成通道特征。其次,我们进行激励操作 以了解每个通道之间的连接。最后,将结果乘以输入字符 U 以产生 SE 模块的输出。相应的计算公式如下:
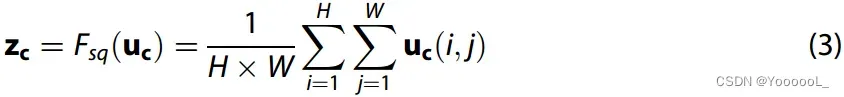
![]()
![]()
上式中,Fsq是Squeeze操作,uc代表来自输入U的特征,Fex是Excitation操作,δ代表ReLU激活函数,Fscale 表示通过 Squeeze 和 Excitation 操作学习的每个通道的激活值乘以输入 U 的特征。 表示输出来自 Squeeze 和 Excitation 操作乘以输入 U。
我们总结了本节中介绍的主要工作。首先,CotYOLO-v3 通过 backbone CotDarknet53 得到三种不同特征尺度下采样后的特征信息(104×104,52×52,26×26)。其次,我们 使用 注意力机制SE模块 来去除背景信息的干扰。最后,在SE模块的输出结果和上采样后的上一层特征信息之间进行 Concat 操作。通过这些操作,我们完成了深层特征和浅层特征的融合。
2.3. anchor boxes聚类方法的优化
K-means 是一种基于分区的聚类方法,通常用于寻找锚的最佳数量和大小 (Wendong et al 2021)。 YOLO-v3 使用 K-means (Coates and Ng 2012) 聚类算法生成 9 种不同大小的锚点。 K-means算法通过一系列迭代将样本中的数据划分为K类。保证每一种数据样本内的样本距离越小,样本距离越大。(前面这句话我觉得原文有误)。我们在DIOR遥感影像数据集中提取待检测物体的宽高,绘制成散点图,观察待检测物体的宽高分布。如图5所示,由于卫星的拍摄角度和高度复杂,遥感图像中出现了少量的特大物体。如果我们使用 k-means 聚类算法来计算这些异常对象的均值,聚类中心将更接近这些异常对象,这导致它对异常值和噪声敏感(Fang 和 Zhaokui 2019)。
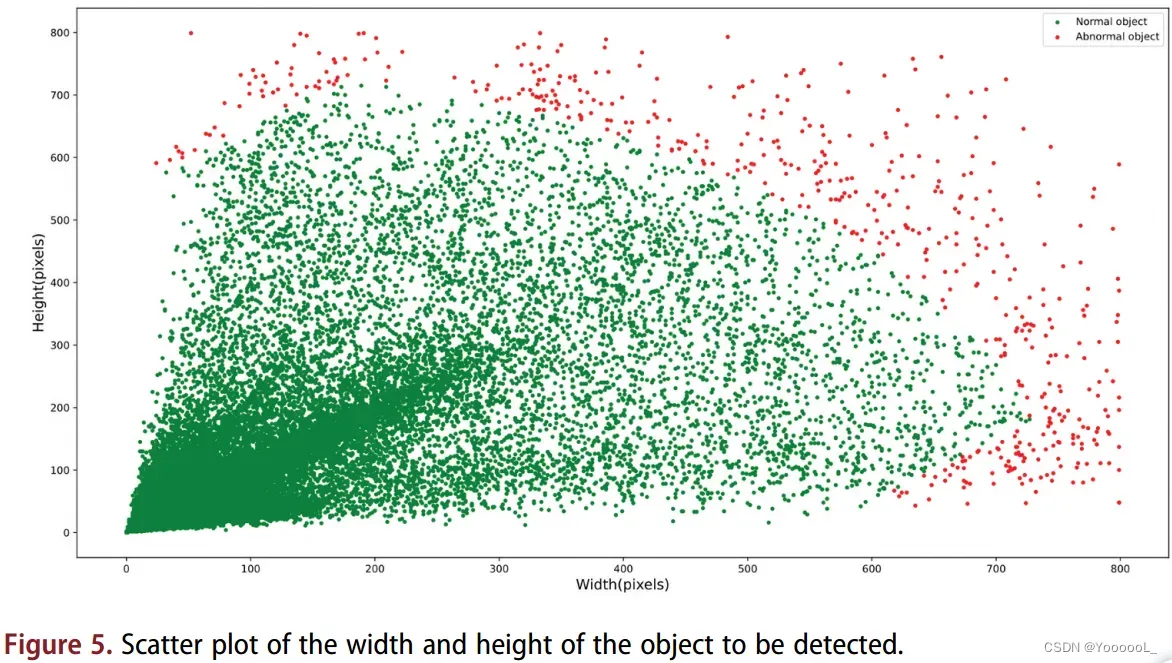
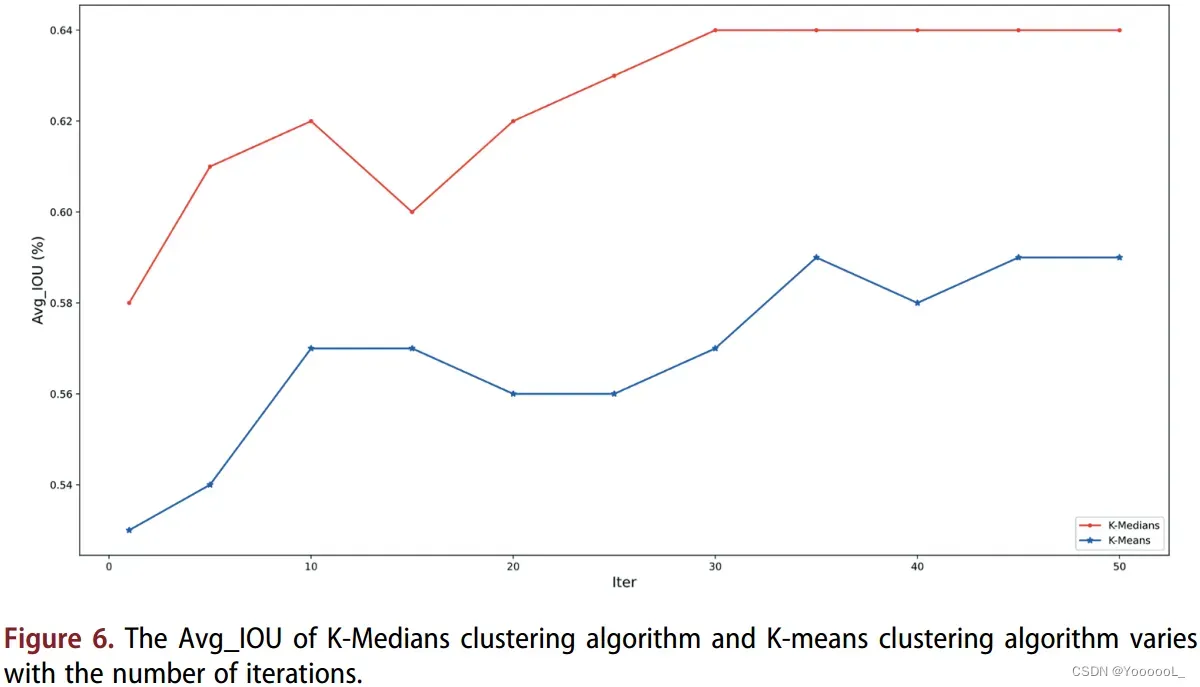
