一、迁移学习概念,含义及动机
1.概念
迁移学习的目标是将某个领域或任务上学习到的知识应用到不同的但相关的领域或问题中。
2.含义
迁移学习的研究来源于一个观测:人类可以将以前的学到的知识应用于解决新的问题,更快的解决问题或取得更好的效果。迁移学习被赋予这样一个任务:从以前的任务当中去学习知识(knowledge)或经验,并应用于新的任务当中。换句话说,迁移学习目的是从一个或多个源任务(source tasks)中抽取知识、经验,然后应用于一个目标领域(target domain)当中去。
3.动机
(1)数据分布偏差问题
传统的机器学习/数据挖掘只有在训练集数据和测试集数据都来自同一个feature space(特征空间)和统一分布的时候才运行的比较好,这意味着每一次换了数据都要重新训练模型,太麻烦了。比如:
(1)从数据类型/内容上看,对于新的数据集,获取新的训练数据很贵也很难。
(2)从时间维度上看,有些数据集很容易过期,即不同时期的数据分布也会不同。比如对于某个用户进行室内wifi定位的时候,把他在一个很大的室内的数据标记好已经很难了,wifi信号强弱还会受到时间影响,所以如果对于每个时间段都要进行一次训练那就太麻烦了。
深度学习对大量的训练数据有很强的依赖性,传统的机器学习方法,因为它需要大量的数据理解数据的潜在模式。一个有趣的现象是发现模型的规模和所需要的数据量有多大几乎是线性关系。一个可以接受的解释是,模型的表达空间必须足够大才能被发现数据下的模式。
(2)域漂移问题
域漂移,指的是使用源域训练的模型在目标域上测试时,目标域的预测分布和真实分布之间存在差异的现象。
举例:源域是猫,目标域是人。假设两个域共享的属性空间包含两个属性,“是不是动物?”、“有几条腿?” 那么,猫的属性表示是“是动物”、“四条腿”;人的属性表示是“是动物”、“两条腿”。那么,基于猫学习的视觉语义映射,在对人进行测试的时候,大部分预测结果会是“是动物”、“四条腿”,而远离了真实属性表示“是动物”、“两条腿”。
二、迁移学习任务
1.domain adaptation
在经典的机器学习问题中,我们往往假设训练集和测试集分布一致,在训练集上训练模型,在测试集上测试。然而在实际问题中,测试场景往往非可控,测试集和训练集分布有很大差异,这时候就会出现所谓过拟合问题:模型在测试集上效果不理想。
以人脸识别为例,如果用东方人人脸数据训练,用于识别西方人,相比东方人识别性能会明显下降。
当训练集和测试集分布不一致的情况下,通过在训练数据上按经验误差最小准则训练的模型在测试上性能不好,因此出现了迁移学习技术。
领域自适应(Domain Adaptation)是迁移学习中的一种代表性方法,指的是利用信息丰富的源域样本来提升目标域模型的性能。
领域自适应问题中两个至关重要的概念:源域(source domain)表示与测试样本不同的领域,但是有丰富的监督信息;目标域(target domain)表示测试样本所在的领域,无标签或者只有少量标签。源域和目标域往往属于同一类任务,但是分布不同。
根据目标域和源域的不同类型,领域自适应问题有四类不同的场景:无监督的,有监督的,异构分布和多个源域问题。
通过在不同阶段进行领域自适应,研究者提出了三种不同的领域自适应方法:1)样本自适应,对源域样本进行加权重采样,从而逼近目标域的分布。2)特征层面自适应,将源域和目标域投影到公共特征子空间。3)模型层面自适应,对源域误差函数进行修改,考虑目标域的误差。
(1)
样本自适应
其基本思想是对源域样本进行重采样,从而使得重采样后的源域样本和目标域样本分布基本一致,在重采样的样本集合上重新学习分类器。
样本迁移(Instance based TL)
在源域中找到与目标域相似的数据,把这个数据的权值进行调整,使得新的数据与目标域的数据进行匹配,然后加重该样本的权值,使得在预测目标域时的比重加大。优点是方法简单,实现容易。缺点在于权重的选择与相似度的度量依赖经验,且源域与目标域的数据分布往往不同。

(2)