此外,对于大多数遥感图像数据集,数据集中的大多数检测目标都是小目标。并且小目标的大小通常与常见数据集中的锚点大小不匹配。因此,YOLO-v3使用K-means聚类算法生成的anchors不再适用于 以小物体为主的 遥感图像数据集。为了提高检测精度,我们改进了K-means聚类算法。改进后的 K-Medians 聚类算法 生成了 9 个不同大小的锚点。 K-Medians 聚类算法确保当我们更新聚类中心时,我们计算的是样本的中值大小,而不是样本的平均值。由于大多数样本量集中在较小的尺寸,中位数计算削弱了异常值对最终聚类结果的影响。为了验证 K-Medians 的 anchors 比 K-means 的更具有代表性,我们做了一个实验。在本实验中,我们以交并比(IOU)作为度量,计算两种聚类方法得到的聚类中心与待检测对象的平均交并集(Avg_IOU)。 Avg_IOU 越大,聚类效果越好。如图 6 所示,通过不断更新聚类中心的位置,K-Medians 聚类比 k-means 聚类具有更多的代表性锚点。
2.4.特征融合上采样方法的改进
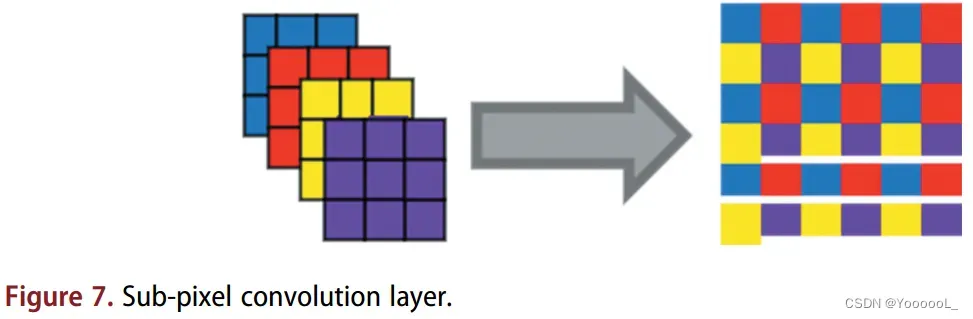
上采样可以增强小目标的细粒度特征,优化小目标检测的效果(Zhang et al 2016)。 Yolo-v3 在特征融合过程中 使用最近邻插值进行上采样。插值是一种简单的上采样方法。但是在小物体的检测中,由于数据集中小物体的分辨率太低,通过插值的方式进行上采样会漏掉很多小物体的特征信息。Deconvolution 反卷积(Fu et al 2017)代替最近邻插值也是一种常见的放大图像尺寸的上采样方法。反卷积是一种通过添加填充来增加图像大小的方法。这种方法会加入很多零,属于无效信息,不利于小目标检测。在本文中,我们 使用亚像素卷积(Shi et al 2016)进行上采样,其原理如图7所示。亚像素卷积直接扩展输入特征的通道维度,然后使用通道维度的倍数来通过重塑提高输入特征的规模。对应的变换关系如下:
![]()
如式6所示,ISR 为高分辨率的特征图,ILR 为低分辨率的特征图。本文采用亚像素卷积,通过卷积 和 多通道重组得到低分辨率的特征图(我认为是得到高分辨率的特征图,原文写错了)。这种方法可以更好地检测小目标。
2.5.预测层的改进
YOLO-v3的预测层采用全卷积结构。第一个卷积层用于改变通道数,第二个卷积层包含网络模型的特征信息。检测对象的分类和回归是通过两个连续的卷积运算实现的。通过分类预测每个anchor的置信度,通过回归预测每个位置的anchors和bounding box的偏移量。根据偏移量tx、ty、tw、th计算预测框位置的公式如下:
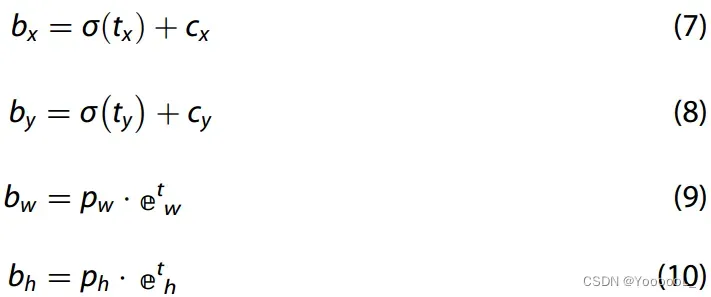
上式中cx,cy为当前Grid单元格左上角点的坐标。 pw,ph分别是anchor的宽度和高度。 bx,by为调整后预测框的中心坐标。 bw,bh分别为预测框调整后的宽度和高度。
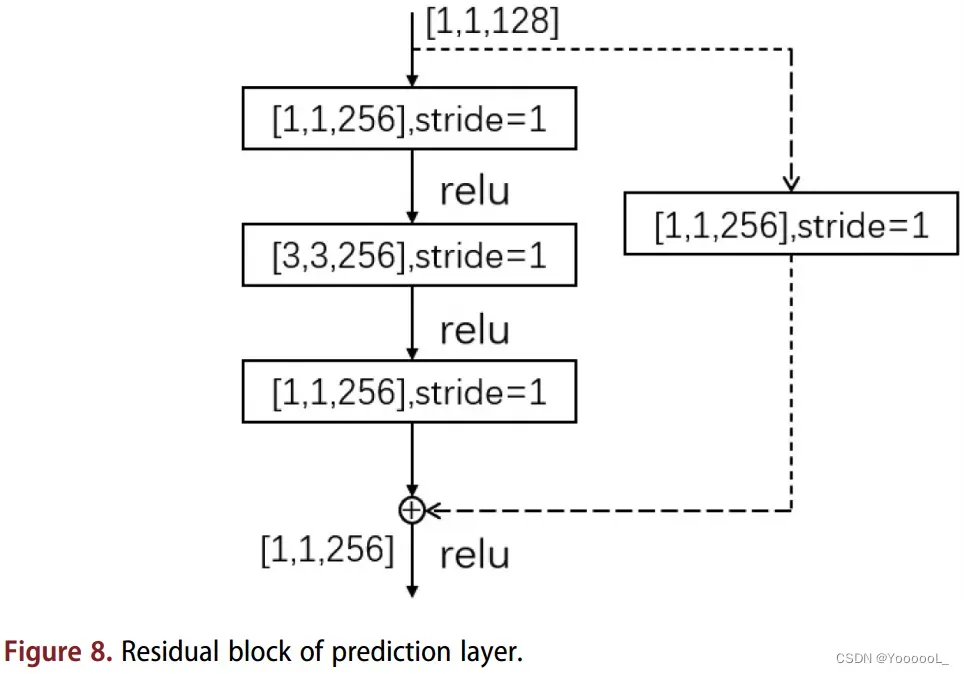
MS-CNN (Cai et al 2016) 指出,改进每个任务的子网络可以提高检测结果的准确性。为了提高预测分支的性能,我们改进了 YOLO-v3 的三个预测层。我们用 残差块 替换 每个预测层的第一个卷积层。该方法优化了候选框的回归和分类任务的输入特征图。同时,第二个卷积层保持不变。残差块如图8所示。
3 实验与分析
3.1.数据集简介
在本文中,我们使用名为 DIOR 数据集的遥感图像 (Li et al 2019)。该数据集的图像大小为 800 × 800。它包含 20 个检测类别,23,463 张图像和 190,288 个实例对象。在本实验中,根据常用的物体尺寸分类规则如表1所示,选取5个尺寸较小的小型地物类别进行实验。它们包括飞机、储罐、轮船、立交桥和车辆。我们从新数据集中使用 9547 张图像进行训练,使用 1054 张图像进行验证,使用 2347 张图像进行测试。

3.2.实验环境及训练过程
本次实验使用的GPU为RTX 3060,显存为12GB。它基于 PyTorch 深度学习框架。并使用python 3.8.1在Linux操作系统上编程。
我们在训练过程中总共进行了120次迭代,batch_size为8。学习率采用固定步长衰减策略。初始学习率为 0.001。每次迭代的学习率变为上次学习率的 0.94。