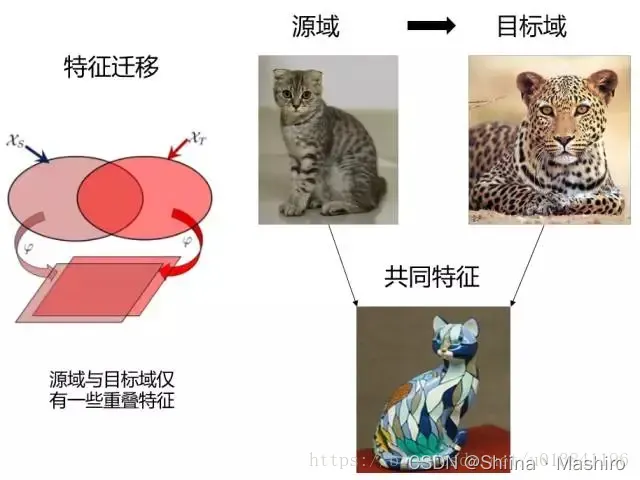
特征自适应
其基本思想是学习公共的特征表示,在公共特征空间,源域和目标域的分布要尽可能相同。
特征迁移(Feature based TL)
假设源域和目标域含有一些共同的交叉特征,通过特征变换,将源域和目标域的特征变换到相同空间,使得该空间中源域数据与目标域数据具有相同分布的数据分布,然后进行传统的机器学习。优点是对大多数方法适用,效果较好。缺点在于难于求解,容易发生过适配。
(3)
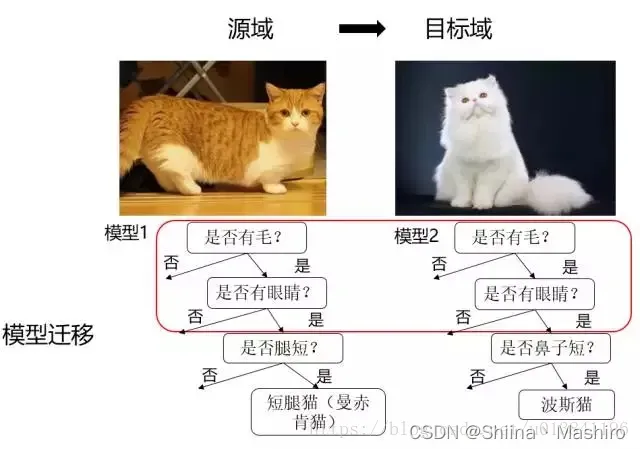
模型自适应
其基本思想是直接在模型层面进行自适应。模型自适应的方法有两种思路,一是直接建模模型,但是在模型中加入“domain间距离近”的约束,二是采用迭代的方法,渐进的对目标域的样本进行分类,将信度高的样本加入训练集,并更新模型。
模型迁移(Parameter based TL)
假设源域和目标域共享模型参数,是指将之前在源域中通过大量数据训练好的模型应用到目标域上进行预测,比如利用上千万的图象来训练好一个图象识别的系统,当我们遇到一个新的图象领域问题的时候,就不用再去找几千万个图象来训练了,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需几万张图片就够,同样可以得到很高的精度。优点是可以充分利用模型之间存在的相似性。缺点在于模型参数不易收敛。
2.domain generalization
领域泛化问题与领域自适应 (Domain Adaptation,DA)最大的不同:DA在训练中,源域和目标域数据均能访问(无监督DA中则只有无标记的目标域数据);而在DG问题中,我们只能访问若干个用于训练的源域数据,测试数据是不能访问的。毫无疑问,DG是比DA更具有挑战性和实用性的场景:毕竟我们都喜欢“一次训练、到处应用”的足够泛化的机器学习模型。
例如,在下图中,DA问题假定训练集和测试集都可以在训练过程中被访问,而DG问题中则只有训练集。

(1)DA与DG比较:
DA不够高效,每来一个新域,都需要重复进行适应,而DG只需训练一次;
DA的性能比DG的性能要高,由于使用了目标域的数据;
DA的强假设是目标域的数据是可用的,显然有些情况是无法满足的,或者代价昂贵。
DA关注如何利用无标注的目标数据,而DG主要关注泛化性。
(2)DG 分类
根据标签空间:
Homogeneous DG: 源域标签空间和目标域标签空间一致,在图像分类和分割中较常见;
Heterogeneous DG:源域标签空间和目标域标签空间不一致,更加实际且更具挑战,例如跨数据集的行人重识别人物,不同数据集中的人物是不一样的。
根据源域数量:
Multi-source:使用多种不同源域数据,能够提高让模型发现更稳定模式的机会;
Single-source:一般通过破坏和干扰数据提高模型的鲁棒性,比如进行数据增广。
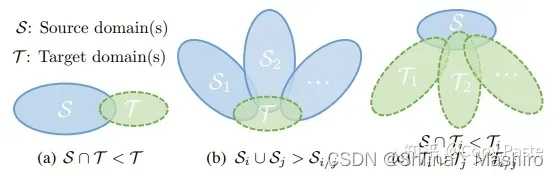
图:域差异。(a)DA, (b)Multi-source DG, © Single-source DG
(3)未来挑战
连续领域泛化:一个系统应具有连续进行泛化和适配的能力,目前只是离线状态的一次应用。
新类别的领域泛化:目前我们假定所有的领域具有相同的类别,未来需要扩展到不同类别中、乃至新类别中。
可解释的领域泛化:尽管基于解耦的方法在可解释性上取得了进步,但是,其他大类的方法的可解释性仍然不强。未来需要对它们的可解释性进行进一步研究。
大规模预训练与领域泛化:众所周知,大规模预训练(如BERT)已成为主流,那么在不同问题的在规模预训练中,我们如何利用DG方法来进一步提高这些预训练模型的泛化能力?
领域泛化的评价:尽管有工作在经验上说明已有的领域泛化方法的效果并没有大大领先于经验风险最小化,但其只是基于最简单的分类任务。我们认为DG需要在特定的评测,例如行人再识别中才能最大限度地发挥其作用。未来,我们需要找到更适合DG问题的应用场景。
文章出处登录后可见!