3.3.评价指标
在本文中,我们使用平均精度(AP)来分析网络模型,我们通过精度(P)和召回率(R)获得它。 P和R可以计算如下:
![]()
![]()
上式中,True Positive(TP)表示正确识别的正样本数,False Positive(FP)表示错误识别为正样本的样本数,False Negative(FN)表示未识别的正样本数。因此,P为正确识别的正样本数与所有识别样本数的比值,R为正确识别的正样本数与正样本总数的比值,AP的值来自于P-R曲线。 AP计算公式如下:

最后,我们使用获得的 AP 来计算 mAP。 mAP计算公式如下,其中N表示检测到的物体类型的数量。在本实验中,用于mAP计算的IOU阈值为0.5。

3.4.性能对比及结果分析
首先,本实验将 YOLO-v3 中的主干 Darknet-53 和 CotYOLO-v3 中的主干 CotDarknet-53 的特征提取过程可视化,以获得特征热图。我们通过分析获得的热图获得两个主干在提取小目标特征的过程中的差异。在本文中,我们分别从backbone Darknet-53和CotDarknet-53中提取最后一层特征输出,得到的特征热图如图9所示。左边的图像是原始图像,中间的图像是backbone Darknet-53特征提取后的热图,右图是backbone CotDarknet-53特征提取后的热图。由于 YOLO-v3 和 CotYOLO-v3 中主干的最后一层输出 1024 个通道,每个特征图由每个通道的 32×32 个小特征图组成,大小为 16×16。
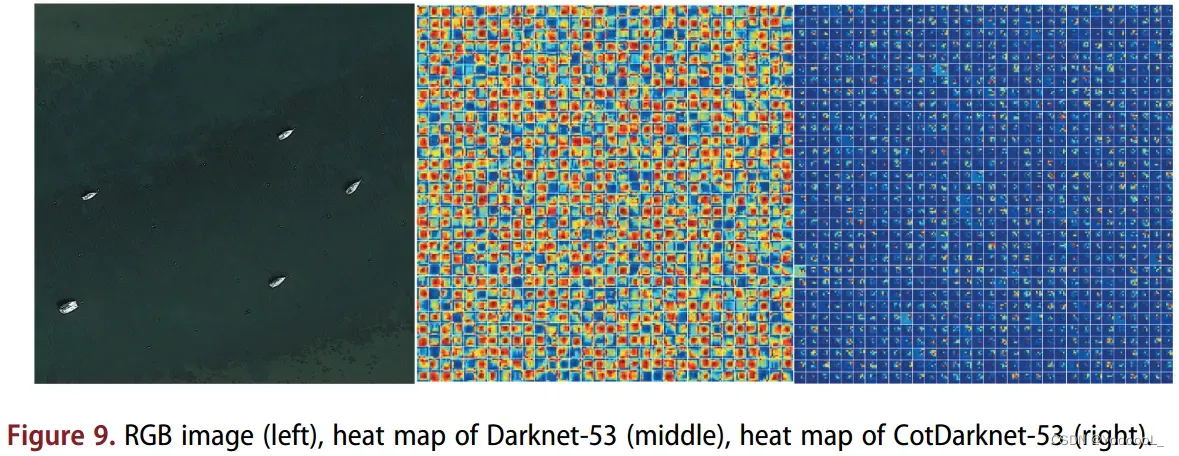
如图9所示,CotDarknet-53提取的特征 能够 更准确地反映图像中待检测小物体的分布情况。结果表明,Cot模块可以利用小物体的上下文信息准确检测小物体。一定程度上缓解了深层网络 对小物体信息的过滤 和 周围环境对小物体检测的干扰。然而,Darknet-53 提取的特征并不能有效区分小物体和背景。因此,CotDarknet-53 比 Darknet-53 更有利于 在特征提取过程中 定位小目标。
为了更好地分析CotYOLO-v3物体检测算法在DIOR数据集中检测小物体的能力,我们在相同的实验环境下分别训练CotYOLO-v3和YOLO-v3,我们选取120次迭代的数据作为最后的结果。 CotYOLO-v3和YOLO-v3的loss变化曲线 如图10所示。
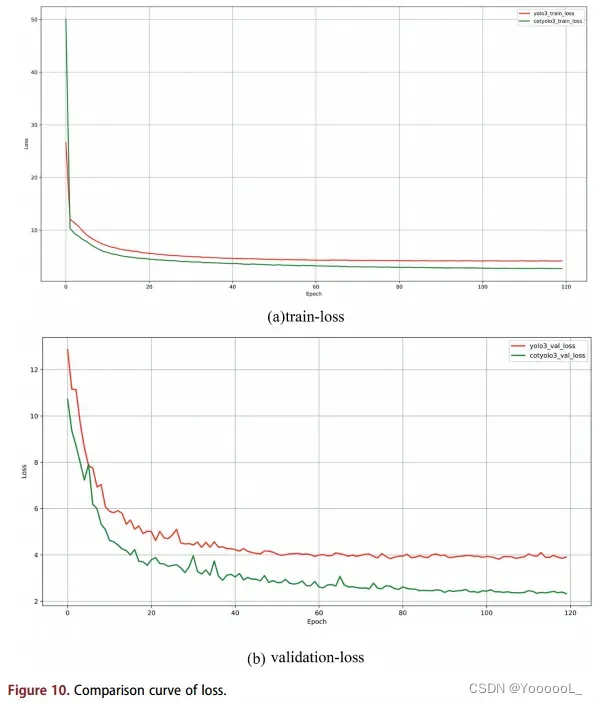
如图10所示,图10(a)中的红线表示YOLOv3的训练损失,绿线表示CotYOLO-v3的训练损失。图10(b)中的红线表示YOLO-v3的验证损失,绿线表示CotYOLO-v3的验证损失。如图 10 所示,YOLO-v3 的训练损失从 26.66 下降到 4.15,验证损失从 12.86 下降到 3.91。 CotYOLO-v3 的训练损失从 50.07 减少到 2.69,CotYOLO-v3 的验证损失从 10.72 减少到 2.33。无论是训练损失 还是 验证损失,CotYOLO-v3 loss的下降幅度都大于YOLO-v3 loss,CotYOLO-v3的值也小于YOLO-v3。此外,CotYOLO-v3 的验证损失显示出明显的振荡衰减过程。它与在训练过程中处理大型数据集时应该发生的变化是一致的。然而,YOLO-v3 的验证损失并没有表现出明显的下降趋势,在 DIOR 数据集上也没有表现出良好的训练过程。因此,从损失对比曲线可以看出,CotYOLO-v3的 损失减少 比 YOLO-v3的损失减少 有更好的表现。
我们使用 120 次迭代的训练结果来计算 YOLO-v3 和 CotYOLO-v3 的检测精度。为了充分展示CotYOLO-v3在DIOR数据集上的效果,我们加入了CotYOLO-v3与其他检测算法的对比实验。它们包括 SSD、CenterNet、YOLO-v3、YOLO-v4 和 YOLO-X。如表2所示,我们得到了120次迭代后不同目标检测算法的检测精度比较。
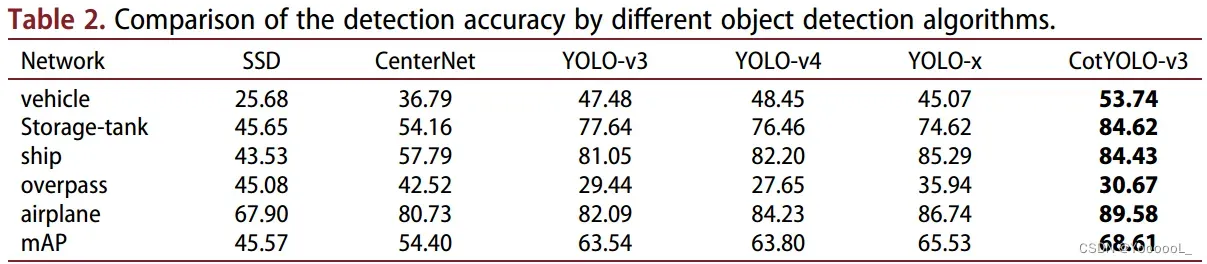
如表2所示,与其他检测算法相比,CotYOLO-v3在各种物体和mAP的检测精度上有更好的表现。与YOLO-v3相比,CotYOLO-v3的mAP提升了5.07%。与其他物体检测算法相比,CotYOLO-v3在遥感图像中的小目标检测方面也具有明显的优势:与YOLO-v4和最近发布的YOLO-X相比,CotYOLO-v3的mAP分别提高了4.81%和3.08%,分别。并且与SSD和CenterNet相比,CotYOLO-v3的mAP提升更为显着。我们发 现SSD不能很好工作的原因是它不能融合深度和浅层特征。当使用中心点预测物体时,CenterNet 效果不佳,因为在 Heatmap 中为较小物体生成的高斯圆差异不足以达到令人满意的检测结果。
我们进一步分析各种物体的检测精度。我们发现 各种网络对储罐、轮船和飞机的检测准确率都很高,主要是因为它们在数据集中所占比例较大,并且易于检测。由于它们的网络相对较小,与其他更复杂的网络相比,SSD 和 CenterNet 对于数据集比例较小的立交桥具有更好的检测精度 (Ketkar 2017)。 CotYOLO-v3 在少量数据集下检测立交桥的能力较弱,主要是由于使用了注意力机制,在大型数据集上效果更好(Dosovitskiy et al 2020)。而CotYOLO-v3在车辆、储罐、船舶和飞机的检测精度上提升最为明显。因此,CotYOLO-v3检测算法在检测遥感图像中的小物体方面具有更好的性能。
为了进一步分析CotYOLO-v3在小目标检测领域的改进,我们设置了消融实验。我们将 CotYOLO-v3 中的 所有改进 分解为六个实验。我们总共进行了七个实验,包括 YOLO-v3。这些改进包括:用Cot模块 替换backbone中的残差块,在特征融合之前添加SE模块,在特征融合过程中引入浅层信息,用亚像素卷积替换FPN中的上采样,用残差块替换预测层中的第一个卷积层,并使用K-Medians算法重新聚类锚框的大小。这些不同的改进对网络模型的影响如表3所示。‘√’表示我们在横轴上使用相应的方法(这里原文也是错的)。如表 3 所示,我们可以清楚地看到 CotYOLO-v3 的各种改进以及这些改进对数据集中小物体检测的贡献。

如表3所示,改进1将YOLO-v3主干中的残差块替换为cot模块,mAP从63.54%提高到65.43%,mAP提高了1.89%。改进1的改进效果最为明显。实验结果表明,Cot模块挖掘了小目标的上下文信息,提高了小物体的检测能力。改进2是在特征融合过程中引入浅层信息,mAP提升了0.84%。实验结果表明,浅层信息具有更高的分辨率,有利于小目标检测。改进3在提取浅层信息后引入SE模块,mAP提升1.04%。实验结果表明,SE模块减少了背景中不必要的浅层特征信息,有利于小目标检测。改进4用亚像素卷积代替FPN中的上采样方法,mAP提升0.07%。实验结果表明,虽然亚像素卷积通过加0弥补了上采样反卷积的不足,但 对遥感图像中小物体检测的提升能力还不够明显。改进5用残差块代替预测层的第一个卷积,mAP提高了0.88%。实验结果表明,预测层中的残差块有利于小物体检测。最后,我们添加 K-Medians 聚类来重新生成锚点的大小,mAP 增加了 0.35%。实验结果表明,获取数据集中样本量的中位数更有利于anchors的聚类大小。综上所述,带有上下文信息的Cot模块对网络提升的贡献最大,带有注意力机制SE模块的浅层特征和深层特征的融合在一定程度上提升了网络的性能。
为了可视化CotYOLO-v3在遥感图像小目标检测领域所做的改进,我们从DIOR数据集中选择了三种包含小目标的代表性图像。它们包括:部分阴影遮挡下的飞机检测、密集分布环境下的船舶检测 和 复杂背景下的立交桥检测。我们分别使用YOLO-v3和CotYOLO-v3对上述三类图像中的小物体进行检测,检测结果如图11所示。


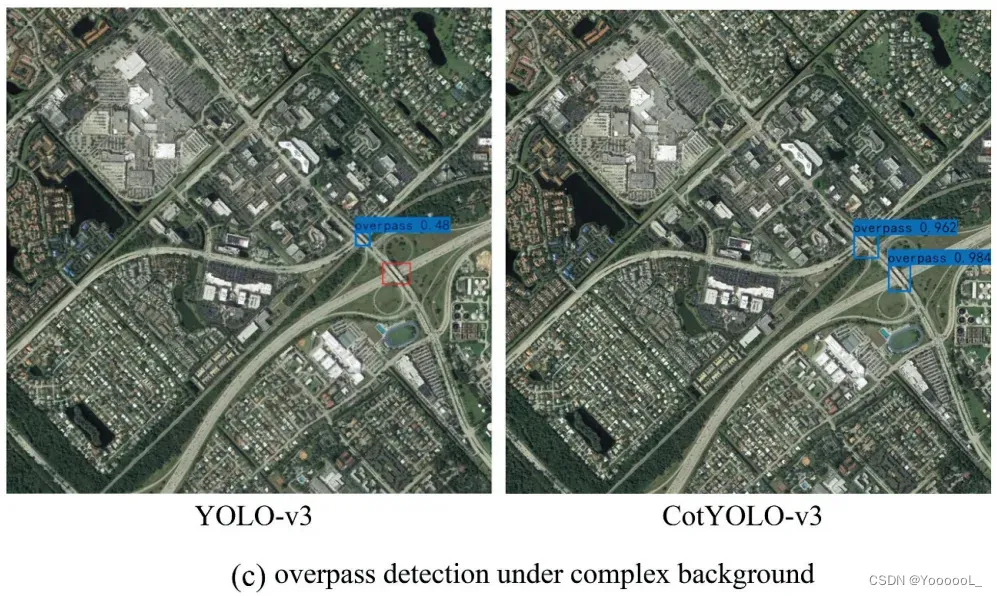
如图11所示,与YOLO-v3相比,CotYOLO-v3检测到了更多难以检测的小物体,检测精度得到了一定程度的提升。 YOLO-v3 未检测到的对象标记为红色。图 11(a) 表示在部分阴影遮挡下的飞机检测。 YOLO-v3只检测一些稍大的物体,不检测不易检测的小物体。同时,它无法检测到被阴影遮挡的小物体。相反,CotYOLO-v3 几乎可以检测到所有飞机,包括那些在阴影中的飞机。因此,与YOLOv3相比,CotYOLO-v3在检测有遮挡的小物体方面具有更高的检测精度。图 11(b) 表示密集分布环境下的船舶检测。在检测物体分布密集的情况下,YOLO-v3无法检测到像素较小且分布密集的船舶。不过与YOLO-v3相比,CotYOLO-v3检测到了更多的小物体,检测精度也有一定程度的提升。图 11(c) 表示复杂背景下的立交桥检测。由于图像背景过于复杂,YOLO-v3检测性能差,漏检率高。不能准确检测小物体,漏检率高。(这里描述又重复了,这篇文章质量不高)相反,CotYOLO-v3在复杂背景下检测出更多的小物体,检测精度得到一定程度的提升。总之,CotYOLO-v3弥补了YOLO-v3在遥感数据集中检测小目标的不足,CotYOLO-v3提高了检测模型在分布密集、背景复杂的情况下的检测性能。
4. 结论
综上所述,针对 遥感图像中小物体分辨率低、缺失率高的问题,本文提出了CotYOLO-v3。首先,该算法使用 结合 上下文信息挖掘 和 自注意力学习的 Cot 模块。该网络通过用 Cot 模块替换 Darknet-53 中残差块中的 3×3 卷积并添加 1×1 卷积来构建 CotDarknet-53。该方法增强了小物体的特征提取能力。其次,我们为特征融合添加了具有小下采样倍数的浅层特征。并且我们在特征融合之前将 SE 模块引入到网络中。这种方法减少了背景等不必要的特征,使检测网络更加关注小物体。第三,我们使用 K-Medians 聚类算法代替 K-means 聚类算法来生成适合 DIOR 数据集的锚点。最后,我们将特征融合中的上采样方法替换为亚像素卷积,并将预测层的第一个卷积替换为残差块。这些方法有助于小对象的特征融合。在本文中,我们在 DIOR 数据集中执行小物体检测。实验结果表明,CotYOLO-v3具有明显的优势。 CotYOLO-v3的mAP达到68.61%。同时,CotYOLO-v3在各类物体中也有着不错的检测精度。在CotYOLO-v3的改进中,带有上下文信息的Cot模块和浅层特征与深度特征与注意机制的融合对提高遥感图像中小物体的网络检测效果最好。 CotYOLO-v3在部分阴影遮挡下的飞机检测、密集分布环境下的船舶检测、复杂背景下的立交桥检测等方面也有显著的检测效果。未来,我们会将CotYOLO-v3部署到移动设备上,实现网络模型的轻量化,提高遥感图像数据集中小物体的检测能力。
文章出处登录后可见!